жҖҺд№Ҳз”ЁPythonиҺ·еҸ–Amazonдәҡ马йҖҠзҡ„е•Ҷе“ҒдҝЎжҒҜ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжҖҺд№Ҳз”ЁPythonиҺ·еҸ–Amazonдәҡ马йҖҠзҡ„е•Ҷе“ҒдҝЎжҒҜвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дёҖгҖҒиҺ·еҸ–дәҡ马йҖҠеҲ—иЎЁйЎөзҡ„дҝЎжҒҜ
д»ҘжёёжҲҸеҢәдёәдҫӢпјҡ
иҺ·еҸ–еҲ—иЎЁеҶ…иғҪиҺ·еҸ–еҲ°зҡ„е•Ҷе“ҒдҝЎжҒҜпјҢеҰӮе•Ҷе“ҒеҗҚпјҢиҜҰжғ…й“ҫжҺҘпјҢиҝӣдёҖжӯҘиҺ·еҸ–е…¶д»–еҶ…е®№гҖӮ
з”Ёrequests.get()иҺ·еҸ–зҪ‘йЎөеҶ…е®№пјҢи®ҫзҪ®еҘҪheaderпјҢеҲ©з”ЁxpathйҖүжӢ©еҷЁйҖүеҸ–зӣёе…іж Үзӯҫзҡ„еҶ…е®№пјҡ
import requests
from parsel import Selector
from urllib.parse import urljoin
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
resp = requests.get(spiderurl, headers=headers)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h3/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)#з”Ёurljoinж–№жі•еҮ‘е®Ңж•ҙй“ҫжҺҘ
print(itemUrl,itemName)жӯӨж—¶е·Із»ҸиҺ·еҸ–зҡ„еҪ“еүҚеҲ—иЎЁйЎөзӣ®еүҚиғҪиҺ·еҫ—зҡ„дҝЎжҒҜпјҡ

дәҢгҖҒиҺ·еҸ–иҜҰжғ…йЎөдҝЎжҒҜ
иҝӣе…ҘиҜҰжғ…йЎөпјҡ
иҝӣе…ҘиҜҰжғ…йЎөд№ӢеҗҺпјҢиғҪиҺ·еҫ—жӣҙеӨҡзҡ„еҶ…е®№
з”Ёrequests.get()иҺ·еҸ–зҪ‘йЎөеҶ…е®№пјҢcssйҖүеҸ–зӣёе…іж Үзӯҫзҡ„еҶ…е®№пјҡ
res = requests.get(itemUrl, headers=headers)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)жӯӨж—¶е·Із»Ҹз”ҹжҲҗиҜҰжғ…йЎөж•°жҚ®зҡ„дҝЎжҒҜпјҡ

зӣ®еүҚж¶үеҸҠеҲ°зҡ„е°ұжҳҜжңҖеҹәжң¬зҡ„requestsиҜ·жұӮдәҡ马йҖҠ并用css/xpathиҺ·еҸ–зӣёеә”зҡ„дҝЎжҒҜгҖӮ
дёүгҖҒд»ЈзҗҶи®ҫзҪ®
зӣ®еүҚпјҢеӣҪеҶ…и®ҝй—®дәҡ马йҖҠдјҡеҫҲдёҚзЁіе®ҡпјҢжҲ‘иҝҷиҫ№еӨ§жҰӮзҺҮдјҡеҮәзҺ°иҝһжҺҘдёҚдёҠзҡ„жғ…еҶөгҖӮеҰӮжһңзңҹзҡ„йңҖиҰҒеҺ»зҲ¬еҸ–дәҡ马йҖҠзҡ„дҝЎжҒҜпјҢжңҖеҘҪдҪҝз”ЁдёҖдәӣзЁіе®ҡзҡ„д»ЈзҗҶпјҢжҲ‘иҝҷиҫ№иҮӘе·ұдҪҝз”Ёзҡ„жҳҜipideaзҡ„д»ЈзҗҶпјҢеҸҜд»ҘзҷҪе«–500MжөҒйҮҸгҖӮеҰӮжһңжңүд»ЈзҗҶзҡ„иҜқи®ҝй—®зҡ„жҲҗеҠҹзҺҮдјҡй«ҳпјҢйҖҹеәҰд№ҹдјҡеҝ«дёҖзӮ№гҖӮ
зҪ‘еқҖеңЁиҝҷйҮҢпјҡhttp://www.ipidea.net/?utm-source=PHP&utm-keyword=?PHP
д»ЈзҗҶдҪҝз”ЁжңүдёӨз§Қж–№ејҸпјҢдёҖжҳҜйҖҡиҝҮapiиҺ·еҸ–IPең°еқҖпјҢиҝҳжңүз”ЁиҙҰеҜҶзҡ„ж–№ејҸдҪҝз”ЁпјҢж–№жі•еҰӮдёӢпјҡ
3.1.1 apiиҺ·еҸ–д»ЈзҗҶ
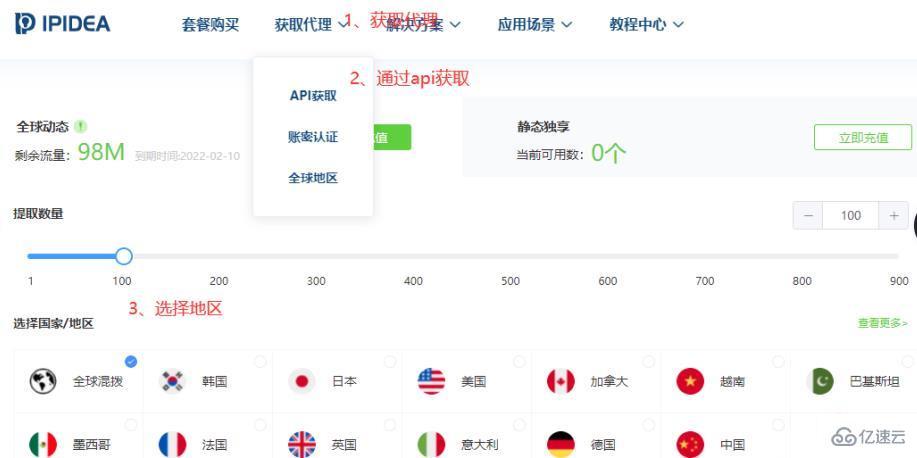
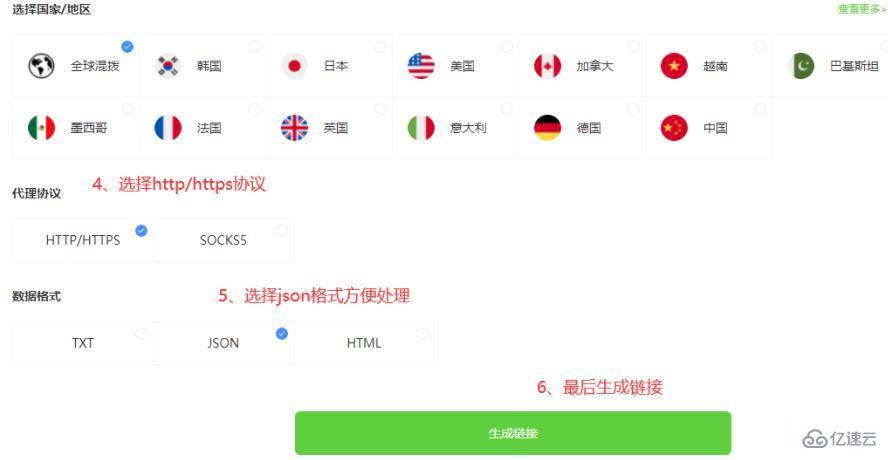
3.1.2 apiиҺ·еҸ–ipд»Јз Ғ
def getProxies():
# иҺ·еҸ–дё”д»…иҺ·еҸ–дёҖдёӘip
api_url = 'з”ҹжҲҗзҡ„apiй“ҫжҺҘ'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('иҺ·еҸ–еӨұиҙҘ')
except:
print('иҺ·еҸ–еӨұиҙҘ')3.2.1 иҙҰеҜҶиҺ·еҸ–д»ЈзҗҶ пјҲжіЁеҶҢең°еқҖпјҡhttp://www.ipidea.net/?utm-source=PHP&utm-keyword=?PHP пјү
еӣ дёәжҳҜиҙҰеҜҶйӘҢиҜҒпјҢжүҖд»ҘйңҖиҰҒеҺ»еҲ°иҙҰжҲ·дёӯеҝғеЎ«еҶҷдҝЎжҒҜеҲӣе»әеӯҗиҙҰжҲ·пјҡ 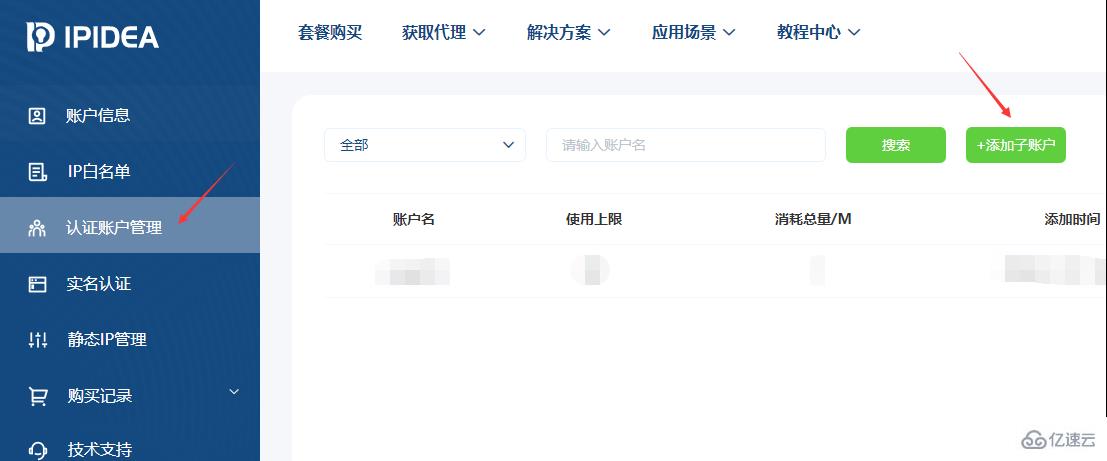
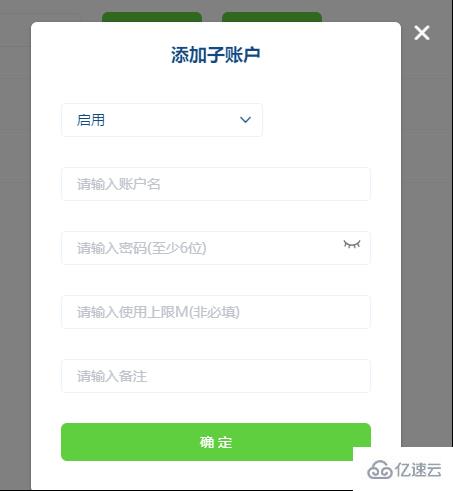
еҲӣе»әеҘҪеӯҗиҙҰжҲ·д№ӢеҗҺпјҢж №жҚ®иҙҰеҸ·е’ҢеҜҶз ҒиҺ·еҸ–й“ҫжҺҘпјҡ
3.2.2 иҙҰеҜҶиҺ·еҸ–д»ЈзҗҶд»Јз Ғ
# иҺ·еҸ–иҙҰеҜҶip
def getAccountIp():
# жөӢиҜ•е®ҢжҲҗеҗҺиҝ”еӣһд»ЈзҗҶproxy
mainUrl = 'https://api.myip.la/en?json'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
entry = 'http://{}-zone-custom{}:proxy.ipidea.io:2334'.format("еёҗеҸ·", "еҜҶз Ғ")
proxy = {
'http': entry,
'https': entry,
}
try:
res = requests.get(mainUrl, headers=headers, proxies=proxy, timeout=10)
if res.status_code == 200:
return proxy
except Exception as e:
print("и®ҝй—®еӨұиҙҘ", e)
passдҪҝз”Ёд»ЈзҗҶд№ӢеҗҺпјҢдәҡ马йҖҠе•Ҷе“ҒдҝЎжҒҜзҡ„иҺ·еҸ–ж”№е–„дәҶдёҚе°‘пјҢд№ӢеүҚд»Јз ҒдјҡжҠҘеҗ„з§ҚиҝһжҺҘеӨұиҙҘзҡ„й”ҷиҜҜпјҢеңЁrequestsиҜ·жұӮд№ӢеүҚи°ғз”Ёд»ЈзҗҶиҺ·еҸ–зҡ„ж–№жі•пјҢж–№жі•returnеӣһд»ЈзҗҶip并еҠ е…ҘrequestsиҜ·жұӮеҸӮж•°пјҢе°ұеҸҜд»Ҙе®һзҺ°д»ЈзҗҶиҜ·жұӮдәҶгҖӮ
еӣӣгҖҒе…ЁйғЁд»Јз Ғ
# coding=utf-8
import requests
from parsel import Selector
from urllib.parse import urljoin
def getProxies():
# иҺ·еҸ–дё”д»…иҺ·еҸ–дёҖдёӘip
api_url = 'з”ҹжҲҗзҡ„apiй“ҫжҺҘ'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('иҺ·еҸ–еӨұиҙҘ')
except:
print('иҺ·еҸ–еӨұиҙҘ')
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
proxies = getProxies()
resp = requests.get(spiderurl, headers=headers, proxies=proxies)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h3/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)
proxies = getProxies()
res = requests.get(itemUrl, headers=headers, proxies=proxies)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)вҖңжҖҺд№Ҳз”ЁPythonиҺ·еҸ–Amazonдәҡ马йҖҠзҡ„е•Ҷе“ҒдҝЎжҒҜвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





