这篇文章主要介绍了Pycharm安装scrapy及初始化爬虫项目的方法的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Pycharm安装scrapy及初始化爬虫项目的方法文章都会有所收获,下面我们一起来看看吧。
1、打开cmd命令窗口,输入:pip install Scrapy。
2、安装成功之后会显示下面字符,表示未将scrapy设置到环境变量。

3、配置环境变量:右键我的电脑-->属性-->高级设置--->环境变量---->系统变量中的Path--->编辑--->添加--->将上文中黄色的路径添加到环境变量即可。
4、scrapy安装完毕。
1、创建一个普通的Pycharm项目,然后找到下面的terminal

2、输入命令scrapy startproject 模块名称(可以自己随便起,我以名为mine为例),成功之后你会发现自己的项目中多了一个mine的包文件。
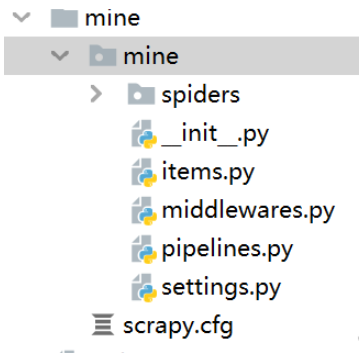
3、上述操作成功后终端会显示下图文字:此时我们输入cd那条命令。进入目标文件。

4、这时就可以创建爬虫目标文件啦,
输入scrapy genspider 爬取名 网站域名
1、爬取名是自己随便起的,比如我要爬百度那么我就可以起名为baidu
2、网站域名就是去掉 https:www. 剩下的部分
2和3操作截图:

5、此时我们会在目录里看见一个新的py文件:里自动生成如下代码:

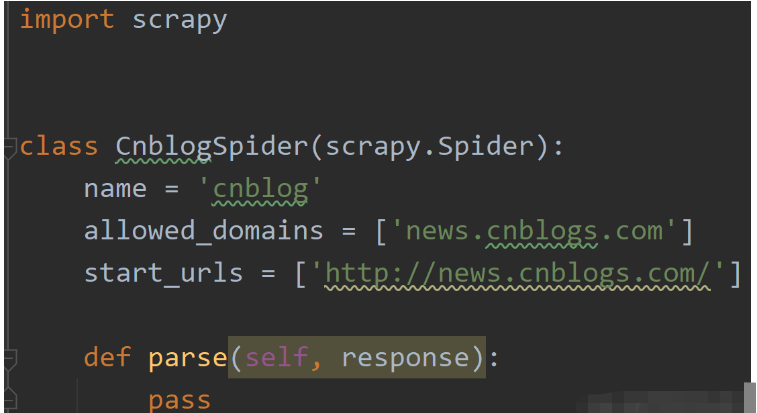
由于pycharm没有创建scrapy框架的模块,所以我们想调试scrapy程序时要自己写一个小脚本来开启pycharm对scrapy的调试功能。
1、在与mine包同级条件下创建一个main.py文件:

2、mine文件将一下代码赋值进去:
import os
import sys
from scrapy.cmdline import execute
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "cnblog"]) # 第三个参数为自己创建的那个爬取的名称关于“Pycharm安装scrapy及初始化爬虫项目的方法”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Pycharm安装scrapy及初始化爬虫项目的方法”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



