Mysqlй”ҒеҶ…йғЁе®һзҺ°жңәеҲ¶жҳҜд»Җд№Ҳ
иҝҷзҜҮвҖңMysqlй”ҒеҶ…йғЁе®һзҺ°жңәеҲ¶жҳҜд»Җд№ҲвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңMysqlй”ҒеҶ…йғЁе®һзҺ°жңәеҲ¶жҳҜд»Җд№ҲвҖқж–Үз« еҗ§гҖӮ
жҰӮиҝ°
иҷҪ然зҺ°еңЁе…ізі»еһӢж•°жҚ®еә“и¶ҠжқҘи¶ҠзӣёдјјпјҢдҪҶе…¶иғҢеҗҺзҡ„е®һзҺ°жңәеҲ¶еҸҜиғҪеӨ§зӣёеҫ„еәӯгҖӮе®һйҷ…дҪҝз”Ёж–№йқўпјҢеӣ дёәSQLиҜӯ法规иҢғзҡ„еӯҳеңЁдҪҝеҫ—жҲ‘们зҶҹжӮүеӨҡз§Қе…ізі»еһӢж•°жҚ®еә“并йқһйҡҫдәӢпјҢдҪҶжҳҜжңүеӨҡе°‘з§Қж•°жҚ®еә“еҸҜиғҪе°ұжңүеӨҡе°‘з§Қй”Ғзҡ„е®һзҺ°ж–№жі•гҖӮ
Microsoft Sql Server2005д№ӢеүҚеҸӘжҸҗдҫӣйЎөй”ҒпјҢзӣҙеҲ°2005зүҲжң¬жүҚејҖе§Ӣж”ҜжҢҒд№җи§Ӯ并еҸ‘гҖҒжӮІи§Ӯ并еҸ‘пјҢд№җи§ӮжЁЎејҸдёӢе…Ғи®ёе®һзҺ°иЎҢзә§еҲ«й”ҒпјҢеңЁSql Serverзҡ„и®ҫи®Ўдёӯй”ҒжҳҜдёҖз§ҚзЁҖзјәиө„жәҗпјҢй”Ғзҡ„ж•°йҮҸи¶ҠеӨҡпјҢејҖй”Җе°ұи¶ҠеӨ§пјҢдёәдәҶйҒҝе…Қеӣ дёәй”Ғзҡ„ж•°йҮҸеҝ«йҖҹж”ҖеҚҮеҜјиҮҙжҖ§иғҪж–ӯеҙ–ејҸдёӢи·ҢпјҢе…¶ж”ҜжҢҒдёҖз§Қз§°дёәй”ҒеҚҮзә§зҡ„жңәеҲ¶пјҢдёҖж—ҰиЎҢй”ҒеҚҮзә§дёәйЎөй”ҒпјҢ并еҸ‘жҖ§иғҪе°ұеҸҲеӣһеҲ°еҺҹзӮ№гҖӮ
дәӢе®һдёҠпјҢеҚідҪҝеңЁеҗҢдёҖдёӘж•°жҚ®еә“пјҢдёҚеҗҢзҡ„жү§иЎҢеј•ж“ҺеҜ№й”ҒиҝҷдёҖеҠҹиғҪзҡ„иҜ йҮҠдҫқ然жҳҜзҷҫ家дәүйёЈгҖӮеҜ№дәҺMyISAMиҖҢиЁҖд»…д»…ж”ҜжҢҒиЎЁй”ҒпјҢ并еҸ‘иҜ»еҸ–е°ҡеҸҜпјҢ并еҸ‘дҝ®ж”№еҸҜе°ұжҚүиҘҹи§ҒиӮҳдәҶгҖӮInnodbеҲҷе’ҢOracleйқһеёёзӣёдјјпјҢжҸҗдҫӣйқһй”Ғе®ҡдёҖиҮҙжҖ§иҜ»еҸ–гҖҒиЎҢй”Ғж”ҜжҢҒпјҢдёҺSql ServerжҳҺжҳҫдёҚеҗҢзҡ„жҳҜйҡҸзқҖй”ҒжҖ»ж•°зҡ„дёҠеҚҮпјҢInnodbд»…д»…еҸӘйңҖиҰҒд»ҳеҮәдёҖзӮ№зӮ№д»Јд»·гҖӮ
иЎҢй”Ғз»“жһ„
Innodbж”ҜжҢҒиЎҢй”ҒпјҢдё”еҜ№дәҺй”Ғзҡ„жҸҸиҝ°е№¶дёҚдјҡеӯҳеңЁзү№еҲ«еӨ§зҡ„ејҖй”ҖгҖӮеӣ жӯӨдёҚйңҖиҰҒй”ҒеҚҮзә§иҝҷдёҖжңәеҲ¶дҪңдёәеӨ§йҮҸй”ҒеҜјиҮҙжҖ§иғҪдёӢйҷҚд№ӢеҗҺзҡ„жҠўж•‘жҺӘж–ҪгҖӮ
ж‘ҳиҮӘlock0priv.hж–Ү件пјҢInnodbеҜ№дәҺиЎҢй”Ғзҡ„е®ҡд№үеҰӮдёӢпјҡ
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};дёҚйҡҫзңӢеҮәиҷҪ然并еҸ‘жҺ§еҲ¶еҸҜд»Ҙз»ҶеҢ–еҲ°иЎҢзә§еҲ«пјҢдҪҶжҳҜй”Ғд»ҘйЎөзҡ„зІ’еәҰз»„з»Үз®ЎзҗҶгҖӮInnodbзҡ„и®ҫи®ЎдёӯйҖҡиҝҮspace idгҖҒpage numberдёӨдёӘеҝ…иҰҒжқЎд»¶е°ұеҸҜд»ҘзЎ®е®ҡе”ҜдёҖдёҖдёӘж•°жҚ®йЎөпјҢn_bitsиЎЁзӨәжҸҸиҝ°иҜҘйЎөиЎҢй”ҒдҝЎжҒҜйңҖиҰҒеӨҡе°‘bitдҪҚгҖӮ
еҗҢдёҖж•°жҚ®йЎөдёӯжҜҸжқЎи®°еҪ•йғҪеҲҶй…Қе”ҜдёҖзҡ„иҝһз»ӯзҡ„йҖ’еўһеәҸеҸ·пјҡheap_noпјҢиӢҘиҰҒзҹҘйҒ“жҹҗдёҖиЎҢи®°еҪ•жҳҜеҗҰдёҠй”ҒпјҢеҲҷеҸӘйңҖиҰҒеҲӨж–ӯдҪҚеӣҫheap_noдҪҚзҪ®зҡ„ж•°еӯ—жҳҜеҗҰдёәдёҖеҚіеҸҜгҖӮз”ұдәҺlock bitmapж №жҚ®ж•°жҚ®йЎөзҡ„и®°еҪ•ж•°йҮҸиҝӣиЎҢеҶ…еӯҳз©әй—ҙеҲҶй…Қзҡ„пјҢеӣ жӯӨжІЎжңүжҳҫејҸе®ҡд№үпјҢдё”иҜҘйЎөи®°еҪ•еҸҜиғҪиҝҳдјҡ继з»ӯеўһеҠ пјҢеӣ жӯӨйў„з•ҷдәҶLOCK_PAGE_BITMAP_MARGINеӨ§е°Ҹзҡ„з©әй—ҙгҖӮ
/**
* Safety margin when creating a new record lock: this many extra records
* can be inserted to the page without need to create a lock with
* a bigger bitmap
*/
#define LOCK_PAGE_BITMAP_MARGIN 64
еҒҮи®ҫspace id = 20пјҢpage number = 100зҡ„ж•°жҚ®йЎөзӣ®еүҚжңү160жқЎи®°еҪ•пјҢheap_noдёә2гҖҒ3гҖҒ4зҡ„и®°еҪ•е·Із»Ҹиў«й”ҒпјҢеҲҷеҜ№еә”зҡ„lock_rec_tз»“жһ„дёҺж•°жҚ®йЎөеә”иҜҘиў«иҝҷж ·еҲ»з”»:
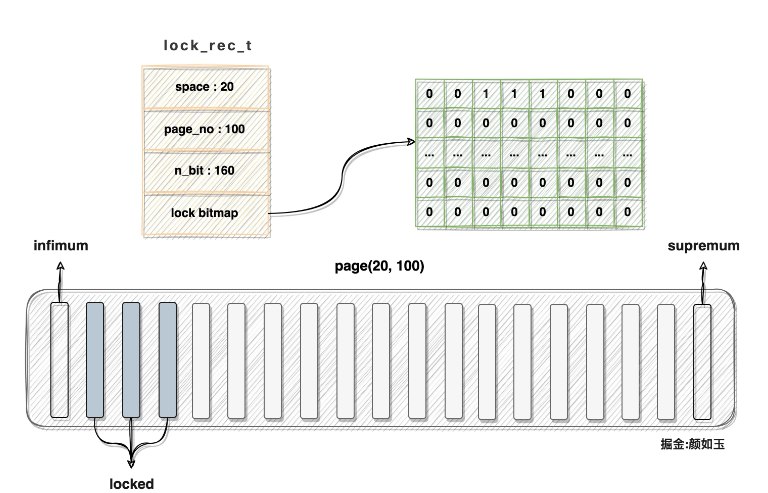
жіЁпјҡ
еҸҜд»ҘзңӢеҲ°иҜҘйЎөеҜ№еә”зҡ„bitmap第дәҢдёүеӣӣдҪҚзҪ®е…ЁйғЁзҪ®дёҖпјҢжҸҸиҝ°дёҖдёӘж•°жҚ®йЎөиЎҢй”ҒжүҖж¶ҲиҖ—еҶ…еӯҳд»Һж„ҹе®ҳдёҠзӣёеҪ“жңүйҷҗпјҢйӮЈе…·дҪ“еҚ з”ЁеӨҡе°‘е‘ўпјҹжҲ‘们еҸҜд»Ҙи®Ўз®—дёҖдёӢ:
160 / 8 + 8 + 1 = 29byteгҖӮ
иҝҷйҮҢиҝҳйўқеӨ–+1пјҢеә”иҜҘжҳҜдёәдәҶйҒҝе…Қеӣ дёәж•ҙйҷӨеҜјиҮҙзҡ„з»“жһңж•°еҖјеҒҸе°Ҹзҡ„й—®йўҳгҖӮеҒҮеҰӮжҳҜ161жқЎи®°еҪ•еҰӮжһңдёҚ+1еҲҷи®Ўз®—еҮәжқҘзҡ„20byteдёҚеӨҹжҸҸиҝ°жүҖжңүи®°еҪ•зҡ„й”ҒдҝЎжҒҜ(дёҚеҠЁз”Ёйў„з•ҷдҪҚ)гҖӮ
ж‘ҳиҮӘlock0priv.hж–Ү件:
/* lock_rec_createеҮҪж•°д»Јз ҒзүҮж®ө */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* жіЁж„ҸиҝҷйҮҢжҳҜеҲҶй…Қзҡ„иҝһз»ӯеҶ…еӯҳ */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}иЎЁй”Ғз»“жһ„
Innodbиҝҳж”ҜжҢҒиЎЁй”ҒпјҢиЎЁй”ҒеҸҜеҲҶдёәдёӨеӨ§зұ»:ж„Ҹеҗ‘й”ҒпјҢиҮӘеўһй”Ғе…¶ж•°жҚ®з»“жһ„е®ҡд№үеҰӮдёӢ:
ж‘ҳиҮӘlock0priv.hж–Ү件
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};ж‘ҳиҮӘut0lst.hж–Ү件
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>дәӢеҠЎдёӯй”Ғзҡ„жҸҸиҝ°
дёҠиҝ°lock_rec_tгҖҒlock_table_tз»“жһ„еҸӘжҳҜеҚ•зӢ¬зҡ„е®ҡд№үпјҢй”Ғдә§з”ҹдәҺдәӢеҠЎд№ӢдёӯпјҢеӣ жӯӨжҜҸдёӘдәӢеҠЎеҜ№еә”зҡ„иЎҢй”ҒгҖҒиЎЁй”ҒдјҡжңүдёҖдёӘзӣёеә”зҡ„й”Ғзҡ„з»“жһ„пјҢе…¶е®ҡд№үеҰӮдёӢ:
ж‘ҳиҮӘlock0priv.hж–Ү件
/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};lock_tжҳҜж №жҚ®жҜҸдёӘдәӢеҠЎжҜҸдёӘйЎө(жҲ–иЎЁ)жқҘе®ҡд№үзҡ„пјҢдҪҶжҳҜдёҖдёӘдәӢеҠЎеҫҖеҫҖж¶үеҸҠеҲ°еӨҡдёӘйЎөпјҢеӣ жӯӨйңҖиҰҒй“ҫиЎЁtrx_locksдёІиҒ”иө·дёҖдёӘдәӢеҠЎзӣёе…ізҡ„жүҖжңүй”ҒдҝЎжҒҜгҖӮйҷӨдәҶйңҖиҰҒж №жҚ®дәӢеҠЎжҹҘиҜўеҲ°жүҖжңүй”ҒдҝЎжҒҜпјҢе®һйҷ…еңәжҷҜиҝҳиҰҒжұӮзі»з»ҹеҝ…йЎ»иғҪеӨҹеҝ«йҖҹй«ҳж•Ҳзҡ„жЈҖжөӢеҮәжҹҗдёӘиЎҢи®°еҪ•жҳҜеҗҰе·Із»ҸдёҠй”ҒгҖӮеӣ жӯӨеҝ…йЎ»жңүдёҖдёӘе…ЁеұҖеҸҳйҮҸж”ҜжҢҒеҜ№иЎҢи®°еҪ•иҝӣиЎҢй”ҒдҝЎжҒҜзҡ„жҹҘиҜўгҖӮInnodbйҖүжӢ©дәҶе“ҲеёҢиЎЁпјҢе…¶е®ҡд№үеҰӮдёӢ:
ж‘ҳиҮӘlock0lock.hж–Ү件
/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* е°ұжҳҜиҝҷйҮҢ: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};еҮҪж•°lock_sys_createеңЁdatabase startд№Ӣйҷ…иҙҹиҙЈеҲқе§ӢеҢ–lock_sys_tз»“жһ„гҖӮrec_hashзҡ„hash slotж•°йҮҸз”ұsrv_lock_table_sizeеҸҳйҮҸеҶіе®ҡгҖӮrec_hashе“ҲеёҢиЎЁзҡ„keyеҖјйҖҡиҝҮйЎөзҡ„space idпјҢpage numberи®Ўз®—еҫ—еҮәгҖӮ
ж‘ҳиҮӘlock0lock.icгҖҒut0rnd.ic ж–Ү件
/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}иҝҷе°Ҷж„Ҹе‘ізқҖж— жі•жҸҗдҫӣдёҖдёӘжүӢж®өдҪҝеҫ—жҲ‘们еҸҜд»ҘзӣҙжҺҘеҫ—зҹҘжҹҗдёҖиЎҢжҳҜеҗҰдёҠй”ҒгҖӮиҖҢжҳҜеә”иҜҘе…ҲйҖҡиҝҮе…¶жүҖеңЁзҡ„йЎөеҫ—еҲ°space idгҖҒpage numberйҖҡиҝҮlock_rec_foldеҮҪж•°еҫ—еҮәkeyеҖјиҖҢеҗҺз»ҸиҝҮhashжҹҘиҜўеҫ—еҲ°lock_rec_tпјҢиҖҢеҗҺж №жҚ®heap_noжү«жҸҸbit mapпјҢжңҖз»ҲзЎ®е®ҡй”ҒдҝЎжҒҜгҖӮlock_rec_get_firstеҮҪж•°е®һзҺ°дәҶдёҠиҝ°йҖ»иҫ‘:
иҝҷйҮҢиҝ”еӣһзҡ„е…¶е®һжҳҜlock_tеҜ№иұЎпјҢж‘ҳиҮӘlock0lock.ccж–Ү件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}й”Ғз»ҙжҠӨд»ҘйЎөзҡ„зІ’еәҰпјҢдёҚжҳҜдёҖдёӘжңҖй«ҳж•ҲзӣҙжҺҘзҡ„ж–№ејҸпјҢжҳҺжҳҫзҡ„ж—¶й—ҙжҚўз©әй—ҙпјҢиҝҷз§Қи®ҫи®ЎдҪҝеҫ—й”Ғзҡ„ејҖй”ҖеҫҲе°ҸгҖӮжҹҗдёҖдәӢеҠЎеҜ№д»»дёҖиЎҢдёҠй”Ғзҡ„ејҖй”ҖйғҪжҳҜдёҖж ·зҡ„пјҢй”Ғж•°йҮҸзҡ„дёҠеҚҮд№ҹдёҚдјҡеёҰжқҘйўқеӨ–зҡ„еҶ…еӯҳж¶ҲиҖ—гҖӮ
жҜҸдёӘдәӢеҠЎйғҪеҜ№еә”дёҖдёӘtrx_tзҡ„еҶ…еӯҳеҜ№иұЎпјҢе…¶дёӯдҝқеӯҳзқҖиҜҘдәӢеҠЎй”ҒдҝЎжҒҜй“ҫиЎЁе’ҢжӯЈеңЁзӯүеҫ…зҡ„й”ҒдҝЎжҒҜгҖӮеӣ жӯӨеӯҳеңЁеҰӮдёӢдёӨз§ҚйҖ”еҫ„еҜ№й”ҒиҝӣиЎҢжҹҘиҜў:
ж №жҚ®дәӢеҠЎ: йҖҡиҝҮtrx_tеҜ№иұЎзҡ„trx_locksй“ҫиЎЁпјҢеҶҚйҖҡиҝҮlock_tеҜ№иұЎдёӯзҡ„trx_locksйҒҚеҺҶеҸҜеҫ—жҹҗдәӢеҠЎжҢҒжңүгҖҒзӯүеҫ…зҡ„жүҖжңүй”ҒдҝЎжҒҜгҖӮ
ж №жҚ®и®°еҪ•: ж №жҚ®и®°еҪ•жүҖеңЁзҡ„йЎөпјҢйҖҡиҝҮspace idгҖҒpage numberеңЁlock_sys_tз»“жһ„дёӯе®ҡдҪҚеҲ°lock_tеҜ№иұЎпјҢжү«жҸҸbitmapжүҫеҲ°heap_noеҜ№еә”зҡ„bitдҪҚгҖӮ
дёҠиҝ°еҗ„з§Қж•°жҚ®з»“жһ„пјҢеҜ№е…¶ж•ҙзҗҶе…ізі»еҰӮдёӢеӣҫжүҖзӨә:
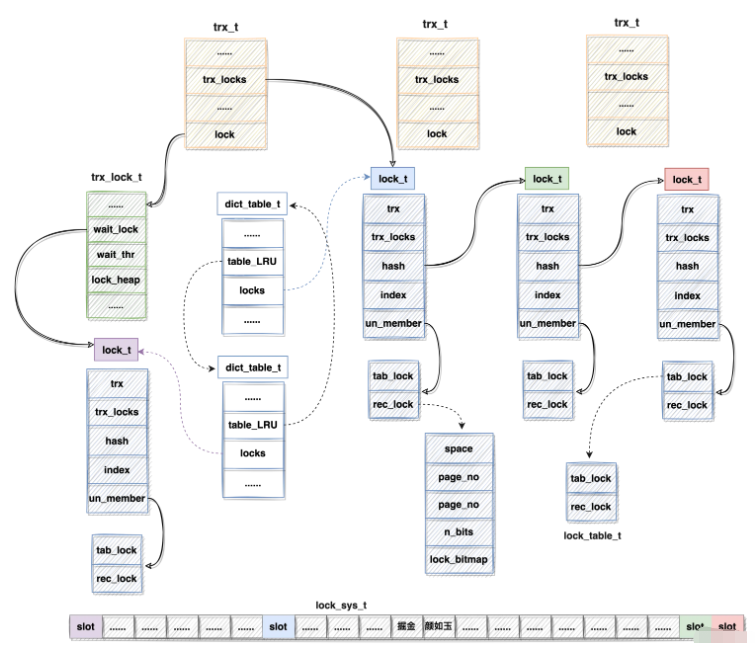
жіЁ:
lock_sys_tдёӯзҡ„slotйўңиүІдёҺlock_tйўңиүІзӣёеҗҢеҲҷиЎЁжҳҺlock_sys_t slotжҢҒжңүlock_t жҢҮй’ҲдҝЎжҒҜпјҢе®һеңЁжҳҜжІЎжі•иҝһзәҝпјҢдёҚ然еӣҫеҫҲж··д№ұ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңMysqlй”ҒеҶ…йғЁе®һзҺ°жңәеҲ¶жҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





