本篇内容主要讲解“怎么使用Python实现数据清洗”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么使用Python实现数据清洗”吧!
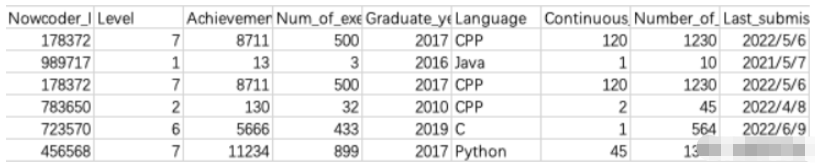
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
运营同学正在做用户调研,为了保证调研的可靠性,想要去掉那些信息不全的用户,即去掉有缺失数据的行,请你帮助他去掉后输出全部数据。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
直接输出清洗后的全部数据。

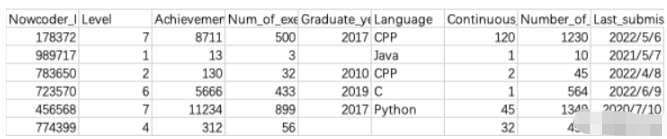
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder[Nowcoder.isna() == False])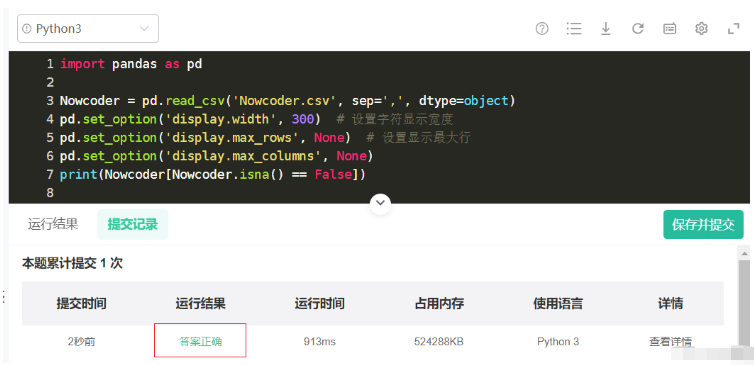
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
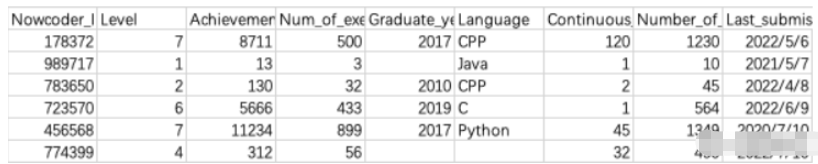
运营同学拿到了这份用户文件,但是由于系统BUG,出现了部分缺失的值,请你使用当前的最大年份填充缺失的毕业年份(“Graduate_year”),用Python填充缺失的常用语言(“Language”),用成就值的均值(四舍五入保留整数)填充缺失的成就值(“Achievement_value”)。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出修改后的全部数据,不用处理输出时年份与成就值的小数点问题。

import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
Nowcoder["Graduate_year"].fillna(Nowcoder["Graduate_year"].max())
Nowcoder["Language"].fillna("Python")
Nowcoder["Achievement_value"].fillna(Nowcoder["Achievement_value"].mean().round(0))
print(Nowcoder)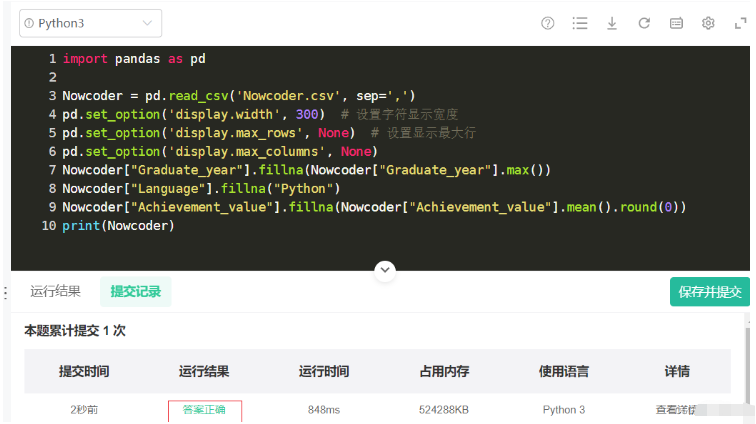
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
牛牛拿到这份文件的时候一脸懵逼,因为系统错误将很多相同用户的数据输出了多条,导致文件中有很多重复的行,请先检查每一行是否重复,然后输出删除重复行后的全部数据。
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述
先输出每一行是否重复,再输出去重后的文件全部数据
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 1000)
pd.set_option('display.max_rows', None)
print(Nowcoder.duplicated())
print(Nowcoder.drop_duplicates(0))
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
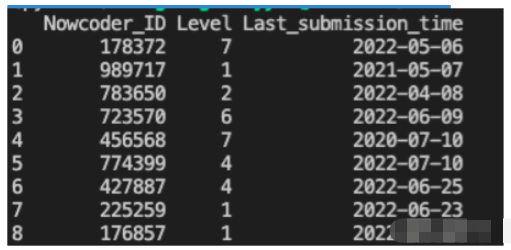
运营同学发现最后一次提交题目日期这一列有各种各样的日期格式,这对于他分析用户十分不友好,你能够帮他输出用户ID、等级以及统一后的日期吗?(日期格式统一为yyyy-mm-dd)
输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。

输出描述
输出用户ID、等级与最后提交日期三列,包括行号。
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
Nowcoder['Last_submission_time'] = pd.to_datetime(Nowcoder["Last_submission_time"],format="%Y-%m-%d")
print(Nowcoder[['Nowcoder_ID','Level','Last_submission_time']])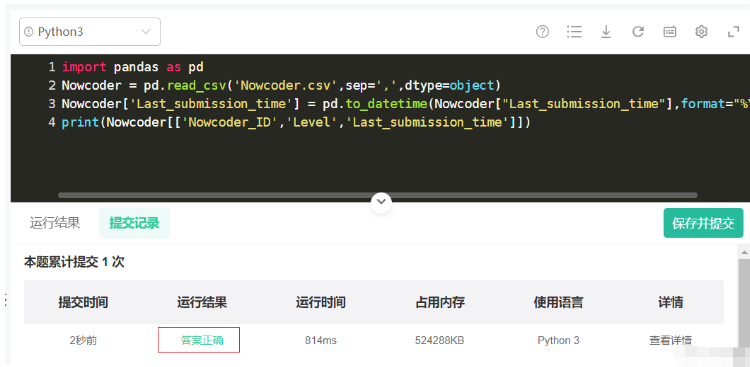
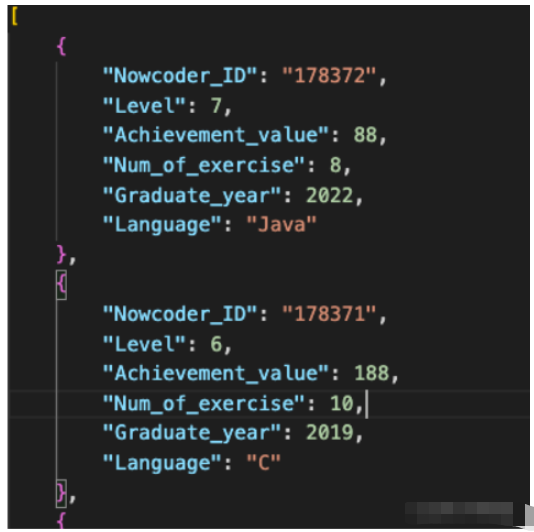
现有一个Nowcoder.json文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Graduate_year:毕业年份
Language:常用语言
如果你读入了这个json文件,能将其转换为pandas的DataFrame格式吗?
输入描述:
数据集直接从当前目录下的Nowcoder.json文件中读取。
输出描述:
输出转换为DataFrame的全部数据,包括行号。

import pandas as pd
import json
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
with open('Nowcoder.json', 'r') as f:
data = json.loads(f.read())
df = pd.DataFrame.from_dict(data)
print(df)
到此,相信大家对“怎么使用Python实现数据清洗”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





