MySQLзҙўеј•жңҖе·ҰеҢ№й…ҚеҺҹеҲҷжҳҜд»Җд№Ҳ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңMySQLзҙўеј•жңҖе·ҰеҢ№й…ҚеҺҹеҲҷжҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еҮҶеӨҮ
дёәдәҶж–№йқўеҗҺз»ӯзҡ„иҜҙжҳҺпјҢжҲ‘们йҰ–е…Ҳе»әз«ӢдёҖдёӘеҰӮдёӢзҡ„иЎЁпјҲMySQL5.7пјүпјҢиЎЁдёӯе…ұжңү5дёӘеӯ—ж®өпјҲaгҖҒbгҖҒcгҖҒdгҖҒeпјүпјҢе…¶дёӯaдёәдё»й”®пјҢжңүдёҖдёӘз”ұbпјҢcпјҢdз»„жҲҗзҡ„иҒ”еҗҲзҙўеј•пјҢеӯҳеӮЁеј•ж“ҺдёәInnoDBпјҢжҸ’е…ҘдёүжқЎжөӢиҜ•ж•°жҚ®гҖӮејәзғҲе»әи®®иҮӘе·ұеңЁMySQLдёӯе°қиҜ•жң¬ж–Үзҡ„жүҖжңүиҜӯеҸҘгҖӮ
CREATE TABLE `test` (
`a` int NOT NULL AUTO_INCREMENT,
`b` int DEFAULT NULL,
`c` int DEFAULT NULL,
`d` int DEFAULT NULL,
`e` int DEFAULT NULL,
PRIMARY KEY(`a`),
KEY `idx_abc` (`b`,`c`,`d`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5);
INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5);
INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
иҝҷж—¶еҖҷпјҢжҲ‘们еҰӮжһңжү§иЎҢдёӢйқўиҝҷдёӘSQLиҜӯеҸҘпјҢдҪ и§үеҫ—дјҡиө°зҙўеј•еҗ—пјҹ
SELECT b, c, d FROM test WHERE d = 2;
еҰӮжһңдҪ жҢүз…§жңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҲз®Җиҝ°дёәеңЁиҒ”еҗҲзҙўеј•дёӯпјҢд»ҺжңҖе·Ұиҫ№зҡ„еӯ—ж®өејҖе§ӢеҢ№й…ҚпјҢиӢҘжқЎд»¶дёӯеӯ—ж®өеңЁиҒ”еҗҲзҙўеј•дёӯз¬ҰеҗҲд»Һе·ҰеҲ°еҸізҡ„йЎәеәҸеҲҷиө°зҙўеј•пјҢеҗҰеҲҷдёҚиө°пјҢеҸҜд»Ҙз®ҖеҚ•зҗҶи§Јдёә(a, b, c)зҡ„иҒ”еҗҲзҙўеј•зӣёеҪ“дәҺеҲӣе»әдәҶaзҙўеј•гҖҒ(a, b)зҙўеј•е’Ң(a, b, c)зҙўеј•пјүпјҢиҝҷеҸҘжҳҫ然жҳҜдёҚз¬ҰеҗҲиҝҷдёӘ规еҲҷзҡ„пјҢе®ғиө°дёҚдәҶзҙўеј•пјҢдҪҶжҳҜжҲ‘们用EXPLAINиҜӯеҸҘеҲҶжһҗпјҢдјҡеҸ‘зҺ°дёҖдёӘеҫҲжңүи¶Јзҡ„зҺ°иұЎпјҢе®ғзҡ„иҫ“еҮәеҰӮдёӢжҳҜдҪҝз”ЁдәҶзҙўеј•зҡ„гҖӮ

иҝҷе°ұеҫҲеҘҮжҖӘдәҶпјҢжңҖе·ҰеҢ№й…ҚеҺҹеҲҷеӨұж•ҲдәҶеҗ—пјҹдәӢе®һдёҠпјҢ并没жңүпјҢжҲ‘们дёҖжӯҘжӯҘжқҘеҲҶжһҗгҖӮ
зҗҶи®әиҜҰи§Ј
з”ұдәҺзҺ°еңЁеҹәжң¬дёҠд»ҘInnoDBеј•ж“Һдёәдё»пјҢжҲ‘们д»ҘInnoDBдёәдҫӢиҝӣиЎҢдё»иҰҒиҜҙжҳҺгҖӮ
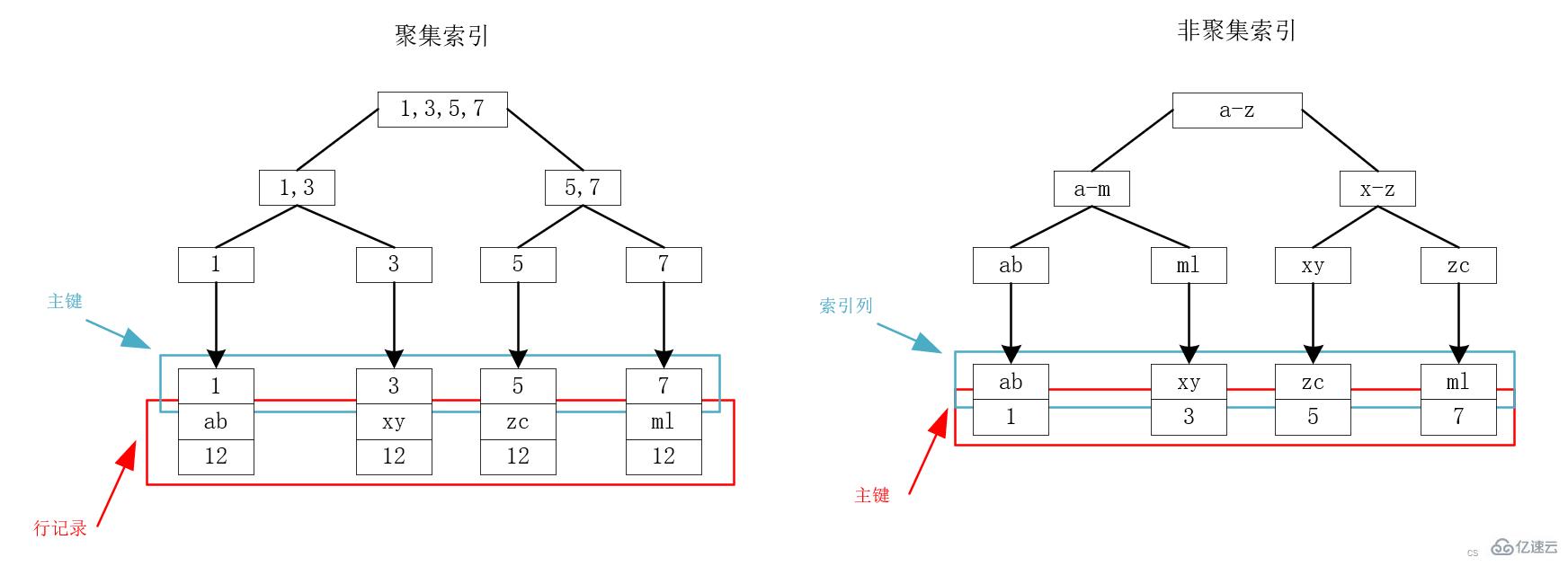
иҒҡйӣҶзҙўеј•е’ҢйқһиҒҡйӣҶзҙўеј•
MySQLеә•еұӮдҪҝз”ЁB+ж ‘жқҘеӯҳеӮЁзҙўеј•пјҢж•°жҚ®еқҮеӯҳеңЁеҸ¶еӯҗиҠӮзӮ№дёҠгҖӮеҜ№дәҺInnoDBиҖҢиЁҖпјҢдё»й”®зҙўеј•е’ҢиЎҢи®°еҪ•ж—¶еӯҳеӮЁеңЁдёҖиө·зҡ„пјҢеӣ жӯӨеҸ«еҒҡиҒҡйӣҶзҙўеј•пјҲclustered indexпјүгҖӮйҷӨдәҶиҒҡйӣҶзҙўеј•пјҢе…¶д»–жүҖжңүйғҪеҸ«еҒҡйқһиҒҡйӣҶзҙўеј•пјҲsecondary indexпјүпјҢеҢ…жӢ¬жҷ®йҖҡзҙўеј•гҖҒе”ҜдёҖзҙўеј•зӯүгҖӮ
еңЁInnoDBдёӯпјҢеҸӘеӯҳеңЁдёҖдёӘиҒҡйӣҶзҙўеј•пјҡ
иӢҘиЎЁеӯҳеңЁдё»й”®пјҢеҲҷдё»й”®зҙўеј•е°ұжҳҜиҒҡйӣҶзҙўеј•пјӣ
иӢҘиЎЁдёҚеӯҳеңЁдё»й”®пјҢеҲҷдјҡжҠҠ第дёҖдёӘйқһз©әзҡ„е”ҜдёҖзҙўеј•дҪңдёәиҒҡйӣҶзҙўеј•пјӣ
еҗҰеҲҷпјҢдјҡйҡҗејҸе®ҡд№үдёҖдёӘrowidдҪңдёәиҒҡйӣҶзҙўеј•гҖӮ
жҲ‘们д»ҘдёӢеӣҫдёәдҫӢпјҢеҒҮи®ҫзҺ°еңЁжңүдёҖдёӘиЎЁпјҢеӯҳеңЁidгҖҒnameгҖҒageдёүдёӘеӯ—ж®өпјҢе…¶дёӯidдёәдё»й”®пјҢеӣ жӯӨidдёәиҒҡйӣҶзҙўеј•пјҢnameе»әз«Ӣзҙўеј•дёәйқһиҒҡйӣҶзҙўеј•гҖӮе…ідәҺidе’Ңnameзҡ„зҙўеј•пјҢжңүеҰӮдёӢзҡ„B+ж ‘пјҢеҸҜд»ҘзңӢеҲ°пјҢиҒҡйӣҶзҙўеј•зҡ„еҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜдё»й”®е’ҢиЎҢи®°еҪ•пјҢйқһиҒҡйӣҶзҙўеј•зҡ„еҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜдё»й”®гҖӮ
еӣһиЎЁжҹҘиҜў
д»ҺдёҠйқўзҡ„зҙўеј•еӯҳеӮЁз»“жһ„жқҘзңӢпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢеңЁдё»й”®зҙўеј•ж ‘дёҠпјҢйҖҡиҝҮдё»й”®е°ұеҸҜд»ҘдёҖж¬ЎжҖ§жҹҘеҮәжҲ‘们жүҖйңҖиҰҒзҡ„ж•°жҚ®пјҢйҖҹеәҰеҫҲеҝ«гҖӮиҝҷеҫҲзӣҙи§ӮпјҢеӣ дёәдё»й”®е°ұе’ҢиЎҢи®°еҪ•еӯҳеӮЁеңЁдёҖиө·пјҢе®ҡдҪҚеҲ°дәҶдё»й”®е°ұе®ҡдҪҚеҲ°дәҶжүҖиҰҒжүҫзҡ„еҢ…еҗ«жүҖжңүеӯ—ж®өзҡ„и®°еҪ•гҖӮ
дҪҶжҳҜеҜ№дәҺйқһиҒҡйӣҶзҙўеј•пјҢеҰӮдёҠйқўзҡ„еҸіеӣҫпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢйңҖиҰҒе…Ҳж №жҚ®nameжүҖеңЁзҡ„зҙўеј•ж ‘жүҫеҲ°еҜ№еә”дё»й”®пјҢ然еҗҺйҖҡиҝҮдё»й”®зҙўеј•ж ‘жҹҘиҜўеҲ°жүҖиҰҒзҡ„и®°еҪ•пјҢиҝҷдёӘиҝҮзЁӢеҸ«еҒҡеӣһиЎЁжҹҘиҜўгҖӮ
зҙўеј•иҰҶзӣ–
дёҠйқўзҡ„еӣһиЎЁжҹҘиҜўж— з–‘дјҡйҷҚдҪҺжҹҘиҜўзҡ„ж•ҲзҺҮпјҢйӮЈд№ҲжңүжІЎжңүеҠһжі•и®©е®ғдёҚеӣһиЎЁе‘ўпјҹиҝҷе°ұжҳҜзҙўеј•иҰҶзӣ–гҖӮжүҖи°“зҙўеј•иҰҶзӣ–пјҢе°ұжҳҜиҜҙпјҢеңЁдҪҝз”ЁиҝҷдёӘзҙўеј•жҹҘиҜўж—¶пјҢдҪҝе®ғзҡ„зҙўеј•ж ‘зҡ„еҸ¶еӯҗиҠӮзӮ№дёҠзҡ„ж•°жҚ®еҸҜд»ҘиҰҶзӣ–дҪ жҹҘиҜўзҡ„жүҖжңүеӯ—ж®өпјҢе°ұеҸҜд»ҘйҒҝе…ҚеӣһиЎЁдәҶгҖӮжҲ‘们еӣһеҲ°дёҖејҖе§Ӣзҡ„дҫӢеӯҗпјҢжҲ‘们е»әз«Ӣзҡ„(b,c,d)зҡ„иҒ”еҗҲзҙўеј•пјҢеӣ жӯӨеҪ“жҲ‘们жҹҘиҜўзҡ„еӯ—ж®өеңЁbгҖҒcгҖҒdдёӯзҡ„ж—¶еҖҷпјҢе°ұдёҚдјҡеӣһиЎЁпјҢеҸӘйңҖиҰҒжҹҘзңӢдёҖж¬Ўзҙўеј•ж ‘пјҢиҝҷе°ұжҳҜзҙўеј•иҰҶзӣ–гҖӮ
жңҖе·ҰеҢ№й…ҚеҺҹеҲҷ
жҢҮзҡ„жҳҜиҒ”еҗҲзҙўеј•дёӯпјҢдјҳе…Ҳиө°жңҖе·Ұиҫ№еҲ—зҡ„зҙўеј•гҖӮеҜ№дәҺеӨҡдёӘеӯ—ж®өзҡ„иҒ”еҗҲзҙўеј•пјҢд№ҹеҗҢзҗҶгҖӮеҰӮ index(a,b,c) иҒ”еҗҲзҙўеј•пјҢеҲҷзӣёеҪ“дәҺеҲӣе»әдәҶ a еҚ•еҲ—зҙўеј•пјҢ(a,b)иҒ”еҗҲзҙўеј•пјҢе’Ң(a,b,c)иҒ”еҗҲзҙўеј•гҖӮ
жҲ‘们еҸҜд»Ҙжү§иЎҢдёӢйқўзҡ„еҮ жқЎиҜӯеҸҘйӘҢиҜҒдёҖдёӢиҝҷдёӘеҺҹеҲҷгҖӮ
EXPLAIN SELECT * FROM test WHERE b = 1;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

жҺҘзқҖпјҢжҲ‘们е°қиҜ•дёҖжқЎдёҚз¬ҰеҗҲжңҖе·ҰеҺҹеҲҷзҡ„жҹҘиҜўпјҢе®ғд№ҹеҰӮеӣҫйў„жңҹдёҖж ·пјҢиө°дәҶе…ЁиЎЁжү«жҸҸгҖӮ
EXPLAIN SELECT * FROM test WHERE d = 3;

иҜҰз»Ҷ规еҲҷ
жҲ‘们е…ҲжқҘзңӢдёӢйқўдёӨдёӘиҜӯеҸҘпјҢ他们зҡ„иҫ“еҮәеҰӮдёӢгҖӮ
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1;
EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra |
--+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+
1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index|
i
d|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra |
--+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+
1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
жҳҫ然第дёҖжқЎиҜӯеҸҘжҳҜз¬ҰеҗҲжңҖе·ҰеҢ№й…Қзҡ„пјҢеӣ жӯӨtypeдёәrefпјҢдҪҶжҳҜ第дәҢжқЎе№¶дёҚз¬ҰеҗҲжңҖе·ҰеҢ№й…ҚпјҢдҪҶжҳҜд№ҹдёҚжҳҜе…ЁиЎЁжү«жҸҸпјҢиҝҷжҳҜеӣ дёәжӯӨж—¶иҝҷиЎЁзӨәжү«жҸҸж•ҙдёӘзҙўеј•ж ‘гҖӮ
е…·дҪ“жқҘзңӢпјҢindex д»ЈиЎЁзҡ„жҳҜдјҡеҜ№ж•ҙдёӘзҙўеј•ж ‘иҝӣиЎҢжү«жҸҸпјҢеҰӮдҫӢеӯҗдёӯзҡ„пјҢеҲ— dпјҢе°ұдјҡеҜјиҮҙжү«жҸҸж•ҙдёӘзҙўеј•ж ‘гҖӮref д»ЈиЎЁ mysql дјҡж №жҚ®зү№е®ҡзҡ„з®—жі•жҹҘжүҫзҙўеј•пјҢиҝҷж ·зҡ„ж•ҲзҺҮжҜ” index е…Ёжү«жҸҸиҰҒй«ҳдёҖдәӣгҖӮдҪҶжҳҜпјҢе®ғеҜ№зҙўеј•з»“жһ„жңүдёҖе®ҡзҡ„иҰҒжұӮпјҢзҙўеј•еӯ—ж®өеҝ…йЎ»жҳҜжңүеәҸзҡ„гҖӮиҖҢиҒ”еҗҲзҙўеј•е°ұз¬ҰеҗҲиҝҷж ·зҡ„иҰҒжұӮпјҢиҒ”еҗҲзҙўеј•еҶ…йғЁе°ұжҳҜжңүеәҸзҡ„пјҢдҪ еҸҜд»ҘзҗҶи§Јдёәorder by b,c,dиҝҷз§ҚжҺ’еәҸ规еҲҷпјҢе…Ҳж №жҚ®еӯ—ж®өbжҺ’еәҸпјҢеҶҚж №жҚ®еӯ—ж®өcжҺ’еәҸпјҢд»ҘжӯӨзұ»жҺЁгҖӮиҝҷд№ҹи§ЈйҮҠдәҶпјҢдёәд»Җд№ҲйңҖиҰҒйҒөе®ҲжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢеҪ“жңҖе·ҰеҲ—жңүеәҸжүҚиғҪдҝқиҜҒеҸіиҫ№зҡ„зҙўеј•еҲ—жңүеәҸгҖӮ
еӣ жӯӨпјҢжҲ‘们жҖ»з»“жңҖеҗҺзҡ„еҺҹеҲҷдёәпјҢиӢҘз¬ҰеҗҲжңҖе·ҰиҰҶзӣ–еҺҹеҲҷпјҢеҲҷиө°refиҝҷз§Қзҙўеј•пјӣиӢҘдёҚз¬ҰеҗҲжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢдҪҶжҳҜз¬ҰеҗҲиҰҶзӣ–зҙўеј•пјҲindexпјүпјҢе°ұеҸҜд»Ҙжү«жҸҸж•ҙдёӘзҙўеј•ж ‘пјҢд»ҺиҖҢжүҫеҲ°иҰҶзӣ–зҙўеј•еҜ№еә”зҡ„еҲ—пјҢйҒҝе…ҚеӣһиЎЁпјӣиӢҘдёҚз¬ҰеҗҲжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢд№ҹдёҚз¬ҰеҗҲиҰҶзӣ–зҙўеј•пјҲеҰӮжң¬дҫӢзҡ„select *пјүпјҢеҲҷйңҖиҰҒжү«жҸҸж•ҙдёӘзҙўеј•ж ‘пјҢ并且еӣһиЎЁжҹҘиҜўиЎҢи®°еҪ•пјҢжӯӨж—¶пјҢжҹҘиҜўдјҳеҢ–еҷЁи®Өдёәиҝҷж ·дёӨж¬ЎжҹҘжүҫзҙўеј•ж ‘пјҢиҝҳдёҚеҰӮе…ЁиЎЁжү«жҸҸжқҘеҫ—еҝ«пјҲеӣ дёәиҒ”еҗҲзҙўеј•жӯӨж—¶дёҚз¬ҰеҗҲжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢиҰҒдёҚжҷ®йҖҡзҙўеј•жҹҘиҜўж…ўеҫ—еӨҡпјүпјҢеӣ жӯӨпјҢжӯӨж—¶дјҡиө°е…ЁиЎЁжү«жҸҸгҖӮ
иЎҘе……пјҡдёәд»Җд№ҲиҰҒдҪҝз”ЁиҒ”еҗҲзҙўеј•
еҮҸе°‘ејҖй”ҖгҖӮе»әдёҖдёӘиҒ”еҗҲзҙўеј•(col1,col2,col3)пјҢе®һйҷ…зӣёеҪ“дәҺе»әдәҶ(col1),(col1,col2),(col1,col2,col3)дёүдёӘзҙўеј•гҖӮжҜҸеӨҡдёҖдёӘзҙўеј•пјҢйғҪдјҡеўһеҠ еҶҷж“ҚдҪңзҡ„ејҖй”Җе’ҢзЈҒзӣҳз©әй—ҙзҡ„ејҖй”ҖгҖӮеҜ№дәҺеӨ§йҮҸж•°жҚ®зҡ„иЎЁпјҢдҪҝз”ЁиҒ”еҗҲзҙўеј•дјҡеӨ§еӨ§зҡ„еҮҸе°‘ејҖй”ҖпјҒ
иҰҶзӣ–зҙўеј•гҖӮеҜ№иҒ”еҗҲзҙўеј•(col1,col2,col3)пјҢеҰӮжһңжңүеҰӮдёӢзҡ„sql: select col1,col2,col3 from test where col1=1 and col2=2гҖӮйӮЈд№ҲMySQLеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮйҒҚеҺҶзҙўеј•еҸ–еҫ—ж•°жҚ®пјҢиҖҢж— йңҖеӣһиЎЁпјҢиҝҷеҮҸе°‘дәҶеҫҲеӨҡзҡ„йҡҸжңәioж“ҚдҪңгҖӮеҮҸе°‘ioж“ҚдҪңпјҢзү№еҲ«зҡ„йҡҸжңәioе…¶е®һжҳҜdbaдё»иҰҒзҡ„дјҳеҢ–зӯ–з•ҘгҖӮжүҖд»ҘпјҢеңЁзңҹжӯЈзҡ„е®һйҷ…еә”з”ЁдёӯпјҢиҰҶзӣ–зҙўеј•жҳҜдё»иҰҒзҡ„жҸҗеҚҮжҖ§иғҪзҡ„дјҳеҢ–жүӢж®өд№ӢдёҖгҖӮ
ж•ҲзҺҮй«ҳгҖӮзҙўеј•еҲ—и¶ҠеӨҡпјҢйҖҡиҝҮзҙўеј•зӯӣйҖүеҮәзҡ„ж•°жҚ®и¶Ҡе°‘гҖӮжңү1000WжқЎж•°жҚ®зҡ„иЎЁпјҢжңүеҰӮдёӢsql:select from table where col1=1 and col2=2 and col3=3,еҒҮи®ҫеҒҮи®ҫжҜҸдёӘжқЎд»¶еҸҜд»ҘзӯӣйҖүеҮә10%зҡ„ж•°жҚ®пјҢеҰӮжһңеҸӘжңүеҚ•еҖјзҙўеј•пјҢйӮЈд№ҲйҖҡиҝҮиҜҘзҙўеј•иғҪзӯӣйҖүеҮә1000W10%=100wжқЎж•°жҚ®пјҢ然еҗҺеҶҚеӣһиЎЁд»Һ100wжқЎж•°жҚ®дёӯжүҫеҲ°з¬ҰеҗҲcol2=2 and col3= 3зҡ„ж•°жҚ®пјҢ然еҗҺеҶҚжҺ’еәҸпјҢеҶҚеҲҶйЎөпјӣеҰӮжһңжҳҜиҒ”еҗҲзҙўеј•пјҢйҖҡиҝҮзҙўеј•зӯӣйҖүеҮә1000w10% 10% *10%=1wпјҢж•ҲзҺҮжҸҗеҚҮеҸҜжғіиҖҢзҹҘпјҒ
вҖңMySQLзҙўеј•жңҖе·ҰеҢ№й…ҚеҺҹеҲҷжҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





