4 C++ Boost 正则表达式
目录: 离线文档: 去除HTML文件中的标签: 正则表达之检验程序: 正则表达式元字符: 锚点: 匹配多个字母与多个数字 标记:含有()一对小括号里面的东西,Boost中()不需要转译了 ?: 不被标记,不能被反向引用 重复特性[贪婪匹配,尽量去匹配最多的]: ? 非贪婪匹配[尽可能少的匹配]: 流模式,不会回头,匹配就匹配了,为高性能服务: 反向引用:必须存在被标记的表达式 或条件: 单词边界: 命名表达式: 注释: 分支重设: 正向预查: 举例1:只是匹配th不是匹配ing,但是ing必须存在 举例2:ing参与匹配,th不被消耗,in被匹配 举例3:除了ing不匹配,其他都匹配. 反向预查: 递归正则: 操作符优先级: 显示子串的个数 boost 正则表达式 sub match boost 正则表达式 算法regex_replace boost 正则表达式 迭代器 boost 正则表达式 -1,就是未被匹配的字符 boost 正则表达式 captures 官方代码为什么会出现段错误? boost 正则表达式 官方例子 boost 正则表达式 search方式 简单的词法分析器,分析C++类定义 boost 正则表达式 迭代器方式 简单的词法分析器,分析C++类定义 boost 正则表达式,将C++文件转换为HTML文件 boost 正则表达式 ,抓取网页中的所有连接:
离线文档:
boost_1_62_0/libs/regex/doc/html/boost_regex/syntax/perl_syntax.html
去除HTML文件中的标签:
chunli@Linux:~/workspace/Boost$ sed 's/<[\/]\?\([[:alpha:]][[:alnum:]]*[^>]*\)>//g' index.html
正则表达之检验程序:
chunli@Linux:~/boost$ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
if (argc != 2)
{
cerr << "Usage: " << argv[0] << " regex-str" << endl;
return 1;
}
boost::regex e(argv[1], boost::regex::icase);
//mark_count 返回regex中带标记子表达式的数量。带标记子表达式是指正则表达式中用圆括号括起来的部分
cout << "subexpressions: " << e.mark_count() << endl;
string line;
while (getline(cin, line))
{
boost::match_results<string::const_iterator> m;
if (boost::regex_search(line, m, e, boost::match_default))
{
const int n = m.size();
for (int i = 0; i < n; ++i)
{
cout << m[i] << " ";
}
cout << endl;
}
else
{
cout << setw(line.size()) << setfill('-') << '-' << right << endl;
}
}
}正则表达式元字符:
.[{}()\*+?|^$
锚点:
Anchors
A '^' character shall match the start of a line.
A '$' character shall match the end of a line.
匹配多个字母与多个数字
chunli@Linux:~/boost$ g++ main.cpp -l boost_regex -Wall && ./a.out "\w+\d+"
subexpressions: 0
Hello,world2016
world2016
标记:含有()一对小括号里面的东西,Boost中()不需要转译了
chunli@Linux:~/boost$ g++ main.cpp -l boost_regex -Wall && ./a.out "([[:alpha:]]+)[[:digit:]]+\1" subexpressions: 1 hello123abc8888888abc abc8888888abc abc \1为引用$1 只有被标记的内容才能被反向引用.
?: 不被标记,不能被反向引用
chunli@Linux:~/boost$ g++ main.cpp -l boost_regex -Wall && ./a.out '(?:[[:alpha:]]+)[[:digit:]]+' subexpressions: 0 abcd1234 abcd1234 11111@@ -------
重复特性[贪婪匹配,尽量去匹配最多的]:
* 任意次
+ 至少一次
? 一次
{n} n次
{n,} 大于等于n次
{n,m} n到m次
chunli@Linux:~/boost$ g++ main.cpp -l boost_regex -Wall && ./a.out 'a.*b'
subexpressions: 0
azzzzzzzzzbbaaazzzzzzzb
azzzzzzzzzbbaaazzzzzzzb? 非贪婪匹配[尽可能少的匹配]:
Non greedy repeats
The normal repeat operators are "greedy", that is to say they will consume as much input as possible. There are non-greedy versions available that will consume as little input as possible while still producing a match.
*? Matches the previous atom zero or more times, while consuming as little input as possible.
+? Matches the previous atom one or more times, while consuming as little input as possible.
?? Matches the previous atom zero or one times, while consuming as little input as possible.
{n,}? Matches the previous atom n or more times, while consuming as little input as possible.
{n,m}? Matches the previous atom between n and m times, while consuming as little input as possible.
chunli@Linux:~/boost$ g++ main.cpp -l boost_regex -Wall && ./a.out 'a.*?b'
subexpressions: 0
azzzzzzzzzbbaaazzzzzzzb
azzzzzzzzzb流模式,不会回头,匹配就匹配了,为高性能服务:
Possessive repeats
By default when a repeated pattern does not match then the engine will backtrack until a match is found. However, this behaviour can sometime be undesireble so there are also "possessive" repeats: these match as much as possible and do not then allow backtracking if the rest of the expression fails to match.
*+ Matches the previous atom zero or more times, while giving nothing back.
++ Matches the previous atom one or more times, while giving nothing back.
?+ Matches the previous atom zero or one times, while giving nothing back.
{n,}+ Matches the previous atom n or more times, while giving nothing back.
{n,m}+ Matches the previous atom between n and m times, while giving nothing back.
Back references反向引用:必须存在被标记的表达式
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '^(a*).*\1$' subexpressions: 1 a66a66 a66a66 asssasss asssasss
或条件:
Alternation The | operator will match either of its arguments, so for example: abc|def will match either "abc" or "def". Parenthesis can be used to group alternations, for example: ab(d|ef) will match either of "abd" or "abef". Empty alternatives are not allowed (these are almost always a mistake), but if you really want an empty alternative use (?:) as a placeholder, for example: |abc is not a valid expression, but (?:)|abc is and is equivalent, also the expression: (?:abc)?? has exactly the same effect. chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out 'l(i|o)ve' subexpressions: 1 love love o live live i ^C chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '\<l(i|o)ve\>' subexpressions: 1 love love o live live i chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out 'abc|123|234' subexpressions: 0 23 -- 123 123 abc abc 234 234 123456789abc 123
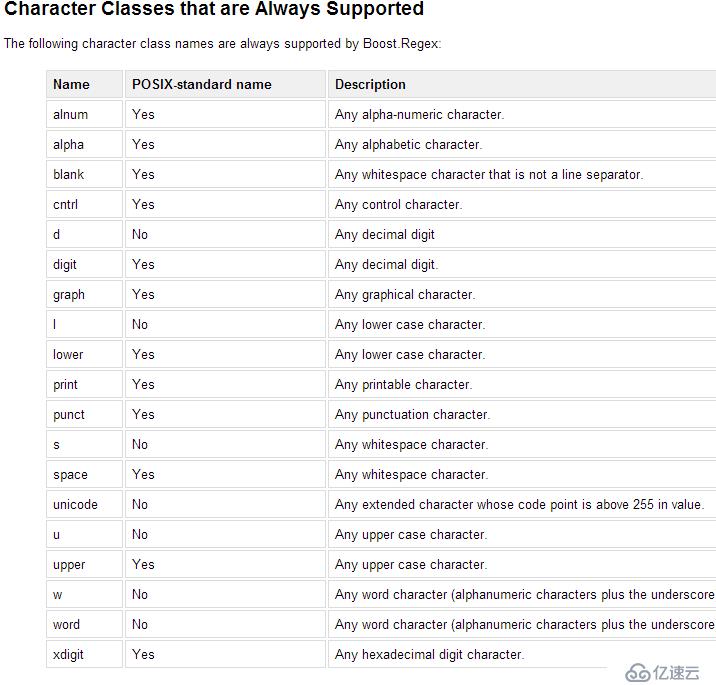
单词边界:
Word Boundaries Word Boundaries The following escape sequences match the boundaries of words: < Matches the start of a word. > Matches the end of a word. \b Matches a word boundary (the start or end of a word). \B Matches only when not at a word boundary.
命名表达式:
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '(?<r1>\d+)[[:blank:]]+\1'
subexpressions: 1
123 123
123 123 123
234 234
234 234 234
^C
chunli@Linux:~/boost$
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '(?<r1>\d+)[[:blank:]]+\g{r1}'
subexpressions: 1
1234 1234
1234 1234 1234
1236 1236
1236 1236 1236注释:
Comments (?# ... ) is treated as a comment, it's contents are ignored. chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '\d+(?#我的注释)' subexpressions: 0 hello1234 1234
分支重设:
Branch reset (?|pattern) resets the subexpression count at the start of each "|" alternative within pattern. The sub-expression count following this construct is that of whichever branch had the largest number of sub-expressions. This construct is useful when you want to capture one of a number of alternative matches in a single sub-expression index. In the following example the index of each sub-expression is shown below the expression: # before ---------------branch-reset----------- after / ( a ) (?| x ( y ) z | (p (q) r) | (t) u (v) ) ( z ) /x # 1 2 2 3 2 3 4 chunli@Linux:~/boost$ ./a.out '( a ) (?| x ( y ) z | (p (q) r) | (t) u (v) ) ( z ) /x' subexpressions: 4
正向预查:
即使字符已经被匹配,但是不被消耗,留着其他人继续匹配
Lookahead
(?=pattern) consumes zero characters, only if pattern matches.
(?!pattern) consumes zero characters, only if pattern does not match.
Lookahead is typically used to create the logical AND of two regular expressions, for example if a password must contain a lower case letter, an upper case letter, a punctuation symbol, and be at least 6 characters long, then the expression:
(?=.*[[:lower:]])(?=.*[[:upper:]])(?=.*[[:punct:]]).{6,}
could be used to validate the password.
举例1:只是匹配th不是匹配ing,但是ing必须存在
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out 'th(?=ing)' subexpressions: 0 those ----- thing th
举例2:ing参与匹配,th不被消耗,in被匹配
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out 'th(?=ing)(in)' subexpressions: 1 thing thin in those -----
举例3:除了ing不匹配,其他都匹配.
chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out 'th(?!ing)' subexpressions: 0 this th thing -----
反向预查:
Lookbehind (?<=pattern) consumes zero characters, only if pattern could be matched against the characters preceding the current position (pattern must be of fixed length). (?<!pattern) consumes zero characters, only if pattern could not be matched against the characters preceding the current position (pattern must be of fixed length). chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '(?<=ti)mer' subexpressions: 0 timer mer memer ----- chunli@Linux:~/boost$ g++ main.cpp -lboost_regex -Wall &&./a.out '(?<!ti)mer' subexpressions: 0 timer ----- hhmer mer
递归正则:
(?N) (?-N) (?+N) (?R) (?0) (?&NAME) (?R) and (?0) recurse to the start of the entire pattern. (?N) executes sub-expression N recursively, for example (?2) will recurse to sub-expression 2. (?-N) and (?+N) are relative recursions, so for example (?-1) recurses to the last sub-expression to be declared, and (?+1) recurses to the next sub-expression to be declared. (?&NAME) recurses to named sub-expression NAME.
操作符优先级:
Operator precedence
The order of precedence for of operators is as follows:
Collation-related bracket symbols [==] [::] [..]
Escaped characters \
Character set (bracket expression) []
Grouping ()
Single-character-ERE duplication * + ? {m,n}
Concatenation
Anchoring ^$
Alternation |===========================================================
Boost regex API
显示子串的个数
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
using boost::regex;
regex e1;
e1 = "^[[:xdigit:]]*$";
cout << e1.str() << endl;
cout << e1.mark_count() << endl;
//regex::save_subexpression_location如果没有打开, e2.subexpression(0)会报错
regex e2("\\b\\w+(?=ing)\\b.{2,}?([[:alpha:]]*)$",regex::perl | regex::icase|regex::save_subexpression_location );
cout << e2.str() << endl;
cout << e2.mark_count() << endl;
pair<regex::const_iterator,regex::const_iterator> sub1 = e2.subexpression(0);
string sub1Str(sub1.first,++sub1.second);
cout << sub1Str << endl;
return 0;
}
pi@raspberrypi:~/boost $
pi@raspberrypi:~/boost $ g++ main.cpp -lboost_regex -Wall &&./a.out
^[[1;5D^[[:xdigit:]]*$
0
\b\w+(?=ing)\b.{2,}?([[:alpha:]]*)$
1
([[:alpha:]]*)
pi@raspberrypi:~/boost $boost 正则表达式 sub match
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
using boost::regex;
//以T开头,跟多个字母 \b边界,然后是16进制匹配
regex e1("\\bT\\w+\\b ([[:xdigit:]]+)");//让正则表达式看到反斜杠
string s("Time ef09,Todo 001");
boost::smatch m;
//bool b = boost::regex_search(s,m,e1,boost::match_all);//:match_all只会匹配最后一下
bool b = boost::regex_search(s,m,e1);//默认只会匹配首次
cout << b <<endl;
const int n = m.size();
for(int i = 0; i<n; i++)
{
cout << "matched:" << i << " ,position:" << m.position(i) <<", ";
cout << "length:" << m.length(i) << " , str:" << m.str(i) << endl;
}
return 0;
}
pi@raspberrypi:~/boost $ g++ main.cpp -lboost_regex -Wall &&./a.out
1
matched:0 ,position:0, length:9 , str:Time ef09
matched:1 ,position:5, length:4 , str:ef09
pi@raspberrypi:~/boost $boost 正则表达式 算法regex_replace
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
using boost::regex;
regex e1("([TQV])|(\\*)|(@)");
string replaceFmt("(\\L?1$&)(?2+)(?3#)");//转小写,转+,转#
string src("guTdQhV@@g*b*");//输入的字符串
cout << "before replaced: " <<src << endl;
//before replaced: guTdQhV@@g*b*
string newStr1 = regex_replace(src,e1,replaceFmt,boost::match_default|boost::format_all);//必须format_all
cout << "after replaced: " << newStr1 << endl;
//after replaced: gutdqhv##g+b+
string newStr2 = regex_replace(src,e1,replaceFmt,boost::match_default|boost::format_default);//奇怪的结果
cout << "after replaced: " << newStr2 << endl;
//其他的方式
ostream_iterator<char> oi(cout);
regex_replace(oi,src.begin(),src.end(),e1,replaceFmt,boost::match_default | boost::match_all);
cout << endl;
return 0;
}
pi@raspberrypi:~/boost $ g++ main.cpp -lboost_regex -Wall &&./a.out
before replaced: guTdQhV@@g*b*
after replaced: gutdqhv##g+b+
after replaced: gu(?1t)(?2+)(?3#)d(?1q)(?2+)(?3#)h(?1v)(?2+)(?3#)(?1@)(?2+)(?3#)(?1@)(?2+)(?3#)g(?1*)(?2+)(?3#)b(?1*)(?2+)(?3#)
guTdQhV@@g*b(?1*)(?2+)(?3#)
pi@raspberrypi:~/boost $boost 正则表达式 迭代器
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
using boost::regex;
regex e("(a+).+?",regex::icase);
string s("ann abb aaat");
boost::sregex_iterator it1(s.begin(),s.end(),e);
boost::sregex_iterator it2;
for(;it1 != it2;++it1)
{
boost::smatch m = *it1;
cout << m << endl;
}
return 0;
}
pi@raspberrypi:~/boost $ g++ main.cpp -lboost_regex -Wall &&./a.out
an
ab
aaat
pi@raspberrypi:~/boost $boost 正则表达式 -1,就是未被匹配的字符
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <iomanip>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char* argv[])
{
using boost::regex;
string s("this is ::a string ::of tokens");
boost::regex re("\\s+:*");//匹配
boost::sregex_token_iterator i(s.begin(),s.end(),re,-1);
boost::sregex_token_iterator j;
unsigned count = 0;
while(i != j)
{
cout << *i++ << endl;
count++;
}
cout << "There were "<< count << " tokens found !" << endl;
return 0;
}
pi@raspberrypi:~/boost $ g++ main.cpp -lboost_regex -Wall &&./a.out
this
is
a
string
of
tokens
There were 6 tokens found !
pi@raspberrypi:~/boost $boost 正则表达式 captures 官方代码为什么会出现段错误?
pi@raspberrypi:~/boost $ cat main.cpp
#include <boost/regex.hpp>
#include <iostream>
void print_captures(const std::string& regx, const std::string& text)
{
boost::regex e(regx);
boost::smatch what;
std::cout << "Expression: \"" << regx << "\"\n";
std::cout << "Text: \"" << text << "\"\n";
if(boost::regex_match(text, what, e, boost::match_extra))
{
unsigned i, j;
std::cout << "** Match found **\n Sub-Expressions:\n";
for(i = 0; i < what.size(); ++i)
std::cout << " $" << i << " = \"" << what[i] << "\"\n";
std::cout << " Captures:\n";
for(i = 0; i < what.size(); ++i)
{
std::cout << " $" << i << " = {";
for(j = 0; j < what.captures(i).size(); ++j)
{
if(j)
std::cout << ", ";
else
std::cout << " ";
std::cout << "\"" << what.captures(i)[j] << "\"";
}
std::cout << " }\n";
}
}
else
{
std::cout << "** No Match found **\n";
}
}
int main(int , char* [])
{
print_captures("(([[:lower:]]+)|([[:upper:]]+))+", "aBBcccDDDDDeeeeeeee");
print_captures("a(b+|((c)*))+d", "abd");
print_captures("(.*)bar|(.*)bah", "abcbar");
print_captures("(.*)bar|(.*)bah", "abcbah");
print_captures("^(?:(\\w+)|(?>\\W+))*$", "now is the time for all good men to come to the aid of the party");
print_captures("^(?>(\\w+)\\W*)*$", "now is the time for all good men to come to the aid of the party");
print_captures("^(\\w+)\\W+(?>(\\w+)\\W+)*(\\w+)$", "now is the time for all good men to come to the aid of the party");
print_captures("^(\\w+)\\W+(?>(\\w+)\\W+(?:(\\w+)\\W+){0,2})*(\\w+)$", "now is the time for all good men to come to the aid of the party");
return 0;
}
pi@raspberrypi:~/boost $ g++ -D BOOST_REGEX_MATCH_EXTRA -l boost_regex -Wall main.cpp &&./a.out
Expression: "(([[:lower:]]+)|([[:upper:]]+))+"
Text: "aBBcccDDDDDeeeeeeee"
** No Match found **
Bus error
pi@raspberrypi:~/boost $boost 正则表达式 官方例子
pi@raspberrypi:~/boost $ cat main.cpp
#include <cstdlib>
#include <stdlib.h>
#include <boost/regex.hpp>
#include <string>
#include <iostream>
using namespace std;
using namespace boost;
regex expression("^([0-9]+)(\\-| |$)(.*)$");//0-9,- $,*三种
int process_ftp(const char* response, std::string* msg)
{
cmatch what;
if(regex_match(response, what, expression))
{
// what[0] contains the whole string
// what[1] contains the response code
// what[2] contains the separator character
// what[3] contains the text message.
if(msg)
msg->assign(what[3].first, what[3].second);
return ::atoi(what[1].first);
}
// failure did not match
if(msg)
msg->erase();
return -1;
}
#if defined(BOOST_MSVC) || (defined(__BORLANDC__) && (__BORLANDC__ == 0x550))
istream& getline(istream& is, std::string& s)
{
s.erase();
char c = static_cast<char>(is.get());
while(c != '\n')
{
s.append(1, c);
c = static_cast<char>(is.get());
}
return is;
}
#endif
int main(int argc, const char*[])
{
std::string in, out;
do
{
if(argc == 1)
{
cout << "enter test string" << endl;
getline(cin, in);
if(in == "quit")
break;
}
else
in = "100 this is an ftp message text";
int result;
result = process_ftp(in.c_str(), &out);
if(result != -1)
{
cout << "Match found:" << endl;
cout << "Response code: " << result << endl;
cout << "Message text: " << out << endl;
}
else
{
cout << "Match not found" << endl;
}
cout << endl;
} while(argc == 1);
return 0;
}
pi@raspberrypi:~/boost $ g++ -l boost_regex -Wall main.cpp &&./a.out
enter test string
404 not found
Match found:
Response code: 404
Message text: not found
enter test string
500 service error
Match found:
Response code: 500
Message text: service error
enter test string
^C
pi@raspberrypi:~/boost $boost 正则表达式 search方式 简单的词法分析器,分析C++类定义
pi@raspberrypi:~/boost $ cat main.cpp
#include <string>
#include <map>
#include <boost/regex.hpp>
// purpose:
// takes the contents of a file in the form of a string
// and searches for all the C++ class definitions, storing
// their locations in a map of strings/int's
typedef std::map<std::string, std::string::difference_type, std::less<std::string> > map_type;
const char* re =
// possibly leading whitespace:
"^[[:space:]]*"
// possible template declaration:
"(template[[:space:]]*<[^;:{]+>[[:space:]]*)?"
// class or struct:
"(class|struct)[[:space:]]*"
// leading declspec macros etc:
"("
"\\<\\w+\\>"
"("
"[[:blank:]]*\\([^)]*\\)"
")?"
"[[:space:]]*"
")*"
// the class name
"(\\<\\w*\\>)[[:space:]]*"
// template specialisation parameters
"(<[^;:{]+>)?[[:space:]]*"
// terminate in { or :
"(\\{|:[^;\\{()]*\\{)";
boost::regex expression(re);
void IndexClasses(map_type& m, const std::string& file)
{
std::string::const_iterator start, end;
start = file.begin();
end = file.end();
boost::match_results<std::string::const_iterator> what;
boost::match_flag_type flags = boost::match_default;
while(boost::regex_search(start, end, what, expression, flags))
{
// what[0] contains the whole string
// what[5] contains the class name.
// what[6] contains the template specialisation if any.
// add class name and position to map:
m[std::string(what[5].first, what[5].second) + std::string(what[6].first, what[6].second)] =
what[5].first - file.begin();
// update search position:
start = what[0].second;
// update flags:
flags |= boost::match_prev_avail;
flags |= boost::match_not_bob;
}
}
#include <iostream>
#include <fstream>
using namespace std;
void load_file(std::string& s, std::istream& is)
{
s.erase();
if(is.bad()) return;
s.reserve(static_cast<std::string::size_type>(is.rdbuf()->in_avail()));
char c;
while(is.get(c))
{
if(s.capacity() == s.size())
s.reserve(s.capacity() * 3);
s.append(1, c);
}
}
int main(int argc, const char** argv)
{
std::string text;
for(int i = 1; i < argc; ++i)
{
cout << "Processing file " << argv[i] << endl;
map_type m;
std::ifstream fs(argv[i]);
load_file(text, fs);
fs.close();
IndexClasses(m, text);
cout << m.size() << " matches found" << endl;
map_type::iterator c, d;
c = m.begin();
d = m.end();
while(c != d)
{
cout << "class \"" << (*c).first << "\" found at index: " << (*c).second << endl;
++c;
}
}
return 0;
}
pi@raspberrypi:~/boost $ cat my_class.cpp
template <class T>
struct A
{
public:
};
template <class T>
class M
{
}
;
pi@raspberrypi:~/boost $ g++ -l boost_regex -Wall main.cpp &&./a.out my_class.cpp
Processing file my_class.cpp
2 matches found
class "A" found at index: 36
class "M" found at index: 88
pi@raspberrypi:~/boost $boost 正则表达式 迭代器方式 简单的词法分析器,分析C++类定义
pi@raspberrypi:~/boost $ cat main.cpp
#include <string>
#include <map>
#include <fstream>
#include <iostream>
#include <boost/regex.hpp>
using namespace std;
// purpose:
// takes the contents of a file in the form of a string
// and searches for all the C++ class definitions, storing
// their locations in a map of strings/int's
typedef std::map<std::string, std::string::difference_type, std::less<std::string> > map_type;
const char* re =
// possibly leading whitespace:
"^[[:space:]]*"
// possible template declaration:
"(template[[:space:]]*<[^;:{]+>[[:space:]]*)?"
// class or struct:
"(class|struct)[[:space:]]*"
// leading declspec macros etc:
"("
"\\<\\w+\\>"
"("
"[[:blank:]]*\\([^)]*\\)"
")?"
"[[:space:]]*"
")*"
// the class name
"(\\<\\w*\\>)[[:space:]]*"
// template specialisation parameters
"(<[^;:{]+>)?[[:space:]]*"
// terminate in { or :
"(\\{|:[^;\\{()]*\\{)";
boost::regex expression(re);
map_type class_index;
bool regex_callback(const boost::match_results<std::string::const_iterator>& what)
{
// what[0] contains the whole string
// what[5] contains the class name.
// what[6] contains the template specialisation if any.
// add class name and position to map:
class_index[what[5].str() + what[6].str()] = what.position(5);
return true;
}
void load_file(std::string& s, std::istream& is)
{
s.erase();
if(is.bad()) return;
s.reserve(static_cast<std::string::size_type>(is.rdbuf()->in_avail()));
char c;
while(is.get(c))
{
if(s.capacity() == s.size())
s.reserve(s.capacity() * 3);
s.append(1, c);
}
}
int main(int argc, const char** argv)
{
std::string text;
for(int i = 1; i < argc; ++i)
{
cout << "Processing file " << argv[i] << endl;
std::ifstream fs(argv[i]);
load_file(text, fs);
fs.close();
// construct our iterators:
boost::sregex_iterator m1(text.begin(), text.end(), expression);
boost::sregex_iterator m2;
std::for_each(m1, m2, ®ex_callback);
// copy results:
cout << class_index.size() << " matches found" << endl;
map_type::iterator c, d;
c = class_index.begin();
d = class_index.end();
while(c != d)
{
cout << "class \"" << (*c).first << "\" found at index: " << (*c).second << endl;
++c;
}
class_index.erase(class_index.begin(), class_index.end());
}
return 0;
}
pi@raspberrypi:~/boost $ g++ -l boost_regex -Wall main.cpp &&./a.out main.cpp my_class.cpp
Processing file main.cpp
0 matches found
Processing file my_class.cpp
2 matches found
class "A" found at index: 23
class "B" found at index: 36
pi@raspberrypi:~/boost $boost 正则表达式,将C++文件转换为HTML文件
pi@raspberrypi:~/boost $ cat main.cpp
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <iterator>
#include <boost/regex.hpp>
#include <fstream>
#include <iostream>
// purpose:
// takes the contents of a file and transform to
// syntax highlighted code in html format
boost::regex e1, e2;
extern const char* expression_text;
extern const char* format_string;
extern const char* pre_expression;
extern const char* pre_format;
extern const char* header_text;
extern const char* footer_text;
void load_file(std::string& s, std::istream& is)
{
s.erase();
if(is.bad()) return;
s.reserve(static_cast<std::string::size_type>(is.rdbuf()->in_avail()));
char c;
while(is.get(c))
{
if(s.capacity() == s.size())
s.reserve(s.capacity() * 3);
s.append(1, c);
}
}
int main(int argc, const char** argv)
{
try{
e1.assign(expression_text);
e2.assign(pre_expression);
for(int i = 1; i < argc; ++i)
{
std::cout << "Processing file " << argv[i] << std::endl;
std::ifstream fs(argv[i]);
std::string in;
load_file(in, fs);
fs.close();
std::string out_name = std::string(argv[i]) + std::string(".htm");
std::ofstream os(out_name.c_str());
os << header_text;
// strip '<' and '>' first by outputting to a
// temporary string stream
std::ostringstream t(std::ios::out | std::ios::binary);
std::ostream_iterator<char> oi(t);
boost::regex_replace(oi, in.begin(), in.end(), e2, pre_format, boost::match_default | boost::format_all);
// then output to final output stream
// adding syntax highlighting:
std::string s(t.str());
std::ostream_iterator<char> out(os);
boost::regex_replace(out, s.begin(), s.end(), e1, format_string, boost::match_default | boost::format_all);
os << footer_text;
os.close();
}
}
catch(...)
{ return -1; }
return 0;
}
const char* pre_expression = "(<)|(>)|(&)|\\r";
const char* pre_format = "(?1<)(?2>)(?3&)";
const char* expression_text = // preprocessor directives: index 1
"(^[[:blank:]]*#(?:[^\\\\\\n]|\\\\[^\\n[:punct:][:word:]]*[\\n[:punct:][:word:]])*)|"
// comment: index 2
"(//[^\\n]*|/\\*.*?\\*/)|"
// literals: index 3
"\\<([+-]?(?:(?:0x[[:xdigit:]]+)|(?:(?:[[:digit:]]*\\.)?[[:digit:]]+(?:[eE][+-]?[[:digit:]]+)?))u?(?:(?:int(?:8|16|32|64))|L)?)\\>|"
// string literals: index 4
"('(?:[^\\\\']|\\\\.)*'|\"(?:[^\\\\\"]|\\\\.)*\")|"
// keywords: index 5
"\\<(__asm|__cdecl|__declspec|__export|__far16|__fastcall|__fortran|__import"
"|__pascal|__rtti|__stdcall|_asm|_cdecl|__except|_export|_far16|_fastcall"
"|__finally|_fortran|_import|_pascal|_stdcall|__thread|__try|asm|auto|bool"
"|break|case|catch|cdecl|char|class|const|const_cast|continue|default|delete"
"|do|double|dynamic_cast|else|enum|explicit|extern|false|float|for|friend|goto"
"|if|inline|int|long|mutable|namespace|new|operator|pascal|private|protected"
"|public|register|reinterpret_cast|return|short|signed|sizeof|static|static_cast"
"|struct|switch|template|this|throw|true|try|typedef|typeid|typename|union|unsigned"
"|using|virtual|void|volatile|wchar_t|while)\\>"
;
const char* format_string = "(?1<font color=\"#008040\">$&</font>)"
"(?2<I><font color=\"#000080\">$&</font></I>)"
"(?3<font color=\"#0000A0\">$&</font>)"
"(?4<font color=\"#0000FF\">$&</font>)"
"(?5<B>$&</B>)";
const char* header_text = "<HTML>\n<HEAD>\n"
"<TITLE>Auto-generated html formated source</TITLE>\n"
"<META HTTP-EQUIV=\"Content-Type\" CONTENT=\"text/html; charset=windows-1252\">\n"
"</HEAD>\n"
"<BODY LINK=\"#0000ff\" VLINK=\"#800080\" BGCOLOR=\"#ffffff\">\n"
"<P> </P>\n<PRE>";
const char* footer_text = "</PRE>\n</BODY>\n\n";
pi@raspberrypi:~/boost $ g++ -l boost_regex -Wall main.cpp &&./a.out main.cpp
Processing file main.cpp看效果图:

boost 正则表达式 ,抓取网页中的所有连接:
pi@raspberrypi:~/boost $ cat main.cpp
#include <fstream>
#include <iostream>
#include <iterator>
#include <boost/regex.hpp>
boost::regex e("<\\s*A\\s+[^>]*href\\s*=\\s*\"([^\"]*)\"",
boost::regex::normal | boost::regbase::icase);
void load_file(std::string& s, std::istream& is)
{
s.erase();
if(is.bad()) return;
//
// attempt to grow string buffer to match file size,
// this doesn't always work...
s.reserve(static_cast<std::string::size_type>(is.rdbuf()->in_avail()));
char c;
while(is.get(c))
{
// use logarithmic growth stategy, in case
// in_avail (above) returned zero:
if(s.capacity() == s.size())
s.reserve(s.capacity() * 3);
s.append(1, c);
}
}
int main(int argc, char** argv)
{
std::string s;
int i;
for(i = 1; i < argc; ++i)
{
std::cout << "Findings URL's in " << argv[i] << ":" << std::endl;
s.erase();
std::ifstream is(argv[i]);
load_file(s, is);
is.close();
boost::sregex_token_iterator i(s.begin(), s.end(), e, 1);
boost::sregex_token_iterator j;
while(i != j)
{
std::cout << *i++ << std::endl;
}
}
//
// alternative method:
// test the array-literal constructor, and split out the whole
// match as well as $1....
//
for(i = 1; i < argc; ++i)
{
std::cout << "Findings URL's in " << argv[i] << ":" << std::endl;
s.erase();
std::ifstream is(argv[i]);
load_file(s, is);
is.close();
const int subs[] = {1, 0,};
boost::sregex_token_iterator i(s.begin(), s.end(), e, subs);
boost::sregex_token_iterator j;
while(i != j)
{
std::cout << *i++ << std::endl;
}
}
return 0;
}
pi@raspberrypi:~/boost $ curl http://www.boost.org/ > boost.html
pi@raspberrypi:~/boost $ g++ -l boost_regex -Wall main.cpp &&./a.out boost.html
Findings URL's in boost.html:
/
http://www.gotw.ca/
http://en.wikipedia.org/wiki/Andrei_Alexandrescu
http://safari.awprofessional.com/?XmlId=0321113586
/users/license.html
http://www.open-std.org/jtc1/sc22/wg21/
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2005/n1745.pdf
http://cppnow.org/
https://developers.google.com/open-source/soc/?csw=1
/doc/libs/release/more/getting_started/index.html
http://fedoraproject.org/
http://www.debian.org/
http://www.netbsd.org/免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





