Nodeдёӯзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎжҖҺд№Ҳе®һзҺ°
иҝҷзҜҮвҖңNodeдёӯзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎжҖҺд№Ҳе®һзҺ°вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңNodeдёӯзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎжҖҺд№Ҳе®һзҺ°вҖқж–Үз« еҗ§гҖӮ
еүҚзҪ®зҹҘиҜҶ
ж–Ү件жҸҸиҝ°з¬Ұ
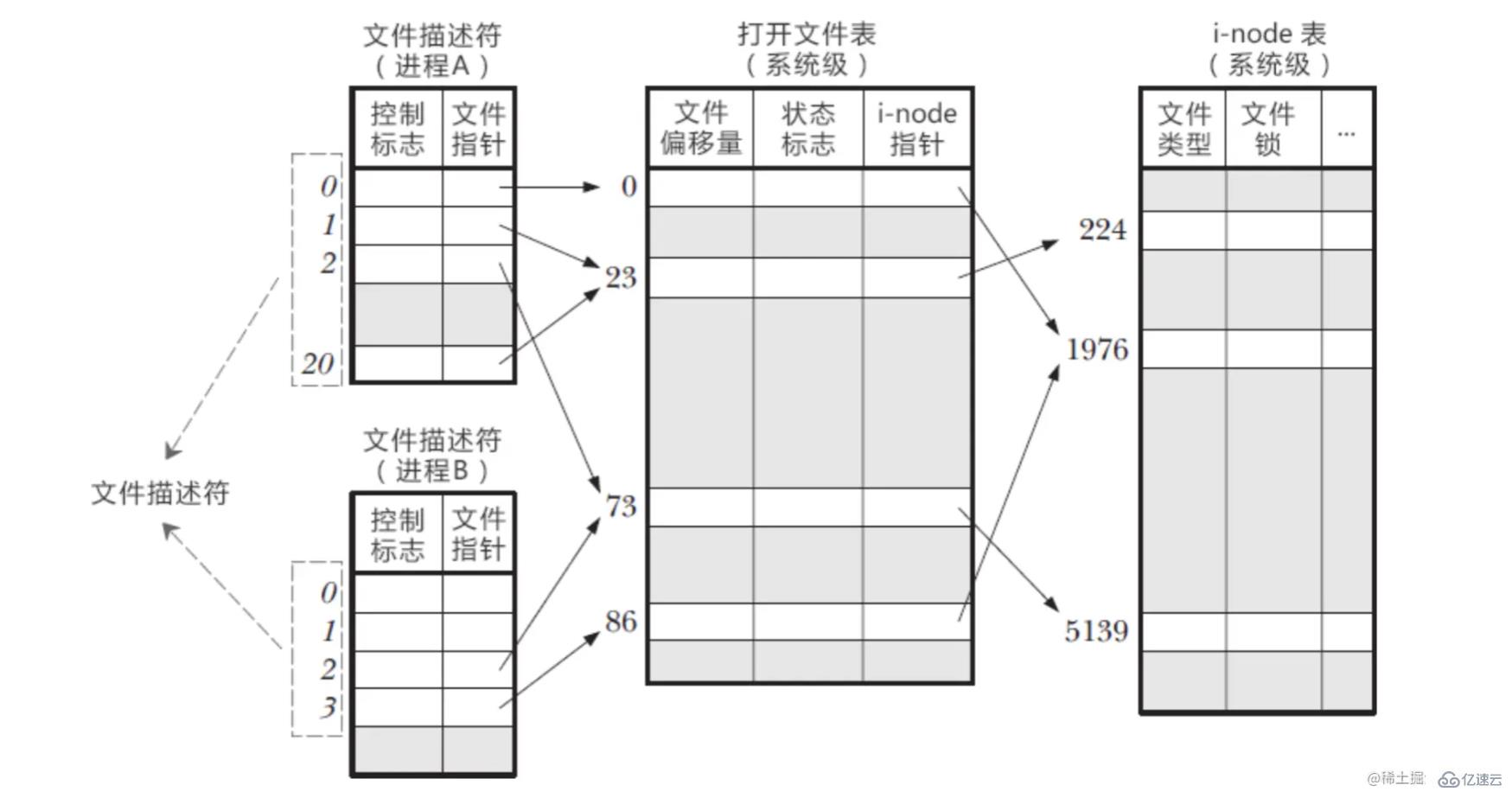
еңЁ Linux зі»з»ҹдёӯпјҢдёҖеҲҮйғҪзңӢжҲҗж–Ү件пјҢеҪ“иҝӣзЁӢжү“ејҖзҺ°жңүж–Ү件时пјҢдјҡиҝ”еӣһдёҖдёӘж–Ү件жҸҸиҝ°з¬ҰгҖӮ
ж–Ү件жҸҸиҝ°з¬ҰжҳҜж“ҚдҪңзі»з»ҹдёәдәҶз®ЎзҗҶе·Із»Ҹиў«иҝӣзЁӢжү“ејҖзҡ„ж–Ү件жүҖеҲӣе»әзҡ„зҙўеј•пјҢз”ЁжқҘжҢҮеҗ‘иў«жү“ејҖзҡ„ж–Ү件гҖӮ
еҪ“жҲ‘们зҡ„иҝӣзЁӢеҗҜеҠЁд№ӢеҗҺпјҢж“ҚдҪңзі»з»ҹдјҡз»ҷжҜҸдёҖдёӘиҝӣзЁӢеҲҶй…ҚдёҖдёӘ PCB жҺ§еҲ¶еқ—пјҢPCB дёӯдјҡжңүдёҖдёӘж–Ү件жҸҸиҝ°з¬ҰиЎЁпјҢеӯҳж”ҫеҪ“еүҚиҝӣзЁӢжүҖжңүзҡ„ж–Ү件жҸҸиҝ°з¬ҰпјҢеҚіеҪ“еүҚиҝӣзЁӢжү“ејҖзҡ„жүҖжңүж–Ү件гҖӮ
иҝӣзЁӢдёӯзҡ„ж–Ү件жҸҸиҝ°з¬ҰжҳҜеҰӮдҪ•е’Ңзі»з»ҹж–Ү件еҜ№еә”иө·жқҘзҡ„пјҹ
еңЁеҶ…ж ёдёӯпјҢзі»з»ҹдјҡз»ҙжҠӨеҸҰеӨ–дёӨз§ҚиЎЁ
ж–Ү件жҸҸиҝ°з¬Ұе°ұжҳҜж•°з»„зҡ„дёӢж ҮпјҢд»Һ0ејҖе§ӢеҫҖдёҠйҖ’еўһпјҢ0/1/2 й»ҳи®ӨжҳҜжҲ‘们зҡ„иҫ“е…Ҙ/иҫ“еҮә/й”ҷиҜҜжөҒзҡ„ж–Ү件жҸҸиҝ°з¬Ұ
еңЁ PCB дёӯз»ҙжҠӨзҡ„ж–Ү件жҸҸиҝ°иЎЁдёӯпјҢеҸҜд»Ҙж №жҚ®ж–Ү件жҸҸиҝ°з¬ҰжүҫеҲ°еҜ№еә”дәҶж–Ү件жҢҮй’ҲпјҢжүҫеҲ°еҜ№еә”зҡ„жү“ејҖж–Ү件表
жү“ејҖж–Ү件表дёӯз»ҙжҠӨдәҶпјҡж–Ү件еҒҸ移йҮҸ(иҜ»еҶҷж–Ү件зҡ„ж—¶еҖҷдјҡжӣҙж–°)пјӣеҜ№дәҺж–Ү件зҡ„зҠ¶жҖҒж ҮиҜҶпјӣжҢҮеҗ‘ i-node иЎЁзҡ„жҢҮй’Ҳ
жғіиҰҒзңҹжӯЈзҡ„ж“ҚдҪңж–Ү件пјҢиҝҳеҫ—йқ i-node иЎЁпјҢиғҪеӨҹиҺ·еҸ–еҲ°зңҹе®һж–Ү件зҡ„зӣёе…ідҝЎжҒҜ
他们д№Ӣй—ҙзҡ„е…ізі»
еӣҫи§Ј
еңЁиҝӣзЁӢ A дёӯпјҢж–Ү件жҸҸиҝ°з¬Ұ1/20еқҮжҢҮеҗ‘дәҶеҗҢдёҖжү“ејҖж–Ү件表项23пјҢиҝҷеҸҜиғҪжҳҜеҜ№еҗҢдёҖж–Ү件еӨҡж¬Ўи°ғз”ЁдәҶ open еҮҪж•°еҪўжҲҗзҡ„
иҝӣзЁӢ A/B зҡ„ж–Ү件жҸҸиҝ°з¬Ұ2йғҪжҢҮеҗ‘еҗҢдёҖж–Ү件пјҢиҝҷеҸҜиғҪжҳҜи°ғз”ЁдәҶ fork еҲӣе»әеӯҗиҝӣзЁӢпјҢA/B жҳҜзҲ¶еӯҗе…ізі»иҝӣзЁӢ
иҝӣзЁӢ A зҡ„ж–Ү件жҸҸиҝ°з¬Ұ0е’ҢиҝӣзЁӢ B зҡ„ж–Ү件жҸҸиҝ°з¬ҰжҢҮеҗ‘дәҶдёҚеҗҢзҡ„жү“ејҖж–Ү件表项пјҢдҪҶиҝҷдәӣиЎЁйЎ№жҢҮеҗ‘дәҶеҗҢдёҖдёӘж–Ү件пјҢиҝҷеҸҜиғҪжҳҜ A/B иҝӣзЁӢеҲҶеҲ«еҜ№еҗҢдёҖж–Ү件еҸ‘иө·дәҶ open и°ғз”Ё
жҖ»з»“
еҗҢдёҖиҝӣзЁӢзҡ„дёҚеҗҢж–Ү件жҸҸиҝ°з¬ҰеҸҜд»ҘжҢҮеҗ‘еҗҢдёҖдёӘж–Ү件
дёҚеҗҢиҝӣзЁӢеҸҜд»ҘжӢҘжңүзӣёеҗҢзҡ„ж–Ү件жҸҸиҝ°з¬Ұ
дёҚеҗҢиҝӣзЁӢзҡ„еҗҢдёҖж–Ү件жҸҸиҝ°з¬ҰеҸҜд»ҘжҢҮеҗ‘дёҚеҗҢзҡ„ж–Ү件
дёҚеҗҢиҝӣзЁӢзҡ„дёҚеҗҢж–Ү件жҸҸиҝ°з¬ҰеҸҜд»ҘжҢҮеҗ‘еҗҢдёҖдёӘж–Ү件
ж–Ү件жҸҸиҝ°з¬Ұзҡ„йҮҚе®ҡеҗ‘
жҜҸж¬ЎиҜ»еҶҷиҝӣзЁӢзҡ„ж—¶еҖҷпјҢйғҪжҳҜд»Һж–Ү件жҸҸиҝ°з¬ҰдёӢжүӢпјҢжүҫеҲ°еҜ№еә”зҡ„жү“ејҖж–Ү件表项пјҢеҶҚжүҫеҲ°еҜ№еә”зҡ„ i-node иЎЁ
?еҰӮдҪ•е®һзҺ°ж–Ү件жҸҸиҝ°з¬ҰйҮҚе®ҡеҗ‘пјҹ
еӣ дёәеңЁж–Ү件жҸҸиҝ°з¬ҰиЎЁдёӯпјҢиғҪеӨҹжүҫеҲ°еҜ№еә”зҡ„ж–Ү件жҢҮй’ҲпјҢеҰӮжһңжҲ‘们改еҸҳдәҶж–Ү件жҢҮй’ҲпјҢжҳҜдёҚжҳҜеҗҺз»ӯзҡ„дёӨдёӘиЎЁеҶ…е®№е°ұеҸ‘з”ҹдәҶж”№еҸҳ
дҫӢеҰӮпјҡж–Ү件жҸҸиҝ°з¬Ұ1жҢҮеҗ‘зҡ„жҳҫзӨәеҷЁпјҢйӮЈд№Ҳе°Ҷж–Ү件жҸҸиҝ°з¬Ұ1жҢҮеҗ‘ log.txt ж–Ү件пјҢйӮЈд№Ҳж–Ү件жҸҸиҝ°з¬Ұ 1 д№ҹе°ұе’Ң log.txt еҜ№еә”иө·жқҘдәҶ
shell еҜ№ж–Ү件жҸҸиҝ°з¬Ұзҡ„йҮҚе®ҡеҗ‘
> жҳҜиҫ“еҮәйҮҚе®ҡеҗ‘з¬ҰеҸ·пјҢ< жҳҜиҫ“е…ҘйҮҚе®ҡеҗ‘з¬ҰеҸ·пјҢе®ғ们жҳҜж–Ү件жҸҸиҝ°з¬Ұж“ҚдҪңз¬Ұ
> е’Ң < йҖҡиҝҮдҝ®ж”№ж–Ү件жҸҸиҝ°з¬Ұж”№еҸҳдәҶж–Ү件жҢҮй’Ҳзҡ„жҢҮеҗ‘пјҢжқҘиғҪеӨҹе®һзҺ°йҮҚе®ҡеҗ‘зҡ„еҠҹиғҪ
жҲ‘们дҪҝз”Ёcat hello.txtж—¶пјҢй»ҳи®Өдјҡе°Ҷз»“жһңиҫ“еҮәеҲ°жҳҫзӨәеҷЁдёҠпјҢдҪҝз”Ё > жқҘйҮҚе®ҡеҗ‘гҖӮcat hello.txt 1 > log.txtд»Ҙиҫ“еҮәзҡ„ж–№ејҸжү“ејҖж–Ү件 log.txtпјҢ并绑е®ҡеҲ°ж–Ү件жҸҸиҝ°з¬Ұ1дёҠ

cеҮҪж•°еҜ№ж–Ү件жҸҸиҝ°з¬Ұзҡ„йҮҚе®ҡеҗ‘
dup
dup еҮҪж•°жҳҜз”ЁжқҘжү“ејҖдёҖдёӘж–°зҡ„ж–Ү件жҸҸиҝ°з¬ҰпјҢжҢҮеҗ‘е’Ң oldfd еҗҢдёҖдёӘж–Ү件пјҢе…ұдә«ж–Ү件еҒҸ移йҮҸе’Ңж–Ү件зҠ¶жҖҒ
int main(int argc, char const *argv[])
{
int fd = open("log.txt");
int copyFd = dup(fd);
//е°Ҷfdйҳ…иҜ»ж–Ү件зҪ®дәҺж–Ү件жң«е°ҫпјҢи®Ўз®—еҒҸ移йҮҸгҖӮ
cout << "fd = " << fd << " еҒҸ移йҮҸпјҡ " << lseek(fd, 0, SEEK_END) << endl;
//зҺ°еңЁжҲ‘们计算copyFdзҡ„еҒҸ移йҮҸ
cout << "copyFd = " << copyFd << "еҒҸ移йҮҸпјҡ" << lseek(copyFd, 0, SEEK_CUR) << endl;
return 0;
}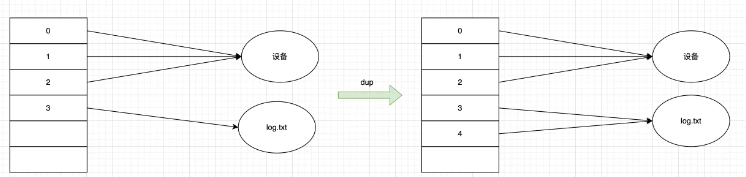
и°ғз”Ё dup(3) зҡ„ж—¶еҖҷпјҢдјҡжү“ејҖж–°зҡ„жңҖе°ҸжҸҸиҝ°з¬ҰпјҢд№ҹе°ұжҳҜ4пјҢиҝҷдёӘ4жҢҮеҗ‘дәҶ3жүҖжҢҮеҗ‘зҡ„ж–Ү件пјҢж“ҚдҪңд»»ж„ҸдёҖдёӘ fd йғҪжҳҜдҝ®ж”№зҡ„дёҖдёӘж–Ү件
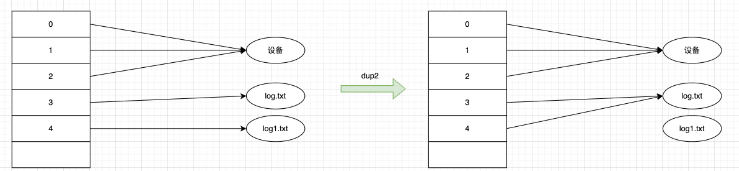
dup2
dup2 еҮҪж•°пјҢжҠҠжҢҮе®ҡзҡ„ newfd д№ҹжҢҮеҗ‘ oldfd жҢҮеҗ‘зҡ„ж–Ү件гҖӮжү§иЎҢе®Ңdup2д№ӢеҗҺпјҢnewfd е’Ң oldfd еҗҢж—¶жҢҮеҗ‘еҗҢдёҖдёӘж–Ү件пјҢе…ұдә«ж–Ү件еҒҸ移йҮҸе’Ңж–Ү件зҠ¶жҖҒ
int main(int argc, char const *argv[])
{
int fd = open("log.txt");
int copyFd = dup(fd);
//е°Ҷfdйҳ…иҜ»ж–Ү件зҪ®дәҺж–Ү件жң«е°ҫпјҢи®Ўз®—еҒҸ移йҮҸгҖӮ
cout << "fd = " << fd << " еҒҸ移йҮҸпјҡ " << lseek(fd, 0, SEEK_END) << endl;
//зҺ°еңЁжҲ‘们计算copyFdзҡ„еҒҸ移йҮҸ
cout << "copyFd = " << copyFd << "еҒҸ移йҮҸпјҡ" << lseek(copyFd, 0, SEEK_CUR) << endl;
return 0;
}
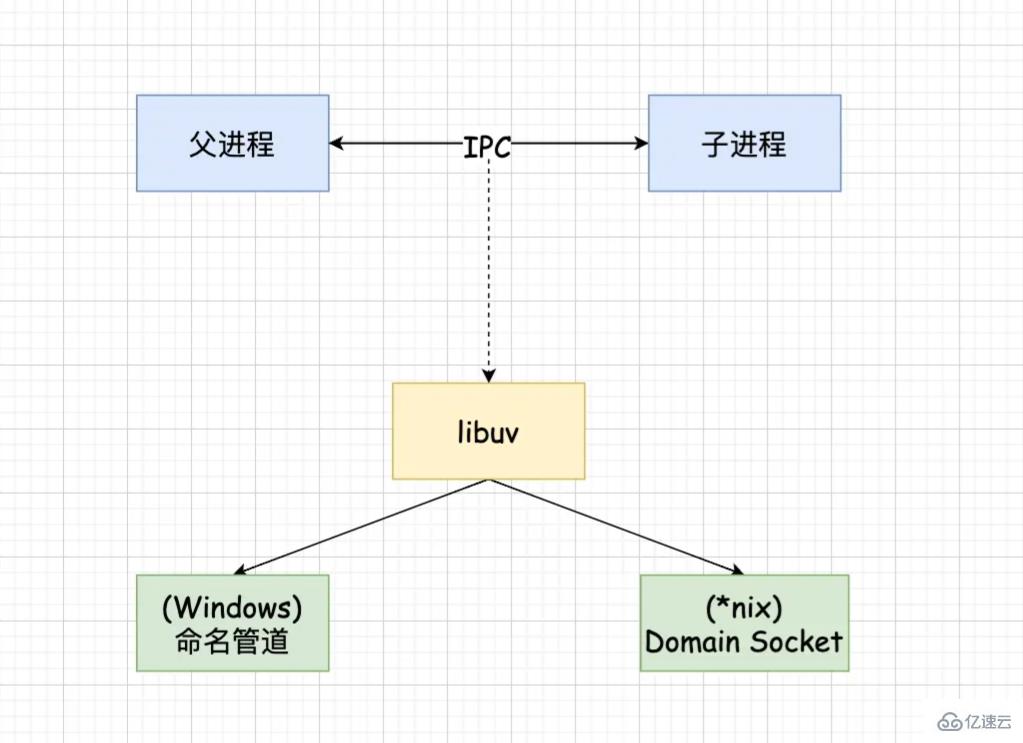
NodeдёӯйҖҡдҝЎеҺҹзҗҶ
Node дёӯзҡ„ IPC йҖҡйҒ“е…·дҪ“е®һзҺ°жҳҜз”ұ libuv жҸҗдҫӣзҡ„гҖӮж №жҚ®зі»з»ҹзҡ„дёҚеҗҢе®һзҺ°ж–№ејҸдёҚеҗҢпјҢwindow дёӢйҮҮз”Ёе‘ҪеҗҚз®ЎйҒ“е®һзҺ°пјҢ*nix дёӢйҮҮз”Ё Domain Socket е®һзҺ°гҖӮеңЁеә”з”ЁеұӮеҸӘдҪ“зҺ°дёә message дәӢ件е’Ң send ж–№жі•гҖӮ
зҲ¶иҝӣзЁӢеңЁе®һйҷ…еҲӣе»әеӯҗиҝӣзЁӢд№ӢеүҚпјҢдјҡеҲӣе»ә IPC йҖҡйҒ“并зӣ‘еҗ¬е®ғпјҢзӯүеҲ°еҲӣе»әеҮәзңҹе®һзҡ„еӯҗиҝӣзЁӢеҗҺпјҢйҖҡиҝҮзҺҜеўғеҸҳйҮҸ(NODE_CHANNEL_FD)е‘ҠиҜүеӯҗиҝӣзЁӢиҜҘ IPC йҖҡйҒ“зҡ„ж–Ү件жҸҸиҝ°з¬ҰгҖӮ
еӯҗиҝӣзЁӢеңЁеҗҜеҠЁзҡ„иҝҮзЁӢдёӯпјҢдјҡж №жҚ®иҜҘж–Ү件жҸҸиҝ°з¬ҰеҺ»иҝһжҺҘ IPC йҖҡйҒ“пјҢд»ҺиҖҢе®ҢжҲҗзҲ¶еӯҗиҝӣзЁӢзҡ„иҝһжҺҘгҖӮ
е»әз«ӢиҝһжҺҘд№ӢеҗҺеҸҜд»ҘиҮӘз”ұзҡ„йҖҡдҝЎдәҶпјҢIPC йҖҡйҒ“жҳҜдҪҝз”Ёе‘ҪеҗҚз®ЎйҒ“жҲ–иҖ… Domain Socket еҲӣе»әзҡ„пјҢеұһдәҺеҸҢеҗ‘йҖҡдҝЎгҖӮ并且е®ғжҳҜеңЁзі»з»ҹеҶ…ж ёдёӯе®ҢжҲҗзҡ„иҝӣзЁӢйҖҡдҝЎ
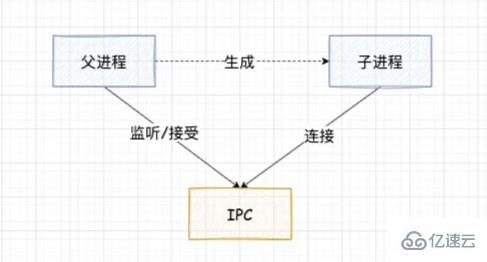
вҡ пёҸ еҸӘжңүеңЁеҗҜеҠЁзҡ„еӯҗиҝӣзЁӢжҳҜ Node иҝӣзЁӢж—¶пјҢеӯҗиҝӣзЁӢжүҚдјҡж №жҚ®зҺҜеўғеҸҳйҮҸеҺ»иҝһжҺҘеҜ№еә”зҡ„ IPC йҖҡйҒ“пјҢеҜ№дәҺе…¶д»–зұ»еһӢзҡ„еӯҗиҝӣзЁӢеҲҷж— жі•е®һзҺ°иҝӣзЁӢй—ҙйҖҡдҝЎпјҢйҷӨйқһе…¶д»–иҝӣзЁӢд№ҹжҢүзқҖиҜҘзәҰе®ҡеҺ»иҝһжҺҘиҝҷдёӘ IPC йҖҡйҒ“гҖӮ
unix domain socket
жҳҜд»Җд№Ҳ
жҲ‘们зҹҘйҒ“з»Ҹе…ёзҡ„йҖҡдҝЎж–№ејҸжҳҜжңү SocketпјҢжҲ‘们平时зҶҹзҹҘзҡ„ Socket жҳҜеҹәдәҺзҪ‘з»ңеҚҸи®®зҡ„пјҢз”ЁдәҺдёӨдёӘдёҚеҗҢдё»жңәдёҠзҡ„дёӨдёӘиҝӣзЁӢйҖҡдҝЎпјҢйҖҡдҝЎйңҖиҰҒжҢҮе®ҡ IP/Host зӯүгҖӮ
дҪҶеҰӮжһңжҲ‘们еҗҢдёҖеҸ°дё»жңәдёҠзҡ„дёӨдёӘиҝӣзЁӢжғіиҰҒйҖҡдҝЎпјҢеҰӮжһңдҪҝз”Ё Socket йңҖиҰҒжҢҮе®ҡ IP/HostпјҢз»ҸиҝҮзҪ‘з»ңеҚҸи®®зӯүпјҢдјҡжҳҫеҫ—иҝҮдәҺз№ҒзҗҗгҖӮжүҖд»Ҙ Unix Domain Socket иҜһз”ҹдәҶгҖӮ
UDS зҡ„дјҳеҠҝпјҡ
з»‘е®ҡ socket ж–Ү件иҖҢдёҚжҳҜз»‘е®ҡ IP/HostпјӣдёҚйңҖиҰҒз»ҸиҝҮзҪ‘з»ңеҚҸи®®пјҢиҖҢжҳҜж•°жҚ®зҡ„жӢ·иҙқ
д№ҹж”ҜжҢҒ SOCK_STREAM(жөҒеҘ—жҺҘеӯ—)е’Ң SOCK_DGRAM(ж•°жҚ®еҢ…еҘ—жҺҘеӯ—)пјҢдҪҶз”ұдәҺжҳҜеңЁжң¬жңәйҖҡиҝҮеҶ…ж ёйҖҡдҝЎпјҢдёҚдјҡдёўеҢ…д№ҹдёҚдјҡеҮәзҺ°еҸ‘йҖҒеҢ…зҡ„ж¬ЎеәҸе’ҢжҺҘ收еҢ…зҡ„ж¬ЎеәҸдёҚдёҖиҮҙзҡ„й—®йўҳ
еҰӮдҪ•е®һзҺ°
жөҒзЁӢеӣҫ
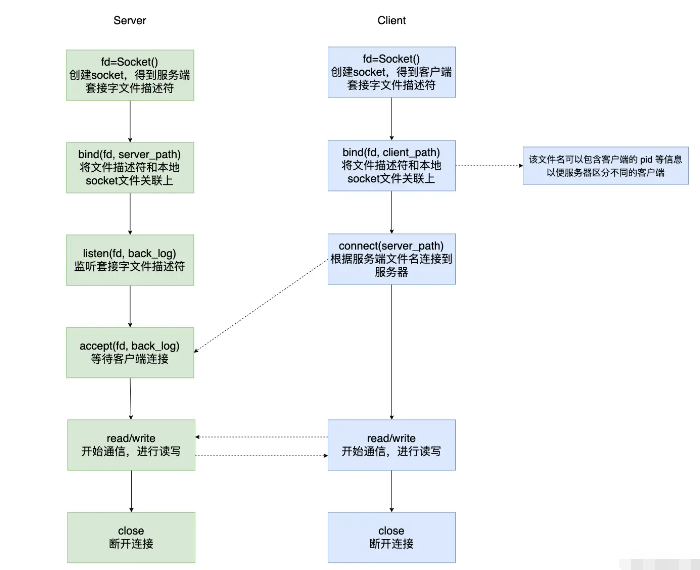
Server з«Ҝ
int main(int argc, char *argv[])
{
int server_fd ,ret, client_fd;
struct sockaddr_un serv, client;
socklen_t len = sizeof(client);
char buf[1024] = {0};
int recvlen;
// еҲӣе»ә socket
server_fd = socket(AF_LOCAL, SOCK_STREAM, 0);
// еҲқе§ӢеҢ– server дҝЎжҒҜ
serv.sun_family = AF_LOCAL;
strcpy(serv.sun_path, "server.sock");
// з»‘е®ҡ
ret = bind(server_fd, (struct sockaddr *)&serv, sizeof(serv));
//и®ҫзҪ®зӣ‘еҗ¬пјҢи®ҫзҪ®иғҪеӨҹеҗҢж—¶е’ҢжңҚеҠЎз«ҜиҝһжҺҘзҡ„е®ўжҲ·з«Ҝж•°йҮҸ
ret = listen(server_fd, 36);
//зӯүеҫ…е®ўжҲ·з«ҜиҝһжҺҘ
client_fd = accept(server_fd, (struct sockaddr *)&client, &len);
printf("=====client bind file:%s\n", client.sun_path);
while (1) {
recvlen = recv(client_fd, buf, sizeof(buf), 0);
if (recvlen == -1) {
perror("recv error");
return -1;
} else if (recvlen == 0) {
printf("client disconnet...\n");
close(client_fd);
break;
} else {
printf("recv buf %s\n", buf);
send(client_fd, buf, recvlen, 0);
}
}
close(client_fd);
close(server_fd);
return 0;
}Client з«Ҝ
int main(int argc, char *argv[])
{
int client_fd ,ret;
struct sockaddr_un serv, client;
socklen_t len = sizeof(client);
char buf[1024] = {0};
int recvlen;
//еҲӣе»әsocket
client_fd = socket(AF_LOCAL, SOCK_STREAM, 0);
//з»ҷе®ўжҲ·з«Ҝз»‘е®ҡдёҖдёӘеҘ—жҺҘеӯ—ж–Ү件
client.sun_family = AF_LOCAL;
strcpy(client.sun_path, "client.sock");
ret = bind(client_fd, (struct sockaddr *)&client, sizeof(client));
//еҲқе§ӢеҢ–serverдҝЎжҒҜ
serv.sun_family = AF_LOCAL;
strcpy(serv.sun_path, "server.sock");
//иҝһжҺҘ
connect(client_fd, (struct sockaddr *)&serv, sizeof(serv));
while (1) {
fgets(buf, sizeof(buf), stdin);
send(client_fd, buf, strlen(buf)+1, 0);
recv(client_fd, buf, sizeof(buf), 0);
printf("recv buf %s\n", buf);
}
close(client_fd);
return 0;
}е‘ҪеҗҚз®ЎйҒ“(Named Pipe)
жҳҜд»Җд№Ҳ
е‘ҪеҗҚз®ЎйҒ“жҳҜеҸҜд»ҘеңЁеҗҢдёҖеҸ°и®Ўз®—жңәзҡ„дёҚеҗҢиҝӣзЁӢд№Ӣй—ҙпјҢжҲ–иҖ…и·Ёи¶ҠдёҖдёӘзҪ‘з»ңзҡ„дёҚеҗҢи®Ўз®—жңәзҡ„дёҚеҗҢиҝӣзЁӢд№Ӣй—ҙзҡ„еҸҜйқ зҡ„еҚ•еҗ‘жҲ–иҖ…еҸҢеҗ‘зҡ„ж•°жҚ®йҖҡдҝЎгҖӮ
еҲӣе»әе‘ҪеҗҚз®ЎйҒ“зҡ„иҝӣзЁӢиў«з§°дёәз®ЎйҒ“жңҚеҠЎз«Ҝ(Pipe Server)пјҢиҝһжҺҘеҲ°иҝҷдёӘз®ЎйҒ“зҡ„иҝӣзЁӢз§°дёәз®ЎйҒ“е®ўжҲ·з«Ҝ(Pipe Client)гҖӮ
е‘ҪеҗҚз®ЎйҒ“зҡ„е‘ҪеҗҚ规иҢғпјҡ\server\pipe[\path]\name
е…¶дёӯ server жҢҮе®ҡдёҖдёӘжңҚеҠЎеҷЁзҡ„еҗҚеӯ—пјҢжң¬жңәйҖӮз”Ё \. иЎЁзӨәпјҢ\192.10.10.1 иЎЁзӨәзҪ‘з»ңдёҠзҡ„жңҚеҠЎеҷЁ
\pipe жҳҜдёҖдёӘдёҚеҸҜеҸҳеҢ–зҡ„еӯ—дёІпјҢз”ЁдәҺжҢҮе®ҡиҜҘж–Ү件еұһдәҺ NPFS(Named Pipe File System)
[\path]\name жҳҜе”ҜдёҖе‘ҪеҗҚз®ЎйҒ“еҗҚз§°зҡ„ж ҮиҜҶ
жҖҺд№Ҳе®һзҺ°
жөҒзЁӢеӣҫ
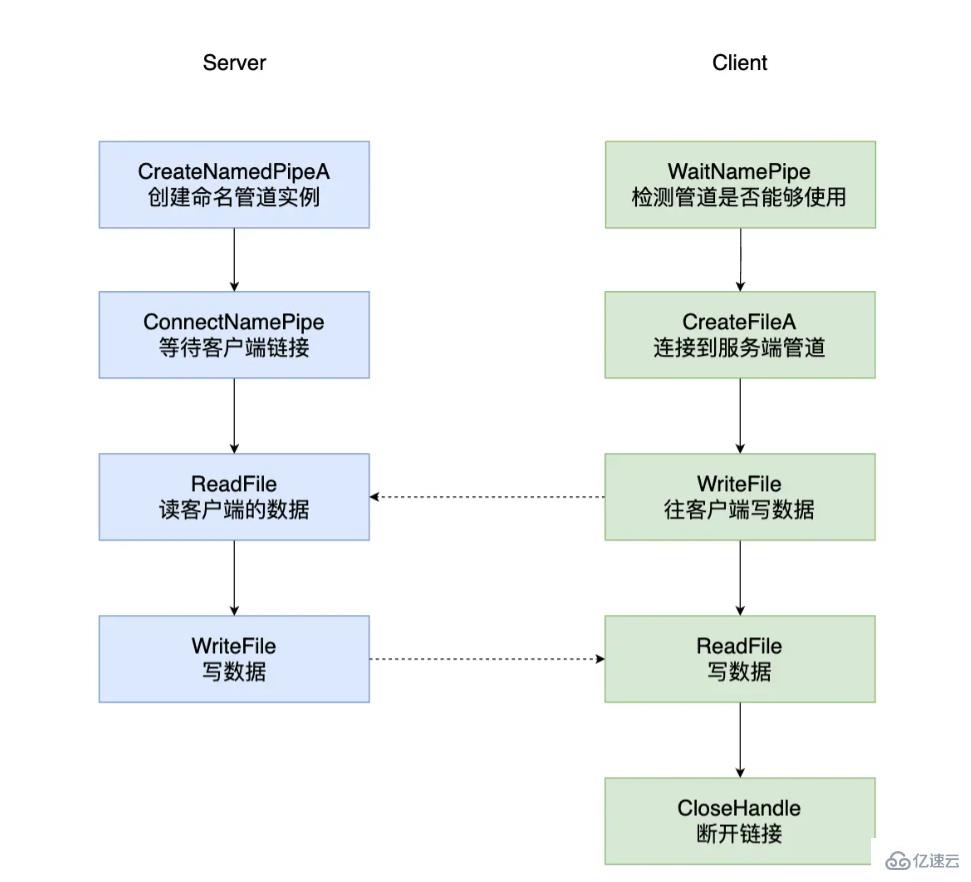
Pipe Server
void ServerTest()
{
HANDLE serverNamePipe;
char pipeName[MAX_PATH] = {0};
char szReadBuf[MAX_BUFFER] = {0};
char szWriteBuf[MAX_BUFFER] = {0};
DWORD dwNumRead = 0;
DWORD dwNumWrite = 0;
strcpy(pipeName, "\\\\.\\pipe\\shuangxuPipeTest");
// еҲӣе»әз®ЎйҒ“е®һдҫӢ
serverNamePipe = CreateNamedPipeA(pipeName,
PIPE_ACCESS_DUPLEX|FILE_FLAG_WRITE_THROUGH,
PIPE_TYPE_BYTE|PIPE_READMODE_BYTE|PIPE_WAIT,
PIPE_UNLIMITED_INSTANCES, 0, 0, 0, NULL);
WriteLog("еҲӣе»әз®ЎйҒ“жҲҗеҠҹ...");
// зӯүеҫ…е®ўжҲ·з«ҜиҝһжҺҘ
BOOL bRt= ConnectNamedPipe(serverNamePipe, NULL );
WriteLog( "收еҲ°е®ўжҲ·з«Ҝзҡ„иҝһжҺҘжҲҗеҠҹ...");
// жҺҘ收数жҚ®
memset( szReadBuf, 0, MAX_BUFFER );
bRt = ReadFile(serverNamePipe, szReadBuf, MAX_BUFFER-1, &dwNumRead, NULL );
// дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶ пјҲеҸӘдёәжөӢиҜ•з”Ёиҝ”еӣһеҺҹжқҘзҡ„ж•°жҚ®пјү
WriteLog( "收еҲ°е®ўжҲ·ж•°жҚ®:[%s]", szReadBuf);
// еҸ‘йҖҒж•°жҚ®
if( !WriteFile(serverNamePipe, szWriteBuf, dwNumRead, &dwNumWrite, NULL ) )
{
WriteLog("еҗ‘е®ўжҲ·еҶҷе…Ҙж•°жҚ®еӨұиҙҘ:[%#x]", GetLastError());
return ;
}
WriteLog("еҶҷе…Ҙж•°жҚ®жҲҗеҠҹ...");
}Pipe Client
void ClientTest()
{
char pipeName[MAX_PATH] = {0};
HANDLE clientNamePipe;
DWORD dwRet;
char szReadBuf[MAX_BUFFER] = {0};
char szWriteBuf[MAX_BUFFER] = {0};
DWORD dwNumRead = 0;
DWORD dwNumWrite = 0;
strcpy(pipeName, "\\\\.\\pipe\\shuangxuPipeTest");
// жЈҖжөӢз®ЎйҒ“жҳҜеҗҰеҸҜз”Ё
if(!WaitNamedPipeA(pipeName, 10000)){
WriteLog("з®ЎйҒ“[%s]ж— жі•жү“ејҖ", pipeName);
return ;
}
// иҝһжҺҘз®ЎйҒ“
clientNamePipe = CreateFileA(pipeName,
GENERIC_READ|GENERIC_WRITE,
0,
NULL,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
NULL);
WriteLog("з®ЎйҒ“иҝһжҺҘжҲҗеҠҹ...");
scanf( "%s", szWritebuf );
// еҸ‘йҖҒж•°жҚ®
if( !WriteFile(clientNamePipe, szWriteBuf, strlen(szWriteBuf), &dwNumWrite, NULL)){
WriteLog("еҸ‘йҖҒж•°жҚ®еӨұиҙҘ,GetLastError=[%#x]", GetLastError());
return ;
}
printf("еҸ‘йҖҒж•°жҚ®жҲҗеҠҹ:%s\n", szWritebuf );
// жҺҘ收数жҚ®
if( !ReadFile(clientNamePipe, szReadBuf, MAX_BUFFER-1, &dwNumRead, NULL)){
WriteLog("жҺҘ收数жҚ®еӨұиҙҘ,GetLastError=[%#x]", GetLastError() );
return ;
}
WriteLog( "жҺҘ收еҲ°жңҚеҠЎеҷЁиҝ”еӣһ:%s", szReadBuf );
// е…ій—ӯз®ЎйҒ“
CloseHandle(clientNamePipe);
}Node еҲӣе»әеӯҗиҝӣзЁӢзҡ„жөҒзЁӢ
Unix
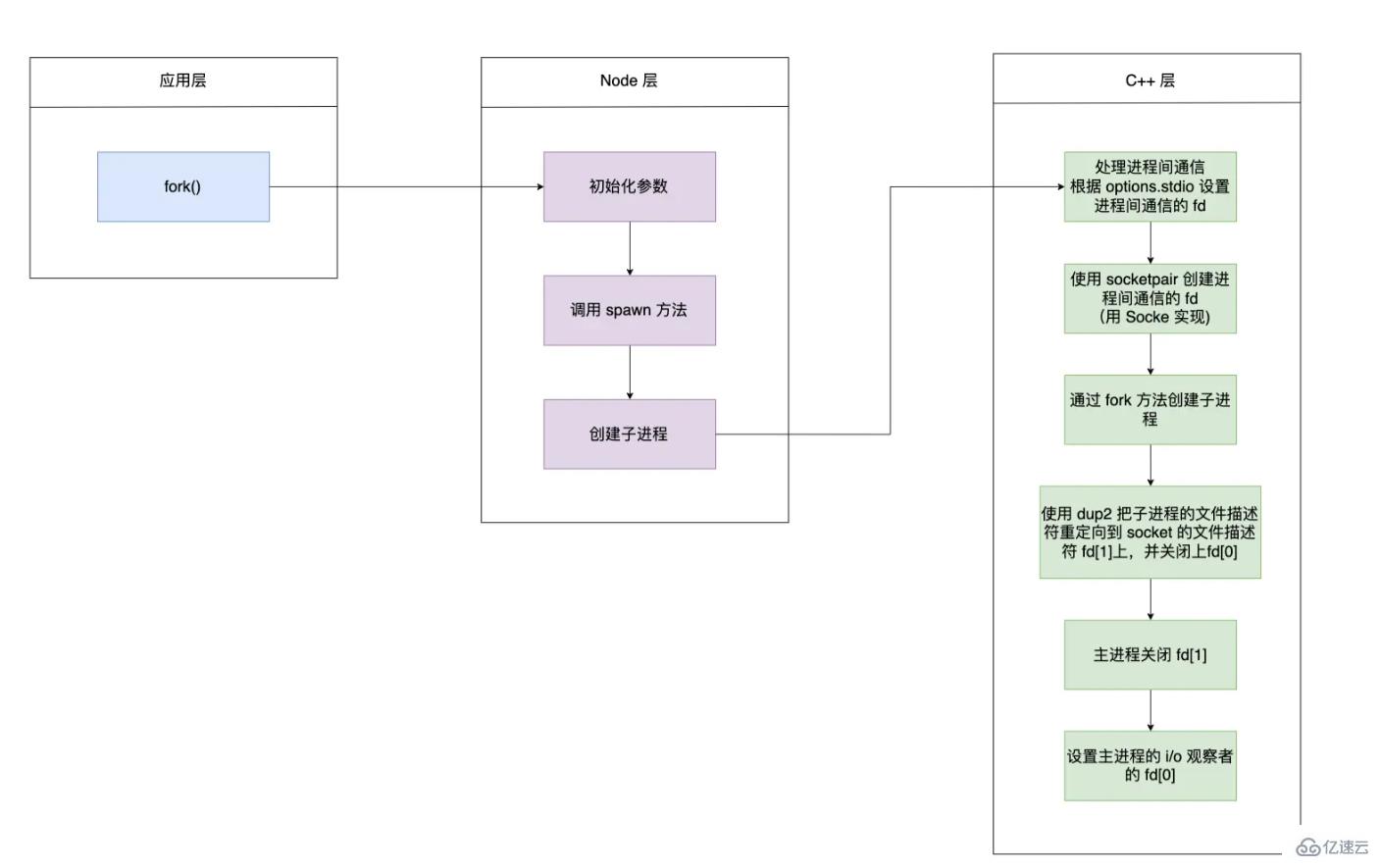
еҜ№дәҺеҲӣе»әеӯҗиҝӣзЁӢгҖҒеҲӣе»әз®ЎйҒ“гҖҒйҮҚе®ҡеҗ‘з®ЎйҒ“еқҮжҳҜеңЁ c++ еұӮе®һзҺ°зҡ„
еҲӣе»әеӯҗиҝӣзЁӢ
int main(int argc,char *argv[]){
pid_t pid = fork();
if (pid < 0) {
// й”ҷиҜҜ
} else if(pid == 0) {
// еӯҗиҝӣзЁӢ
} else {
// зҲ¶иҝӣзЁӢ
}
}еҲӣе»әз®ЎйҒ“
дҪҝз”Ё socketpair еҲӣе»әз®ЎйҒ“пјҢе…¶еҲӣе»әеҮәжқҘзҡ„з®ЎйҒ“жҳҜе…ЁеҸҢе·Ҙзҡ„пјҢиҝ”еӣһзҡ„ж–Ү件жҸҸиҝ°з¬Ұдёӯзҡ„д»»дҪ•дёҖдёӘйғҪеҸҜиҜ»е’ҢеҸҜеҶҷ
int main ()
{
int fd[2];
int r = socketpair(AF_UNIX, SOCK_STREAM, 0, fd);
if (fork()){ /* зҲ¶иҝӣзЁӢ */
int val = 0;
close(fd[1]);
while (1){
sleep(1);
++val;
printf("еҸ‘йҖҒж•°жҚ®: %d\n", val);
write(fd[0], &val, sizeof(val));
read(fd[0], &val, sizeof(val));
printf("жҺҘ收数жҚ®: %d\n", val);
}
} else { /*еӯҗиҝӣзЁӢ*/
int val;
close(fd[0]);
while(1){
read(fd[1], &val, sizeof(val));
++val;
write(fd[1], &val, sizeof(val));
}
}
}еҪ“жҲ‘们дҪҝз”Ё socketpair еҲӣе»әдәҶз®ЎйҒ“д№ӢеҗҺпјҢзҲ¶иҝӣзЁӢе…ій—ӯдәҶ fd[1]пјҢеӯҗиҝӣзЁӢе…ій—ӯдәҶ fd[0]гҖӮеӯҗиҝӣзЁӢеҸҜд»ҘйҖҡиҝҮ fd[1] иҜ»еҶҷж•°жҚ®пјӣеҗҢзҗҶдё»иҝӣзЁӢйҖҡиҝҮ fd[0]иҜ»еҶҷж•°жҚ®е®ҢжҲҗйҖҡдҝЎгҖӮ
еҜ№еә”д»Јз Ғпјҡhttps://github.com/nodejs/node/blob/main/deps/uv/src/unix/process.c#L344
child_process.fork зҡ„иҜҰз»Ҷи°ғз”Ё
fork еҮҪж•°ејҖеҗҜдёҖдёӘеӯҗиҝӣзЁӢзҡ„жөҒзЁӢ
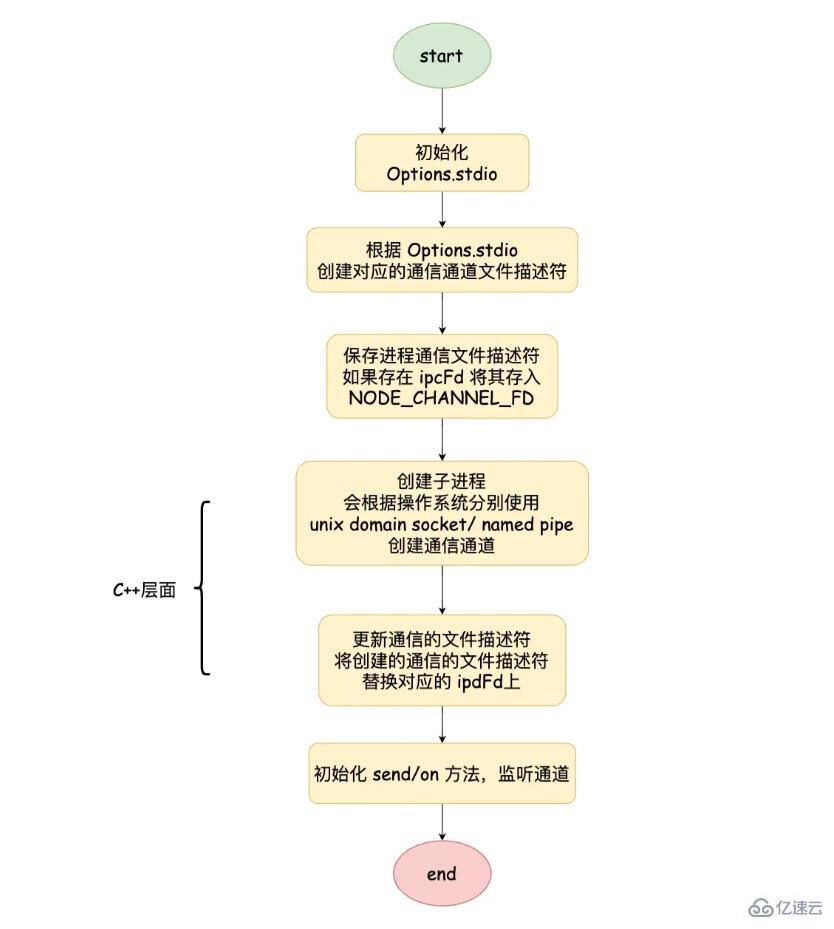
еҲқе§ӢеҢ–еҸӮж•°дёӯзҡ„ options.stdioпјҢ并且и°ғз”Ё spawn еҮҪж•°
function spawn(file, args, options) {
const child = new ChildProcess();
child.spawn(options);
}еҲӣе»ә ChildProcess е®һдҫӢпјҢеҲӣе»әеӯҗиҝӣзЁӢд№ҹжҳҜи°ғз”Ё C++ еұӮ this._handle.spawn ж–№жі•
function ChildProcess() {
// C++еұӮе®ҡд№ү
this._handle = new Process();
}йҖҡиҝҮ child.spawn и°ғз”ЁеҲ° ChildProcess.prototype.spawn ж–№жі•дёӯгҖӮе…¶дёӯ getValidStdio ж–№жі•дјҡж №жҚ® options.stdio еҲӣе»әе’Ң C++ дәӨдә’зҡ„ Pipe еҜ№иұЎпјҢ并иҺ·еҫ—еҜ№еә”зҡ„ж–Ү件жҸҸиҝ°з¬ҰпјҢе°Ҷж–Ү件жҸҸиҝ°з¬ҰеҶҷе…ҘеҲ°зҺҜеўғеҸҳйҮҸ NODE_CHANNEL_FD дёӯпјҢи°ғз”Ё C++ еұӮеҲӣе»әеӯҗиҝӣзЁӢпјҢеңЁи°ғз”Ё setupChannel ж–№жі•
ChildProcess.prototype.spawn = function(options) {
// йў„еӨ„зҗҶиҝӣзЁӢй—ҙйҖҡдҝЎзҡ„ж•°жҚ®з»“жһ„
stdio = getValidStdio(stdio, false);
const ipc = stdio.ipc;
const ipcFd = stdio.ipcFd;
//е°Ҷж–Ү件жҸҸиҝ°з¬ҰеҶҷе…ҘзҺҜеўғеҸҳйҮҸдёӯ
if (ipc !== undefined) {
ArrayPrototypePush(options.envPairs, `NODE_CHANNEL_FD=${ipcFd}`);
}
// еҲӣе»әиҝӣзЁӢ
const err = this._handle.spawn(options);
// ж·»еҠ sendж–№жі•е’Ңзӣ‘еҗ¬IPCдёӯж•°жҚ®
if (ipc !== undefined) setupChannel(this, ipc, serialization);
}еӯҗиҝӣзЁӢеҗҜеҠЁж—¶пјҢдјҡж №жҚ®зҺҜеўғеҸҳйҮҸдёӯжҳҜеҗҰеӯҳеңЁ NODE_CHANNEL_FD еҲӨж–ӯжҳҜеҗҰи°ғз”Ё _forkChild ж–№жі•пјҢеҲӣе»әдёҖдёӘ Pipe еҜ№иұЎ, еҗҢж—¶и°ғз”Ё open ж–№жі•жү“ејҖеҜ№еә”зҡ„ж–Ү件жҸҸиҝ°з¬ҰпјҢеңЁи°ғз”ЁsetupChannel
function _forkChild(fd, serializationMode) {
const p = new Pipe(PipeConstants.IPC);
p.open(fd);
p.unref();
const control = setupChannel(process, p, serializationMode);
}
еҸҘжҹ„дј йҖ’
setupChannel
дё»иҰҒжҳҜе®ҢжҲҗдәҶеӨ„зҗҶжҺҘ收зҡ„ж¶ҲжҒҜгҖҒеҸ‘йҖҒж¶ҲжҒҜгҖҒеӨ„зҗҶж–Ү件жҸҸиҝ°з¬Ұдј йҖ’зӯү
function setipChannel(){
channel.onread = function(arrayBuffer){
//...
}
target.on('internalMessage', function(message, handle){
//...
})
target.send = function(message, handle, options, callback){
//...
}
target._send = function(message, handle, options, callback){
//...
}
function handleMessage(message, handle, internal){
//...
}
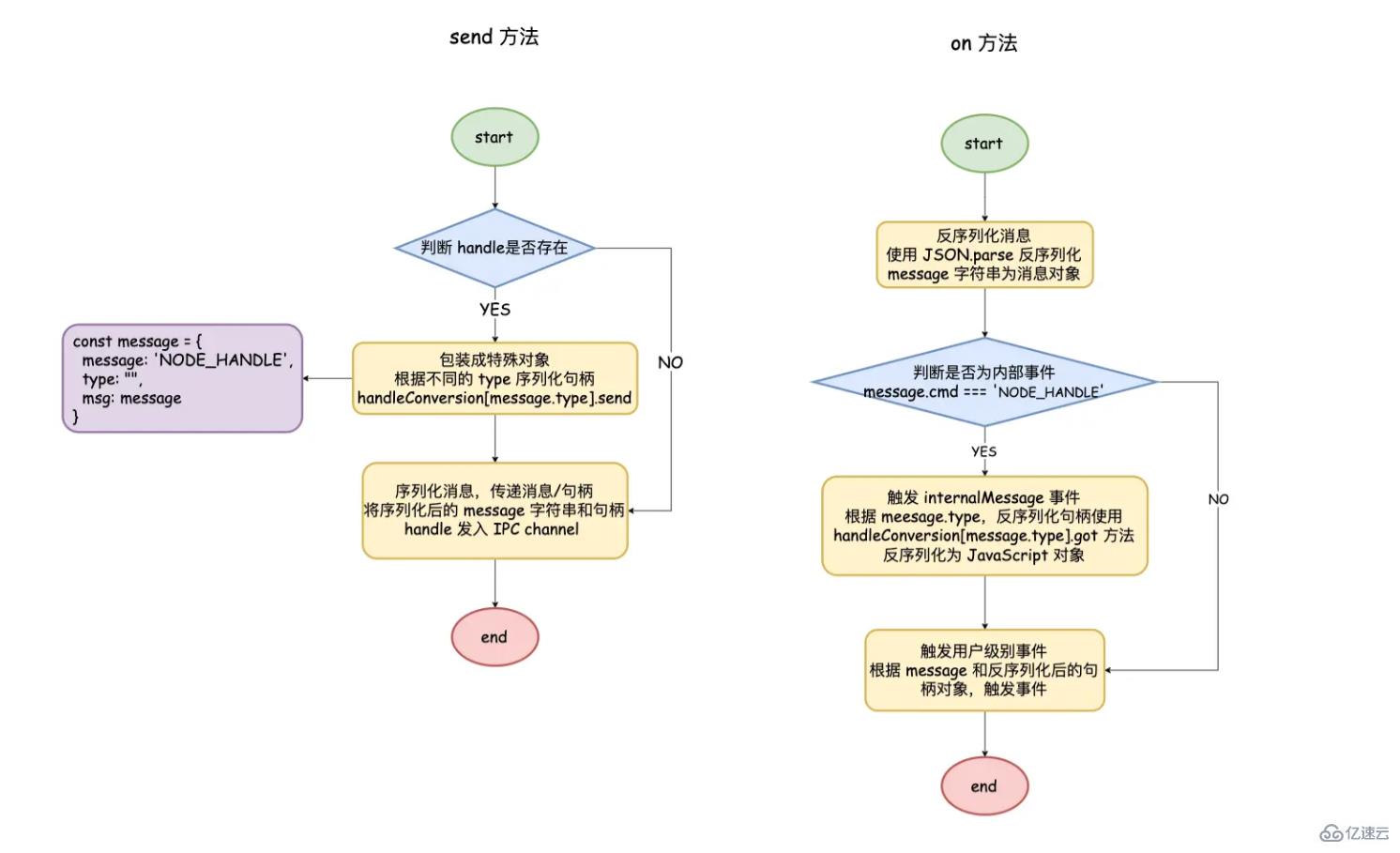
}target.send: process.send ж–№жі•пјҢиҝҷйҮҢ target е°ұжҳҜиҝӣзЁӢеҜ№иұЎжң¬иә«.
target._send: жү§иЎҢе…·дҪ“ send йҖ»иҫ‘зҡ„еҮҪж•°, еҪ“еҸӮж•° handle дёҚеӯҳеңЁж—¶, иЎЁзӨәжҷ®йҖҡзҡ„ж¶ҲжҒҜдј йҖ’пјӣиӢҘеӯҳеңЁпјҢеҢ…иЈ…дёәеҶ…йғЁеҜ№иұЎпјҢиЎЁжҳҺжҳҜдёҖдёӘ internalMessage дәӢ件и§ҰеҸ‘гҖӮи°ғз”ЁдҪҝз”ЁJSON.stringify еәҸеҲ—еҢ–еҜ№иұЎ, дҪҝз”Ёchannel.writeUtf8String еҶҷе…Ҙж–Ү件жҸҸиҝ°з¬Ұдёӯ
channel.onread: иҺ·еҸ–еҲ°ж•°жҚ®ж—¶и§ҰеҸ‘, и·ҹ channel.writeUtf8String зӣёеҜ№еә”гҖӮйҖҡиҝҮ JSON.parse еҸҚеәҸеҲ—еҢ– message д№ӢеҗҺ, и°ғз”Ё handleMessage иҝӣиҖҢи§ҰеҸ‘еҜ№еә”дәӢ件
handleMessage: з”ЁжқҘеҲӨж–ӯжҳҜи§ҰеҸ‘ message дәӢ件иҝҳжҳҜ internalMessage дәӢ件
target.on('internalMessage'): й’ҲеҜ№еҶ…йғЁеҜ№иұЎеҒҡзү№ж®ҠеӨ„зҗҶпјҢеңЁи°ғз”Ё message дәӢ件
иҝӣзЁӢй—ҙж¶ҲжҒҜдј йҖ’
зҲ¶иҝӣзЁӢйҖҡиҝҮ child.send еҸ‘йҖҒж¶ҲжҒҜ е’Ң server/socket еҸҘжҹ„еҜ№иұЎ
жҷ®йҖҡж¶ҲжҒҜзӣҙжҺҘ JSON.stringify еәҸеҲ—еҢ–пјӣеҜ№дәҺеҸҘжҹ„еҜ№иұЎжқҘиҜҙпјҢйңҖиҰҒе…ҲеҢ…иЈ…жҲҗдёәеҶ…йғЁеҜ№иұЎ
message = {
cmd: 'NODE_HANDLE',
type: null,
msg: message
};йҖҡиҝҮ handleConversion.[message.type].send зҡ„ж–№жі•еҸ–еҮәеҸҘжҹ„еҜ№иұЎеҜ№еә”зҡ„ C++ еұӮйқўзҡ„ TCP еҜ№иұЎпјҢеңЁйҮҮз”ЁJSON.stringify еәҸеҲ—еҢ–
const handleConversion = {
'net.Server': {
simultaneousAccepts: true,
send(message, server, options) {
return server._handle;
},
got(message, handle, emit) {
const server = new net.Server();
server.listen(handle, () => {
emit(server);
});
}
}
//....
}жңҖеҗҺе°ҶеәҸеҲ—еҢ–еҗҺзҡ„еҶ…йғЁеҜ№иұЎе’Ң TCP еҜ№иұЎеҶҷе…ҘеҲ° IPC йҖҡйҒ“дёӯ
еӯҗиҝӣзЁӢеңЁжҺҘ收еҲ°ж¶ҲжҒҜд№ӢеҗҺпјҢдҪҝз”Ё JSON.parse еҸҚеәҸеҲ—еҢ–ж¶ҲжҒҜпјҢеҰӮжһңдёәеҶ…йғЁеҜ№иұЎи§ҰеҸ‘ internalMessage дәӢ件
жЈҖжҹҘжҳҜеҗҰеёҰжңү TCP еҜ№иұЎпјҢйҖҡиҝҮ handleConversion.[message.type].got еҫ—еҲ°е’ҢзҲ¶иҝӣзЁӢдёҖж ·зҡ„еҸҘжҹ„еҜ№иұЎ
жңҖеҗҺеҸ‘и§ҰеҸ‘ message дәӢд»¶дј йҖ’еӨ„зҗҶеҘҪзҡ„ж¶ҲжҒҜе’ҢеҸҘжҹ„еҜ№иұЎпјҢеӯҗиҝӣзЁӢйҖҡиҝҮ process.on жҺҘ收
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңNodeдёӯзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎжҖҺд№Ҳе®һзҺ°вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





