这篇文章主要讲解了“MySQL中流式查询及游标查询的方式是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“MySQL中流式查询及游标查询的方式是什么”吧!

现在业务系统需要从 MySQL 数据库里读取 500w 数据行进行处理
迁移数据
导出数据
批量处理数据
常规查询:一次性读取 500w 数据到 JVM 内存中,或者分页读取
流式查询:每次读取一条加载到 JVM 内存进行业务处理
游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据
默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,更易于实现。
假设单表 500w 数据量,没有人会一次性加载到内存中,一般会采用分页的方式。
在这里,测试demo中只是为了监控JVM,所以没有采用分页,一次性将数据载入内存中
@Test
public void generalQuery() throws Exception {
// 1核2G:查询一百条记录:47ms
// 1核2G:查询一千条记录:2050 ms
// 1核2G:查询一万条记录:26589 ms
// 1核2G:查询五万条记录:135966 ms
String sql = "select * from wh_b_inventory limit 10000";
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
我们将对内存调小-Xms70m -Xmx70m
整个查询过程中,堆内存占用逐步增长,并且最终导致OOM:
java.lang.OutOfMemoryError: GC overhead limit exceeded
1、频繁触发GC
2、存在OOM隐患
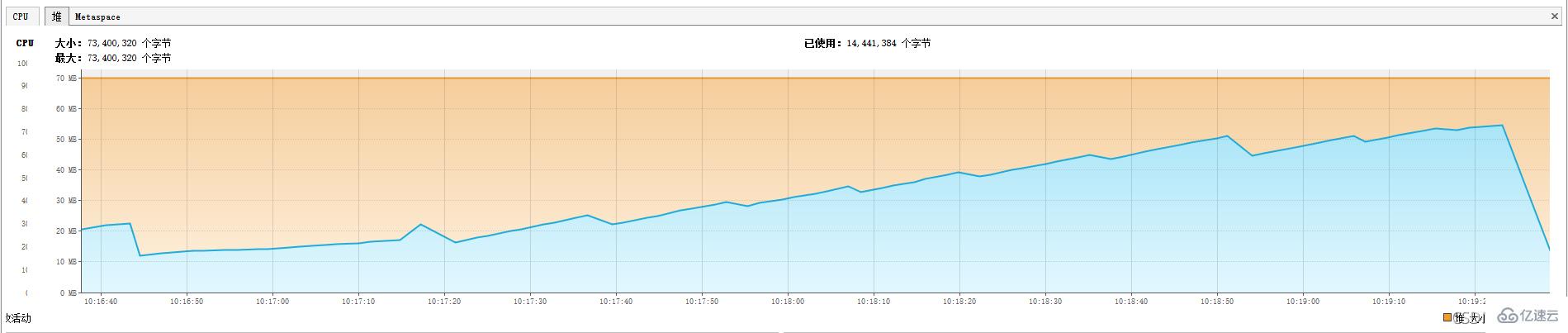
流式查询有一点需要注意:必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常,其 查询会独占连接。
从测试结果来看,流式查询并没有提升查询的速度
@Test
public void streamQuery() throws Exception {
// 1核2G:查询一百条记录:138ms
// 1核2G:查询一千条记录:2304 ms
// 1核2G:查询一万条记录:26536 ms
// 1核2G:查询五万条记录:135931 ms
String sql = "select * from wh_b_inventory limit 50000";
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
我们将堆内存调小-Xms70m -Xmx70m
我们发现即使堆内存只有70m,却依然没有发生OOM
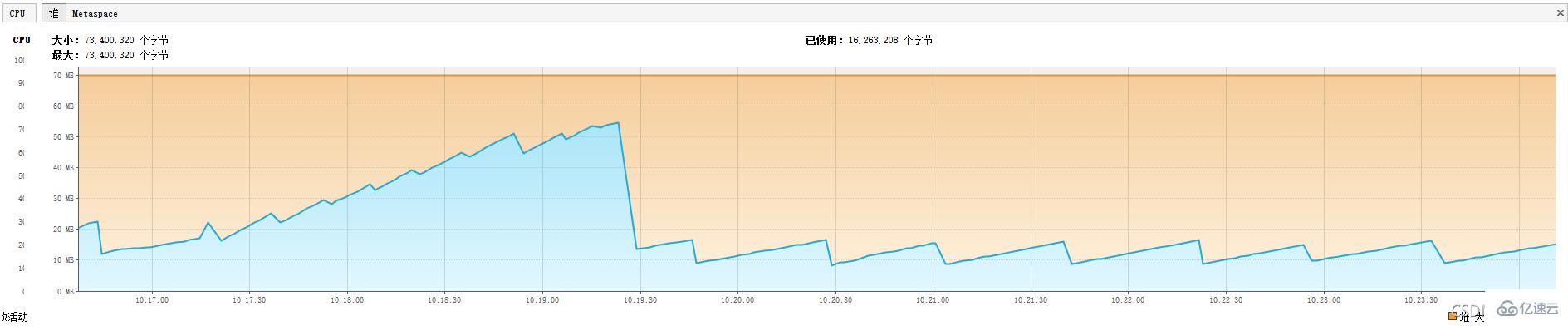
注意:
1、需要在数据库连接信息里拼接参数 useCursorFetch=true
2、其次设置 Statement 每次读取数据数量,比如一次读取 1000
从测试结果来看,游标查询在一定程度缩短了查询速度
@Test
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://101.34.50.82:3306/mysql-demo?useCursorFetch=true", "root", "123456");
start = System.currentTimeMillis();
// 1核2G:查询一百条记录:52 ms
// 1核2G:查询一千条记录:1095 ms
// 1核2G:查询一万条记录:17432 ms
// 1核2G:查询五万条记录:90244 ms
String sql = "select * from wh_b_inventory limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
我们将堆内存调小-Xms70m -Xmx70m
我们发现在单线程情况下,游标查询和流式查询一样,都能很好的规避OOM,并且游标查询能够优化查询速度。
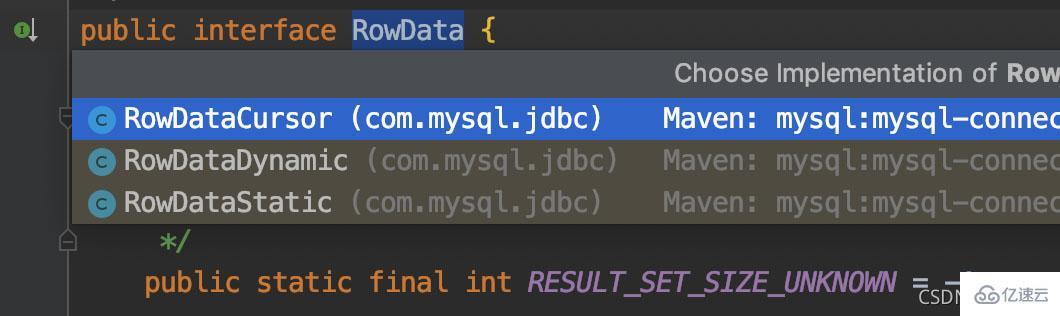
ResultSet.next() 的逻辑是实现类 ResultSetImpl 每次都从 RowData 获取下一行的数据。RowData 是一个接口,实现关系图如下
默认情况下 ResultSet 会使用 RowDataStatic 实例,在生成 RowDataStatic 对象时就会把 ResultSet 中所有记录读到内存里,之后通过 next() 再一条条从内存中读
当采用流式处理时,ResultSet 使用的是 RowDataDynamic 对象,而这个对象 next() 每次调用都会发起 IO 读取单行数据
RowDataCursor 的调用为批处理,然后进行内部缓存,流程如下:
首先会查看自己内部缓冲区是否有数据没有返回,如果有则返回下一行
如果都读取完毕,向 MySQL Server 触发一个新的请求读取 fetchSize 数量结果
并将返回结果缓冲到内部缓冲区,然后返回第一行数据
总结来说就是:
默认的 RowDataStatic 读取全部数据到客户端内存中,也就是我们的 JVM;
RowDataDynamic 每次 IO 调用读取一条数据;
RowDataCursor 一次读取 fetchSize 行,消费完成再发起请求调用。
在 JDBC 与 MySQL 服务端的交互是通过 Socket 完成的,对应到网络编程,可以把 MySQL 当作一个 SocketServer,因此一个完整的请求链路应该是:
JDBC 客户端 -> 客户端 Socket -> MySQL -> 检索数据返回 -> MySQL 内核 Socket Buffer -> 网络 -> 客户端 Socket Buffer -> JDBC 客户端
普通查询会将当次查询到的所有数据加载到JVM,然后再进行处理。
如果查询数据量过大,会不断经历 GC,然后就是内存溢出
服务端准备好从第一条数据开始返回时,向缓冲区怼入数据,这些数据通过TCP链路,怼入客户端机器的内核缓冲区,JDBC会的inputStream.read()方法会被唤醒去读取数据,唯一的区别是开启了stream读取的时候,每次只是从内核中读取一个package大小的数据,只是返回一行数据,如果1个package无法组装1行数据,会再读1个package。
当开启游标的时候,服务端返回数据的时候,就会按照fetchSize的大小返回数据了,而客户端接收数据的时候每次都会把换缓冲区数据全部读取干净,假如数据有1亿数据,将FetchSize设置成1000的话,会进行10万次来回通信;
由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时空间来存放需要拿走的数据。
因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
1.IOPS飙升
2.磁盘空间飙升
3.客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数据
4.在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS由“读写”转变为“读取”。
IOPS (Input/Output Per Second):磁盘每秒的读写次数
5.CPU和内存会有一定比例的上升
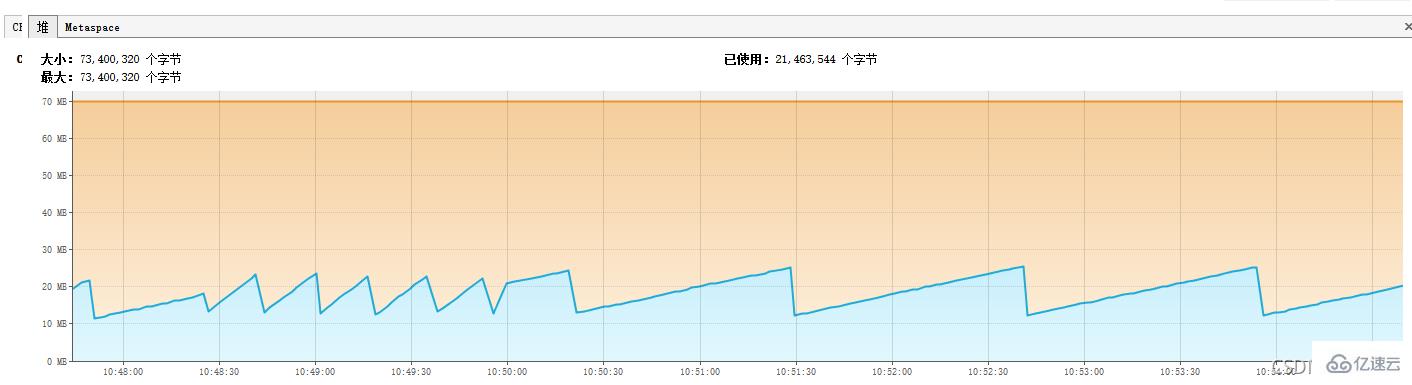
并发调用:Jmete 1 秒 10 个线程并发调用
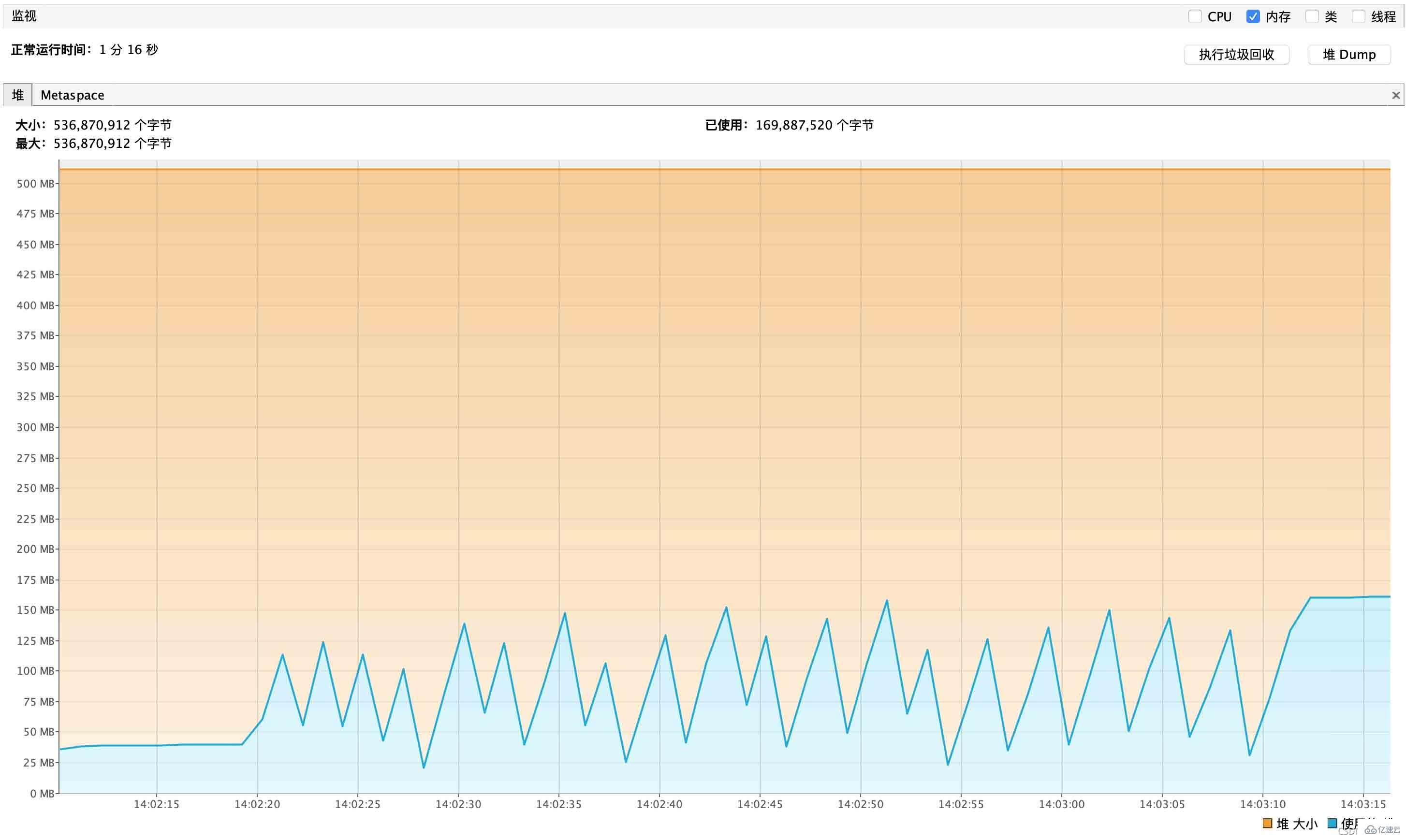
流式查询内存性能报告如下
并发调用对于内存占用情况也很 OK,不存在叠加式增加
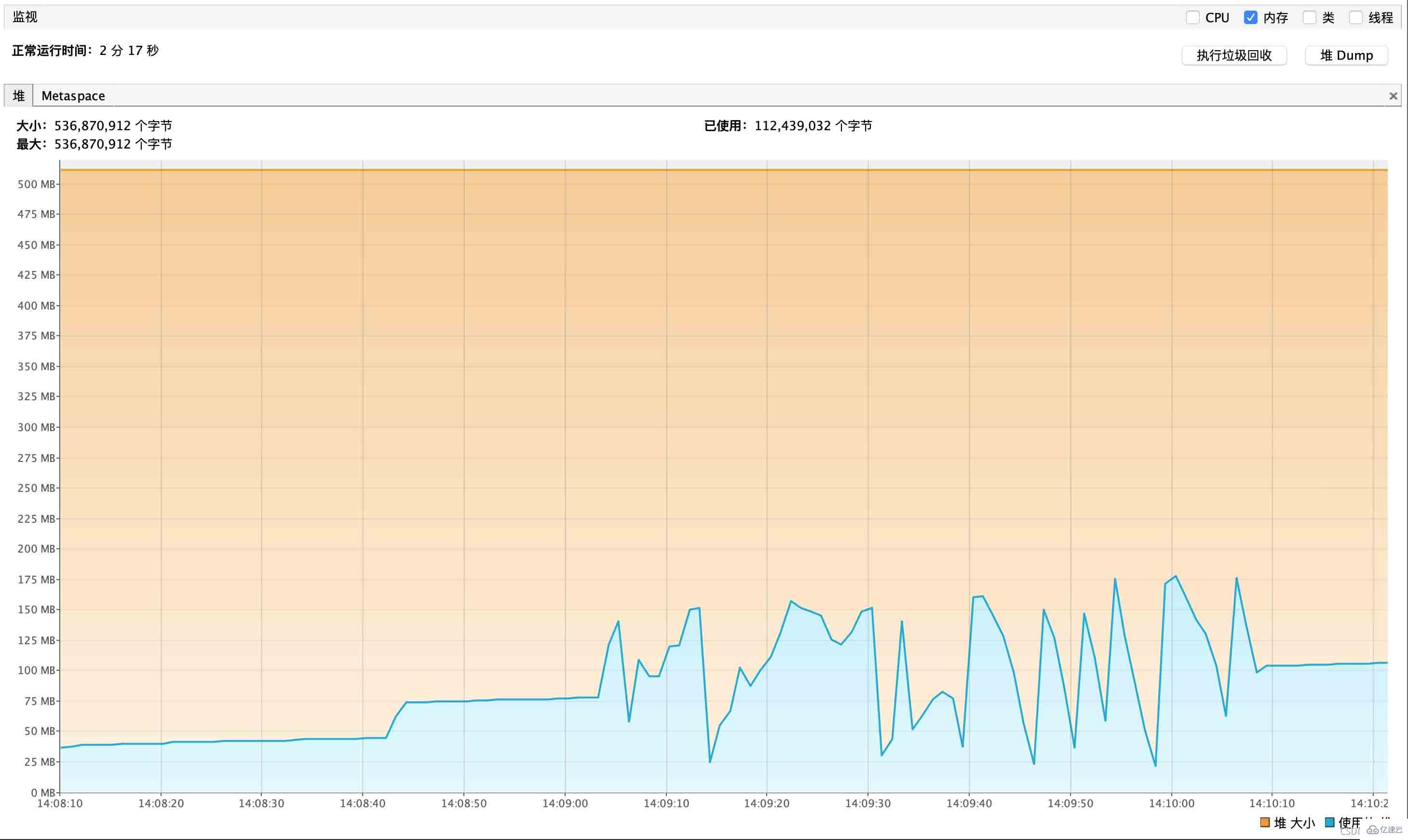
游标查询内存性能报告如下
 感谢各位的阅读,以上就是“MySQL中流式查询及游标查询的方式是什么”的内容了,经过本文的学习后,相信大家对MySQL中流式查询及游标查询的方式是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
感谢各位的阅读,以上就是“MySQL中流式查询及游标查询的方式是什么”的内容了,经过本文的学习后,相信大家对MySQL中流式查询及游标查询的方式是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





