这篇文章主要介绍“go pprof如何使用”,在日常操作中,相信很多人在go pprof如何使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”go pprof如何使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
pprof是Go的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是CPU使用情况、内存使用情况、goroutine运行情况等,当需要性能调优或者定位Bug时候,这些记录的信息是相当重要。使用pprof有多种方式,Go已经现成封装好了1个“net/http/pprof”,使用简单的几行命令,就可以开启pprof,记录运行信息,并且提供了Web服务。
profile 一般被称为 性能分析,词典上的翻译是 概况(名词)或者 描述…的概况(动词)。对于计算机程序来说,它的 profile,就是一个程序在运行时的各种概况信息,包括 cpu 占用情况,内存情况,线程情况,线程阻塞情况等等。知道了程序的这些信息,也就能容易的定位程序中的问题和故障原因 。
pprof是Go的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是CPU使用情况、内存使用情况、goroutine运行情况等,当需要性能调优或者定位Bug时候,这些记录的信息是相当重要。
golang 对于 profiling 支持的比较好,标准库就提供了profile库 “runtime/pprof” 和 “net/http/pprof”,而且也提供了很多好用的可视化工具来辅助开发者做 profiling。
对于在线服务,对于一个 HTTP Server,访问 pprof 提供的 HTTP 接口,获得性能数据。当然,实际上这里底层也是调用的 runtime/pprof 提供的函数,封装成接口对外提供网络访问,本文主要介绍"net/http/pprof"的使用。
使用pprof有多种方式,Go已经现成封装好了1个:net/http/pprof,使用简单的几行命令,就可以开启pprof,记录运行信息,并且提供了Web服务,能够通过浏览器和命令行2种方式获取运行数据。
web服务中如何开启监控,来看一个简单的例子。
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
)
func main() {
// 开启pprof,监听请求
ip := "0.0.0.0:8080"
if err := http.ListenAndServe(ip, nil); err != nil {
fmt.Printf("start pprof failed on %s\n", ip)
}
dosomething()
}
在程序中导入 "net/http/pprof"包,并打开监听端口,这时候便可以获取程序的profile,在实际生产中,我们一般将这个功能封装成一个goroutine。那么开启之后如何查看呢?有三种方式:
打开一个浏览器输入 ip:port/debug/pprof,回车。

pprof会提供很多性能数据。具体含义为:
allocs:内存分配情况的采样信息
blocks:阻塞操作情况的采样信息 cmdline:程序启动命令及其参数
goroutine:当前所有协程的堆栈信息
heap:堆上内存的使用情况的采样信息 mutex:锁争用情况的采样信息
profile:cpu占用情况的采样信息
threadcreate:系统线程创建情况的采样信息
trace:程序运行的跟踪信息
allocs是所有对象的内存分配,heap是活跃对象的内存分配,后文会有详细的描述。
1、当 CPU 性能分析启用后,Go runtime 会每 10ms 就暂停一下,记录当前运行的 goroutine 的调用堆栈及相关数据。当性能分析数据保存到硬盘后,我们就可以分析代码中的热点了。
2、内存性能分析则是在堆(Heap)分配的时候,记录一下调用堆栈。默认情况下,是每 1000 次分配,取样一次,这个数值可以改变。栈(Stack)分配 由于会随时释放,因此不会被内存分析所记录。由于内存分析是取样方式,并且也因为其记录的是分配内存,而不是使用内存。因此使用内存性能分析工具来准确判断程序具体的内存使用是比较困难的。
3、阻塞分析是一个很独特的分析,它有点儿类似于 CPU 性能分析,但是它所记录的是 goroutine 等待资源所花的时间。阻塞分析对分析程序并发瓶颈非常有帮助,阻塞性能分析可以显示出什么时候出现了大批的 goroutine 被阻塞了。阻塞性能分析是特殊的分析工具,在排除 CPU 和内存瓶颈前,不应该用它来分析。
当然,如果你点进任何一个链接,便会发现,可读性差,几乎无法分析。如图:

点击heap,拉到最底部,可以看到一些有意思的数据,有时候也有可能会对问题排查有帮助,但一般不用。
heap profile: 3190: 77516056 [54762: 612664248] @ heap/1048576
1: 29081600 [1: 29081600] @ 0x89368e 0x894cd9 0x8a5a9d 0x8a9b7c 0x8af578 0x8b4441 0x8b4c6d 0x8b8504 0x8b2bc3 0x45b1c1
# 0x89368d github.com/syndtr/goleveldb/leveldb/memdb.(*DB).Put+0x59d
# 0x894cd8 xxxxx/storage/internal/memtable.(*MemTable).Set+0x88
# 0x8a5a9c xxxxx/storage.(*snapshotter).AppendCommitLog+0x1cc
# 0x8a9b7b xxxxx/storage.(*store).Update+0x26b
# 0x8af577 xxxxx/config.(*config).Update+0xa7
# 0x8b4440 xxxxx/naming.(*naming).update+0x120
# 0x8b4c6c xxxxx/naming.(*naming).instanceTimeout+0x27c
# 0x8b8503 xxxxx/naming.(*naming).(xxxxx/naming.instanceTimeout)-fm+0x63
......
# runtime.MemStats
# Alloc = 2463648064
# TotalAlloc = 31707239480
# Sys = 4831318840
# Lookups = 2690464
# Mallocs = 274619648
# Frees = 262711312
# HeapAlloc = 2463648064
# HeapSys = 3877830656
# HeapIdle = 854990848
# HeapInuse = 3022839808
# HeapReleased = 0
# HeapObjects = 11908336
# Stack = 655949824 / 655949824
# MSpan = 63329432 / 72040448
# MCache = 38400 / 49152
# BuckHashSys = 1706593
# GCSys = 170819584
# OtherSys = 52922583
# NextGC = 3570699312
# PauseNs = [1052815 217503 208124 233034 ......]
# NumGC = 31
# DebugGC = false
Sys: 进程从系统获得的内存空间,虚拟地址空间
HeapAlloc:进程堆内存分配使用的空间,通常是用户new出来的堆对象,包含未被gc掉的。
HeapSys:进程从系统获得的堆内存,因为golang底层使用TCmalloc机制,会缓存一部分堆内存,虚拟地址空间
PauseNs:记录每次gc暂停的时间(纳秒),最多记录256个最新记录。
NumGC: 记录gc发生的次数
除了浏览器,Go还提供了命令行的方式,能够获取以上信息,这种方式用起来更方便。
使用命令go tool pprof url可以获取指定的profile文件,此命令会发起http请求,然后下载数据到本地,之后进入交互式模式,就像gdb一样,可以使用命令查看运行信息,以下为使用示例:
# 下载cpu profile,默认从当前开始收集30s的cpu使用情况,需要等待30s
go tool pprof http://localhost:8080/debug/pprof/profile # 30-second CPU profile
go tool pprof http://localhost:8080/debug/pprof/profile?seconds=120 # wait 120s
# 下载heap profile
go tool pprof http://localhost:8080/debug/pprof/heap # heap profile
# 下载goroutine profile
go tool pprof http://localhost:8080/debug/pprof/goroutine # goroutine profile
# 下载block profile
go tool pprof http://localhost:8080/debug/pprof/block # goroutine blocking profile
# 下载mutex profile
go tool pprof http://localhost:8080/debug/pprof/mutex
接下来用一个例子来说明最常用的四个命令:web、top、list、traces。
接下来以内存分析举例,cpu和goroutine等分析同理,读者可以自行举一反三。
首先,我们通过命令go tool pprof url获取指定的profile/heap文件,随后自动进入命令行。如图:
第一步,我们首先输入web命令,这时浏览器会弹出各个函数之间的调用图,以及内存的之间的关系。如图:
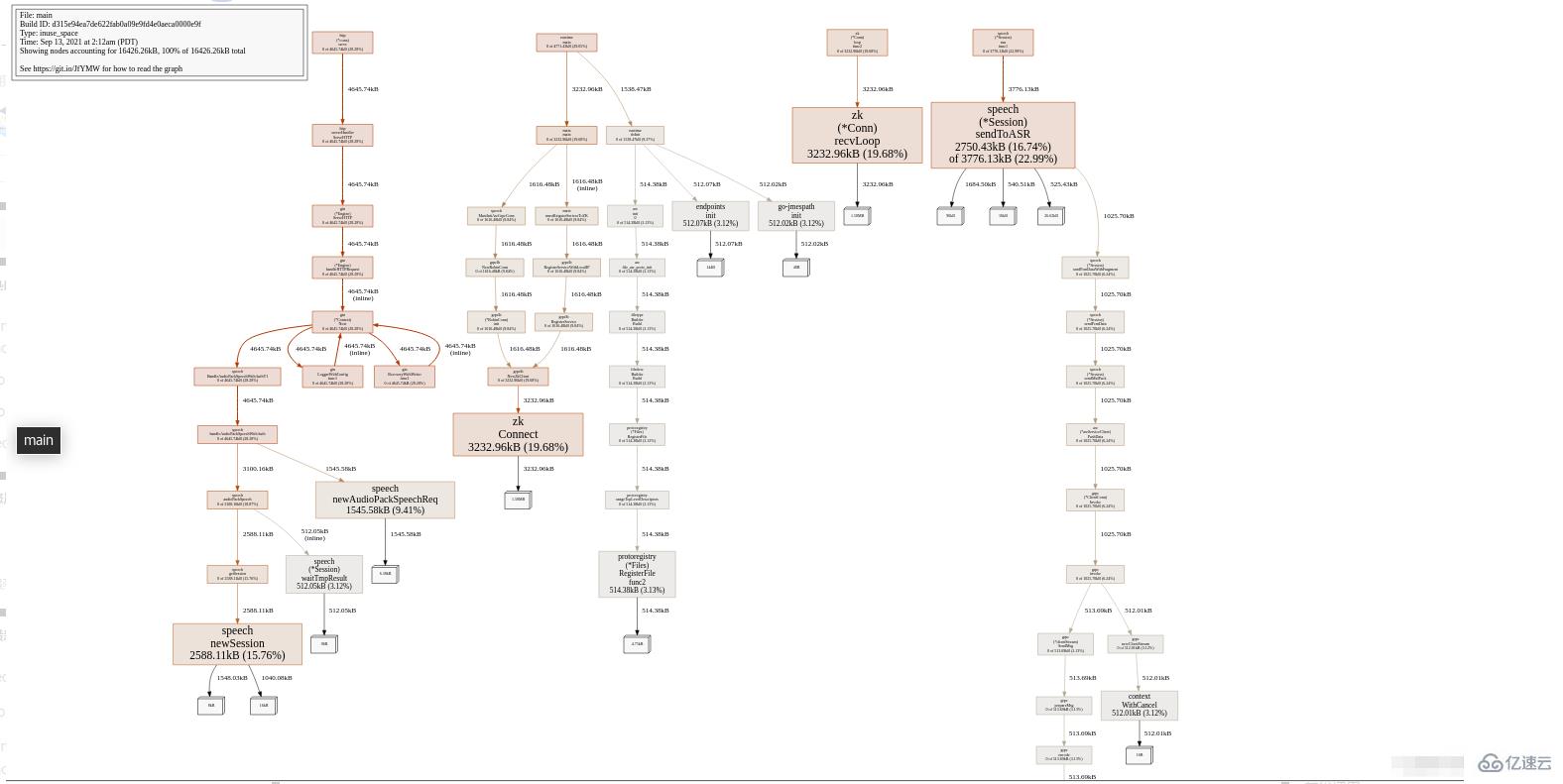
这个图的具体读法,可参照:中文文档 或者英文文档 这里不多赘述。只需要了解越红越大的方块,有问题的可能性就越大,代表可能占用了更多的内存,如果在cpu的图中代表消耗了更多cpu资源,以此类推。
接下来 top、list、traces三步走可以看出很多想要的结果。
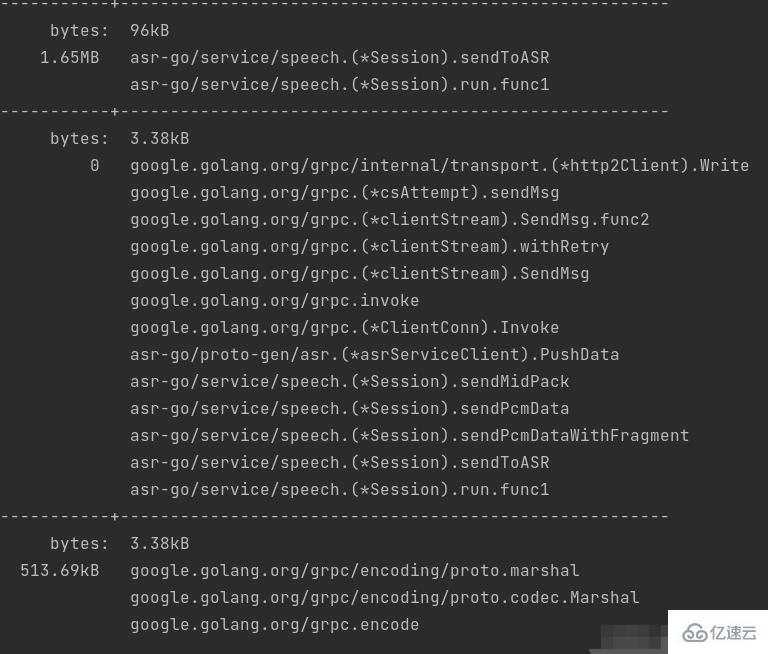
top 按指标大小列出前10个函数,比如内存是按内存占用多少,CPU是按执行时间多少。
top会列出5个统计数据:
flat: 本函数占用的内存量。
flat%: 本函数内存占使用中内存总量的百分比。
sum%: 之前函数flat的累计和。
cum:是累计量,假如main函数调用了函数f,函数f占用的内存量,也会记进来。
cum%: 是累计量占总量的百分比。
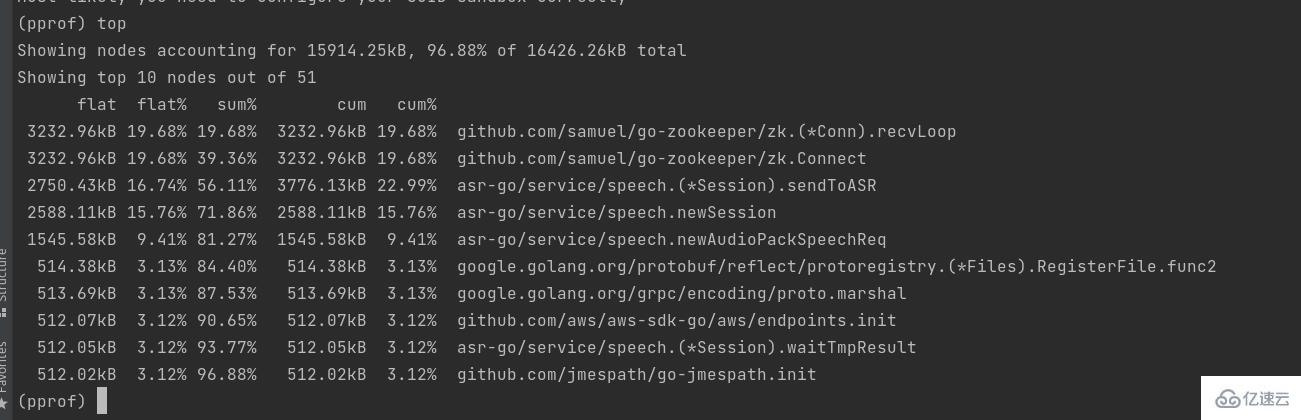
这样我们可以看到到底是具体哪些函数占用了多少内存。
当然top后也可以接参数,top n可以列出前n个函数。
list可以查看某个函数的代码,以及该函数每行代码的指标信息,如果函数名不明确,会进行模糊匹配,比如list main会列出main.main和runtime.main。现在list sendToASR试一下。
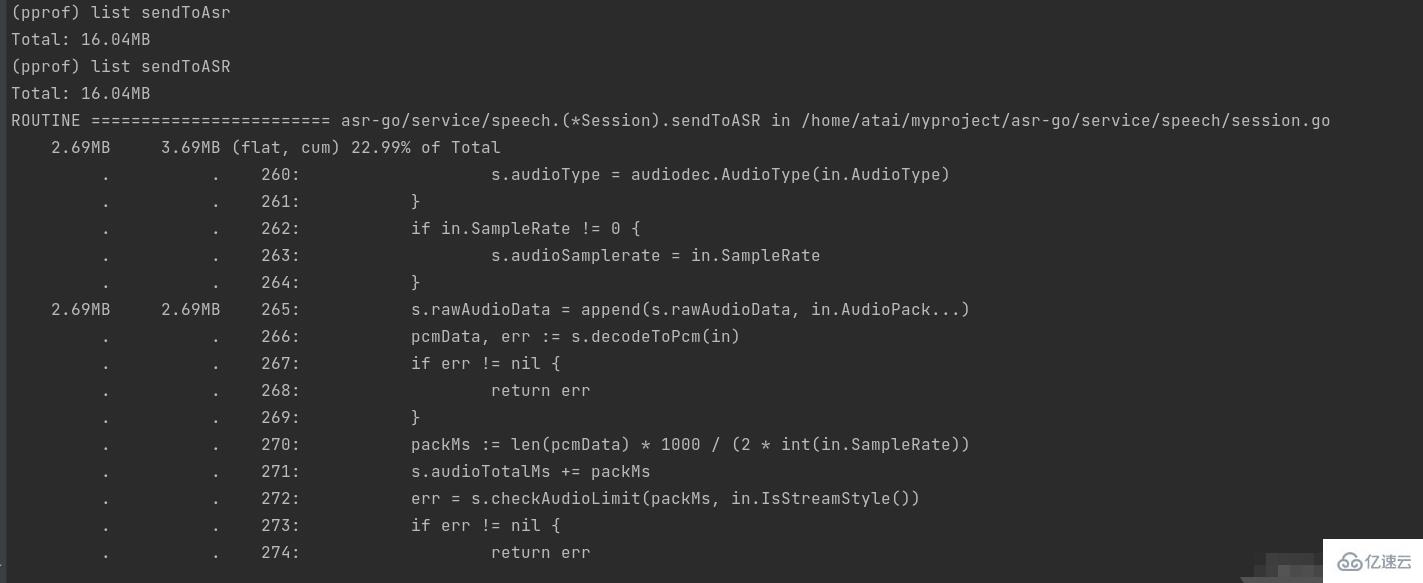
可以看到切片中增加元素时,占用了很多内存,左右2个数据分别是flat和cum。
traces 打印所有调用栈,以及调用栈的指标信息。使用方式为traces+函数名(模糊匹配)。
在命令行之中,还有一个重要的参数 -base,假设我们已经通过命令行得到profile1与profile2,使用go tool pprof -base profile1 profile2,便可以以profile1为基础,得出profile2在profile1之上出现了哪些变化。通过两个时间切片的比较,我们可以清晰的了解到,两个时间节点之中发生的变化,方便我们定位问题(很重要!!!!)
打开可视化界面的方式为:go tool pprof -http=:1234 http://localhost:8080/debug/pprof/heap 其中1234是我们指定的端口
Top
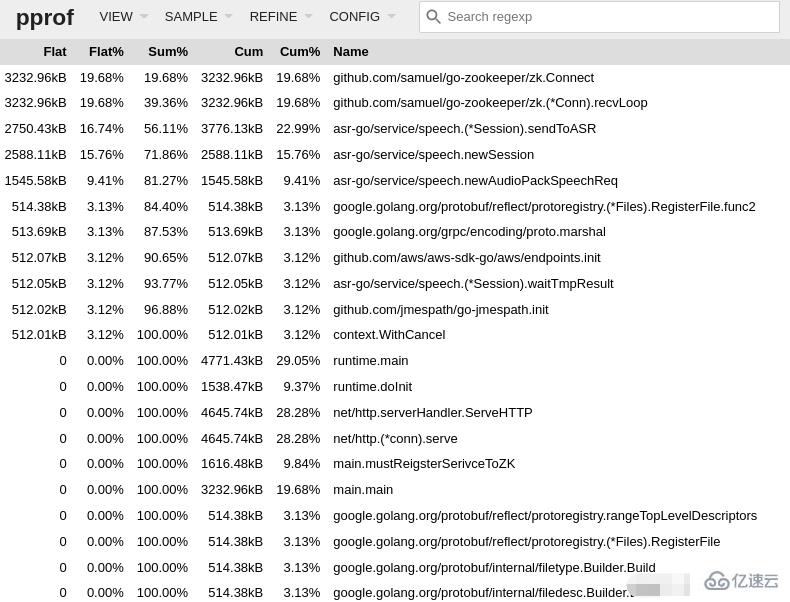
该视图与前面所讲解的 top 子命令的作用和含义是一样的,因此不再赘述。
Graph
为函数调用图,不在赘述.
Peek
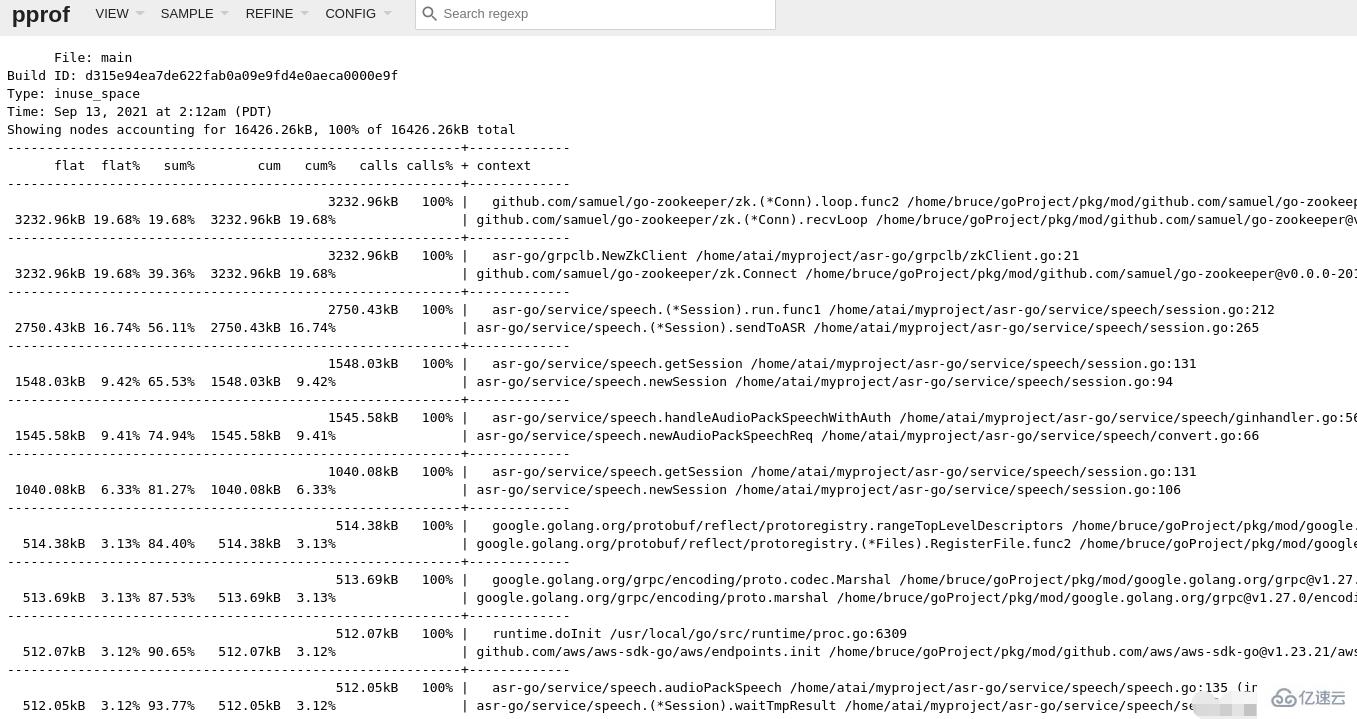
此视图相较于 Top 视图,增加了所属的上下文信息的展示,也就是函数的输出调用者/被调用者。
Source
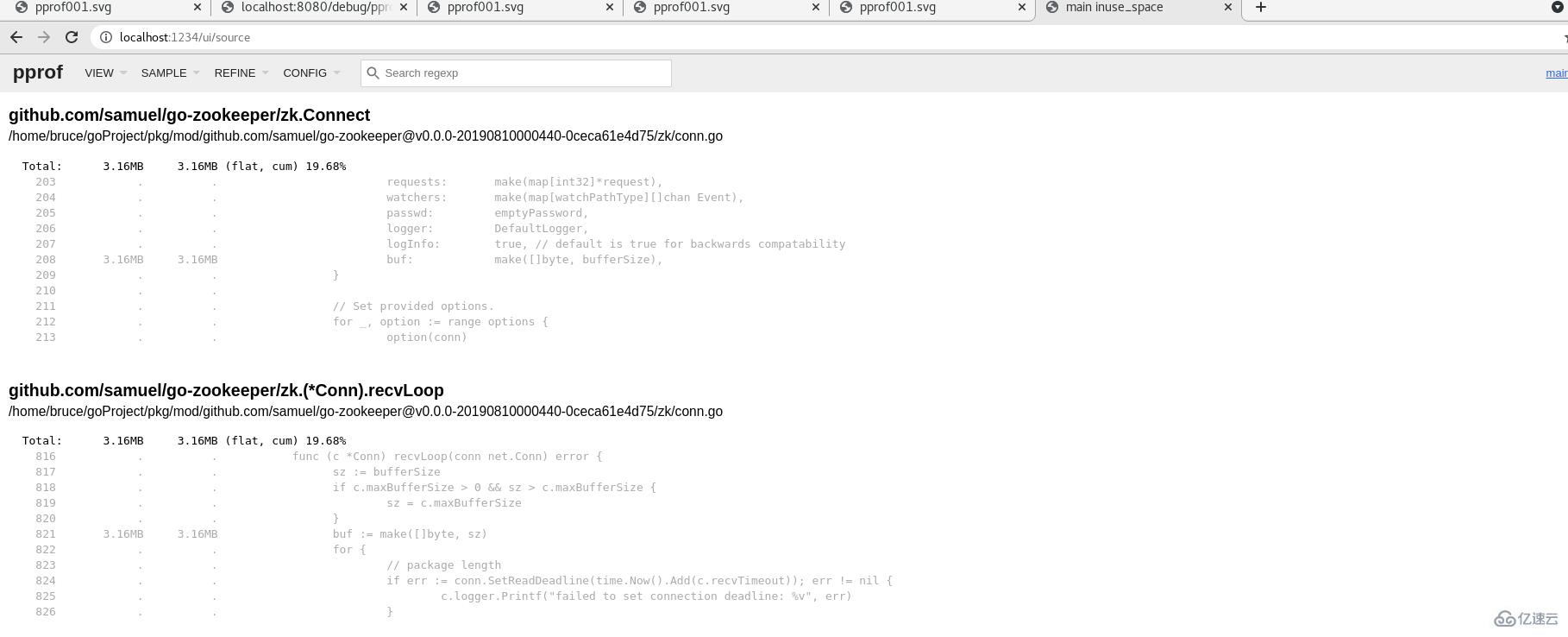
该视图主要是增加了面向源代码的追踪和分析,可以看到其开销主要消耗在哪里。
Flame Graph

对应资源消耗的火焰图,火焰图的读法,这里不赘述,不是本文的重点。
第二个下拉菜单如图所示:

alloc_objects,alloc_space表示应用程序分配过的资源,不管有没有释放,inuse_objects,inuse_space表示应用程序的还未释放的资源常配情况。
| Name | Meaning |
|---|---|
| inuse_space | amount of memory allocated and not released yet |
| inuse_objects | amount of objects allocated and not released yet |
| alloc_space | total amount of memory allocated (regardless of released) |
| alloc_objects | total amount of objects allocated (regardless of released) |
第一个下拉菜单可以与第二个下拉菜单相组合,可以查看临时变量的火焰图,常驻变量的内存调用图等。
tips:
程序运行占用较大的内存,可以通过 inuse_space 来体现.
存在非常频繁的 GC 活动,通常意味着 alloc_space非常高,而程序运行过程中并没有消耗太多的内存(体现为 inuse_space 并不高),当然也可能出现 GC 来不及回收,因此c出现inuse_space 也变高的情况。这种情况下同样会大量消耗CPU。
内存泄漏,通常 alloc_space 较高,且
inuse_space 也较高。
上面我们已经看完了go pprof 的所有操作,接下来讲解一下go tool pprof 的具体使用流程。
通过监控平台监测到内存或cpu问题。
通过浏览器方式大致判断是哪些可能的问题。
通过命令行方式抓取几个时间点的profile
使用web命令查看函数调用图
使用top 、traces、list 命令定位问题
如果出现了goroutine泄漏或者内存泄漏等随着时间持续增长的问题,go tool pprof -base比较两个不同时间点的状态更方便我们定位问题。
启动程序后,用浏览器方式打开profile:
发现内存持续上升,同时goroutine也在持续上升,初步判断,内存泄漏是由于goroutine泄漏导致的。
接下来通过命令行方式抓取goroutine的情况:命令行输入:go tool pprof localhost:8080/debug/pprof/goroutine,获取结果。
一、使用web命令查看调用图,大概了解目前的goroutine的泄露情况:
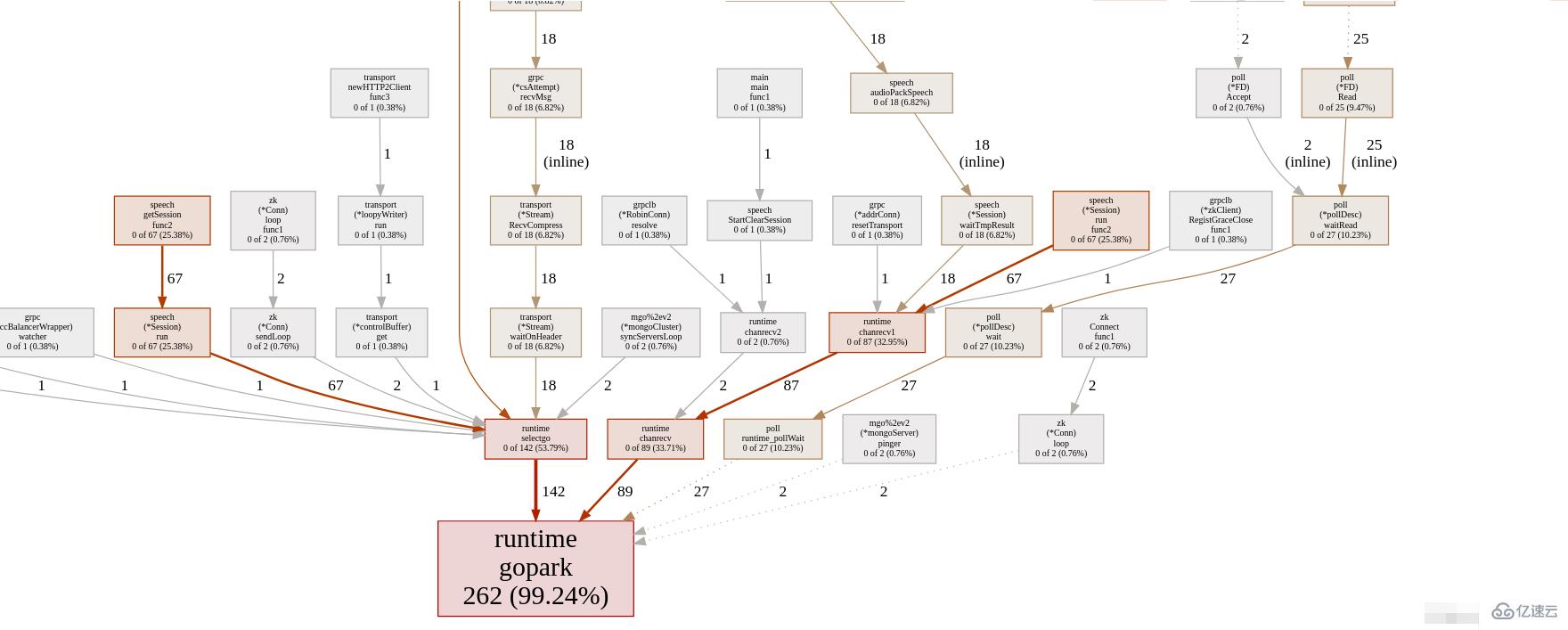
通过观察,最引入注目的便是runtime.gopark这个函数,这个函数在所有goroutine泄漏时都会出现,并且是大头,接下来我们研究一下这个函数的作用:
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
mcall(park_m)
}
该函数的作用为:
1、调用acquirem函数:获取当前goroutine所绑定的m,设置各类所需参数。调用 releasem 函数将当前 goroutine 和其 m 的绑定关系解除。
2、调用 park_m 函数:将当前 goroutine 的状态从 _Grunning 切换为 _Gwaiting,也就是等待状态。删除 m 和当前 goroutine m→curg(简称gp)之间的关联。
3、调用 mcall 函数,仅会在需要进行 goroutiine 切换时会被调用:切换当前线程的堆栈,从 g 的堆栈切换到 g0 的堆栈并调用 fn(g) 函数。将 g 的当前 PC/SP 保存在 g->sched 中,以便后续调用 goready 函数时可以恢复运行现场。
综上:该函数的关键作用就是将当前的 goroutine 放入等待状态,这意味着 goroutine 被暂时被搁置了,也就是被运行时调度器暂停了。
所以出现goroutine泄漏一定会调用这个函数,这个函数不是goroutine泄漏的原因,而是goroutine泄漏的结果。
此外,我们发现有两个函数的goroutine的达到了67,很可疑,在我们接下来的验证中要格外留意。
二、使用top命令,获取更加具体的函数信息:
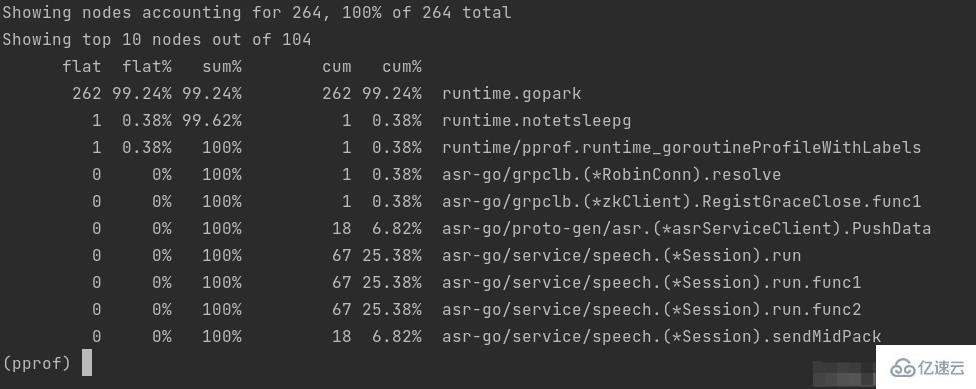
与上面分析的结论相似,我们要将关注点放在三个开启了67个goroutine的函数。
三、traces+函数名,查看调用栈,这一步在函数调用很复杂,无法从调用图里面清晰的看出时使用,帮助我们更清晰的了解函数的调用堆栈:
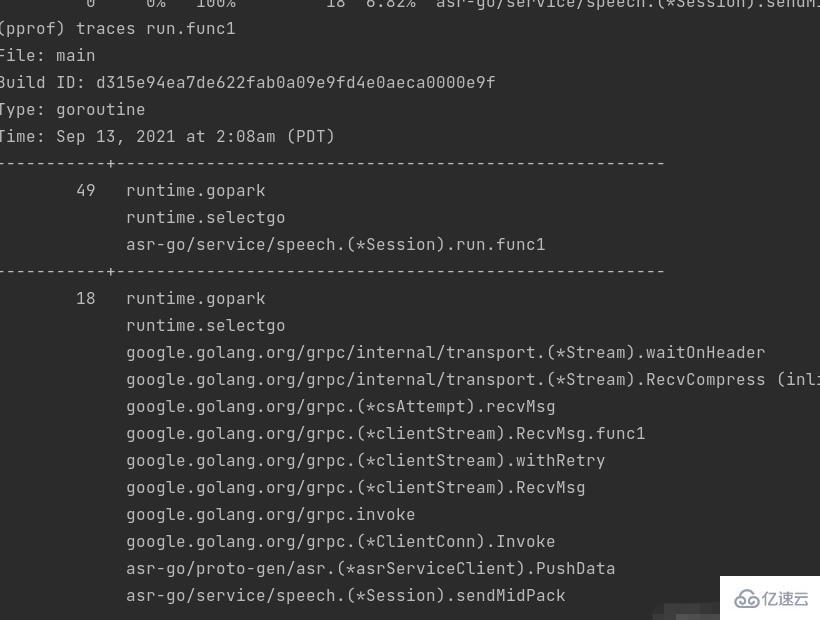
四、使用list+函数名,查看具体代码的问题。
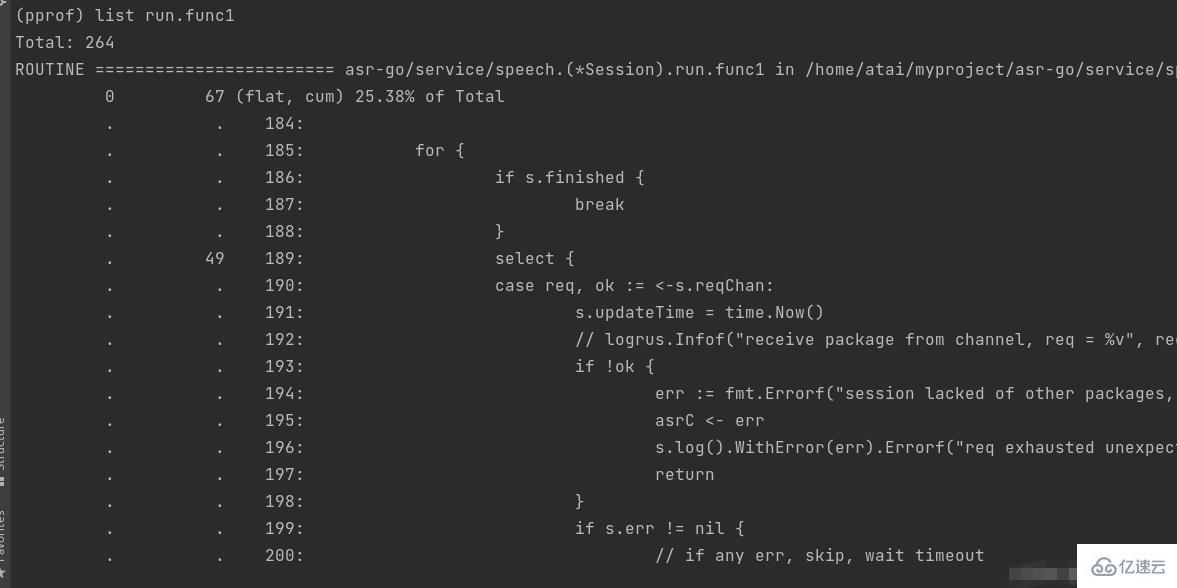
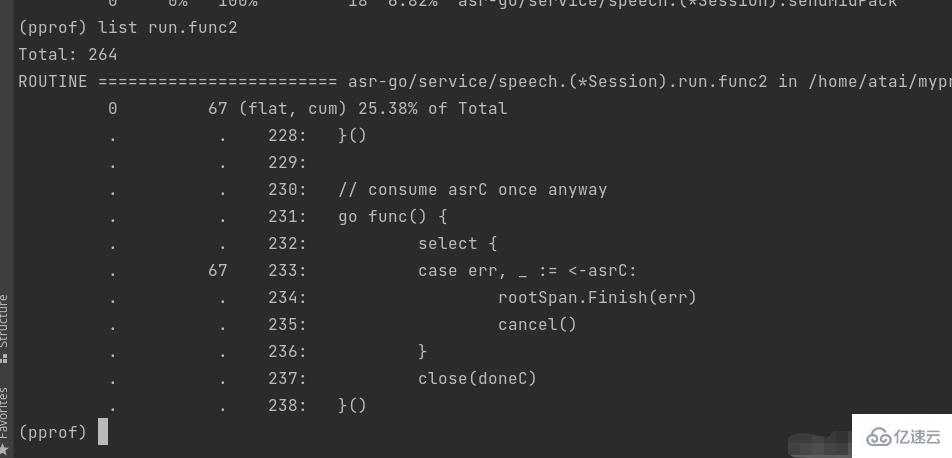
通过list命令我们可以清楚的看出问题代码是堵塞在哪里。
什么是goroutine泄漏:如果你启动了一个 goroutine,但并没有符合预期的退出,直到程序结束,此goroutine才退出,这种情况就是 goroutine 泄露。当 goroutine 泄露发生时,该 goroutine 的栈(一般 2k 内存空间起)一直被占用不能释放,goroutine 里的函数在堆上申请的空间也不能被 垃圾回收器 回收。这样,在程序运行期间,内存占用持续升高,可用内存越来也少,最终将导致系统崩溃。
什么时候出现goroutine泄漏:goroutine泄露一般是因为channel操作阻塞而导致整个routine一直阻塞等待或者 goroutine 里有死循环。
具体细分一下:
从 channel 里读,但是没有写。
向 unbuffered channel 写,但是没有读。
向已满的 buffered channel 写,但是没有读。
select操作在所有case上阻塞。
goroutine进入死循环中,导致资源一直无法释放。
select底层也是channel实现的,如果所有case上的操作阻塞,select内部的channel便会阻塞,goroutine也无法继续执行。所以我们使用channel时一定要格外小心。
通过分析上面两幅图的情况,可以判断是因为select在所有case上死锁了,再深入代码分析,是因为项目中的的语音模型并发能力弱,在语音发包速度快起来的时候无法处理,导致select不满足条件,导致goroutine泄漏,应该在for循环之外加一个asr←nil,保证func2的select一定会满足,同时提高模型的并发能力,使得func1的不会阻塞。
防止goroutine泄漏的建议:
创建goroutine时就要想好该goroutine该如何结束。
使用channel时,要考虑到 channel阻塞时协程可能的行为,是否会创建大量的goroutine。
goroutine中不可以存在死循环。
我们通过grafana发现内存出现泄漏:
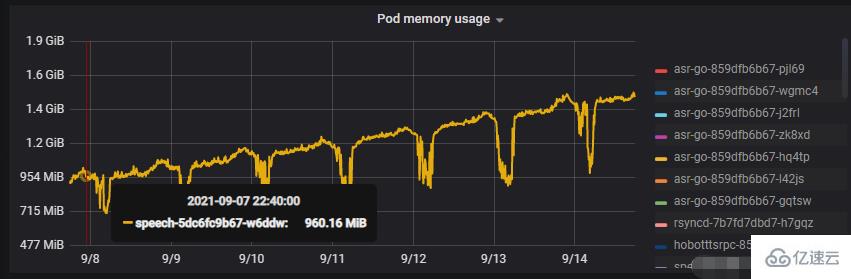
这一次我们不使用命令行,而是使用图形化界面来定位问题。
输入 go tool pprof -http=:1234 localhost:8080/debug/pprof/heap:
 发现内存占用很有可能是
发现内存占用很有可能是byte.makeSlice()导致的,火焰图看的更加清晰:

而调用byte.makeSlice()的函数为标准库中的ioutil.ReadAll(),接下来我们只需要研究这个标准库函数的实现即可。
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
buf := bytes.NewBuffer(make([]byte, 0, capacity))
defer func() {
e := recover()
if e == nil {
return
}
if panicErr, ok := e.(error); ok && panicErr == bytes.ErrTooLarge {
err = panicErr
} else {
panic(e)
}
}()
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
// bytes.MinRead = 512
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
可以看到 ioutil.ReadAll 每次都会分配初始化一个大小为 bytes.MinRead 的 buffer ,bytes.MinRead 在 Golang 里是一个常量,值为 512 。就是说每次调用 ioutil.ReadAll 都先会分配一块大小为 512 字节的内存。
接下来看一下ReadFrom函数的实现:
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
// If buffer is empty, reset to recover space.
if b.off >= len(b.buf) {
b.Truncate(0)
}
for {
if free := cap(b.buf) - len(b.buf); free < MinRead {
// not enough space at end
newBuf := b.buf
if b.off+free < MinRead {
// not enough space using beginning of buffer;
// double buffer capacity
newBuf = makeSlice(2*cap(b.buf) + MinRead)
}
copy(newBuf, b.buf[b.off:])
b.buf = newBuf[:len(b.buf)-b.off]
b.off = 0
}
m, e := r.Read(b.buf[len(b.buf):cap(b.buf)])
b.buf = b.buf[0 : len(b.buf)+m]
n += int64(m)
if e == io.EOF {
break
}
if e != nil {
return n, e
}
}
return n, nil // err is EOF, so return nil explicitly
}
ReadFrom函数主要作用就是从 io.Reader 里读取的数据放入 buffer 中,如果 buffer 空间不够,就按照每次 2x + MinRead 的算法递增,这里 MinRead 的大小也是 512 Bytes 。
项目读取的音频文件一般很大,buffer不够用,会一直调用makeSlice扩容,消耗大量内存,但是仅仅这样,只是程序执行时消耗了比较多的内存,并未有内存泄露的情况,那服务器又是如何内存不足的呢?这就不得不扯到 Golang 的 GC 机制。
GC算法的触发时机
golang的GC算法为三色算法,按理说会回收临时变量,但是触发GC的时机导致了这个问题:
已分配的 Heap 到达某个阈值,会触发 GC, 该阈值由上一次 GC 时的 HeapAlloc 和 GCPercent 共同决定
每 2 分钟会触发一次强制的 GC,将未 mark 的对象释放,但并不还给 OS
每 5 分钟会扫描一个 Heap, 对于一直没有被访问的 Heap,归还给 OS
ioutil.ReadAll会将全部的数据加载到内存,一个大请求会多次调用makeSlice 分配很多内存空间,并发的时候,会在很短时间内占用大量的系统内存,然后将 GC 阈值增加到一个很高的值,这个时候要 GC 就只有等 2 分钟一次的强制 GC。这样内存中的数据无法及时GC,同时阈值还在不停的升高,导致GC的效率越来越低,最终导致缓慢的内存泄漏。
解决方法
//req.AduioPack,err=ioutil.ReadAll(c.Resquest.Body)
buffer:=bytes.NewBuffer(make[]byte,0,6400)
_,err:=io.Copy(buffer,c.Resquest.Body)
temp:=buffer.Bytes()
req.AduioPack=temp
不是一次性把文件读入内存,而是申请固定的内存大小。
到此,关于“go pprof如何使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





