Redisй«ҳеҸҜз”Ёжһ¶жһ„еҰӮдҪ•жҗӯе»ә
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢRedisй«ҳеҸҜз”Ёжһ¶жһ„еҰӮдҪ•жҗӯе»әзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
жҢҒд№…еҢ–жңәеҲ¶
еңЁзҗҶи§ЈйӣҶзҫӨжһ¶жһ„еүҚпјҢе…ҲиҰҒд»Ӣз»ҚдёҖдёӢredisзҡ„жҢҒд№…еҢ–жңәеҲ¶пјҢеӣ дёәеңЁеҗҺйқўзҡ„йӣҶзҫӨдёӯдјҡж¶үеҸҠеҲ°жҢҒд№…еҢ–гҖӮredisжҢҒд№…еҢ–жҳҜе°Ҷзј“еӯҳеңЁеҶ…еӯҳдёӯзҡ„ж•°жҚ®ж №жҚ®дёҖдәӣ规еҲҷиҝӣиЎҢиҗҪзӣҳпјҢд»ҘйҳІжӯўеңЁredisжңҚеҠЎе®•жңәж—¶еҸҜд»ҘиҝӣиЎҢж•°жҚ®жҒўеӨҚжҲ–иҖ…жҳҜйӣҶзҫӨжһ¶жһ„дёӯиҝӣиЎҢдё»д»ҺиҠӮзӮ№ж•°жҚ®еҗҢжӯҘгҖӮredisжҢҒд№…еҢ–зҡ„ж–№ејҸжңүRDBе’ҢAOFдёӨз§ҚпјҢеңЁ4.0зүҲжң¬еҗҺж–°еҮәдәҶж··еҗҲжҢҒд№…еҢ–жЁЎејҸгҖӮ
RDB
RDBжҳҜredisй»ҳи®ӨејҖеҗҜзҡ„жҢҒд№…еҢ–жңәеҲ¶пјҢе…¶жҢҒд№…еҢ–ж–№ејҸжҳҜжҢүз…§з”ЁжҲ·й…ҚзҪ®зҡ„规еҲҷ"Xз§’еҶ…иҮіе°‘еҸ‘з”ҹиҝҮYж¬Ўж”№еҠЁ",з”ҹжҲҗеҝ«з…§е№¶иҗҪзӣҳеҲ°dump.rdbдәҢиҝӣеҲ¶ж–Ү件дёӯгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢredisй…ҚзҪ®дәҶдёүз§ҚпјҢеҲҶеҲ«дёә900з§’еҶ…иҮіе°‘еҸ‘з”ҹиҝҮ1ж¬Ўзј“еӯҳkeyзҡ„ж”№еҠЁпјҢ300з§’еҶ…иҮіе°‘еҸ‘з”ҹиҝҮ10ж¬Ўзј“еӯҳkeyзҡ„ж”№еҠЁд»ҘеҸҠ60з§’еҶ…иҮіе°‘еҸ‘з”ҹиҝҮ10000ж¬Ўж”№еҠЁгҖӮ

йҷӨдәҶredisиҮӘеҠЁеҝ«з…§жҢҒд№…еҢ–ж•°жҚ®еӨ–пјҢиҝҳжңүдёӨдёӘе‘Ҫд»ӨеҸҜд»Ҙеё®еҠ©жҲ‘们жүӢеҠЁиҝӣиЎҢеҶ…еӯҳж•°жҚ®еҝ«з…§пјҢиҝҷдёӨдёӘе‘Ҫд»ӨеҲҶеҲ«дёәsaveе’ҢbgsaveгҖӮ

saveпјҡд»ҘеҗҢжӯҘзҡ„ж–№ејҸиҝӣиЎҢж•°жҚ®еҝ«з…§пјҢеҪ“зј“еӯҳж•°жҚ®йҮҸеӨ§пјҢдјҡйҳ»еЎһе…¶д»–е‘Ҫд»Өзҡ„жү§иЎҢпјҢж•ҲзҺҮдёҚй«ҳгҖӮ
bgsaveпјҡд»ҘејӮжӯҘзҡ„ж–№ејҸиҝӣиЎҢж•°жҚ®еҝ«з…§пјҢжңүredisдё»зәҝзЁӢforkеҮәдёҖдёӘеӯҗиҝӣзЁӢжқҘиҝӣиЎҢж•°жҚ®еҝ«з…§пјҢдёҚдјҡйҳ»еЎһе…¶д»–е‘Ҫд»Өзҡ„жү§иЎҢпјҢж•ҲзҺҮиҫғй«ҳгҖӮз”ұдәҺжҳҜйҮҮз”ЁејӮжӯҘеҝ«з…§зҡ„ж–№ејҸпјҢйӮЈд№Ҳе°ұжңүеҸҜиғҪеҸ‘з”ҹеңЁеҝ«з…§зҡ„иҝҮзЁӢдёӯпјҢжңүе…¶д»–е‘Ҫд»ӨеҜ№ж•°жҚ®иҝӣиЎҢдәҶдҝ®ж”№гҖӮдёәдәҶйҒҝе…ҚиҝҷдёӘй—®йўҳreidsйҮҮз”ЁдәҶеҶҷж—¶еӨҚеҲ¶(Cpoy-On-Write)зҡ„ж–№ејҸ,еӣ дёәжӯӨж—¶иҝӣиЎҢеҝ«з…§зҡ„иҝӣзЁӢжҳҜз”ұдё»зәҝзЁӢforkеҮәжқҘзҡ„пјҢжүҖд»Ҙдә«жңүдё»зәҝзЁӢзҡ„иө„жәҗпјҢеҪ“еҝ«з…§иҝҮзЁӢдёӯеҸ‘з”ҹж•°жҚ®ж”№еҠЁж—¶пјҢйӮЈд№ҲиҜҘж•°жҚ®дјҡиў«еӨҚеҲ¶дёҖд»Ҫ并з”ҹжҲҗеүҜжң¬ж•°жҚ®пјҢеӯҗиҝӣзЁӢдјҡе°Ҷж”№еүҜжң¬ж•°жҚ®еҶҷе…ҘеҲ°dump.rdbж–Ү件дёӯгҖӮ
RDBеҝ«з…§жҳҜд»ҘдәҢиҝӣеҲ¶зҡ„ж–№ејҸиҝӣиЎҢеӯҳеӮЁзҡ„пјҢжүҖд»ҘеңЁж•°жҚ®жҒўеӨҚж—¶пјҢйҖҹеәҰдјҡжҜ”иҫғеҝ«пјҢдҪҶжҳҜе®ғеӯҳеңЁж•°жҚ®дёўеӨұзҡ„йЈҺйҷ©гҖӮеҒҮеҰӮи®ҫзҪ®зҡ„еҝ«з…§и§„еҲҷдёә60з§’еҶ…иҮіе°‘еҸ‘з”ҹ100ж¬Ўж•°жҚ®ж”№еҠЁпјҢйӮЈд№ҲеңЁ50з§’ж—¶пјҢredisжңҚеҠЎз”ұдәҺжҹҗз§ҚеҺҹеӣ зӘҒ然宕жңәдәҶпјҢйӮЈеңЁиҝҷ50з§’еҶ…зҡ„жүҖжңүж•°жҚ®е°ҶдјҡдёўеӨұгҖӮ
AOF
AOFжҳҜRedisзҡ„еҸҰдёҖз§ҚжҢҒд№…еҢ–ж–№ејҸпјҢдёҺRDBдёҚеҗҢж—¶жҳҜпјҢAOFи®°еҪ•зқҖжҜҸдёҖжқЎжӣҙж”№ж•°жҚ®зҡ„е‘Ҫд»Ө并дҝқеӯҳеҲ°зЈҒзӣҳдёӢзҡ„appendonly.aofж–Ү件дёӯпјҢеҪ“redisжңҚеҠЎйҮҚеҗҜж—¶пјҢдјҡеҠ иҪҪиҜҘж–Үе°Ҷ并еҶҚж¬Ўжү§иЎҢж–Ү件дёӯдҝқеӯҳзҡ„е‘Ҫд»ӨпјҢд»ҺиҖҢиҫҫеҲ°ж•°жҚ®жҒўеӨҚзҡ„ж•ҲжһңгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢAOFжҳҜе…ій—ӯзҡ„пјҢеҸҜд»ҘйҖҡиҝҮдҝ®ж”№confй…ҚзҪ®ж–Ү件жқҘиҝӣиЎҢејҖеҗҜгҖӮ
# appendonly no е…ій—ӯAOFжҢҒд№…еҢ–
appendonly yes # ејҖеҗҜAOFжҢҒд№…еҢ–
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof" # жҢҒд№…еҢ–ж–Ү件еҗҚ
AOFжҸҗдҫӣдәҶдёүз§Қж–№ејҸпјҢеҸҜд»Ҙи®©е‘Ҫд»ӨдҝқеӯҳеҲ°зЈҒзӣҳгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢAOFйҮҮз”Ёappendfsync everysecзҡ„ж–№ејҸиҝӣиЎҢе‘Ҫд»ӨжҢҒд№…еҢ–гҖӮ
appendfsync always #жҜҸж¬Ўжңүж–°зҡ„ж”№еҶҷе‘Ҫд»Өж—¶пјҢйғҪдјҡиҝҪеҠ еҲ°зЈҒзӣҳзҡ„aofж–Ү件дёӯгҖӮж•°жҚ®е®үе…ЁжҖ§жңҖй«ҳпјҢдҪҶж•ҲзҺҮжңҖж…ўгҖӮ
appendfsync everysec # жҜҸдёҖз§’пјҢйғҪдјҡе°Ҷж”№еҶҷе‘Ҫд»ӨиҝҪеҠ еҲ°зЈҒзӣҳдёӯзҡ„aofж–Ү件дёӯгҖӮеҰӮжһңеҸ‘з”ҹе®•жңәпјҢд№ҹеҸӘдјҡдёўеӨұ1з§’зҡ„ж•°жҚ®гҖӮ
appendfsync no #дёҚдјҡдё»еҠЁиҝӣиЎҢе‘Ҫд»ӨиҗҪзӣҳпјҢиҖҢжҳҜз”ұж“ҚдҪңзі»з»ҹеҶіе®ҡд»Җд№Ҳж—¶еҖҷеҶҷе…ҘеҲ°зЈҒзӣҳгҖӮж•°жҚ®е®үе…ЁжҖ§дёҚй«ҳгҖӮ
ејҖеҗҜAOFеҗҺйңҖиҰҒйҮҚж–°еҗҜеҠЁredisжңҚеҠЎпјҢеҪ“еҶҚж¬Ўжү§иЎҢзӣёе…іж”№еҶҷе‘Ҫд»Өж—¶пјҢaofж–Ү件дёӯдјҡи®°еҪ•ж“ҚдҪңзҡ„е‘Ҫд»ӨгҖӮ


зӣёеҜ№дәҺRDBпјҢиҷҪ然AOFзҡ„ж•°жҚ®е®үе…ЁжҖ§жӣҙй«ҳпјҢдҪҶжҳҜйҡҸзқҖжңҚеҠЎзҡ„жҢҒз»ӯиҝҗиЎҢпјҢaofзҡ„ж–Ү件д№ҹдјҡи¶ҠжқҘи¶ҠеӨ§пјҢзӯүеҲ°дёӢж¬ЎжҒўеӨҚж•°жҚ®ж—¶пјҢйҖҹеәҰдјҡи¶ҠжқҘи¶Ҡж…ўгҖӮеҰӮжһңRDBе’ҢAOFйғҪејҖеҗҜпјҢеңЁжҒўеӨҚж•°жҚ®ж—¶пјҢredisдјҡдјҳе…ҲйҖүжӢ©AOF,жҜ•з«ҹAOFдёўеӨұзҡ„ж•°жҚ®жӣҙе°‘е•ҠгҖӮ
| RDB | AOF |
|---|
| жҒўеӨҚж•ҲзҺҮ | й«ҳ | дҪҺ |
| ж•°жҚ®е®үе…ЁжҖ§ | дҪҺ | й«ҳ |
| з©әй—ҙеҚ з”Ё | дҪҺ | й«ҳ |
ж··еҗҲжЁЎејҸ
з”ұдәҺRDBжҢҒд№…еҢ–ж–№ејҸе®№жҳ“йҖ жҲҗж•°жҚ®дёўеӨұпјҢAOFжҢҒд№…еҢ–ж–№ејҸж•°жҚ®жҒўеӨҚиҫғж…ўпјҢжүҖд»ҘеңЁredis4.0зүҲжң¬еҗҺпјҢж–°еҮәжқҘж··еҗҲжҢҒд№…еҢ–жЁЎејҸгҖӮж··еҗҲжҢҒд№…еҢ–е°ҶRDBе’ҢAOFзҡ„дјҳзӮ№иҝӣиЎҢдәҶйӣҶжҲҗпјҢ并иҖҢдё”дҫқиө–дәҺAOF,жүҖд»ҘеңЁдҪҝз”Ёж··еҗҲжҢҒд№…еҢ–еүҚпјҢйңҖиҰҒејҖеҗҜAOFгҖӮеңЁејҖеҗҜж··еҗҲжҢҒд№…еҢ–еҗҺпјҢеҪ“еҸ‘з”ҹAOFйҮҚеҶҷж—¶пјҢдјҡе°ҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®д»ҘRDBзҡ„ж•°жҚ®ж јејҸдҝқеӯҳеҲ°aofж–Ү件дёӯпјҢеңЁдёӢдёҖж¬Ўзҡ„йҮҚеҶҷд№ӢеүҚпјҢж··еҗҲжҢҒд№…еҢ–дјҡиҝҪеҠ дҝқеӯҳжҜҸжқЎж”№еҶҷе‘Ҫд»ӨеҲ°aofж–Ү件дёӯгҖӮеҪ“йңҖиҰҒжҒўеӨҚж•°жҚ®ж—¶пјҢдјҡеҠ иҪҪдҝқеӯҳзҡ„rdbеҶ…е®№ж•°жҚ®пјҢ然еҗҺеҶҚ继з»ӯеҗҢжӯҘaofжҢҮд»ӨгҖӮ
# AOFйҮҚеҶҷй…ҚзҪ®пјҢеҪ“aofж–Ү件иҫҫеҲ°60MB并且жҜ”дёҠж¬ЎйҮҚеҶҷеҗҺзҡ„дҪ“йҮҸеӨҡ100%ж—¶иҮӘеҠЁи§ҰеҸ‘AOFйҮҚеҶҷ auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-use-rdb-preamble yes # ејҖеҗҜж··еҗҲжҢҒд№…еҢ–# aof-use-rdb-preamble no # е…ій—ӯж··еҗҲжҢҒд№…еҢ–
AOFйҮҚеҶҷжҳҜжҢҮеҪ“aofж–Ү件и¶ҠжқҘи¶ҠеӨ§ж—¶пјҢredisдјҡиҮӘеҠЁдјҳеҢ–aofж–Ү件дёӯж— з”Ёзҡ„е‘Ҫд»ӨпјҢд»ҺиҖҢеҮҸе°‘ж–Ү件дҪ“з§ҜгҖӮжҜ”еҰӮеңЁеӨ„зҗҶж–Үз« йҳ…иҜ»йҮҸж—¶пјҢжҜҸжҹҘзңӢдёҖж¬Ўж–Үз« е°ұдјҡжү§иЎҢдёҖж¬ЎIncrе‘Ҫд»ӨпјҢдҪҶжҳҜйҡҸзқҖйҳ…иҜ»йҮҸзҡ„дёҚж–ӯеўһеҠ ,aofж–Ү件дёӯзҡ„incrе‘Ҫд»Өд№ҹдјҡз§ҜзҙҜзҡ„и¶ҠжқҘи¶ҠеӨҡгҖӮеңЁAOFйҮҚеҶҷеҗҺпјҢе°ҶдјҡеҲ йҷӨиҝҷдәӣжІЎз”Ёзҡ„Incrе‘Ҫд»ӨпјҢе°Ҷиҝҷдәӣе‘Ҫд»ӨзӣҙжҺҘжӣҝжҚўдёәset key valueе‘Ҫд»ӨгҖӮйҷӨдәҶredisиҮӘеҠЁйҮҚеҶҷAOFпјҢеҰӮжһңйңҖиҰҒпјҢд№ҹеҸҜд»ҘйҖҡиҝҮbgrewriteaofе‘Ҫд»ӨжүӢеҠЁи§ҰеҸ‘гҖӮ
дё»д»ҺеӨҚеҲ¶
еңЁз”ҹдә§зҺҜеўғдёӯпјҢдёҖиҲ¬дёҚдјҡзӣҙжҺҘй…ҚзҪ®еҚ•иҠӮзӮ№зҡ„redisжңҚеҠЎпјҢиҝҷж ·еҺӢеҠӣеӨӘеӨ§гҖӮдёәдәҶзј“и§ЈredisжңҚеҠЎеҺӢеҠӣпјҢеҸҜд»Ҙжҗӯе»әдё»д»ҺеӨҚеҲ¶пјҢеҒҡиҜ»еҶҷеҲҶзҰ»гҖӮredisдё»д»ҺеӨҚеҲ¶пјҢжҳҜжңүдёҖдёӘдё»иҠӮзӮ№Masterе’ҢеӨҡдёӘд»ҺиҠӮзӮ№Slaveз»„жҲҗгҖӮдё»д»ҺиҠӮзӮ№й—ҙзҡ„ж•°жҚ®еҗҢжӯҘеҸӘиғҪжҳҜеҚ•еҗ‘дј иҫ“зҡ„пјҢеҸӘиғҪз”ұMasterиҠӮзӮ№дј иҫ“еҲ°SlaveиҠӮзӮ№гҖӮ
зҺҜеўғй…ҚзҪ®
еҮҶеӨҮдёүеҸ°linuxжңҚеҠЎеҷЁпјҢе…¶дёӯдёҖеҸ°дҪңдёәredisзҡ„дё»иҠӮзӮ№пјҢдёӨеҸ°дҪңдёәreidsзҡ„д»ҺиҠӮзӮ№гҖӮеҰӮжһңжІЎжңүи¶іеӨҹзҡ„жңәеҷЁеҸҜд»ҘеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠйқўе°Ҷredisж–Ү件еӨҡеӨҚеҲ¶дёӨд»Ҫ并жӣҙж”№з«ҜеҸЈеҸ·пјҢиҝҷж ·еҸҜд»Ҙжҗӯе»әдёҖдёӘдјӘйӣҶзҫӨгҖӮ
| IP | дё»/д»ҺиҠӮзӮ№ | з«ҜеҸЈ | зүҲжң¬ |
|---|
| 192.168.36.128 | дё» | 6379 | 5.0.14 |
| 192.168.36.130 | д»Һ | 6379 | 5.0.14 |
| 192.168.36.131 | д»Һ | 6379 | 5.0.14 |
й…ҚзҪ®д»ҺиҠӮзӮ№36.130пјҢ36.131жңәеҷЁдёӯreids.conf
дҝ®ж”№redis.confж–Ү件дёӯзҡ„replicaofпјҢй…ҚзҪ®дё»иҠӮзӮ№зҡ„ipе’Ңз«ҜеҸЈеҸ·пјҢ并且ејҖеҗҜд»ҺиҠӮзӮ№еҸӘиҜ»гҖӮ


еҗҜеҠЁдё»иҠӮзӮ№36.128жңәеҷЁдёӯreidsжңҚеҠЎ
./src/redis-server redis.conf
 3. дҫқж¬ЎеҗҜеҠЁд»ҺиҠӮзӮ№36.130пјҢ36.131жңәеҷЁдёӯзҡ„redisжңҚеҠЎ
3. дҫқж¬ЎеҗҜеҠЁд»ҺиҠӮзӮ№36.130пјҢ36.131жңәеҷЁдёӯзҡ„redisжңҚеҠЎ
./src/redis-server redis.conf
еҗҜеҠЁжҲҗеҠҹеҗҺеҸҜд»ҘзңӢеҲ°ж—Ҙеҝ—дёӯжҳҫзӨәе·Із»ҸдёҺMasterиҠӮзӮ№е»әз«Ӣзҡ„иҝһжҺҘгҖӮ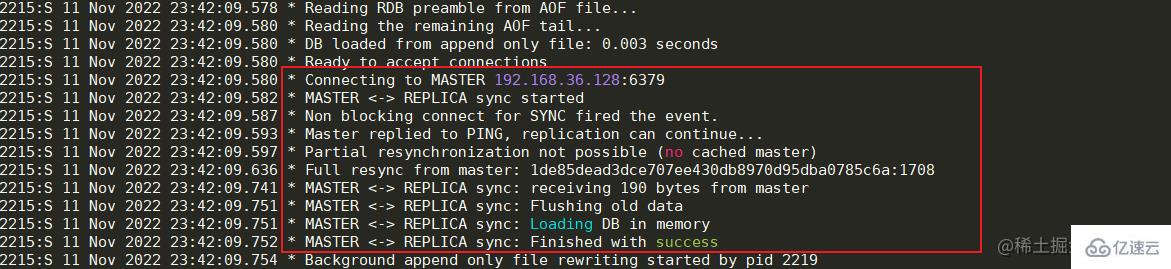 еҰӮжһңеҮәзҺ°дёҺMasterиҠӮзӮ№зҡ„иҝһжҺҘиў«жӢ’пјҢйӮЈд№Ҳе…ҲжЈҖжҹҘMasterиҠӮзӮ№зҡ„жңҚеҠЎеҷЁжҳҜеҗҰејҖеҗҜйҳІзҒ«еўҷ,еҰӮжһңејҖеҗҜпјҢеҸҜд»ҘејҖж”ҫ6379з«ҜеҸЈжҲ–иҖ…е…ій—ӯйҳІзҒ«еўҷгҖӮеҰӮжһңйҳІзҒ«еўҷиў«е…ій—ӯдҪҶиҝһжҺҘд»Қ然被жӢ’пјҢйӮЈд№ҲеҸҜд»Ҙдҝ®ж”№MasterиҠӮзӮ№жңҚеҠЎдёӯзҡ„redis.confж–Ү件гҖӮе°Ҷbing 127.0.0.1дҝ®ж”№дёәжң¬жңәеҜ№еӨ–зҡ„зҪ‘еҚЎipжҲ–иҖ…зӣҙжҺҘжіЁйҮҠжҺүеҚіеҸҜпјҢ然еҗҺйҮҚеҗҜжңҚеҠЎеҷЁеҚіеҸҜгҖӮ
еҰӮжһңеҮәзҺ°дёҺMasterиҠӮзӮ№зҡ„иҝһжҺҘиў«жӢ’пјҢйӮЈд№Ҳе…ҲжЈҖжҹҘMasterиҠӮзӮ№зҡ„жңҚеҠЎеҷЁжҳҜеҗҰејҖеҗҜйҳІзҒ«еўҷ,еҰӮжһңејҖеҗҜпјҢеҸҜд»ҘејҖж”ҫ6379з«ҜеҸЈжҲ–иҖ…е…ій—ӯйҳІзҒ«еўҷгҖӮеҰӮжһңйҳІзҒ«еўҷиў«е…ій—ӯдҪҶиҝһжҺҘд»Қ然被жӢ’пјҢйӮЈд№ҲеҸҜд»Ҙдҝ®ж”№MasterиҠӮзӮ№жңҚеҠЎдёӯзҡ„redis.confж–Ү件гҖӮе°Ҷbing 127.0.0.1дҝ®ж”№дёәжң¬жңәеҜ№еӨ–зҡ„зҪ‘еҚЎipжҲ–иҖ…зӣҙжҺҘжіЁйҮҠжҺүеҚіеҸҜпјҢ然еҗҺйҮҚеҗҜжңҚеҠЎеҷЁеҚіеҸҜгҖӮ

жҹҘзңӢзҠ¶жҖҒ
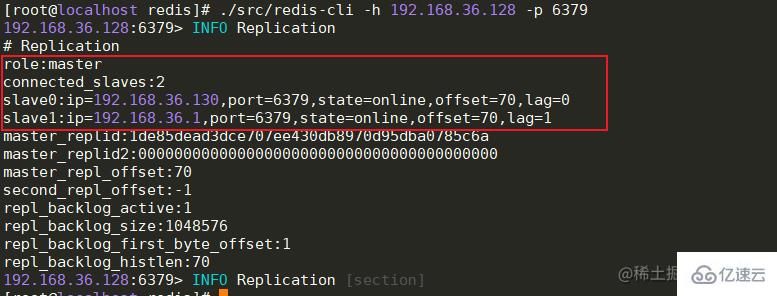
е…ЁйғЁиҠӮзӮ№еҗҜеҠЁжҲҗеҠҹеҗҺпјҢMasterиҠӮзӮ№еҸҜд»ҘжҹҘзңӢд»ҺиҠӮзӮ№зҡ„иҝһжҺҘзҠ¶жҖҒпјҢoffsetеҒҸ移йҮҸзӯүдҝЎжҒҜгҖӮ
info replication # дё»иҠӮзӮ№жҹҘзңӢиҝһжҺҘдҝЎжҒҜ
ж•°жҚ®еҗҢжӯҘжөҒзЁӢ
е…ЁйҮҸж•°жҚ®еҗҢжӯҘ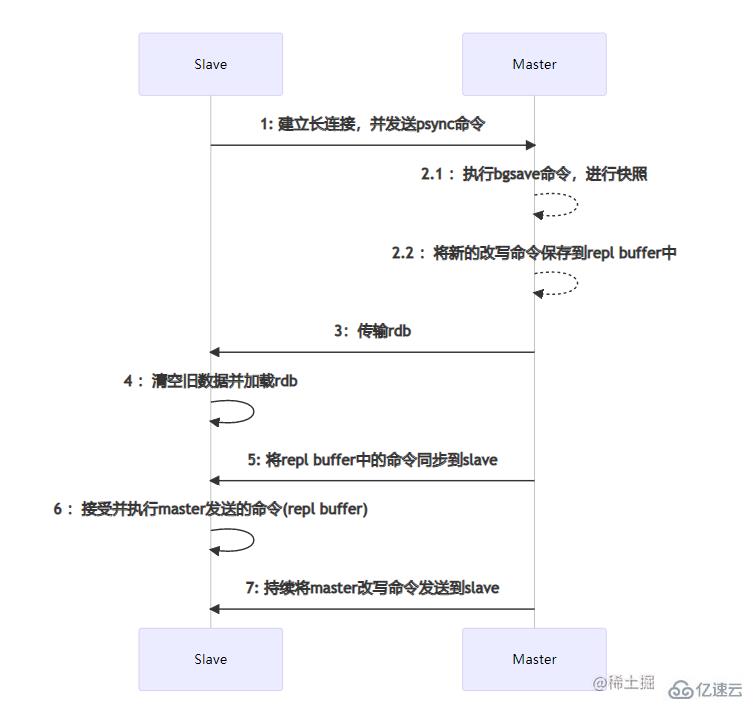 дё»д»ҺиҠӮзӮ№д№Ӣй—ҙзҡ„ж•°жҚ®еҗҢжӯҘжҳҜйҖҡиҝҮе»әз«Ӣsocketй•ҝиҝһжҺҘжқҘиҝӣиЎҢдј иҫ“зҡ„гҖӮеҪ“SlaveиҠӮзӮ№еҗҜеҠЁж—¶пјҢдјҡдёҺMasterиҠӮзӮ№е»әз«Ӣй•ҝиҝһжҺҘпјҢ并且еҸ‘йҖҒpsyncеҗҢжӯҘж•°жҚ®е‘Ҫд»ӨгҖӮеҪ“MasterиҠӮзӮ№ж”¶еҲ°psyncе‘Ҫд»Өж—¶пјҢдјҡжү§иЎҢpgsaveиҝӣиЎҢrdbеҶ…еӯҳж•°жҚ®еҝ«з…§(иҝҷйҮҢзҡ„rdbеҝ«з…§дёҺconfж–Ү件дёӯжҳҜеҗҰејҖеҗҜrdbж— е…і),еҰӮжһңеңЁеҝ«з…§иҝҮзЁӢдёӯжңүж–°зҡ„ж”№еҶҷе‘Ҫд»ӨпјҢйӮЈд№ҲMasterиҠӮзӮ№дјҡе°Ҷиҝҷдәӣе‘Ҫд»ӨдҝқеӯҳеҲ°repl bufferзј“еҶІеҢәдёӯгҖӮеҪ“еҝ«з…§з»“жқҹеҗҺпјҢдјҡе°Ҷrdbдј иҫ“з»ҷSlaveиҠӮзӮ№гҖӮSlaveиҠӮзӮ№еңЁжҺҘ收еҲ°rdbеҗҺпјҢеҰӮжһңеӯҳеңЁж—§ж•°жҚ®пјҢйӮЈд№Ҳдјҡе°Ҷиҝҷдәӣж—§ж•°жҚ®жё…йҷӨ并еҠ иҪҪrdbгҖӮеҠ иҪҪе®ҢжҲҗеҗҺдјҡжҺҘеҸ—masterзј“еӯҳеңЁrepl bufferдёӯзҡ„ж–°е‘Ҫд»ӨгҖӮеңЁиҝҷдәӣжӯҘйӘӨе…ЁйғЁжү§иЎҢе®ҢжҲҗеҗҺпјҢдё»д»ҺиҠӮзӮ№е·Із»Ҹз®—иҝһжҺҘжҲҗеҠҹдәҶпјҢеҗҺз»ӯMasterиҠӮзӮ№зҡ„е‘Ҫд»ӨдјҡдёҚж–ӯзҡ„еҸ‘йҖҒеҲ°SlaveиҠӮзӮ№гҖӮеҰӮжһңеңЁй«ҳ并еҸ‘зҡ„жғ…еҶөдёӢпјҢеҸҜиғҪдјҡеӯҳеңЁж•°жҚ®е»¶иҝҹзҡ„жғ…еҶөгҖӮ
дё»д»ҺиҠӮзӮ№д№Ӣй—ҙзҡ„ж•°жҚ®еҗҢжӯҘжҳҜйҖҡиҝҮе»әз«Ӣsocketй•ҝиҝһжҺҘжқҘиҝӣиЎҢдј иҫ“зҡ„гҖӮеҪ“SlaveиҠӮзӮ№еҗҜеҠЁж—¶пјҢдјҡдёҺMasterиҠӮзӮ№е»әз«Ӣй•ҝиҝһжҺҘпјҢ并且еҸ‘йҖҒpsyncеҗҢжӯҘж•°жҚ®е‘Ҫд»ӨгҖӮеҪ“MasterиҠӮзӮ№ж”¶еҲ°psyncе‘Ҫд»Өж—¶пјҢдјҡжү§иЎҢpgsaveиҝӣиЎҢrdbеҶ…еӯҳж•°жҚ®еҝ«з…§(иҝҷйҮҢзҡ„rdbеҝ«з…§дёҺconfж–Ү件дёӯжҳҜеҗҰејҖеҗҜrdbж— е…і),еҰӮжһңеңЁеҝ«з…§иҝҮзЁӢдёӯжңүж–°зҡ„ж”№еҶҷе‘Ҫд»ӨпјҢйӮЈд№ҲMasterиҠӮзӮ№дјҡе°Ҷиҝҷдәӣе‘Ҫд»ӨдҝқеӯҳеҲ°repl bufferзј“еҶІеҢәдёӯгҖӮеҪ“еҝ«з…§з»“жқҹеҗҺпјҢдјҡе°Ҷrdbдј иҫ“з»ҷSlaveиҠӮзӮ№гҖӮSlaveиҠӮзӮ№еңЁжҺҘ收еҲ°rdbеҗҺпјҢеҰӮжһңеӯҳеңЁж—§ж•°жҚ®пјҢйӮЈд№Ҳдјҡе°Ҷиҝҷдәӣж—§ж•°жҚ®жё…йҷӨ并еҠ иҪҪrdbгҖӮеҠ иҪҪе®ҢжҲҗеҗҺдјҡжҺҘеҸ—masterзј“еӯҳеңЁrepl bufferдёӯзҡ„ж–°е‘Ҫд»ӨгҖӮеңЁиҝҷдәӣжӯҘйӘӨе…ЁйғЁжү§иЎҢе®ҢжҲҗеҗҺпјҢдё»д»ҺиҠӮзӮ№е·Із»Ҹз®—иҝһжҺҘжҲҗеҠҹдәҶпјҢеҗҺз»ӯMasterиҠӮзӮ№зҡ„е‘Ҫд»ӨдјҡдёҚж–ӯзҡ„еҸ‘йҖҒеҲ°SlaveиҠӮзӮ№гҖӮеҰӮжһңеңЁй«ҳ并еҸ‘зҡ„жғ…еҶөдёӢпјҢеҸҜиғҪдјҡеӯҳеңЁж•°жҚ®е»¶иҝҹзҡ„жғ…еҶөгҖӮ
йғЁеҲҶж•°жҚ®еҗҢжӯҘ
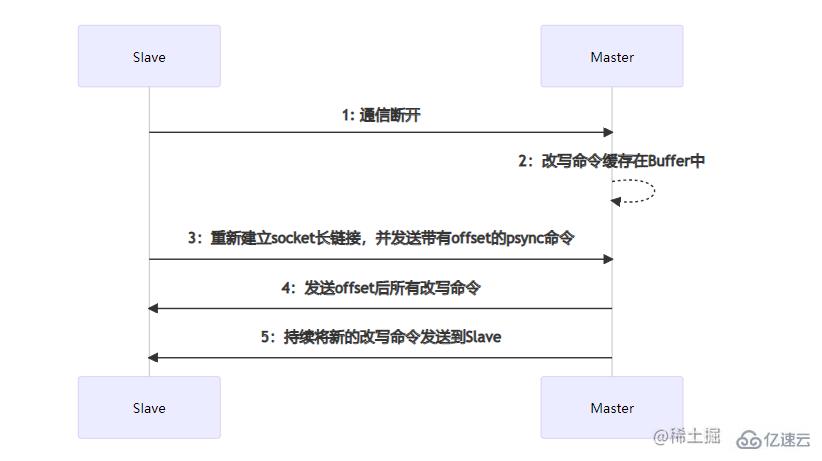
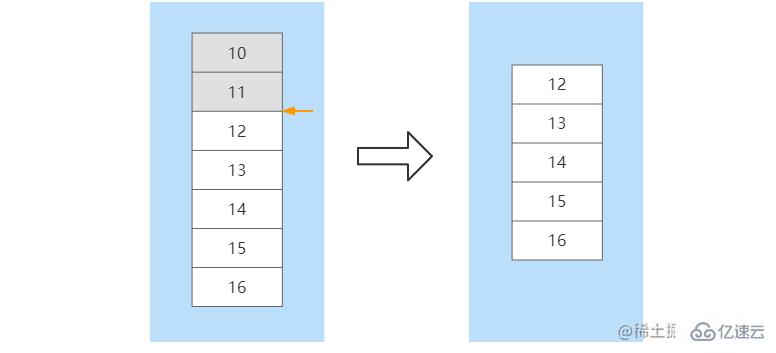
йғЁеҲҶж•°жҚ®еҗҢжӯҘеҸ‘з”ҹеңЁSlaveиҠӮзӮ№еҸ‘з”ҹе®•жңәпјҢ并且еңЁзҹӯж—¶й—ҙеҶ…иҝӣиЎҢдәҶжңҚеҠЎжҒўеӨҚгҖӮзҹӯж—¶й—ҙеҶ…дё»д»ҺиҠӮзӮ№д№Ӣй—ҙзҡ„ж•°жҚ®е·®йўқдёҚдјҡеӨӘеӨ§пјҢеҰӮжһңжү§иЎҢе…ЁйҮҸж•°жҚ®еҗҢжӯҘе°ҶдјҡжҜ”иҫғиҖ—ж—¶гҖӮйғЁеҲҶж•°жҚ®еҗҢжӯҘж—¶пјҢSlaveдјҡеҗ‘MasterиҠӮзӮ№е»әз«Ӣsocketй•ҝиҝһжҺҘ并еҸ‘йҖҒеёҰжңүдёҖдёӘoffsetеҒҸ移йҮҸзҡ„ж•°жҚ®еҗҢжӯҘиҜ·жұӮпјҢиҝҷдёӘoffsetеҸҜд»ҘзҗҶи§Јж•°жҚ®еҗҢжӯҘзҡ„дҪҚзҪ®гҖӮMasterиҠӮзӮ№еңЁж”¶еҲ°ж•°жҚ®еҗҢжӯҘиҜ·жұӮеҗҺпјҢдјҡж №жҚ®offsetз»“еҗҲbufferзј“еҶІеҢәеҶ…ж–°зҡ„ж”№еҶҷе‘Ҫд»ӨиҝӣиЎҢдҪҚзҪ®зЎ®е®ҡгҖӮеҰӮжһңзЎ®е®ҡдәҶoffsetзҡ„дҪҚзҪ®пјҢйӮЈд№Ҳе°ұдјҡе°ҶиҝҷдёӘдҪҚзҪ®еҫҖеҗҺзҡ„жүҖжңүж”№еҶҷе‘Ҫд»ӨеҸ‘йҖҒеҲ°SlaveиҠӮзӮ№гҖӮеҰӮжһңжІЎжңүзЎ®е®ҡoffsetзҡ„дҪҚзҪ®пјҢйӮЈд№ҲдјҡеҶҚж¬Ўжү§иЎҢе…ЁйҮҸж•°жҚ®еҗҢжӯҘгҖӮжҜ”еҰӮпјҢеңЁSlaveиҠӮзӮ№жІЎжңүе®•жңәд№ӢеүҚе‘Ҫд»Өе·Із»ҸеҗҢжӯҘеҲ°дәҶoffset=11иҝҷдёӘдҪҚзҪ®пјҢеҪ“иҜҘиҠӮзӮ№йҮҚеҗҜеҗҺпјҢеҗ‘MasterиҠӮзӮ№еҸ‘йҖҒиҜҘoffsetпјҢMasterж №жҚ®offsetеңЁзј“еҶІеҢәдёӯиҝӣиЎҢе®ҡдҪҚпјҢеңЁе®ҡдҪҚеҲ°11иҝҷдёӘдҪҚзҪ®еҗҺпјҢе°ҶиҜҘдҪҚзҪ®еҫҖеҗҺзҡ„жүҖжңүе‘Ҫд»ӨеҸ‘йҖҒз»ҷSlaveгҖӮеңЁж•°жҚ®еҗҢжӯҘе®ҢжҲҗеҗҺпјҢеҗҺз»ӯMasterиҠӮзӮ№зҡ„е‘Ҫд»ӨдјҡдёҚж–ӯзҡ„еҸ‘йҖҒеҲ°иҜҘSlaveиҠӮзӮ№
дјҳзјәзӮ№
дјҳзӮ№
еҸҜд»Ҙе®һзҺ°дёҖдё»еӨҡд»ҺпјҢиҜ»еҶҷеҲҶзҰ»пјҢеҮҸиҪ»MasterиҠӮзӮ№иҜ»ж“ҚдҪңеҺӢеҠӣ
жҳҜе“Ёе…өпјҢйӣҶзҫӨжһ¶жһ„зҡ„еҹәзЎҖ
зјәзӮ№
дёҚе…·еӨҮиҮӘеҠЁдё»д»ҺеҲҮжҚўеҠҹиғҪпјҢеҪ“MasterиҠӮзӮ№е®•жңәеҗҺпјҢйңҖиҰҒжүӢеҠЁеҲҮжҚўдё»иҠӮзӮ№
е®№жҳ“еҮәзҺ°ж•°жҚ®дёҚдёҖиҮҙпјҢеҪ“MasterиҠӮзӮ№е®•жңәеүҚпјҢеҰӮжһңжңүж•°жҚ®жңӘеҗҢжӯҘпјҢеҲҷдјҡйҖ жҲҗж•°жҚ®дёўеӨұ
е“Ёе…өжЁЎејҸ
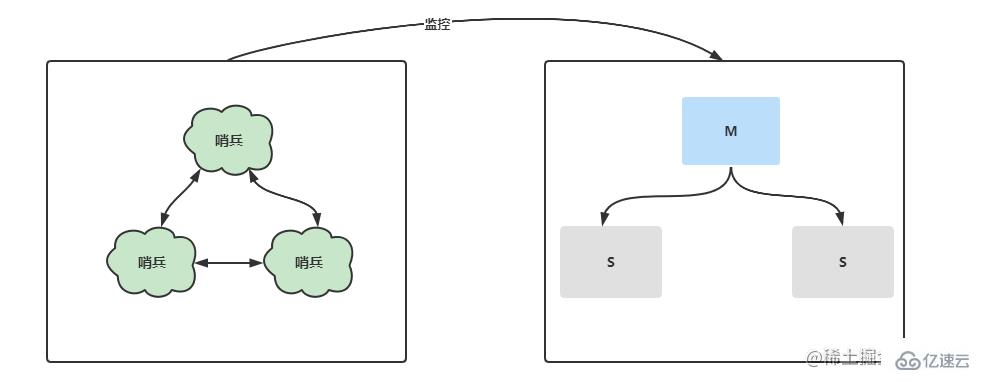
е“Ёе…өжЁЎејҸеҜ№дё»д»ҺеӨҚеҲ¶иҝӣиЎҢдәҶиҝӣдёҖжӯҘдјҳеҢ–пјҢзӢ¬з«ӢеҮәеҚ•зӢ¬зҡ„е“Ёе…өиҝӣзЁӢз”ЁдәҺзӣ‘жҺ§дё»д»Һжһ¶жһ„дёӯзҡ„жңҚеҠЎеҷЁзҠ¶жҖҒпјҢдёҖж—ҰеҸ‘з”ҹе®•жңәпјҢе“Ёе…өдјҡеңЁзҹӯж—¶й—ҙеҶ…йҖүдёҫеҮәж–°зҡ„MasterиҠӮзӮ№е№¶иҝӣиЎҢдё»д»ҺеҲҮжҚўгҖӮдёҚд»…еҰӮжӯӨпјҢеңЁеӨҡе“Ёе…өзҡ„иҠӮзӮ№дёӢпјҢжҜҸдёӘе“Ёе…өйғҪдјҡзӣёдә’иҝӣиЎҢзӣ‘жҺ§пјҢзӣ‘жҺ§е“Ёе…өиҠӮзӮ№жҳҜеҗҰе®•жңәгҖӮ
зҺҜеўғй…ҚзҪ®
| IP | дё»/д»ҺиҠӮзӮ№ | з«ҜеҸЈ | е“Ёе…өз«ҜеҸЈ | зүҲжң¬ |
|---|
| 192.168.36.128 | дё» | 6379 | 26379 | 5.0.14 |
| 192.168.36.130 | д»Һ | 6379 | 26379 | 5.0.14 |
| 192.168.36.131 | д»Һ | 6379 | 26379 | 5.0.14 |
дё»д»ҺеӨҚеҲ¶жҳҜе“Ёе…өжЁЎејҸзҡ„еҹәзЎҖпјҢжүҖд»ҘеңЁжҗӯе»әе“Ёе…өеүҚйңҖиҰҒе®ҢжҲҗдё»д»ҺеӨҚеҲ¶зҡ„й…ҚзҪ®гҖӮеңЁжҗӯе»әе®Ңдё»д»ҺеҗҺпјҢе“Ёе…өзҡ„жҗӯе»әе°ұе®№жҳ“еҫҲеӨҡгҖӮ
жүҫеҲ°е®үиЈ…зӣ®еҪ•дёӢзҡ„sentinel.confж–Ү件并иҝӣиЎҢдҝ®ж”№гҖӮдё»иҰҒдҝ®ж”№дёӨдёӘең°ж–№пјҢеҲҶеҲ«дёәе“Ёе…өз«ҜеҸЈportе’Ңзӣ‘жҺ§зҡ„дё»иҠӮзӮ№ipең°еқҖе’Ңз«ҜеҸЈеҸ·гҖӮ


еңЁй…ҚзҪ®е®ҢжҲҗеҗҺпјҢеҸҜд»ҘдҪҝз”Ёе‘Ҫд»ӨеҗҜеҠЁеҗ„жңәеҷЁзҡ„е“Ёе…өжңҚеҠЎгҖӮеҗҜеҠЁжҲҗеҠҹеҗҺпјҢеҸҜжҹҘзңӢredisжңҚеҠЎе’Ңе“Ёе…өжңҚеҠЎзҡ„иҝӣиЎҢдҝЎжҒҜгҖӮ
 жҗӯе»әжҲҗеҠҹеҗҺпјҢе°ұжқҘйҖҡиҝҮд»Јз Ғжј”зӨәдё»иҠӮзӮ№е®•жңәзҡ„жғ…еҶөдёӢпјҢе“Ёе…өжҳҜеҗҰдјҡеё®еҠ©зі»з»ҹиҮӘеҠЁиҝӣиЎҢдё»еӨҮеҲҮжҚўгҖӮеңЁspringbootйЎ№зӣ®дёӯеј•е…ҘеҜ№еә”зҡ„pom,并й…ҚзҪ®еҜ№еә”зҡ„redisе“Ёе…өдҝЎжҒҜгҖӮ
жҗӯе»әжҲҗеҠҹеҗҺпјҢе°ұжқҘйҖҡиҝҮд»Јз Ғжј”зӨәдё»иҠӮзӮ№е®•жңәзҡ„жғ…еҶөдёӢпјҢе“Ёе…өжҳҜеҗҰдјҡеё®еҠ©зі»з»ҹиҮӘеҠЁиҝӣиЎҢдё»еӨҮеҲҮжҚўгҖӮеңЁspringbootйЎ№зӣ®дёӯеј•е…ҘеҜ№еә”зҡ„pom,并й…ҚзҪ®еҜ№еә”зҡ„redisе“Ёе…өдҝЎжҒҜгҖӮ
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.2.2.RELEASE</version></dependency><dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version></dependency>
server:
port: 8081spring:
redis:
sentinel:
master: mymaster # дё»жңҚеҠЎиҠӮзӮ№
nodes: 192.168.36.128:26379,192.168.36.130:26379,192.168.36.131:26379 #е“Ёе…өиҠӮзӮ№
timeout: 3000 #иҝһжҺҘи¶…ж—¶ж—¶й—ҙ
@Slf4j
@RestController
public class RedisTest {
@Resource
private StringRedisTemplate stringRedisTemplate;
/*
* жҜҸз§’й’ҹеҗ‘redisдёӯеҶҷе…Ҙж•°жҚ®пјҢдёӯйҖ”killжҺүдё»иҠӮзӮ№иҝӣзЁӢпјҢжЁЎжӢҹе®•жңә
*/
@GetMapping("/redis/testSet")
public void test(@RequestParam(name = "key") String key,
@RequestParam(name = "value") String value) throws InterruptedException {
int idx=0;
for(;;){
try {
idx++;
stringRedisTemplate.opsForValue().set(key+idx, value);
log.info("=====еӯҳеӮЁжҲҗеҠҹ:{},{}=====",key+idx,value);
}catch (Exception e){
log.error("====иҝһжҺҘredisжңҚеҠЎеҷЁеӨұиҙҘ:{}====",e.getMessage());
}
Thread.sleep(1000);
}
}
}еҪ“еҗҜеҠЁжңҚеҠЎеҗҺпјҢйҖҡиҝҮиҠӮеҗҺеҗ‘еҗҺз«Ҝдј йҖ’ж•°жҚ®пјҢеҸҜд»ҘзңӢеҲ°иҫ“еҮәзҡ„ж—Ҙеҝ—пјҢиЎЁзӨәredisе“Ёе…өйӣҶзҫӨе·Із»ҸеҸҜд»ҘжӯЈеёёиҝҗиЎҢдәҶгҖӮйӮЈд№ҲиҝҷдёӘж—¶еҖҷkillжҺү36.128жңәеҷЁдёҠзҡ„дё»иҠӮзӮ№пјҢжЁЎжӢҹжңҚеҠЎе®•жңәгҖӮйҖҡиҝҮж—Ҙеҝ—еҸҜд»ҘзҹҘйҒ“пјҢжңҚеҠЎеҮәзҺ°ејӮеёёдәҶпјҢеңЁиҝҮеҚҒеҮ з§’еҸ‘зҺ°е“Ёе…өе·Із»ҸиҮӘеҠЁеё®зі»з»ҹиҝӣиЎҢдәҶдё»д»ҺеҲҮжҚўпјҢ并且жңҚеҠЎд№ҹеҸҜд»ҘжӯЈеёёи®ҝй—®дәҶгҖӮ
2022-11-14 22:20:23.134 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test14,123=====
2022-11-14 22:20:24.142 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test15,123=====
2022-11-14 22:20:24.844 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was /192.168.36.128:6379
2022-11-14 22:20:26.909 WARN 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379
2022-11-14 22:20:28.165 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====иҝһжҺҘredisжңҚеҠЎеҷЁеӨұиҙҘ:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)====
2022-11-14 22:20:31.199 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379
2022-11-14 22:20:52.189 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====иҝһжҺҘredisжңҚеҠЎеҷЁеӨұиҙҘ:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)====
2022-11-14 22:20:53.819 WARN 8764 --- [ioEventLoop-4-2] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379
2022-11-14 22:20:56.194 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====иҝһжҺҘredisжңҚеҠЎеҷЁеӨұиҙҘ:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)====
2022-11-14 22:20:57.999 INFO 8764 --- [xecutorLoop-1-2] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379
2022-11-14 22:20:58.032 INFO 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ReconnectionHandler : Reconnected to 192.168.36.131:6379
2022-11-14 22:20:58.040 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test24,123=====
2022-11-14 22:20:59.051 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test25,123=====
2022-11-14 22:21:00.057 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test26,123=====
2022-11-14 22:21:01.065 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====еӯҳеӮЁжҲҗеҠҹ:test27,123=====
ж•…йҡңиҪ¬з§»
еңЁеӨҡдёӘе“Ёе…өзҡ„жЁЎејҸдёӢпјҢжҜҸдёӘе“Ёе…өйғҪдјҡеҗ‘redisиҠӮзӮ№еҸ‘йҖҒеҝғи·іеҢ…жқҘжЈҖжөӢиҠӮзӮ№зҡ„иҝҗиЎҢзҠ¶жҖҒгҖӮеҰӮжһңжҹҗдёӘе“Ёе…өеҸ‘зҺ°дё»иҠӮзӮ№иҝһжҺҘи¶…ж—¶дәҶпјҢжІЎжңү收еҲ°еҝғи·іпјҢйӮЈд№Ҳзі»з»ҹ并дёҚдјҡз«ӢеҲ»иҝӣиЎҢж•…йҡңиҪ¬з§»пјҢиҝҷз§Қжғ…еҶөеҸ«еҒҡдё»и§ӮдёӢзәҝгҖӮеҰӮжһңеҗҺз»ӯзҡ„е“Ёе…өиҠӮзӮ№еҸ‘зҺ°пјҢдёҺдё»иҠӮзӮ№зҡ„еҝғи·ід№ҹеӨұиҙҘдәҶ并且哨е…өж•°йҮҸи¶…иҝҮ2дёӘпјҢйӮЈд№ҲиҝҷдёӘж—¶еҖҷе°ұдјҡи®Өдёәдё»иҠӮзӮ№е®ўи§ӮдёӢзәҝпјҢ并且дјҡиҝӣиЎҢж•…йҡңиҪ¬з§»пјҢиҝҷдёӘе®ўи§ӮдёӢзәҝзҡ„ж•°еҖјеҸҜд»ҘеңЁе“Ёе…өзҡ„й…ҚзҪ®ж–Ү件дёӯиҝӣиЎҢй…ҚзҪ®гҖӮ
sentinel monitor master 192.168.36.128 6378 2
зҷ»еҪ•еҗҺеӨҚеҲ¶
еңЁж•…йҡңиҪ¬з§»еүҚпјҢйңҖиҰҒйҖүдёҫеҮәдёҖдёӘе“Ёе…өleaderжқҘиҝӣиЎҢMasterиҠӮзӮ№зҡ„йҮҚж–°йҖүдёҫгҖӮе“Ёе…өзҡ„йҖүдёҫиҝҮзЁӢеӨ§иҮҙеҸҜд»ҘеҲҶдёәдёүжӯҘпјҡ
еҪ“жҹҗдёӘзҡ„е“Ёе…өзЎ®е®ҡдё»иҠӮзӮ№е·Із»ҸдёӢзәҝж—¶пјҢдјҡеғҸе…¶д»–е“Ёе…өеҸ‘йҖҒis-master-down-by-addrе‘Ҫд»ӨпјҢиҰҒжұӮе°ҶиҮӘе·ұи®ҫдёәleaderпјҢ并еӨ„зҗҶж•…йҡңиҪ¬з§»е·ҘдҪңгҖӮ
е…¶д»–е“Ёе…өеңЁж”¶еҲ°е‘Ҫд»ӨеҗҺпјҢиҝӣиЎҢжҠ•зҘЁйҖүдёҫ
еҰӮжһңзҘЁж•°иҝҮеҚҠж—¶пјҢйӮЈд№ҲеҸ‘йҖҒе‘Ҫд»Өзҡ„е“Ёе…өиҠӮзӮ№е°ҶжҲҗдёәдё»иҠӮзӮ№пјҢ并иҝӣиЎҢж•…йҡңиҪ¬з§»гҖӮ
еҪ“йҖүдёҫеҮәдё»е“Ёе…өеҗҺпјҢйӮЈд№ҲиҝҷдёӘдё»е“Ёе…өе°ұдјҡиҝҮж»ӨжҺүе®•жңәзҡ„redisиҠӮзӮ№пјҢйҮҚж–°йҖүдёҫеҮәMasterиҠӮзӮ№гҖӮйҰ–е…Ҳдјҡж №жҚ®redisиҠӮзӮ№зҡ„дјҳе…Ҳзә§иҝӣиЎҢйҖүдёҫ(slave-priority)пјҢж•°еҖји¶ҠеӨ§зҡ„д»ҺиҠӮзӮ№е°Ҷдјҡиў«йҖүдёҫдёәдё»иҠӮзӮ№гҖӮеҰӮжһңиҝҷдёӘдјҳе…Ҳзә§зӣёеҗҢпјҢйӮЈд№Ҳдё»е“Ёе…өиҠӮзӮ№е°ұдјҡйҖүжӢ©ж•°жҚ®жңҖе…Ёзҡ„д»ҺиҠӮзӮ№дҪңдёәж–°зҡ„дё»иҠӮзӮ№гҖӮеҰӮжһңиҝҳжҳҜйҖүдёҫеӨұиҙҘпјҢйӮЈд№Ҳе°ұдјҡйҖүдёҫеҮәиҝӣзЁӢidжңҖе°Ҹзҡ„д»ҺиҠӮзӮ№дҪңдёәдё»иҠӮзӮ№гҖӮ
и„‘иЈӮ
еңЁйӣҶзҫӨзҺҜеўғдёӢдјҡз”ұдәҺзҪ‘з»ңзӯүеҺҹеӣ еҮәзҺ°и„‘иЈӮзҡ„жғ…еҶөпјҢжүҖи°“зҡ„и„‘иЈӮе°ұжҳҜз”ұдәҺдё»иҠӮзӮ№е’Ңд»ҺиҠӮзӮ№е’Ңе“Ёе…өеӨ„дәҺдёҚеҗҢзҡ„зҪ‘з»ңеҲҶеҢәпјҢз”ұдәҺзҪ‘з»ңжіўеҠЁзӯүеҺҹеӣ пјҢдҪҝеҫ—е“Ёе…өжІЎжңүиғҪеӨҹеҚідҪҝжҺҘ收еҲ°дё»иҠӮзӮ№зҡ„еҝғи·іпјҢжүҖд»ҘйҖҡиҝҮйҖүдёҫзҡ„ж–№ејҸйҖүдёҫдәҶдёҖдёӘд»ҺиҠӮзӮ№дёәж–°зҡ„дё»иҠӮзӮ№пјҢиҝҷж ·е°ұеӯҳеңЁдәҶдёӨдёӘдё»иҠӮзӮ№пјҢе°ұеғҸдёҖдёӘдәәжңүдёӨдёӘеӨ§и„‘дёҖж ·пјҢиҝҷж ·дјҡеҜјиҮҙе®ўжҲ·з«ҜиҝҳеңЁеғҸиҖҒзҡ„дё»иҠӮзӮ№йӮЈйҮҢеҶҷе…Ҙж•°жҚ®пјҢж–°иҠӮзӮ№ж— жі•еҗҢжӯҘж•°жҚ®пјҢеҪ“зҪ‘з»ңжҒўеӨҚеҗҺпјҢе“Ёе…өдјҡе°ҶиҖҒзҡ„дё»иҠӮзӮ№йҷҚдёәд»ҺиҠӮзӮ№пјҢиҝҷж—¶еҶҚд»Һж–°дё»иҠӮзӮ№еҗҢжӯҘж•°жҚ®пјҢиҝҷдјҡеҜјиҮҙеӨ§йҮҸж•°жҚ®дёўеӨұгҖӮеҰӮжһңйңҖиҰҒйҒҝе…Қи„‘иЈӮзҡ„й—®йўҳпјҢеҸҜд»Ҙй…ҚзҪ®дёӢйқўдёӨиЎҢдҝЎжҒҜгҖӮ
min-replicas-to-write 3 # жңҖе°‘д»ҺиҠӮзӮ№дёә3
min-replicas-max-lag 10 # иЎЁзӨәж•°жҚ®еӨҚеҲ¶е’ҢеҗҢжӯҘзҡ„延иҝҹдёҚиғҪи¶…иҝҮ10з§’
дјҳзјәзӮ№
дјҳзӮ№пјҡйҷӨдәҶжӢҘжңүдё»д»ҺеӨҚеҲ¶зҡ„дјҳзӮ№еӨ–пјҢиҝҳеҸҜд»ҘиҝӣиЎҢж•…йҡңиҪ¬з§»пјҢдё»д»ҺеҲҮжҚўпјҢзі»з»ҹжӣҙеҠ еҸҜйқ гҖӮ
зјәзӮ№пјҡж•…йҡңиҪ¬з§»йңҖиҰҒиҠұиҙ№дёҖе®ҡзҡ„ж—¶й—ҙпјҢеңЁй«ҳ并еҸ‘еңәжҷҜдёӢе®№жҳ“еҮәзҺ°ж•°жҚ®дёўеӨұгҖӮдёҚе®№жҳ“е®һзҺ°еңЁзәҝжү©е®№гҖӮ
ClusterжЁЎејҸ
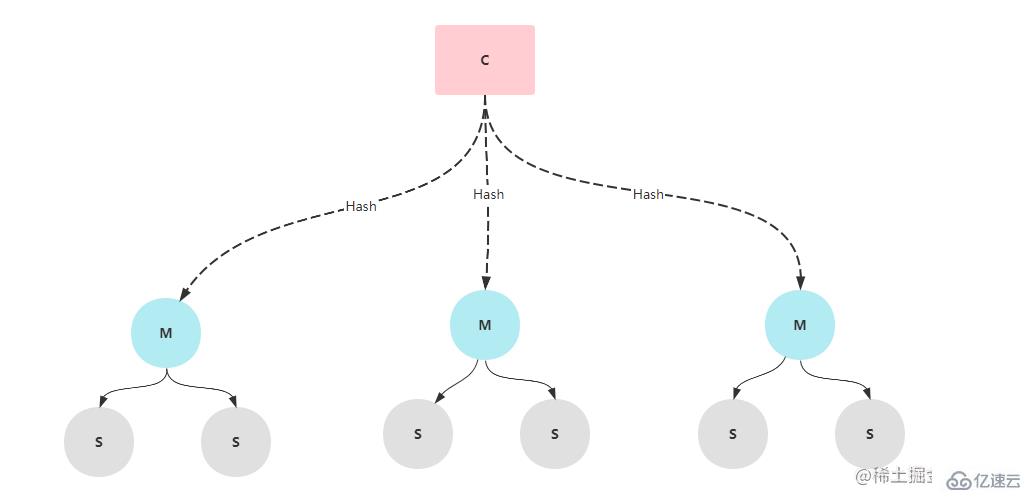
е“Ёе…өжЁЎејҸдёӯиҷҪ然еңЁдё»иҠӮзӮ№е®•жңәзҡ„жғ…еҶөдёӢиғҪеӨҹеҒҡеҲ°дё»д»ҺеҲҮжҚўпјҢдҪҶжҳҜеңЁеҲҮжҚўзҡ„иҝҮзЁӢдёӯйңҖиҰҒиҠұиҙ№еҚҒеҮ з§’жҲ–иҖ…жӣҙд№…зҡ„ж—¶й—ҙ,дјҡйҖ жҲҗйғЁеҲҶж•°жҚ®зҡ„дёўеӨұгҖӮеҰӮжһңеңЁе№¶еҸ‘йҮҸдёҚй«ҳзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘдҪҝз”ЁиҜҘйӣҶзҫӨжЁЎејҸпјҢдҪҶжҳҜеңЁй«ҳ并еҸ‘зҡ„жғ…еҶөдёӢпјҢиҝҷеҚҒеҮ з§’зҡ„ж—¶й—ҙеҸҜиғҪдјҡйҖ жҲҗдёҘйҮҚзҡ„еҗҺжһңпјҢжүҖд»ҘпјҢеңЁеҫҲеӨҡдә’иҒ”зҪ‘е…¬еҸёйғҪжҳҜйҮҮз”ЁClusterйӣҶзҫӨжһ¶жһ„гҖӮClusterйӣҶзҫӨдёӯз”ұеӨҡдёӘredisиҠӮзӮ№з»„жҲҗпјҢжҜҸдёӘredisжңҚеҠЎиҠӮзӮ№йғҪжңүдёҖдёӘMasterиҠӮзӮ№е’ҢеӨҡдёӘSlaveиҠӮзӮ№пјҢеңЁиҝӣиЎҢж•°жҚ®еӯҳеӮЁж—¶пјҢredisдјҡеҜ№ж•°жҚ®зҡ„keyиҝӣиЎҢhashиҝҗз®—е№¶ж №жҚ®иҝҗз®—з»“жһңеҲҶй…ҚеҲ°дёҚеҗҢзҡ„ж§ҪдҪҚгҖӮдёҖиҲ¬жғ…еҶөдёӢпјҢClusterйӣҶзҫӨжһ¶жһ„иҰҒи®ҫзҪ®6дёӘиҠӮзӮ№(дёүдё»дёүд»Һ)гҖӮ
зҺҜеўғжҗӯе»ә
з”ұдәҺеҸӘжңүдёүеҸ°иҷҡжӢҹжңәпјҢжүҖд»ҘйңҖиҰҒеңЁжҜҸеҸ°жңҚеҠЎеҷЁдёҠйқўжҗӯе»әдёӨдёӘredisжңҚеҠЎпјҢз«ҜеҸЈеҲҶеҲ«дёә6379е’Ң6380пјҢиҝҷдёӘеҲҡеҘҪеҸҜд»Ҙжһ„е»ә6дёӘиҠӮзӮ№гҖӮ
| IP | дё»/д»ҺиҠӮзӮ№ | з«ҜеҸЈ | зүҲжң¬ |
|---|
| 192.168.36.128 | - | 6379 | 5.0.14 |
| 192.168.36.128 | - | 6380 | 5.0.14 |
| 192.168.36.130 | - | 6379 | 5.0.14 |
| 192.168.36.130 | - | 6380 | 5.0.14 |
| 192.168.36.131 | - | 6379 | 5.0.14 |
| 192.168.36.131 | - | 6380 | 5.0.14 |
дёәдәҶзңӢиө·жқҘдёҚжҳҜйӮЈд№Ҳж··д№ұпјҢеҸҜд»Ҙдёәclusterж–°е»әдёҖдёӘж–Ү件еӨ№пјҢ并е°Ҷredisзҡ„ж–Ү件жӢ·иҙқеҲ°clusterж–Ү件еӨ№дёӯпјҢ并дҝ®ж”№ж–Ү件еӨ№еҗҚдёәredis-6379,reids-6380гҖӮ
ж–°е»әе®ҢжҲҗеҗҺпјҢдҝ®ж”№жҜҸдёӘиҠӮзӮ№зҡ„redis.confй…ҚзҪ®ж–Ү件пјҢжүҫеҲ°clusterзӣёе…ізҡ„й…ҚзҪ®дҪҚзҪ®пјҢе°Ҷcluster-enableжӣҙж”№дёәyes,иЎЁзӨәејҖеҗҜйӣҶзҫӨжЁЎејҸгҖӮејҖеҗҜеҗҺпјҢйңҖиҰҒдҝ®ж”№йӣҶзҫӨиҠӮзӮ№иҝһжҺҘзҡ„и¶…ж—¶ж—¶й—ҙcluster-node-timeoutпјҢиҠӮзӮ№й…ҚзҪ®ж–Ү件еҗҚcluster-config-fileзӯүзӯүпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҗҢдёҖеҸ°жңәеҷЁдёҠйқўзҡ„жңҚеҠЎиҠӮзӮ№и®°еҫ—жӣҙж”№з«ҜеҸЈеҸ·гҖӮ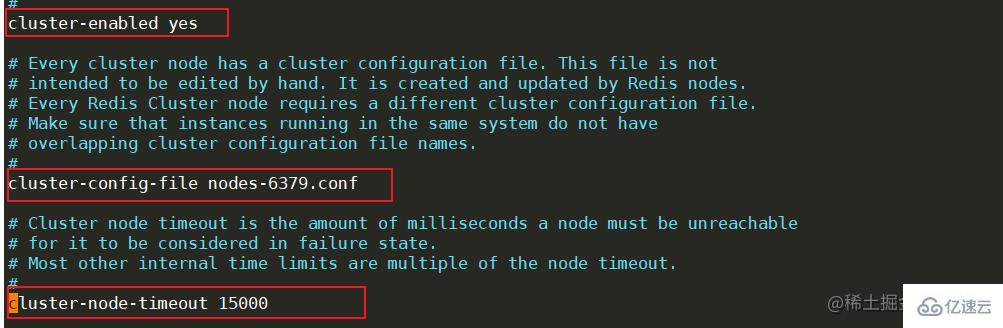



еңЁжҜҸдёӘиҠӮзӮ№йғҪй…ҚзҪ®е®ҢжҲҗеҗҺпјҢеҸҜд»Ҙдҫқж¬ЎеҗҜеҠЁеҗ„иҠӮзӮ№гҖӮеҗҜеҠЁжҲҗеҠҹеҗҺпјҢеҸҜд»ҘжҹҘзңӢredisзҡ„иҝӣзЁӢдҝЎжҒҜпјҢеҗҺйқўжңүжҳҺжҳҫзҡ„ж ҮиҜҶдёә[cluster]гҖӮ

зҺ°еңЁиҷҪ然жҜҸдёӘиҠӮзӮ№зҡ„redisйғҪе·Із»ҸжӯЈеёёеҗҜеҠЁдәҶпјҢдҪҶжҳҜжҜҸдёӘиҠӮзӮ№д№Ӣй—ҙ并没жңүд»»дҪ•иҒ”зі»е•ҠгҖӮжүҖд»ҘиҝҷдёӘж—¶еҖҷиҝҳйңҖиҰҒжңҖеҗҺдёҖжӯҘпјҢе°Ҷеҗ„иҠӮзӮ№е»әз«Ӣе…ізі»гҖӮеңЁд»»ж„ҸдёҖеҸ°жңәеҷЁдёҠиҝҗиЎҢдёӢйқўзҡ„е‘Ҫд»Ө-- cluster create ip:port,иҝӣиЎҢйӣҶзҫӨеҲӣе»әгҖӮе‘Ҫд»Өжү§иЎҢжҲҗеҠҹеҗҺпјҢеҸҜд»ҘзңӢеҲ°ж§ҪдҪҚзҡ„еҲҶеёғжғ…еҶөе’Ңдё»д»Һе…ізі»гҖӮ
./src/redis-cli --cluster create 192.168.36.128:6379 192.168.36.128:6380 192.168.36.130:6379 192.168.36.130:6380 192.168.36.131:6379 192.168.36.131:6380 --cluster-replicas 1еӨҚеҲ¶д»Јз Ғ
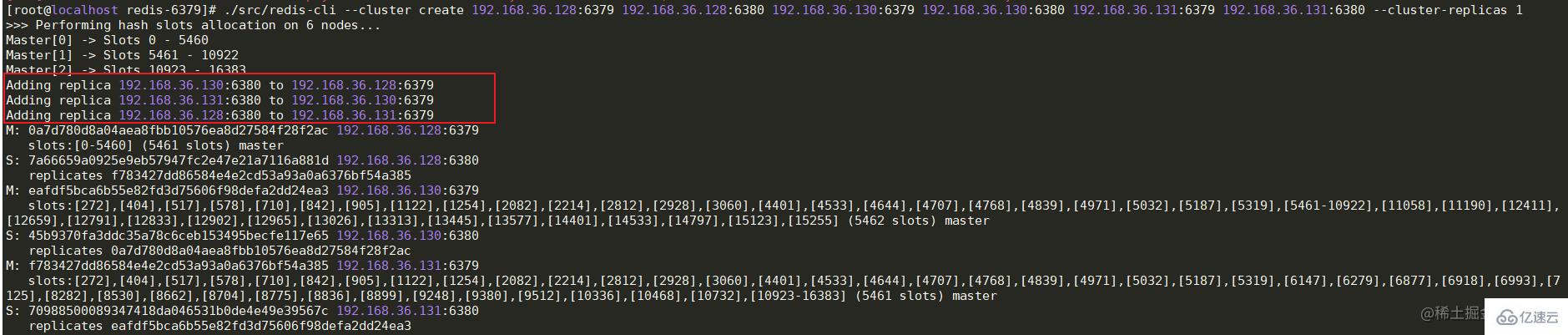
clusterжҲҗеҠҹеҗҜеҠЁеҗҺпјҢеҸҜд»ҘеңЁд»Јз Ғдёӯз®ҖеҚ•зҡ„жөӢиҜ•дёҖдёӢпјҢиҝҷйҮҢзҡ„д»Јз Ғдҫқж—§йҮҮз”Ёе“Ёе…өжЁЎејҸдёӯзҡ„жөӢиҜ•д»Јз ҒпјҢеҸӘжҳҜе°Ҷsentinelзӣёе…ізҡ„дҝЎжҒҜжіЁйҮҠжҺү并еҠ дёҠclusterзҡ„иҠӮзӮ№дҝЎжҒҜеҚіеҸҜгҖӮ
spring:
redis:
cluster:
nodes: 192.168.36.128:6379,192.168.36.128:6380,192.168.36.130:6379,192.168.36.130:6380,192.168.36.131:6379,192.168.36.131:6380# sentinel:# master: mymaster# nodes: 192.168.36.128:26379,192.168.36.130:26379,192.168.36.131:26379
timeout: 3000
lettuce:
pool:
max-active: 80
min-idle: 50
ж•°жҚ®еҲҶзүҮ
ClusterжЁЎејҸдёӢз”ұдәҺеӯҳеңЁеӨҡдёӘMasterиҠӮзӮ№пјҢжүҖд»ҘеңЁеӯҳеӮЁж•°жҚ®ж—¶пјҢйңҖиҰҒзЎ®е®ҡе°ҶиҝҷдёӘж•°жҚ®еӯҳеӮЁеҲ°е“ӘеҸ°жңәеҷЁдёҠгҖӮдёҠйқўеңЁеҗҜеҠЁйӣҶзҫӨжҲҗеҠҹеҗҺеҸҜд»ҘзңӢеҲ°жҜҸеҸ°MasterиҠӮзӮ№йғҪжңүиҮӘе·ұзҡ„дёҖдёӘж§ҪдҪҚ(Slots)иҢғеӣҙ,Master[0]зҡ„ж§ҪдҪҚиҢғеӣҙжҳҜ0 - 5460пјҢMaster[1]зҡ„ж§ҪдҪҚиҢғеӣҙжҳҜ5461 - 10922пјҢMaster[2]зҡ„ж§ҪдҪҚиҢғеӣҙжҳҜ10922 - 16383гҖӮredisеңЁеӯҳеӮЁеүҚдјҡйҖҡиҝҮCRC16ж–№жі•и®Ўз®—еҮәkeyзҡ„hashеҖјпјҢ并дёҺ16383иҝӣиЎҢдҪҚиҝҗз®—жқҘзЎ®е®ҡжңҖз»Ҳзҡ„ж§ҪдҪҚеҖјгҖӮжүҖд»ҘпјҢеҸҜд»ҘзҹҘйҒ“зЎ®е®ҡж§ҪдҪҚзҡ„ж–№ејҸе°ұжҳҜ CRC16(key) & 16383гҖӮи®Ўз®—еҮәж§ҪдҪҚеҗҺпјҢжӯӨж—¶еңЁjavaжңҚеҠЎз«Ҝ并дёҚзҹҘйҒ“иҝҷдёӘж§ҪдҪҚеҜ№еә”еҲ°е“ӘдёҖеҸ°redisжңҚеҠЎпјҢе…¶е®һеңЁjavaжңҚеҠЎз«ҜеҗҜеҠЁжңҚеҠЎж—¶дјҡе°Ҷredisзҡ„зӣёе…іж§ҪдҪҚе’Ңжҳ е°„зҡ„ipдҝЎжҒҜиҝӣиЎҢдёҖдёӘжң¬ең°зј“еӯҳпјҢжүҖд»ҘзҹҘйҒ“ж§ҪдҪҚеҗҺпјҢе°ұдјҡзҹҘйҒ“еҜ№еә”ж§ҪдҪҚзҡ„ipгҖӮ
йҖүдёҫжңәеҲ¶
clusterжЁЎејҸдёӯзҡ„йҖүдёҫдёҺе“Ёе…өдёӯзҡ„дёҚеҗҢгҖӮеҪ“жҹҗдёӘд»ҺиҠӮзӮ№еҸ‘зҺ°иҮӘе·ұзҡ„дё»иҠӮзӮ№зҠ¶жҖҒеҸҳдёәfailзҠ¶жҖҒж—¶пјҢдҫҝе°қиҜ•иҝӣиЎҢж•…йҡңиҪ¬з§»гҖӮз”ұдәҺжҢӮжҺүзҡ„дё»иҠӮзӮ№еҸҜиғҪдјҡжңүеӨҡдёӘд»ҺиҠӮзӮ№пјҢд»ҺиҖҢеӯҳеңЁеӨҡдёӘд»ҺиҠӮзӮ№з«һдәүжҲҗдёәж–°дё»иҠӮзӮ№ гҖӮе…¶йҖүдёҫиҝҮзЁӢеӨ§жҰӮеҰӮдёӢпјҡ
д»ҺиҠӮзӮ№е°ҶиҮӘе·ұи®°еҪ•зҡ„йӣҶзҫӨcurrentEpochеҠ 1пјҢ并е№ҝж’ӯFAILOVER_AUTH_REQUESTдҝЎжҒҜпјҢйҖҡзҹҘйӣҶзҫӨдёӯзҡ„жүҖжңүиҠӮзӮ№пјҢйңҖиҰҒиҝӣиЎҢйҮҚж–°йҖүдёҫдәҶгҖӮ
е…¶д»–иҠӮзӮ№ж”¶еҲ°иҜҘдҝЎжҒҜпјҢдҪҶеҸӘжңүmasterиҠӮзӮ№дјҡиҝӣиЎҢе“Қеә”пјҢеҲӨж–ӯиҜ·жұӮиҖ…зҡ„еҗҲжі•жҖ§пјҢ并еҸ‘йҖҒ FAILOVER_AUTH_ACKпјҢеҜ№жҜҸдёҖдёӘepochеҸӘеҸ‘йҖҒдёҖж¬ЎackгҖӮ
еҸ‘йҖҒйҖҡзҹҘзҡ„д»ҺиҠӮзӮ№дјҡ收йӣҶеҗ„masterдё»иҠӮзӮ№иҝ”еӣһзҡ„FAILOVER_AUTH_ACKгҖӮ
еҰӮжһңиҜҘд»ҺиҠӮзӮ№ж”¶еҲ°зҡ„ackж•°иҝҮеҚҠпјҢйӮЈд№ҲиҜҘиҠӮзӮ№е°ұдјҡиў«йҖүдёҫдёәж–°зҡ„Masterдё»иҠӮзӮ№гҖӮжҲҗдёәдё»иҠӮзӮ№еҗҺпјҢе№ҝж’ӯйҖҡзҹҘе…¶д»–е°ҸйӣҶзҫӨиҠӮзӮ№
дјҳзјәзӮ№
дјҳзӮ№пјҡ
жңүеӨҡдёӘдё»иҠӮзӮ№пјҢеҒҡеҲ°еҺ»дёӯеҝғеҢ–гҖӮ
ж•°жҚ®еҸҜд»Ҙж§ҪдҪҚиҝӣиЎҢеҲҶеёғеӯҳеӮЁ
жү©еұ•жҖ§жӣҙй«ҳпјҢеҸҜз”ЁжҖ§жӣҙй«ҳгҖӮclusterйӣҶзҫӨдёӯзҡ„иҠӮзӮ№еҸҜд»ҘеңЁзәҝж·»еҠ жҲ–еҲ йҷӨпјҢе®ҳж–№жҺЁиҚҗиҠӮзӮ№ж•°дёҚи¶…1000гҖӮеҪ“йғЁеҲҶMasterиҠӮзӮ№дёҚеҸҜз”Ёж—¶пјҢж•ҙдёӘйӣҶзҫӨ任然еҸҜд»ҘжӯЈеёёе·ҘдҪңгҖӮ
зјәзӮ№пјҡ
д»ҘдёҠе°ұжҳҜвҖңRedisй«ҳеҸҜз”Ёжһ¶жһ„еҰӮдҪ•жҗӯе»әвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





