这篇文章主要介绍“游戏服务器中的Netty应用怎么实现”,在日常操作中,相信很多人在游戏服务器中的Netty应用怎么实现问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”游戏服务器中的Netty应用怎么实现”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
端口号资源
cat /proc/sys/net/ipv4/ip_local_port_range
文件描述符资源
系统级:当前系统可打开的最大数量,通过 cat /proc/sys/fs/file-max 查看
用户级:指定用户可打开的最大数量,通过 cat /etc/security/limits.conf 查看
进程级:单个进程可打开的最大数量,通过 cat /proc/sys/fs/nr_open 查看
线程资源 BIO/NIO
所有操作都是同步阻塞(accept,read)
客户端连接数与服务器线程数比例是1:1
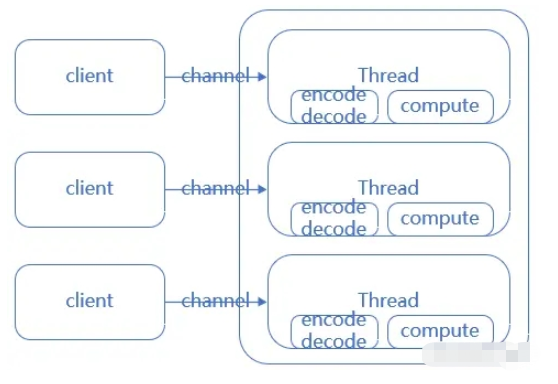
非阻塞IO
通过selector实现可以一个线程管理多个连接
通过selector的事件注册(OP_READ/OP_WRITE/OP_CONNECT/OP_ACCEPT),处理自己感兴趣的事件
客户端连接数与服务器线程数比例是n:1
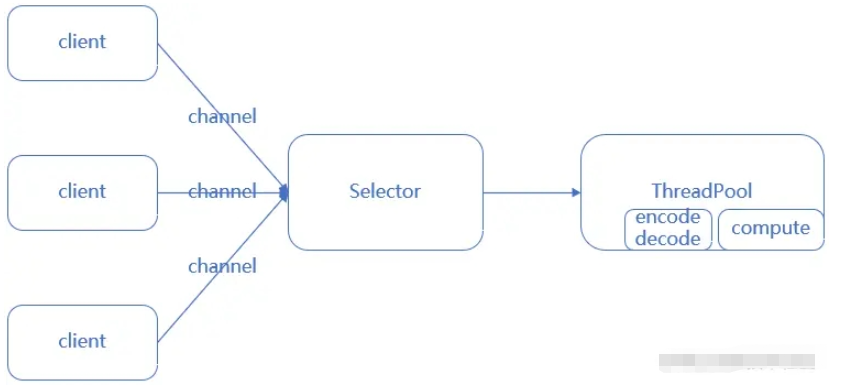
所有IO在同一个NIO线程完成(处理连接,分派请求,编码,解码,逻辑运算,发送)
优点:
编码简单
不存在共享资源竞争
并发安全
缺点:
单线程处理大量链路时,性能无法支撑,不能合理利用多核处理
线程过载后,处理速度变慢,会导致消息积压
一旦线程挂掉,整个通信层不可用 redis使用的就是reactor单进程模型,redis由于都是内存级操作,所以使用此模式没什么问题
reactor单线程模型图:
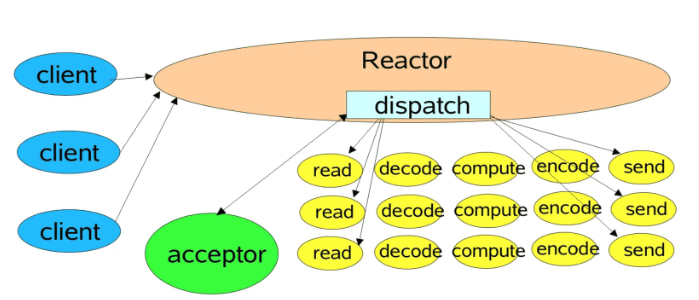
netty reactor单线程模型图:
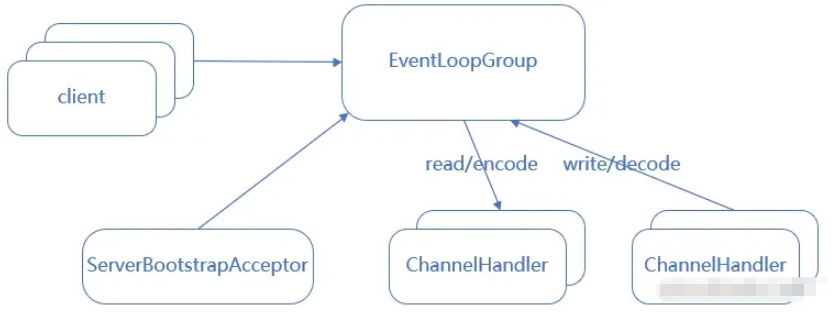
Netty对应实现方式
// Netty对应实现方式:创建io线程组是,boss和worker,使用同一个线程组,并且线程数为1 EventLoopGroup ioGroup = new NioEventLoopGroup(1); b.group(ioGroup, ioGroup) .channel(NioServerSocketChannel.class) .childHandler(initializer); ChannelFuture f = b.bind(portNumner); cf = f.sync(); f.get();
根据单线程模型,io处理中最耗时的编码,解码,逻辑运算等cpu消耗较多的部分,可提取出来使用多线程实现,并充分利用多核cpu的优势
优点:
多线程处理逻辑运算,提高多核CPU利用率
缺点:
对于单Reactor来说,大量链接的IO事件处理依然是性能瓶颈
reactor多线程模型图:
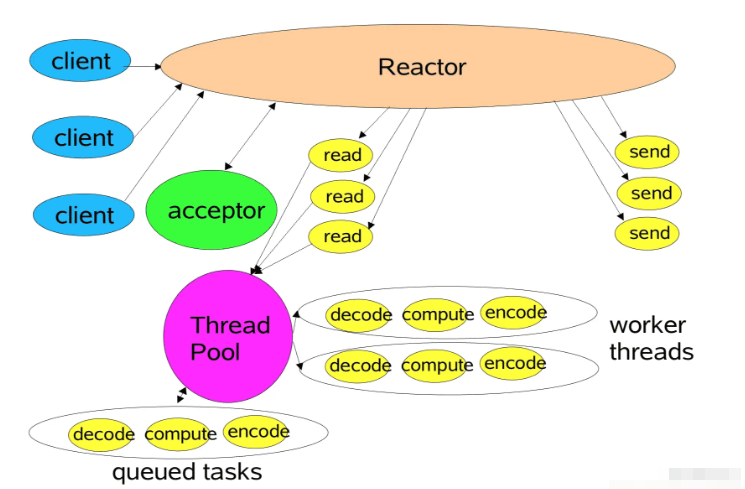
netty reactor多线程模型图:
Netty对应实现方式
// Netty对应实现方式:创建io线程组是,boss和worker,使用同一个线程组,并且线程数为1,把逻辑运算部分投递到用户自定义线程处理 EventLoopGroup ioGroup = new NioEventLoopGroup(1); b.group(ioGroup, ioGroup) .channel(NioServerSocketChannel.class) .childHandler(initializer); ChannelFuture f = b.bind(portNumner); cf = f.sync(); f.get();
根据多线程模型,可把它的性能瓶颈做进一步优化,即把reactor由单个改为reactor线程池,把原来的reactor分为mainReactor和subReactor
优点:
解决单Reactor的性能瓶颈问题(Netty/Nginx采用这种设计)
reactor主从多线程模型图:

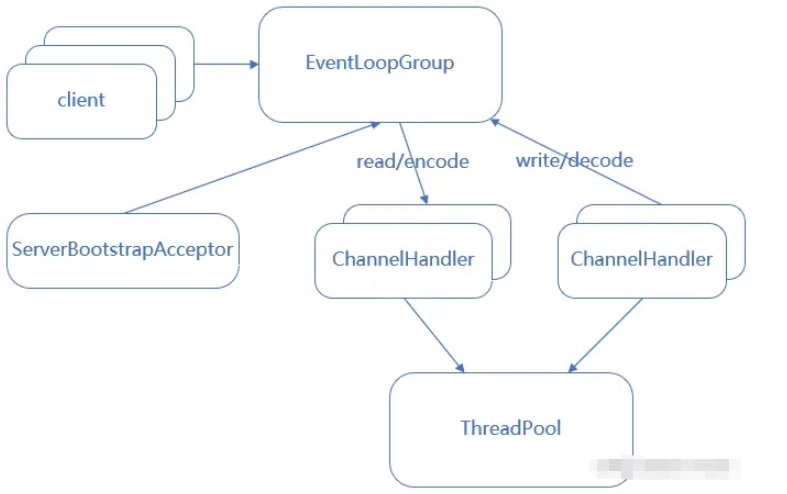
netty reactor主从多线程模型图:

Netty对应实现方式
// Netty对应实现方式:创建io线程组boss和worker,boss线程数为1,work线程数为cpu*2(一般IO密集可设置为2倍cpu核数) EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); b.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childHandler(initializer); ChannelFuture f = b.bind(portNumner); cf = f.sync(); f.get();
创建group实例
// 1.构造参数不传或传0,默认取系统参数配置,没有参数配置,取CPU核数*2
super(nThreads == 0 ? DEFAULT_EVENT_LOOP_THREADS : nThreads, executor, args);
private static final int DEFAULT_EVENT_LOOP_THREADS;
static {
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt(
"io.netty.eventLoopThreads", NettyRuntime.availableProcessors() * 2));
}
// 2.不同版本的JDK会有不同版本的SelectorProvider实现,Windows下的是WindowsSelectorProvider
public NioEventLoopGroup(int nThreads, Executor executor) {
//默认selector,最终实现类似:https://github.com/frohoff/jdk8u-jdk/blob/master/src/macosx/classes/sun/nio/ch/DefaultSelectorProvider.java
//basic flow: 1 java.nio.channels.spi.SelectorProvider 2 META-INF/services 3 default
this(nThreads, executor, SelectorProvider.provider());
}
// 3.创建nThread个EventExecutor,并封装到选择器chooser,chooser会根据线程数分别有两种实现(GenericEventExecutorChooser和PowerOfTwoEventExecutorChooser,算法不同,但实现逻辑一样,就是均匀的分配线程处理)
EventExecutorChooserFactory.EventExecutorChooser chooser;
children = new EventExecutor[nThreads];
for (int i = 0; i < nThreads; i ++) {
// ...
children[i] = newChild(executor, args);
// ...
}
chooser = chooserFactory.newChooser(children);设置group
// 两种方式设置group
// parent和child使用同一个group,调用仍然是分别设置parent和child
@Override
public ServerBootstrap group(EventLoopGroup group) {
return group(group, group);
}
ServerBootstrap.group(EventLoopGroup parentGroup, EventLoopGroup childGroup){
// 具体代码略,可直接参考源码
// 里面实现内容是把parentGroup绑定到this.group,把childGroup绑定到this.childGroup
}Netty启动
// 调用顺序
ServerBootstrap:bind() -> doBind() -> initAndRegister()
private ChannelFuture doBind(final SocketAddress localAddress) {
final ChannelFuture regFuture = initAndRegister();
// ...
doBind0(regFuture, channel, localAddress, promise);
// ...
}
final ChannelFuture initAndRegister() {
// 创建ServerSocketChannel
Channel channel = channelFactory.newChannel();
// ...
// 开始register
ChannelFuture regFuture = config().group().register(channel);
// register调用顺序
// next().register(channel) -> (EventLoop) super.next() -> chooser.next()
// ...
}由以上源码可得知,bind只在起服调用一次,因此bossGroup仅调用一次regist,也就是仅调用一次next,因此只有一根线程是有用的,其余线程都是废弃的,所以bossGroup线程数设置为1即可
// 启动BossGroup线程并绑定本地SocketAddress
private static void doBind0(
final ChannelFuture regFuture, final Channel channel,
final SocketAddress localAddress, final ChannelPromise promise) {
channel.eventLoop().execute(new Runnable() {
@Override
public void run() {
if (regFuture.isSuccess()) {
channel.bind(localAddress, promise).addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
} else {
promise.setFailure(regFuture.cause());
}
}
});
}客户端连接
// 消息事件读取
NioEventLoop.run() -> processSelectedKeys() -> ... -> ServerBootstrapAcceptor.channelRead
// ServerBootstrapAcceptor.channelRead处理客户端连接事件
// 最后一行的childGroup.register的逻辑和上面的代码调用处一样
public void channelRead(ChannelHandlerContext ctx, Object msg) {
child.pipeline().addLast(childHandler);
setChannelOptions(child, childOptions, logger);
setAttributes(child, childAttrs);
childGroup.register(child)
}select(时间复杂度O(n)):用一个fd数组保存所有的socket,然后通过死循环遍历调用操作系统的select方法找到就绪的fd
while(1) {
nready = select(list);
// 用户层依然要遍历,只不过少了很多无效的系统调用
for(fd <-- fdlist) {
if(fd != -1) {
// 只读已就绪的文件描述符
read(fd, buf);
// 总共只有 nready 个已就绪描述符,不用过多遍历
if(--nready == 0) break;
}
}
}poll(时间复杂度O(n)):同select,不过把fd数组换成了fd链表,去掉了fd最大连接数(1024个)的数量限制
epoll(时间复杂度O(1)):解决了select/poll的几个缺陷
调用需传入整个fd数组或fd链表,需要拷贝数据到内核
内核层需要遍历检查文件描述符的就绪状态
内核仅返回可读文件描述符个数,用户仍需自己遍历所有fd
epoll是操作系统基于事件关联fd,做了以下优化:
内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。(epoll_ctl)
内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。(epoll_wait)
内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
epoll仅在Linux系统上支持
// DefaultSelectorProvider.create方法在不同版本的jdk下有不同实现,创建不同Selector
// Windows版本的jdk,其实现中调用的是native的poll方法
public static SelectorProvider create() {
return new WindowsSelectorProvider();
}
// Linux版本的jdk
public static SelectorProvider create() {
String str = (String)AccessController.doPrivileged(new GetPropertyAction("os.name"));
if (str.equals("SunOS")) {
return createProvider("sun.nio.ch.DevPollSelectorProvider");
}
if (str.equals("Linux")) {
return createProvider("sun.nio.ch.EPollSelectorProvider");
}
return new PollSelectorProvider();
}netty依然基于epoll做了一层封装,主要做了以下事情:
(1)java的nio默认使用水平触发,Netty的Epoll默认使用边缘触发,且可配置
边缘触发:当状态变化时才会发生io事件。
水平触发:只要满足条件,就触发一个事件(只要有数据没有被获取,内核就不断通知你)
(2)Netty的Epoll提供更多的nio的可配参数。
(3)调用c代码,更少gc,更少synchronized 具体可以参考源码NioEventLoop.run和EpollEventLoop.run进行对比
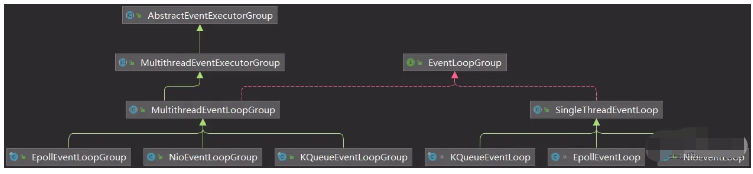
线程组类图
channel类图

// 创建指定的EventLoopGroup
bossGroup = new EpollEventLoopGroup(1, new DefaultThreadFactory("BOSS_LOOP"));
workerGroup = new EpollEventLoopGroup(32, new DefaultThreadFactory("IO_LOOP"));
b.group(bossGroup, workerGroup)
// 指定channel的class
.channel(EpollServerSocketChannel.class)
.childHandler(initializer);
// 其中channel(clz)方法是通过class来new一个反射ServerSocketChannel创建工厂类
public B channel(Class<? extends C> channelClass) {
if (channelClass == null) {
throw new NullPointerException("channelClass");
}
return channelFactory(new ReflectiveChannelFactory<C>(channelClass));
}
final ChannelFuture initAndRegister() {
// ...
Channel channel = channelFactory.newChannel();
// ...
}childOption(ChannelOption.SO_KEEPALIVE, true)
TCP链路探活
option(ChannelOption.SO_REUSEADDR, true)
重用处于TIME_WAIT但是未完全关闭的socket地址,让端口释放后可立即被重用。默认关闭,需要手动开启
childOption(ChannelOption.TCP_NODELAY, true)
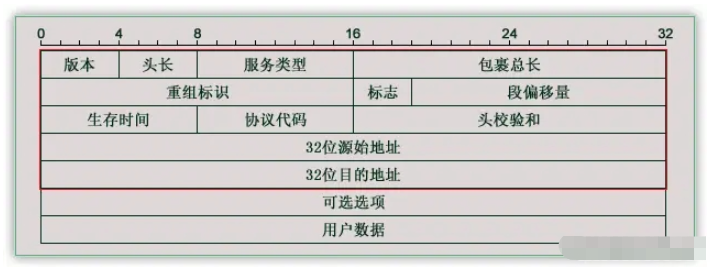
IP报文格式
TCP报文格式
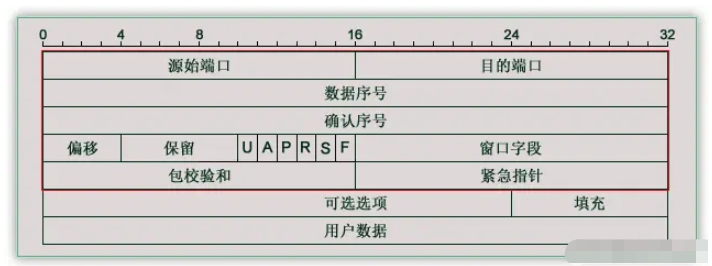
开启则禁用TCP Negal算法,优点低延时,缺点在大量小数据包的情况下,网络利用率低
关闭则开启TCP Negal算法,优点提高网络利用率(数据缓存到一定量才发送),缺点延时高
Negal算法
如果包长度达到MSS(maximum segment size最大分段长度),则允许发送;
如果该包含有FIN,则允许发送;
设置了TCP_NODELAY选项,则允许发送;
未设置TCP_CORK选项(是否阻塞不完整报文)时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
MSS计算规则 MSS的值是在TCP三次握手建立连接的过程中,经通信双方协商确定的 802.3标准里,规定了一个以太帧的数据部分(Payload)的最大长度是1500个字节(MTU)
MSS = MTU - IP首部 - TCP首部
以太网环境下:
MTU = 1500字节
IP首部 = 32*5/4 = 160bit = 20字节
TCP首部 = 32*5/4 = 160bit = 20字节
最终得出MSS = 1460字节
结论:因为游戏服务器的实时性要求,在网络带宽足够的情况下,建议开启TCP_NODELAY,关闭Negal算法,带宽可以浪费,响应必须及时
注意:需要客户端服务器均关闭Negal算法,否则仍然会有延迟发送,影响传输速度
option(ChannelOption.SO_BACKLOG, 100)
操作系统内核中维护的两个队列
syns queue:保存syn到达,但没完成三次握手的半连接
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
accpet queue:保存完成三次握手,内核等待accept调用的连接
cat /proc/sys/net/core/somaxconn
netty对于backlog的默认值设置在NetUtil类253行
SOMAXCONN = AccessController.doPrivileged(new PrivilegedAction<Integer>() {
@Override
public Integer run() {
// 1.设置默认值
int somaxconn = PlatformDependent.isWindows() ? 200 : 128;
File file = new File("/proc/sys/net/core/somaxconn");
if (file.exists()) {
// 2.文件存在,读取操作系统配置
in = new BufferedReader(new FileReader(file));
somaxconn = Integer.parseInt(in.readLine());
} else {
// 3.文件不存在,从各个参数中读取
if (SystemPropertyUtil.getBoolean("io.netty.net.somaxconn.trySysctl", false)) {
tmp = sysctlGetInt("kern.ipc.somaxconn");
if (tmp == null) {
tmp = sysctlGetInt("kern.ipc.soacceptqueue");
if (tmp != null) {
somaxconn = tmp;
}
} else {
somaxconn = tmp;
}
}
}
}
}结论:
Linux下/proc/sys/net/core/somaxconn一定存在,所以backlog一定取得它的值,我参考prod机器的参数配置的65535,也就是不设置backlog的情况下,服务器运行缓存65535个全连接
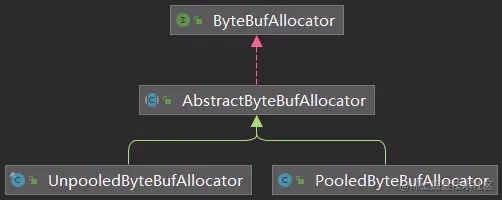
默认分配ByteBuffAllocator赋值如下: ByteBufUtil.java
static {
//以io.netty.allocator.type为准,没有的话,安卓平台用非池化实现,其他用池化实现
String allocType = SystemPropertyUtil.get(
"io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
ByteBufAllocator alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
//io.netty.allocator.type设置的不是"unpooled"或者"pooled",就用池化实现。
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
DEFAULT_ALLOCATOR = alloc;
}RCVBUF_ALLOCATOR默认AdaptiveRecvByteBufAllocator
public class DefaultChannelConfig implements ChannelConfig {
// ...
public DefaultChannelConfig(Channel channel) {
this(channel, new AdaptiveRecvByteBufAllocator());
}
// ...
}/**
* Shortcut method for {@link #shutdownGracefully(long, long, TimeUnit)} with sensible default values.
*
* @return the {@link #terminationFuture()}
*/
Future<?> shutdownGracefully();
/**
* Signals this executor that the caller wants the executor to be shut down. Once this method is called,
* {@link #isShuttingDown()} starts to return {@code true}, and the executor prepares to shut itself down.
* Unlike {@link #shutdown()}, graceful shutdown ensures that no tasks are submitted for <i>'the quiet period'</i>
* (usually a couple seconds) before it shuts itself down. If a task is submitted during the quiet period,
* it is guaranteed to be accepted and the quiet period will start over.
*
* @param quietPeriod the quiet period as described in the documentation
静默期:在此期间,仍然可以提交任务
* @param timeout the maximum amount of time to wait until the executor is {@linkplain #shutdown()}
* regardless if a task was submitted during the quiet period
超时时间:等待所有任务执行完的最大时间
* @param unit the unit of {@code quietPeriod} and {@code timeout}
*
* @return the {@link #terminationFuture()}
*/
Future<?> shutdownGracefully(long quietPeriod, long timeout, TimeUnit unit);
// 抽象类中的实现
static final long DEFAULT_SHUTDOWN_QUIET_PERIOD = 2;
static final long DEFAULT_SHUTDOWN_TIMEOUT = 15;
@Override
public Future<?> shutdownGracefully() {
return shutdownGracefully(DEFAULT_SHUTDOWN_QUIET_PERIOD, DEFAULT_SHUTDOWN_TIMEOUT, TimeUnit.SECONDS);
}把NIO线程的状态位设置成ST_SHUTTING_DOWN状态,不再处理新的消息(不允许再对外发送消息);
退出前的预处理操作:把发送队列中尚未发送或者正在发送的消息发送完、把已经到期或者在退出超时之前到期的定时任务执行完成、把用户注册到NIO线程的退出Hook任务执行完成;
资源的释放操作:所有Channel的释放、多路复用器的去注册和关闭、所有队列和定时任务的清空取消,最后是NIO线程的退出。
到此,关于“游戏服务器中的Netty应用怎么实现”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





