这篇文章主要介绍了Vue中的虚拟DOM如何构建的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Vue中的虚拟DOM如何构建文章都会有所收获,下面我们一起来看看吧。

虚拟DOM技术使得我们的页面渲染的效率更高,减轻了节点的操作从而提高性能。
DOM和其解析流程 本节我们主要介绍真实 DOM 的解析过程,通过介绍其解析过程以及存在的问题,从而引出为什么需要虚拟DOM。一图胜千言,如下图为 webkit 渲染引擎工作流程图

所有的浏览器渲染引擎工作流程大致分为5步:创建 DOM 树 —> 创建 Style Rules -> 构建 Render 树 —> 布局 Layout -—> 绘制 Painting。
第一步,构建 DOM 树:用 HTML 分析器,分析 HTML 元素,构建一棵 DOM 树;
第二步,生成样式表:用 CSS 分析器,分析 CSS 文件和元素上的 inline 样式,生成页面的样式表;
第三步,构建 Render 树:将 DOM 树和样式表关联起来,构建一棵 Render 树(Attachment)。每个 DOM 节点都有 attach 方法,接受样式信息,返回一个 render 对象(又名 renderer),这些 render 对象最终会被构建成一棵 Render 树;
第四步,确定节点坐标:根据 Render 树结构,为每个 Render 树上的节点确定一个在显示屏上出现的精确坐标;
第五步,绘制页面:根据 Render 树和节点显示坐标,然后调用每个节点的 paint 方法,将它们绘制出来。
注意点:
1、DOM 树的构建是文档加载完成开始的? 构建 DOM 树是一个渐进过程,为达到更好的用户体验,渲染引擎会尽快将内容显示在屏幕上,它不必等到整个 HTML 文档解析完成之后才开始构建 render 树和布局。
2、Render 树是 DOM 树和 CSS 样式表构建完毕后才开始构建的? 这三个过程在实际进行的时候并不是完全独立的,而是会有交叉,会一边加载,一边解析,以及一边渲染。
3、CSS 的解析注意点? CSS 的解析是从右往左逆向解析的,嵌套标签越多,解析越慢。
4、JS 操作真实 DOM 的代价? 用我们传统的开发模式,原生 JS 或 JQ 操作 DOM 时,浏览器会从构建 DOM 树开始从头到尾执行一遍流程。在一次操作中,我需要更新 10 个 DOM 节点,浏览器收到第一个 DOM 请求后并不知道还有 9 次更新操作,因此会马上执行流程,最终执行10 次。例如,第一次计算完,紧接着下一个 DOM 更新请求,这个节点的坐标值就变了,前一次计算为无用功。计算 DOM 节点坐标值等都是白白浪费的性能。即使计算机硬件一直在迭代更新,操作 DOM 的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户体验
Virtual-DOM 基础DOM 的好处 虚拟 DOM 就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有 10 次更新 DOM 的动作,虚拟 DOM 不会立即操作 DOM,而是将这 10 次更新的 diff 内容保存到本地一个 JS 对象中,最终将这个 JS 对象一次性 attch 到 DOM 树上,再进行后续操作,避免大量无谓的计算量。所以,用 JS 对象模拟 DOM 节点的好处是,页面的更新可以先全部反映在 JS 对象(虚拟 DOM )上,操作内存中的 JS 对象的速度显然要更快,等更新完成后,再将最终的 JS 对象映射成真实的 DOM,交由浏览器去绘制。
JS 对象模拟 DOM 树(1)如何用 JS 对象模拟 DOM 树
例如一个真实的 DOM 节点如下:
<div id="virtual-dom">
<p>Virtual DOM</p>
<ul id="list">
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<div>Hello World</div>
</div>我们用 JavaScript 对象来表示 DOM 节点,使用对象的属性记录节点的类型、属性、子节点等。
element.js 中表示节点对象代码如下:
/**
* Element virdual-dom 对象定义
* @param {String} tagName - dom 元素名称
* @param {Object} props - dom 属性
* @param {Array<Element|String>} - 子节点
*/
function Element(tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
// dom 元素的 key 值,用作唯一标识符
if(props.key){
this.key = props.key
}
var count = 0
children.forEach(function (child, i) {
if (child instanceof Element) {
count += child.count
} else {
children[i] = '' + child
}
count++
})
// 子元素个数
this.count = count
}
function createElement(tagName, props, children){
return new Element(tagName, props, children);
}
module.exports = createElement;根据 element 对象的设定,则上面的 DOM 结构就可以简单表示为:
var el = require("./element.js");
var ul = el('div',{id:'virtual-dom'},[ el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [ el('li', { class: 'item' }, ['Item 1']),
el('li', { class: 'item' }, ['Item 2']),
el('li', { class: 'item' }, ['Item 3'])
]),
el('div',{},['Hello World'])
])现在 ul 就是我们用 JavaScript 对象表示的 DOM 结构,我们输出查看 ul 对应的数据结构如下:

(2)渲染用 JS 表示的 DOM 对象
但是页面上并没有这个结构,下一步我们介绍如何将 ul 渲染成页面上真实的 DOM 结构,相关渲染函数如下:
/**
* render 将virdual-dom 对象渲染为实际 DOM 元素
*/
Element.prototype.render = function () {
var el = document.createElement(this.tagName)
var props = this.props
// 设置节点的DOM属性
for (var propName in props) {
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}我们通过查看以上 render 方法,会根据 tagName 构建一个真正的 DOM 节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。
我们将构建好的 DOM 结构添加到页面 body 上面,如下:
ulRoot = ul.render();
document.body.appendChild(ulRoot);这样,页面 body 里面就有真正的 DOM 结构,效果如下图所示:

DOM 树的差异 — diff 算法diff 算法用来比较两棵 Virtual DOM 树的差异,如果需要两棵树的完全比较,那么 diff 算法的时间复杂度为O(n^3)。但是在前端当中,你很少会跨越层级地移动 DOM 元素,所以 Virtual DOM 只会对同一个层级的元素进行对比,如下图所示, div 只会和同一层级的 div 对比,第二层级的只会跟第二层级对比,这样算法复杂度就可以达到 O(n)。

(1)深度优先遍历,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
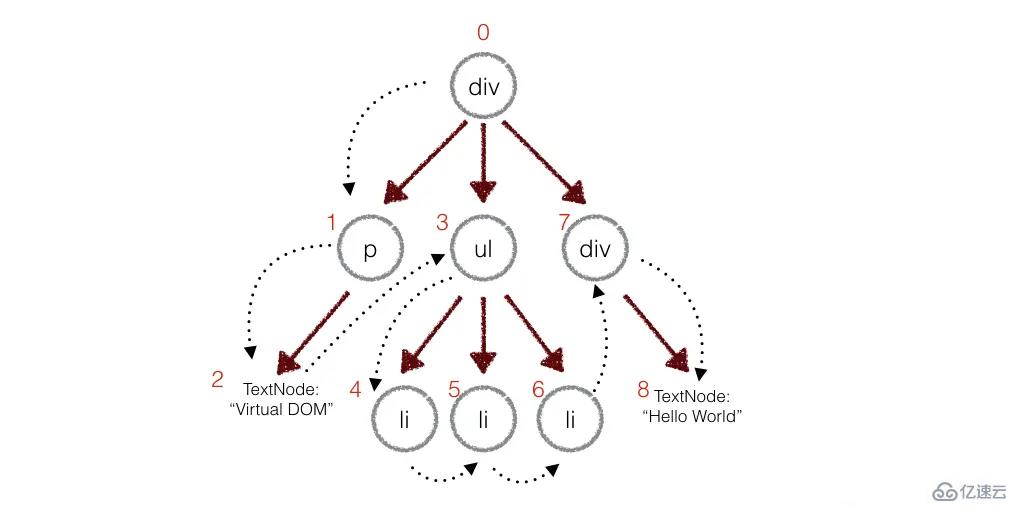
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff(oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk(oldNode, newNode, index, patches) {
var currentPatch = []
if (typeof (oldNode) === "string" && typeof (newNode) === "string") {
// 文本内容改变
if (newNode !== oldNode) {
currentPatch.push({ type: patch.TEXT, content: newNode })
}
} else if (newNode!=null && oldNode.tagName === newNode.tagName && oldNode.key === newNode.key) {
// 节点相同,比较属性
var propsPatches = diffProps(oldNode, newNode)
if (propsPatches) {
currentPatch.push({ type: patch.PROPS, props: propsPatches })
}
// 比较子节点,如果子节点有'ignore'属性,则不需要比较
if (!isIgnoreChildren(newNode)) {
diffChildren(
oldNode.children,
newNode.children,
index,
patches,
currentPatch
)
}
} else if(newNode !== null){
// 新节点和旧节点不同,用 replace 替换
currentPatch.push({ type: patch.REPLACE, node: newNode })
}
if (currentPatch.length) {
patches[index] = currentPatch
}
}从以上可以得出,patches[1] 表示 p ,patches[3] 表示 ul ,以此类推。
(2)差异类型
DOM 操作导致的差异类型包括以下几种:
节点替换:节点改变了,例如将上面的 div 换成 h2;
顺序互换:移动、删除、新增子节点,例如上面 div 的子节点,把 p 和 ul 顺序互换;
属性更改:修改了节点的属性,例如把上面 li 的 class 样式类删除;
文本改变:改变文本节点的文本内容,例如将上面 p 节点的文本内容更改为 “Real Dom”;
以上描述的几种差异类型在代码中定义如下所示:
var REPLACE = 0 // 替换原先的节点
var REORDER = 1 // 重新排序
var PROPS = 2 // 修改了节点的属性
var TEXT = 3 // 文本内容改变(3)列表对比算法
子节点的对比算法,例如 p, ul, div 的顺序换成了 div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如 p 和 div 的 tagName 不同,p 会被 div 所替代。最终,三个节点都会被替换,这样 DOM 开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
将这个问题抽象出来其实就是字符串的最小编辑距离问题(Edition Distance),最常见的解决方法是 Levenshtein Distance , Levenshtein Distance 是一个度量两个字符序列之间差异的字符串度量标准,两个单词之间的 Levenshtein Distance 是将一个单词转换为另一个单词所需的单字符编辑(插入、删除或替换)的最小数量。Levenshtein Distance 是1965年由苏联数学家 Vladimir Levenshtein 发明的。Levenshtein Distance 也被称为编辑距离(Edit Distance),通过动态规划求解,时间复杂度为 O(M*N)。
定义:对于两个字符串 a、b,则他们的 Levenshtein Distance 为:
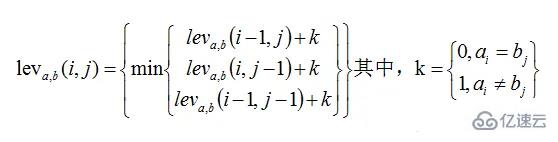
示例:字符串 a 和 b,a=“abcde” ,b=“cabef”,根据上面给出的计算公式,则他们的 Levenshtein Distance 的计算过程如下:

本文的 demo 使用插件 list-diff2 算法进行比较,该算法的时间复杂度伟 O(n*m),虽然该算法并非最优的算法,但是用于对于 dom 元素的常规操作是足够的。该算法具体的实现过程这里不再详细介绍,该算法的具体介绍可以参照:github.com/livoras/lis…
(4)实例输出
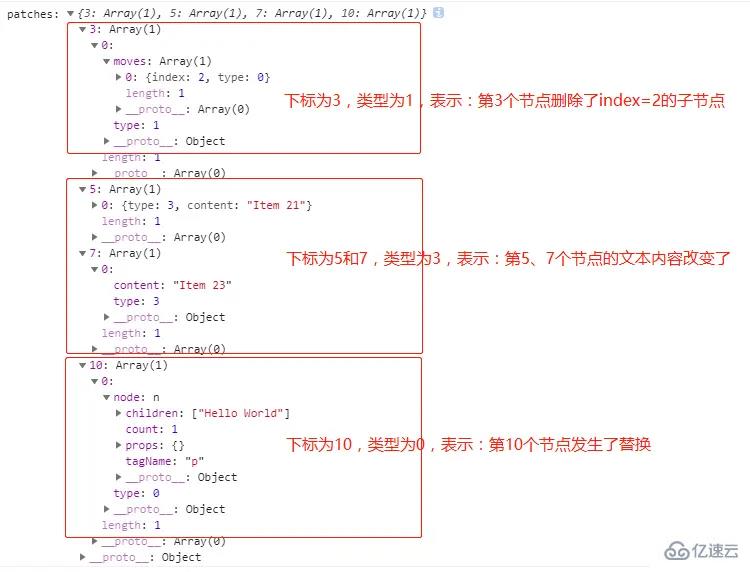
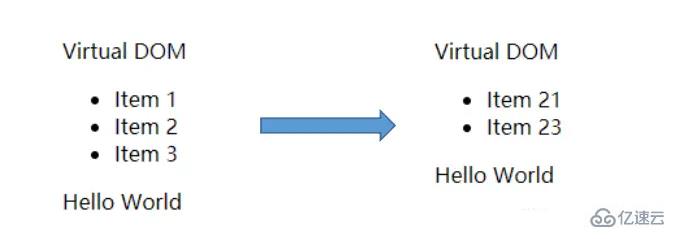
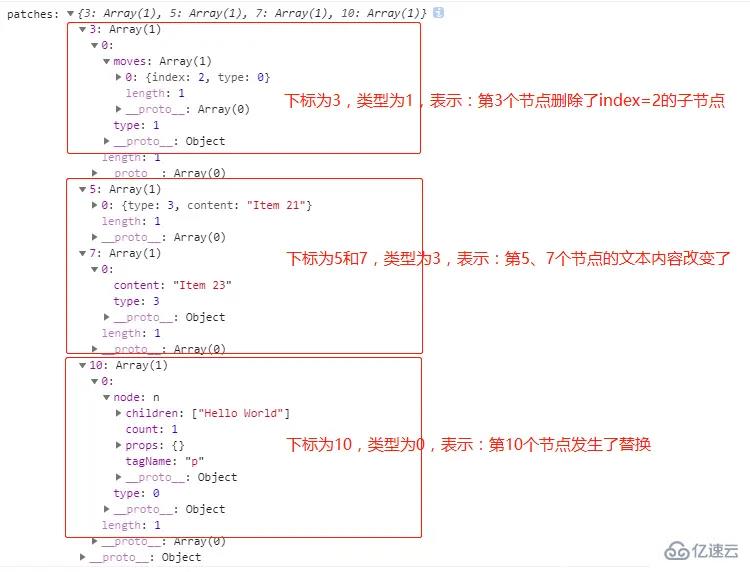
两个虚拟 DOM 对象如下图所示,其中 ul1 表示原有的虚拟 DOM 树,ul2 表示改变后的虚拟 DOM 树
var ul1 = el('div',{id:'virtual-dom'},[ el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [ el('li', { class: 'item' }, ['Item 1']),
el('li', { class: 'item' }, ['Item 2']),
el('li', { class: 'item' }, ['Item 3'])
]),
el('div',{},['Hello World'])
])
var ul2 = el('div',{id:'virtual-dom'},[ el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [ el('li', { class: 'item' }, ['Item 21']),
el('li', { class: 'item' }, ['Item 23'])
]),
el('p',{},['Hello World'])
])
var patches = diff(ul1,ul2);
console.log('patches:',patches);我们查看输出的两个虚拟 DOM 对象之间的差异对象如下图所示,我们能通过差异对象得到,两个虚拟 DOM 对象之间进行了哪些变化,从而根据这个差异对象(patches)更改原先的真实 DOM 结构,从而将页面的 DOM 结构进行更改。
DOM 对象的差异应用到真正的 DOM 树(1)深度优先遍历 DOM 树
因为步骤一所构建的 JavaScript 对象树和 render 出来真正的 DOM 树的信息、结构是一样的。所以我们可以对那棵 DOM 树也进行深度优先的遍历,遍历的时候从步骤二生成的 patches 对象中找出当前遍历的节点差异,如下相关代码所示:
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
// 从patches拿出当前节点的差异
var currentPatches = patches[walker.index]
var len = node.childNodes
? node.childNodes.length
: 0
// 深度遍历子节点
for (var i = 0; i < len; i++) {
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
// 对当前节点进行DOM操作
if (currentPatches) {
applyPatches(node, currentPatches)
}
}(2)对原有 DOM 树进行 DOM 操作
我们根据不同类型的差异对当前节点进行不同的 DOM 操作 ,例如如果进行了节点替换,就进行节点替换 DOM 操作;如果节点文本发生了改变,则进行文本替换的 DOM 操作;以及子节点重排、属性改变等 DOM 操作,相关代码如 applyPatches 所示 :
function applyPatches (node, currentPatches) {
currentPatches.forEach(currentPatch => {
switch (currentPatch.type) {
case REPLACE:
var newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render()
node.parentNode.replaceChild(newNode, node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}(3)DOM结构改变
通过将第 2.2.2 得到的两个 DOM 对象之间的差异,应用到第一个(原先)DOM 结构中,我们可以看到 DOM 结构进行了预期的变化,如下图所示:
相关代码实现已经放到 github 上面,有兴趣的同学可以clone运行实验,github地址为:github.com/fengshi123/…
Virtual DOM 算法主要实现上面三个步骤来实现:
用 JS 对象模拟 DOM 树 — element.js
<div id="virtual-dom">
<p>Virtual DOM</p>
<ul id="list">
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<div>Hello World</div>
</div>比较两棵虚拟 DOM 树的差异 — diff.js
将两个虚拟 DOM 对象的差异应用到真正的 DOM 树 — patch.js
function applyPatches (node, currentPatches) {
currentPatches.forEach(currentPatch => {
switch (currentPatch.type) {
case REPLACE:
var newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render()
node.parentNode.replaceChild(newNode, node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}Vue 源码 Virtual-DOM 简析我们从第二章节(Virtual-DOM 基础)中已经掌握 Virtual DOM 渲染成真实的 DOM 实际上要经历 VNode 的定义、diff、patch 等过程,所以本章节 Vue 源码的解析也按这几个过程来简析。
VNode 模拟 DOM 树VNode 类简析在 Vue.js 中,Virtual DOM 是用 VNode 这个 Class 去描述,它定义在 src/core/vdom/vnode.js 中 ,从以下代码块中可以看到 Vue.js 中的 Virtual DOM 的定义较为复杂一些,因为它这里包含了很多 Vue.js 的特性。实际上 Vue.js 中 Virtual DOM 是借鉴了一个开源库 snabbdom 的实现,然后加入了一些 Vue.js 的一些特性。
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array<VNode>;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
// strictly internal
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
asyncFactory: Function | void; // async component factory function
asyncMeta: Object | void;
isAsyncPlaceholder: boolean;
ssrContext: Object | void;
fnContext: Component | void; // real context vm for functional nodes
fnOptions: ?ComponentOptions; // for SSR caching
devtoolsMeta: ?Object; // used to store functional render context for devtools
fnScopeId: ?string; // functional scope id support
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
this.context = context
this.fnContext = undefined
this.fnOptions = undefined
this.fnScopeId = undefined
this.key = data && data.key
this.componentOptions = componentOptions
this.componentInstance = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
this.isOnce = false
this.asyncFactory = asyncFactory
this.asyncMeta = undefined
this.isAsyncPlaceholder = false
}
}这里千万不要因为 VNode 的这么属性而被吓到,或者咬紧牙去摸清楚每个属性的意义,其实,我们主要了解其几个核心的关键属性就差不多了,例如:
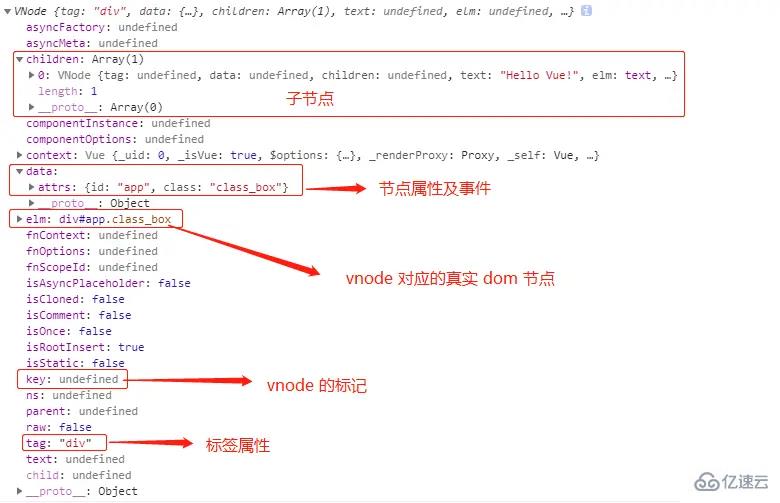
tag 属性即这个vnode的标签属性
data 属性包含了最后渲染成真实dom节点后,节点上的class,attribute,style以及绑定的事件
children 属性是vnode的子节点
text 属性是文本属性
elm 属性为这个vnode对应的真实dom节点
key 属性是vnode的标记,在diff过程中可以提高diff的效率
VNode 过程(1)初始化vue
我们在实例化一个 vue 实例,也即 new Vue( ) 时,实际上是执行 src/core/instance/index.js 中定义的 Function 函数。
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}通过查看 Vue 的 function,我们知道 Vue 只能通过 new 关键字初始化,然后调用 this._init 方法,该方法在 src/core/instance/init.js 中定义。
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// 省略一系列其它初始化的代码
if (vm.$options.el) {
console.log('vm.$options.el:',vm.$options.el);
vm.$mount(vm.$options.el)
}
}(2)Vue 实例挂载
Vue 中是通过 $mount 实例方法去挂载 dom 的,下面我们通过分析 compiler 版本的 mount 实现,相关源码在目录 src/platforms/web/entry-runtime-with-compiler.js 文件中定义:。
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && query(el)
// 省略一系列初始化以及逻辑判断代码
return mount.call(this, el, hydrating)
}我们发现最终还是调用用原先原型上的 $mount 方法挂载 ,原先原型上的 $mount 方法在 src/platforms/web/runtime/index.js 中定义 。
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && inBrowser ? query(el) : undefined
return mountComponent(this, el, hydrating)
}我们发现$mount 方法实际上会去调用 mountComponent 方法,这个方法定义在 src/core/instance/lifecycle.js 文件中
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 省略一系列其它代码
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
// 生成虚拟 vnode
const vnode = vm._render()
// 更新 DOM
vm._update(vnode, hydrating)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
return vm
}从上面的代码可以看到,mountComponent 核心就是先实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法,在此方法中调用 vm._render 方法先生成虚拟 Node,最终调用 vm._update 更新 DOM。
(3)创建虚拟 Node
Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中:
Vue.prototype._render = function (): VNode {
const vm: Component = this
const { render, _parentVnode } = vm.$options
let vnode
try {
// 省略一系列代码
currentRenderingInstance = vm
// 调用 createElement 方法来返回 vnode
vnode = render.call(vm._renderProxy, vm.$createElement)
} catch (e) {
handleError(e, vm, `render`){}
}
// set parent
vnode.parent = _parentVnode
console.log("vnode...:",vnode);
return vnode
}Vue.js 利用 _createElement 方法创建 VNode,它定义在 src/core/vdom/create-elemenet.js 中:
export function _createElement (
context: Component,
tag?: string | Class<Component> | Function | Object,
data?: VNodeData,
children?: any,
normalizationType?: number
): VNode | Array<VNode> {
// 省略一系列非主线代码
if (normalizationType === ALWAYS_NORMALIZE) {
// 场景是 render 函数不是编译生成的
children = normalizeChildren(children)
} else if (normalizationType === SIMPLE_NORMALIZE) {
// 场景是 render 函数是编译生成的
children = simpleNormalizeChildren(children)
}
let vnode, ns
if (typeof tag === 'string') {
let Ctor
ns = (context.$vnode && context.$vnode.ns) || config.getTagNamespace(tag)
if (config.isReservedTag(tag)) {
// 创建虚拟 vnode
vnode = new VNode(
config.parsePlatformTagName(tag), data, children,
undefined, undefined, context
)
} else if ((!data || !data.pre) && isDef(Ctor = resolveAsset(context.$options, 'components', tag))) {
// component
vnode = createComponent(Ctor, data, context, children, tag)
} else {
vnode = new VNode(
tag, data, children,
undefined, undefined, context
)
}
} else {
vnode = createComponent(tag, data, context, children)
}
if (Array.isArray(vnode)) {
return vnode
} else if (isDef(vnode)) {
if (isDef(ns)) applyNS(vnode, ns)
if (isDef(data)) registerDeepBindings(data)
return vnode
} else {
return createEmptyVNode()
}
}_createElement 方法有 5 个参数,context 表示 VNode 的上下文环境,它是 Component 类型;tag表示标签,它可以是一个字符串,也可以是一个 Component;data 表示 VNode 的数据,它是一个 VNodeData 类型,可以在 flow/vnode.js 中找到它的定义;children 表示当前 VNode 的子节点,它是任意类型的,需要被规范为标准的 VNode 数组;
为了更直观查看我们平时写的 Vue 代码如何用 VNode 类来表示,我们通过一个实例的转换进行更深刻了解。
例如,实例化一个 Vue 实例:
var app = new Vue({
el: '#app',
render: function (createElement) {
return createElement('div', {
attrs: {
id: 'app',
class: "class_box"
},
}, this.message)
},
data: {
message: 'Hello Vue!'
}
})我们打印出其对应的 VNode 表示:
diff 过程Vue.js 源码的 diff 调用逻辑Vue.js 源码实例化了一个 watcher,这个 ~ 被添加到了在模板当中所绑定变量的依赖当中,一旦 model 中的响应式的数据发生了变化,这些响应式的数据所维护的 dep 数组便会调用 dep.notify() 方法完成所有依赖遍历执行的工作,这包括视图的更新,即 updateComponent 方法的调用。watcher 和 updateComponent方法定义在 src/core/instance/lifecycle.js 文件中 。
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 省略一系列其它代码
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
// 生成虚拟 vnode
const vnode = vm._render()
// 更新 DOM
vm._update(vnode, hydrating)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
return vm
}完成视图的更新工作事实上就是调用了vm._update方法,这个方法接收的第一个参数是刚生成的Vnode,调用的vm._update方法定义在 src/core/instance/lifecycle.js中。
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this
const prevEl = vm.$el
const prevVnode = vm._vnode
const restoreActiveInstance = setActiveInstance(vm)
vm._vnode = vnode
if (!prevVnode) {
// 第一个参数为真实的node节点,则为初始化
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */)
} else {
// 如果需要diff的prevVnode存在,那么对prevVnode和vnode进行diff
vm.$el = vm.__patch__(prevVnode, vnode)
}
restoreActiveInstance()
// update __vue__ reference
if (prevEl) {
prevEl.__vue__ = null
}
if (vm.$el) {
vm.$el.__vue__ = vm
}
// if parent is an HOC, update its $el as well
if (vm.$vnode && vm.$parent && vm.$vnode === vm.$parent._vnode) {
vm.$parent.$el = vm.$el
}
}在这个方法当中最为关键的就是 vm.__patch__ 方法,这也是整个 virtual-dom 当中最为核心的方法,主要完成了prevVnode 和 vnode 的 diff 过程并根据需要操作的 vdom 节点打 patch,最后生成新的真实 dom 节点并完成视图的更新工作。
接下来,让我们看下 vm.__patch__的逻辑过程, vm.__patch__ 方法定义在 src/core/vdom/patch.js 中。
function patch (oldVnode, vnode, hydrating, removeOnly) {
......
if (isUndef(oldVnode)) {
// 当oldVnode不存在时,创建新的节点
isInitialPatch = true
createElm(vnode, insertedVnodeQueue)
} else {
// 对oldVnode和vnode进行diff,并对oldVnode打patch
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
}
......
}
}在 patch 方法中,我们看到会分为两种情况,一种是当 oldVnode 不存在时,会创建新的节点;另一种则是已经存在 oldVnode ,那么会对 oldVnode 和 vnode 进行 diff 及 patch 的过程。其中 patch 过程中会调用 sameVnode 方法来对对传入的2个 vnode 进行基本属性的比较,只有当基本属性相同的情况下才认为这个2个vnode 只是局部发生了更新,然后才会对这2个 vnode 进行 diff,如果2个 vnode 的基本属性存在不一致的情况,那么就会直接跳过 diff 的过程,进而依据 vnode 新建一个真实的 dom,同时删除老的 dom节点。
function sameVnode (a, b) {
return (
a.key === b.key &&
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
)
}diff 过程中主要是通过调用 patchVnode 方法进行的:
function patchVnode (oldVnode, vnode, insertedVnodeQueue, ownerArray, index, removeOnly) {
......
const elm = vnode.elm = oldVnode.elm
const oldCh = oldVnode.children
const ch = vnode.children
// 如果vnode没有文本节点
if (isUndef(vnode.text)) {
// 如果oldVnode的children属性存在且vnode的children属性也存在
if (isDef(oldCh) && isDef(ch)) {
// updateChildren,对子节点进行diff
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(ch)
}
// 如果oldVnode的text存在,那么首先清空text的内容,然后将vnode的children添加进去
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 删除elm下的oldchildren
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// oldVnode有子节点,而vnode没有,那么就清空这个节点
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
// 如果oldVnode和vnode文本属性不同,那么直接更新真是dom节点的文本元素
nodeOps.setTextContent(elm, vnode.text)
}
......
}从以上代码得知,
diff 过程中又分了好几种情况,oldCh 为 oldVnode的子节点,ch 为 Vnode的子节点:
首先进行文本节点的判断,若 oldVnode.text !== vnode.text,那么就会直接进行文本节点的替换;
在vnode 没有文本节点的情况下,进入子节点的 diff;
当 oldCh 和 ch 都存在且不相同的情况下,调用 updateChildren 对子节点进行 diff;
若 oldCh不存在,ch 存在,首先清空 oldVnode 的文本节点,同时调用 addVnodes 方法将 ch 添加到elm真实 dom 节点当中;
若 oldCh存在,ch不存在,则删除 elm 真实节点下的 oldCh 子节点;
若 oldVnode 有文本节点,而 vnode 没有,那么就清空这个文本节点。
diff 流程分析(1)Vue.js 源码
这里着重分析下updateChildren方法,它也是整个 diff 过程中最重要的环节,以下为 Vue.js 的源码过程,为了更形象理解 diff 过程,我们给出相关的示意图来讲解。
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 为oldCh和newCh分别建立索引,为之后遍历的依据
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// 直到oldCh或者newCh被遍历完后跳出循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldCh[idxInOld] = undefined
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}在开始遍历 diff 前,首先给 oldCh和 newCh 分别分配一个 startIndex 和 endIndex 来作为遍历的索引,当oldCh 或者 newCh 遍历完后(遍历完的条件就是 oldCh 或者 newCh 的 startIndex >= endIndex ),就停止oldCh 和 newCh 的 diff 过程。接下来通过实例来看下整个 diff 的过程(节点属性中不带 key 的情况)。
(2)无 key 的 diff 过程
我们通过以下示意图对以上代码过程进行讲解:
(2.1)首先从第一个节点开始比较,不管是 oldCh 还是 newCh 的起始或者终止节点都不存在 sameVnode ,同时节点属性中是不带 key标记的,因此第一轮的 diff 完后,newCh的 startVnode 被添加到 oldStartVnode的前面,同时 newStartIndex前移一位;

(2.2)第二轮的 diff中,满足 sameVnode(oldStartVnode, newStartVnode),因此对这2个 vnode 进行diff,最后将 patch 打到 oldStartVnode 上,同时 oldStartVnode和 newStartIndex 都向前移动一位 ;
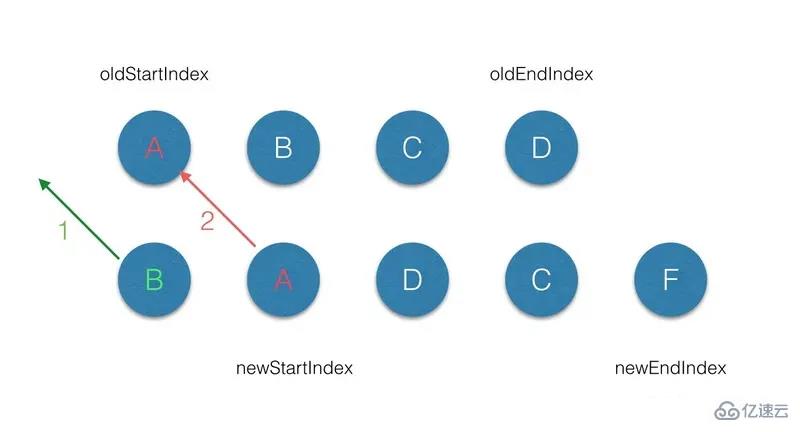
(2.3)第三轮的 diff 中,满足 sameVnode(oldEndVnode, newStartVnode),那么首先对 oldEndVnode和newStartVnode 进行 diff,并对 oldEndVnode进行 patch,并完成 oldEndVnode 移位的操作,最后newStartIndex前移一位,oldStartVnode 后移一位;
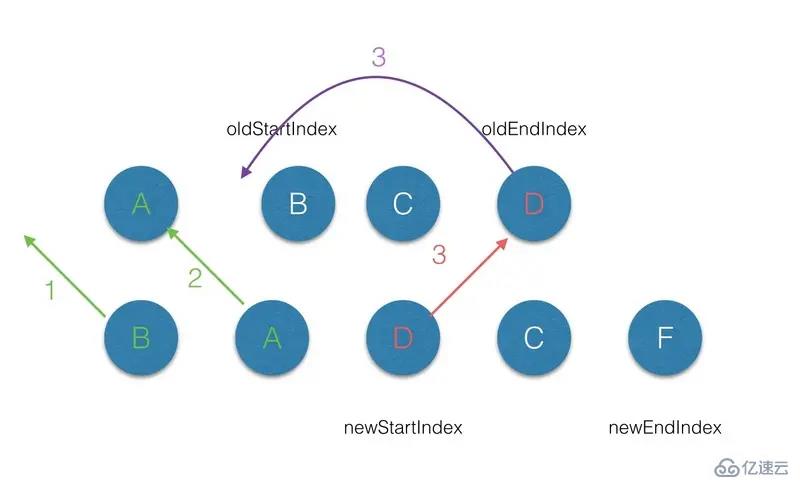
(2.4)第四轮的 diff中,过程同步骤3;
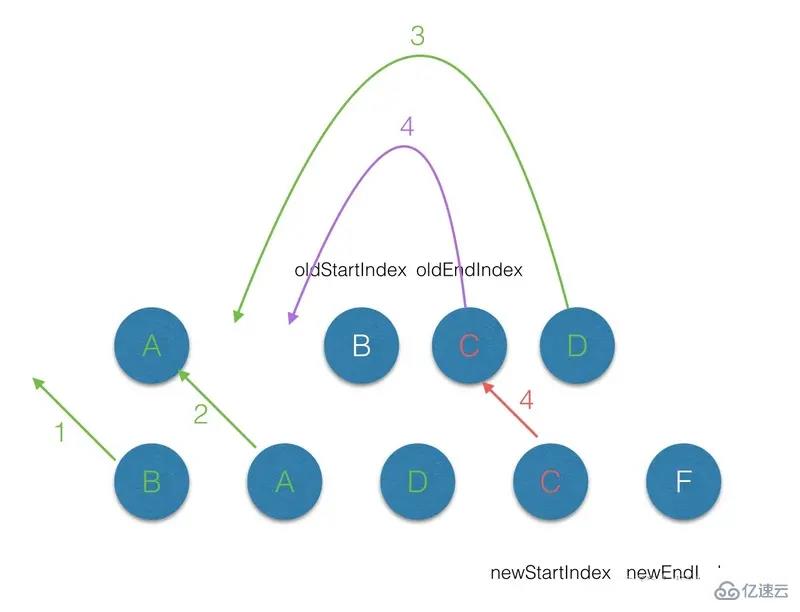
(2.5)第五轮的 diff 中,同过程1;

(2.6)遍历的过程结束后,newStartIdx > newEndIdx,说明此时 oldCh 存在多余的节点,那么最后就需要将这些多余的节点删除。
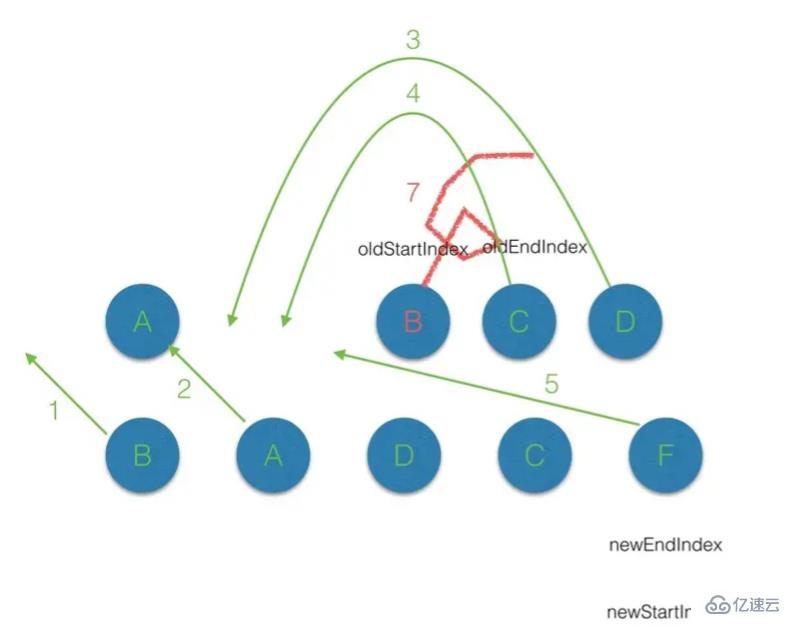
(3)有 key 的 diff 流程
在 vnode 不带 key 的情况下,每一轮的 diff 过程当中都是起始和结束节点进行比较,直到 oldCh 或者newCh 被遍历完。而当为 vnode 引入 key 属性后,在每一轮的 diff 过程中,当起始和结束节点都没有找到sameVnode 时,然后再判断在 newStartVnode 的属性中是否有 key,且是否在 oldKeyToIndx 中找到对应的节点 :
如果不存在这个 key,那么就将这个 newStartVnode作为新的节点创建且插入到原有的 root 的子节点中;
如果存在这个 key,那么就取出 oldCh 中的存在这个 key 的 vnode,然后再进行 diff 的过;
通过以上分析,给vdom上添加 key属性后,遍历 diff 的过程中,当起始点,结束点的搜寻及 diff 出现还是无法匹配的情况下时,就会用 key 来作为唯一标识,来进行 diff,这样就可以提高 diff 效率。
带有 Key属性的 vnode的 diff 过程可见下图:
(3.1)首先从第一个节点开始比较,不管是 oldCh 还是 newCh 的起始或者终止节点都不存在 sameVnode,但节点属性中是带 key 标记的, 然后在 oldKeyToIndx 中找到对应的节点,这样第一轮 diff 过后 oldCh 上的B节点被删除了,但是 newCh 上的B节点上 elm 属性保持对 oldCh 上 B节点 的elm引用。
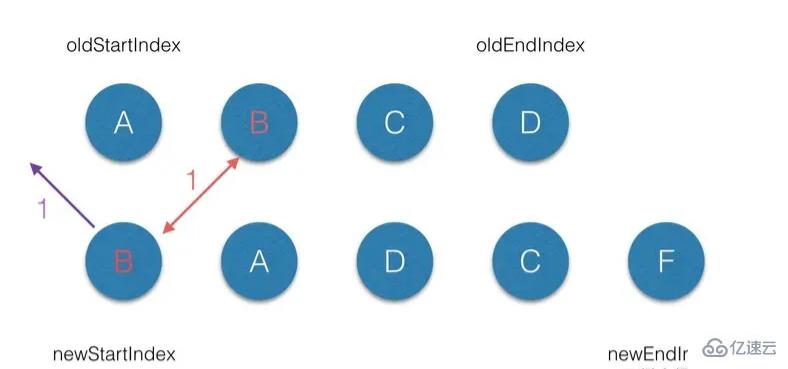
(3.2)第二轮的 diff 中,满足 sameVnode(oldStartVnode, newStartVnode),因此对这2个 vnode 进行diff,最后将 patch 打到 oldStartVnode上,同时 oldStartVnode 和 newStartIndex 都向前移动一位 ;
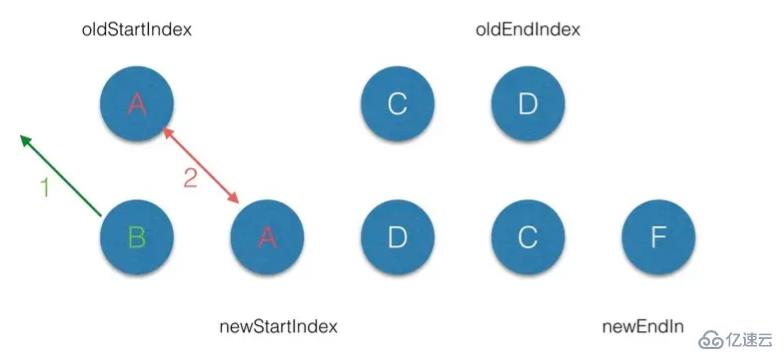
(3.3)第三轮的 diff中,满足 sameVnode(oldEndVnode, newStartVnode),那么首先对 oldEndVnode 和newStartVnode 进行 diff,并对 oldEndVnode 进行 patch,并完成 oldEndVnode 移位的操作,最后newStartIndex 前移一位,oldStartVnode后移一位;
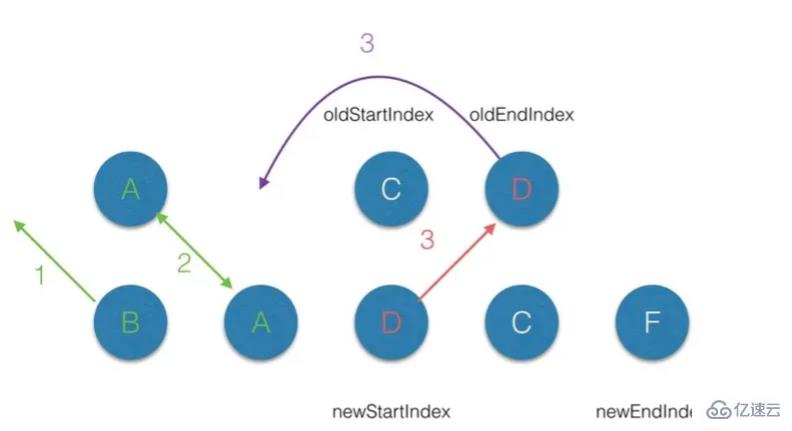
(3.4)第四轮的diff中,过程同步骤2;
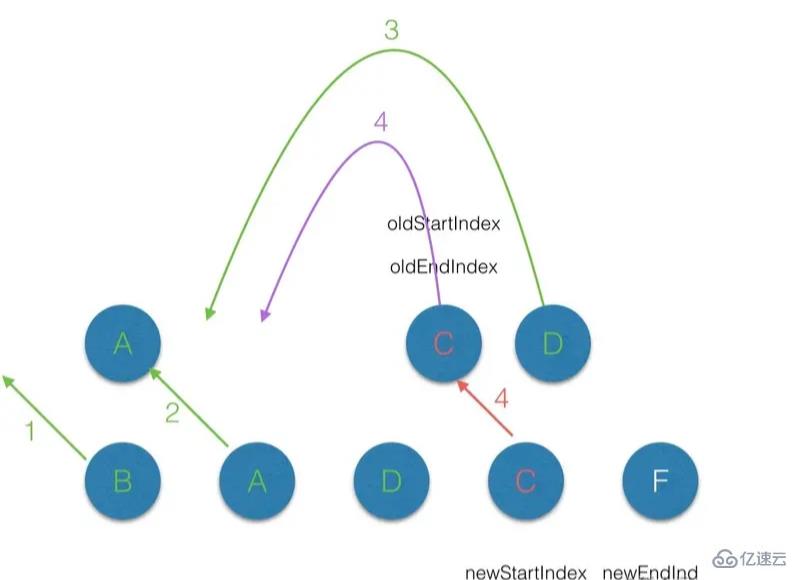
(3.5)第五轮的diff中,因为此时 oldStartIndex 已经大于 oldEndIndex,所以将剩余的 Vnode 队列插入队列最后。
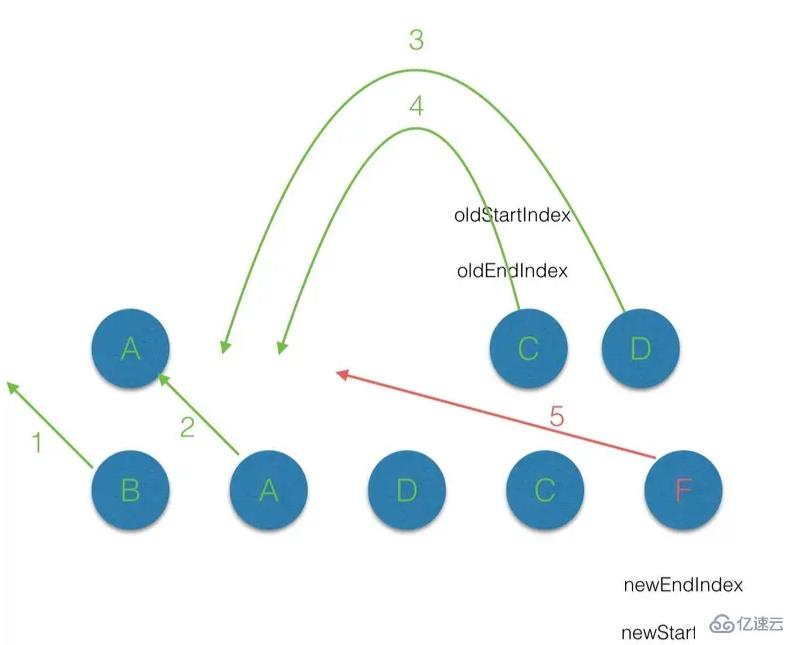
patch 过程通过3.2章节介绍的 diff 过程中,我们会看到 nodeOps 相关的方法对真实 DOM 结构进行操作,nodeOps 定义在 src/platforms/web/runtime/node-ops.js 中,其为基本 DOM 操作,这里就不在详细介绍。
export function createElementNS (namespace: string, tagName: string): Element {
return document.createElementNS(namespaceMap[namespace], tagName)
}
export function createTextNode (text: string): Text {
return document.createTextNode(text)
}
export function createComment (text: string): Comment {
return document.createComment(text)
}
export function insertBefore (parentNode: Node, newNode: Node, referenceNode: Node) {
parentNode.insertBefore(newNode, referenceNode)
}
export function removeChild (node: Node, child: Node) {
node.removeChild(child)
}关于“Vue中的虚拟DOM如何构建”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Vue中的虚拟DOM如何构建”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



