本文小编为大家详细介绍“pandas怎么处理数据中的缺失值和重复值”,内容详细,步骤清晰,细节处理妥当,希望这篇“pandas怎么处理数据中的缺失值和重复值”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
pandas对大数据有很多便捷的清洗用法,尤其针对缺失值和重复值。缺失值就不用说了,会影响计算,重复值有时候可能并未带来新的信息反而增加了计算量,所以有时候要进行处理。针对一些文本数据可能不合要求的还要进行替换什么的。
首先导入包:
import numpy as np
import pandas as pd'''一般使用特殊类型 NaN 代表缺失值,可以用 Numpy 可定义它np.NaN/np.nan。在 Pandas 1.0 以后实验性地使用一个标量 pd.NA 来代表。
如果想把正负无穷也为认是缺失值,可以通过以下全局配置来设定:'''
pandas.options.mode.use_inf_as_na = True
#以下数据 NaN 为缺失值:
df=(pd.DataFrame(np.random.randn(5, 3),index=['a', 'c', 'e', 'f', 'h'], columns=['one', 'two', 'three'])
.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']))
df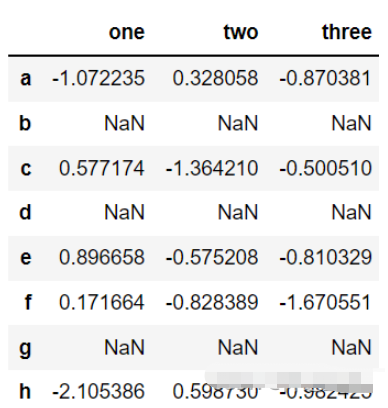
#可以判断是否缺失值,DataFrame 和 Series 一般都支持。:
# 不是缺失值
df.one.notna()
df.isna() # 是缺失值
df[df.one.notna()]# 进行筛选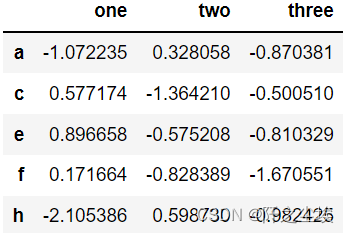
#需要注意的是,Numpy 中 np.nan 和 np.nan 不相等,因此不能用 ==/!= 进行对比:
None == None # noqa: E711 # True
np.nan == np.nan # False
None == np.nan # False其他方法:
df.notna()
df['team'].isna()
df['team'].isnull()df.isnull().sum()#计算每列缺失值个数
df.isnull().sum(1)#计算每行缺失值个数
df.isnull().sum().sum()#总共缺失值个数df.loc[df.isna().any(1)]# 有缺失值的行
df.loc[:,df.isna().any()] # 有缺失值的列
df.loc[~(df.isna().any(1))] # 没有缺失值的行
df.loc[:,~(df.isna().any())] # 没有缺失值的列#时间中的缺失值
#对于时间中的缺失值,Pandas 提供了一个 NaT 来表示,并且 NaT 和 NaN 之间是兼容的:
df['timestamp'] = pd.Timestamp('20120101')
df.loc[['a', 'c', 'h'], ['one', 'timestamp']] = np.nan
df.timestamp
#整型中的缺失值,由于 NaN 是浮点型,因此一列甚至缺少一个整数的整数列都将转换为浮点。
pd.Series([1, 2, np.nan, 4], dtype=pd.Int64Dtype())
#可以使用 None 等方法将内容修改为缺失值:
s.loc[0] = None
s.loc[1] = np.nan
df.two = pd.NA首先生成案例数据:
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
df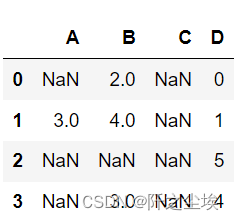
fillna(x) 可以将缺失值填充指定的值。以下为几种常见的填充方法:
df.fillna(0)# 填充为 0
# 填充为指定字符
df.fillna('missing')
df.fillna('暂无')
df.fillna('待补充')
df.one.fillna('暂无') # 指定字段填充
df.one.fillna(0, inplace=Ture) # 使填充内容生效
df.fillna(0, limit=1) # 只替换第一个
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3} # 不同列替换不同的值
df.fillna(value=values)不指定值,使用一定的方法。
#使用 method{‘backfill', ‘bfill', ‘pad', ‘ffill', None}, default None
df.fillna(method='backfill')# 使用上一个有效值填充
df.fillna(method='bfill')# 同 backfill
df.fillna(method='pad')# 把当前值广播到后边的缺失值
df.fillna(method='ffill')# 同 pad
#fillna(method='ffill') 可以简写为 ffill() , fillna(method='bfill') 可以简写为 bfill()使用计算值填充:
# 填充列的平均值
df.fillna(df.mean())
# 对指定列填充平均值
df.fillna(df.mean()['B':'C'])
# 填充列的平均值,另外一个方法
df.where(pd.notna(df), df.mean(), axis='columns')
#特别的计算:
# 第一个非空值
df.fillna(method='bfill').head(1).iloc[0]
# 第一个非空值索引
df.notna().idxmax()
df.apply(pd.Series.first_valid_index)插值方式,以下是一个非常简单的示例,其中一个值是缺失的,我们对它进行差值:
s = pd.Series([0, 1,4,9, np.nan, 25]) s.interpolate()
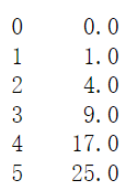
9和25之间的中间点为17,就把缺失值补为了17,这是线性插值。
s.interpolate(method='spline',order=2)
这是二级多项式插值。用X^2这个函数去插值的,
'''默认linear 方法,会认为是一条直线。
计算方法:
默认 method=‘linear’ 如果你的数据增长速率越来越快,可以选择 method='quadratic' 二次插值。如果数据集呈现出累计分布的样子,
推荐选择 method='pchip'。如果需要填补缺省值,以平滑绘图为目标,推荐选择 method='akima'。method='akima' 和 method = ‘pchip’,
需要你的环境中安装了 Scipy 库。除此之外,method='barycentric' 和 method='pchip' 同样也需要 Scipy 才能使用。
使用插值方法,可为:
linear:线性,忽略索引,并将值等距地对待,这是MultiIndexes支持的唯一方法
time:时间,以插值给定的时间间隔长度处理每日或更高粒度的数据
index, values:索引,值,使用索引的实际数值
pad:使用现有值填写NaN。
‘nearest’, ‘zero’, ‘slinear’, ‘quadratic’, ‘cubic’, ‘spline’, ‘barycentric’, ‘polynomial’:
传递给 scipy.interpolate.interp1d,这些方法使用索引的数值。 ‘polynomial’ 和 ‘spline’ 都要求您还指定一个顺序(int),
例如 df.interpolate(method='polynomial',order=5)
nearest:最近
zero:零
slinear:线性
quadratic:二次方
cubic:立方
spline:花键,样条插值
barycentric:重心插值
polynomial:多项式
‘krogh’, ‘piecewise_polynomial’, ‘spline’, ‘pchip’, ‘akima’: SciPy 类似名称的插值方法。
krogh: 克罗格插值
piecewise_polynomial: 分段多项式
spline: 样条插值
pchip: 立方插值 (累计分布)
akima: 阿克玛插值 (平滑绘图)
from_derivatives:指 scipy.interpolate.BPoly.from_derivatives,它替换了 scipy 0.18 中的 piecewise_polynomial 插值方法。
其他参数:
axis: 插值应用的轴方向,可选择 {0 or ‘index’, 1 or ‘columns’, None}, 默认为 None
limitint: 要填充的连续 NaN 的最大数量, 必须大于 0。
inplace: 是否将最终结果替换原数据,默认为 False
limit_direction: 限制方向,可传入 {‘forward’, ‘backward’, ‘both’}, 默认 ‘forward’,如果指定了限制,则将沿该方向填充连续的 NaN
limit_area: 限制区域,可传入 {None, ‘inside’, ‘outside’}, 默认 None,如果指定了限制,则连续的NaN将被此限制填充
None: 没有填充限制
‘inside’: 仅填充有效值包围的NaN(内插)
‘outside’: 仅将NaN填充到有效值之外(外推)
downcast: 可传入‘infer’ 或者 None, 默认是 None,如果可以向下转换 dtypes
**kwargs: 传递给插值函数的关键字参数 '''
生成案例数据:
#一般删除会针对行进行,如一行中有缺失值就会删除,当然也会有针对列的。
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),
pd.NaT]})
df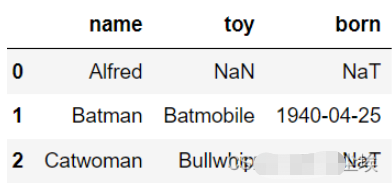
# 删除所有有缺失值的行(有一个缺失就删除)
df.dropna()
# 删除所有有缺失值的列
df.dropna(axis='columns')
df.dropna(axis=1)
# 删除所有值都缺失的行
df.dropna(how='all')
# 不足2个非空值时删除
df.dropna(thresh=2)
# 指定判断缺失值的列范围
df.dropna(subset=['name', 'born'])
# 使删除和的结果生效
df.dropna(inplace=True)
# 指定列的缺失值删除
df.toy.dropna()重复值的寻找主要使用duplicated,语法为:
df.duplicated(subset=None, keep='first')'''可以返回表示重复行的布尔系列,可以指定列。keep参数确定要标记的重复项(如果有),选项有:
first:将除第一次出现的重复值标记为True,默认。
last:将除最后一次出现的重复值标记为True。
False:将所有重复值标记为True。'''
生成案例数据:
df = pd.DataFrame({'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5] })
df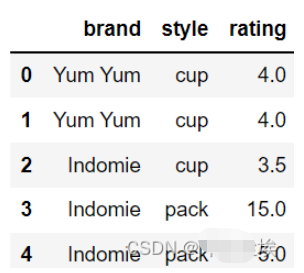
#默认情况下,对于每组重复的值,第一次出现都设置为False,所有其他值设置为True。
df.duplicated()
通过使用“ last”,将每组重复值的最后一次出现设置为False,将所有其他重复值设置为True。
df.duplicated(keep='last')
#通过将keep设置为False,所有重复项都为True。
df.duplicated(keep='last')
要在特定列上查找重复项,请使用子集。
df.duplicated(keep=False)
'''删除重复值的语法为:
df.drop_duplicates(subset=None,
keep='first',
inplace=False,
ignore_index=False)subset指定的标签或标签序列可选,仅删除某些列重复项,默认情况为使用所有列,其他有:
keep:确定要保留的重复项(如果有)
first : 保留第一次出现的重复项,默认
last : 保留最后一次出现的重复项。
False : 删除所有重复项
inplac:False,是将副本放置在适当位置还是返回副本
ignore_inde:如果为True, 则重新分配自然索引(0, 1, …, n - 1)'''
df.drop_duplicates()#默认情况下,它将基于所有列删除重复的行。
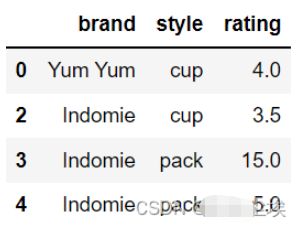
df.drop_duplicates(subset=['brand'])#要删除特定列上的重复项,使用子集
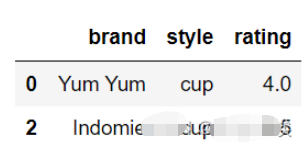
df.drop_duplicates(subset=['brand', 'style'], keep='last')#删除重复项并保留最后一次出现,请使用keep。

语法
df.drop(labels=None,axis=0,index=None,columns=None,level=None,inplace=False,errors='raise')labels表示要删除的行或者列,多个可以传入列表:
axis:表示轴方向,默认0(行)
index:指定一行或多行
columns:指定列
level:指定多层索引
inplace:立即修改
df.drop([2,4])#删除指定行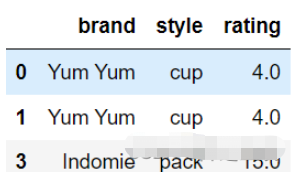
df.drop(['brand','rating'],axis=1)#删除指定列
df.drop(columns=['brand','rating'])#同上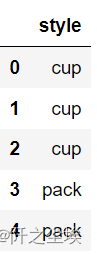
有时候想把数据替换为指定的值,空值缺失值都可以替换
#指定值替换,以下是在 Series 中将 0 替换为 5:
ser = pd.Series([0., 1., 2., 3., 4.])
ser.replace(0, 5)
#也可以批量替换:
# 一一对应进行替换
ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0])
# 用字典映射对应替换值
ser.replace({0: 10, 1: 100})
# 将 a 列的 0 b 列中的 5 替换为 100
df.replace({'a': 0, 'b': 5}, 100)
# 指定列里的替换规划
df.replace({'a': {0: 100, 4: 400}})除了给定指定值进行替换,我们还可以指定一些替换的方法:
# 将 1,2,3 替换为它们前一个值(0)
ser.replace([1, 2, 3], method='pad') # ffill 是它同义词
# 将 1,2,3 替换为它们后一个值(4)
ser.replace([1, 2, 3], method='bfill')#如果遇到字符比较复杂的内容,就是使用正则(默认没有开启)进行匹配:
# 把 bat 替换为 new
df.replace(to_replace='bat', value='new')
# 利用正则将 ba 开头的替换为 new
df.replace(to_replace=r'^ba.$', value='new', regex=True)
# 如果多列规则不一的情况下可以按以下格式对应传入
df.replace({'A': r'^ba.$'}, {'A': 'new'}, regex=True)
# 多个规则替换为同一个值
df.replace(regex=[r'^ba.$', 'foo'], value='new')
# 直接多个正则及对应的替换内容
df.replace(regex={r'^ba.$': 'new', 'foo': 'xyz'})替换可以处理缺失值相关的问题,如我们可以将无效的值先替换为 nan,再做缺失值处理:
生成案例数据‘
d = {'a': list(range(4)),
'b': list('ab..'),
'c': ['a', 'b', np.nan, 'd']}
df = pd.DataFrame(d)
df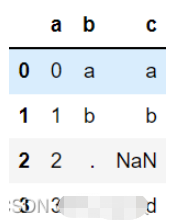
一些用法:
# 将.替换为 nan,(也可以替换为 None)
df.replace('.', np.nan)
# 使用正则,将空格和点等替换为 nan
df.replace(r'\s*\.\s*', np.nan, regex=True)
# 对应替换,a 换 b, 点换 nan
df.replace(['a', '.'], ['b', np.nan])
# 点换 dot, a 换 astuff (第一位+)
df.replace([r'\.', r'(a)'], ['dot', r'\1stuff'], regex=True)
# b 中的点要替换,替换为 b 替换规则为 nan,可以多列
df.replace({'b': '.'}, {'b': np.nan})
# 使用正则
df.replace({'b': r'\s*\.\s*'}, {'b': np.nan}, regex=True)
# b列的 b 值换为空
df.replace({'b': {'b': r''}}, regex=True)
# b 列的点空格等换 nan
df.replace(regex={'b': {r'\s*\.\s*': np.nan}})
# b列点等+ty
df.replace({'b': r'\s*(\.)\s*'},
{'b': r'\1ty'},regex=True)
# 多个正则规则(a,b,. 都换为缺失)
df.replace([r'\s*\.\s*', r'a|b'], np.nan, regex=True)
# 用参数名传参
df.replace(regex=[r'\s*\.\s*', r'a|b'], value=np.nan)生成数据:
df = pd.DataFrame(np.random.randn(5, 2))
df[np.random.rand(df.shape[0]) > 0.5] = 1.5
df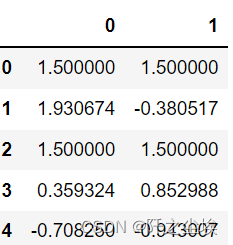
# 将 1.5 替换为 nan
df.replace(1.5, np.nan)
# 将1.5换为 nan, 同时于左上角的值换为 a
df.replace([1.5, df.iloc[0, 0]], [np.nan, 'a'])
# 使替换生效
df.replace(1.5, np.nan, inplace=True)#对一些极端值,如过大或者过小,可以使用 df.clip(lower, upper) 来修剪,当数据大于 upper 时,使用 upper 的值,
#小于 lower 时用 lower 的值,就像 numpy.clip 方法一样。
df = pd.DataFrame({'a': [-1, 2, 5], 'b': [6, 1, -3]})
df
修剪成最大为3最小为0
df.clip(0,3)
用来处理数据里面的异常值什么的还是很方便的。
读到这里,这篇“pandas怎么处理数据中的缺失值和重复值”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


