这篇文章主要讲解了“如何使用Golang爬取必应壁纸”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何使用Golang爬取必应壁纸”吧!
graph TD
请求数据 --> 解析数据 --> 数据入库
接下来具体聊聊每一步需要做什么
请求数据:在这里我们需要使用golang中的内置包http包向目标地址发起请求,这一步就完成了
解析数据:这里我们需要对请求到的数据进行解析,因为不是整个请求到的数据我们都需要,我们只需要某些具体的关键的数据而已。这一步也叫数据清洗
数据入库:不难理解,这就是将解析好的数据进行入库操作
先到必应壁纸官网上观察,做爬虫的话是需要对数据特别敏感的。
接下来,需要调出浏览器的开发者工具(这个大家应该都非常熟悉吧,不熟悉的话很难跟下去的喔)。直接按下F12或者右键点击检查
 但是呢?在必应壁纸上,右键不能调用控制台,只能手动调出了。大家不用担心,按照第一张图操作就好。如果有同学的chrome是中文的,也是一样的操作,选择更多工具,选择开发者工具即可
但是呢?在必应壁纸上,右键不能调用控制台,只能手动调出了。大家不用担心,按照第一张图操作就好。如果有同学的chrome是中文的,也是一样的操作,选择更多工具,选择开发者工具即可
不出意外呢,大家肯定看到的是这样的页面
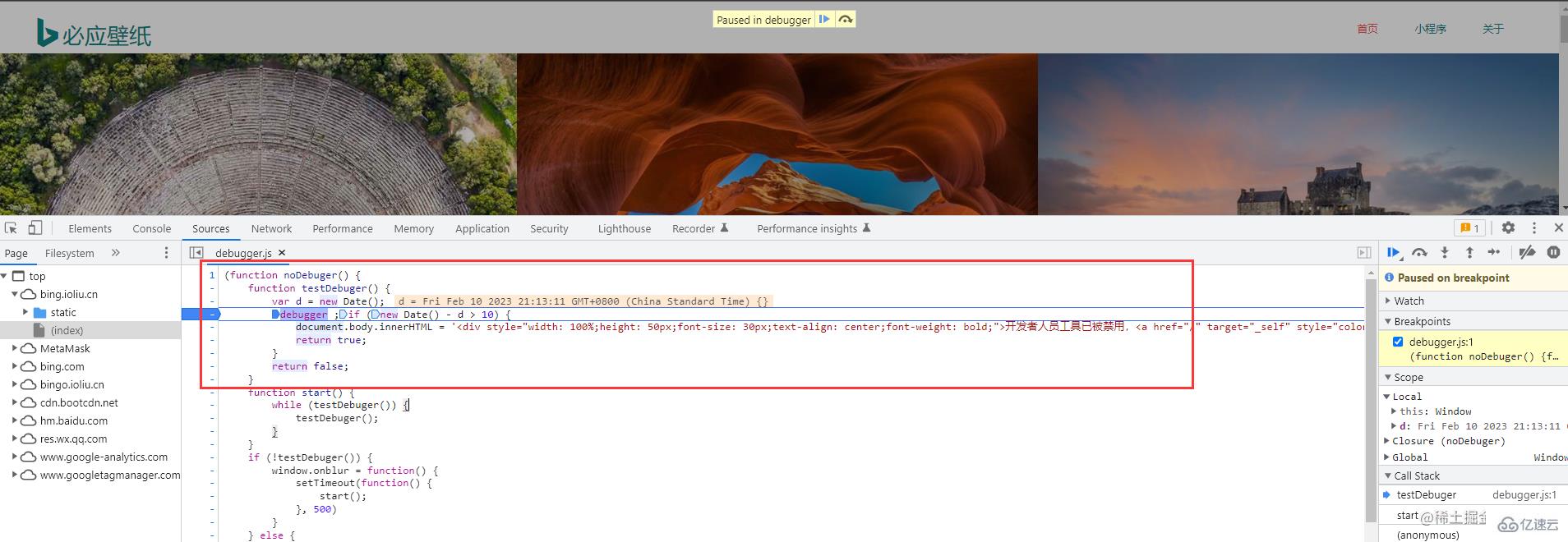 这个没关系的,只是必应壁纸网站的一些反爬错误而已。(我很久之前爬的时候还没有这个反爬错误)这个是不影响我们操作的
这个没关系的,只是必应壁纸网站的一些反爬错误而已。(我很久之前爬的时候还没有这个反爬错误)这个是不影响我们操作的
接下来选择这个工具,帮助我们快速定位到我们想要的元素上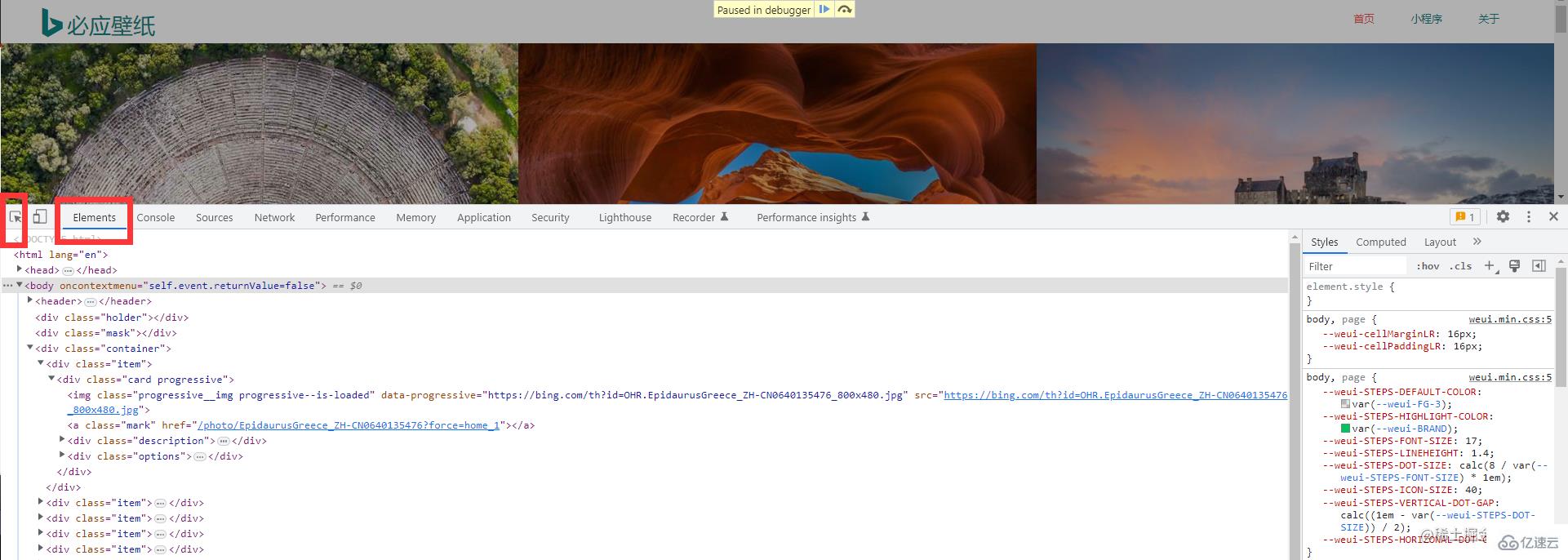 然后我们就能找到我们所需的图片信息
然后我们就能找到我们所需的图片信息

下面是爬取一页的数据
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h4").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}
下面是爬取多页数据爬取多页的代码没有多大的改动,我们还是需要先观察网站的特点
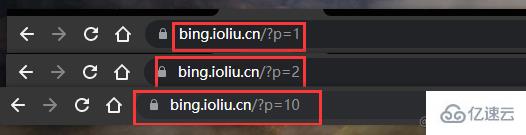
发现什么了吗?第一页p=1,第二页p=2,第十页p=10
所以我们直接起一个for循环,然后复用之前爬取单页的代码就行
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}
感谢各位的阅读,以上就是“如何使用Golang爬取必应壁纸”的内容了,经过本文的学习后,相信大家对如何使用Golang爬取必应壁纸这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





