这篇文章主要介绍了python中怎么实现径向基核函数的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇python中怎么实现径向基核函数文章都会有所收获,下面我们一起来看看吧。
class moon_data_class(object):
def __init__(self,N,d,r,w):
self.N=N
self.w=w
self.d=d
self.r=r
def sgn(self,x):
if(x>0):
return 1;
else:
return -1;
def sig(self,x):
return 1.0/(1+np.exp(x))
def dbmoon(self):
N1 = 10*self.N
N = self.N
r = self.r
w2 = self.w/2
d = self.d
done = True
data = np.empty(0)
while done:
#generate Rectangular data
tmp_x = 2*(r+w2)*(np.random.random([N1, 1])-0.5)
tmp_y = (r+w2)*np.random.random([N1, 1])
tmp = np.concatenate((tmp_x, tmp_y), axis=1)
tmp_ds = np.sqrt(tmp_x*tmp_x + tmp_y*tmp_y)
#generate double moon data ---upper
idx = np.logical_and(tmp_ds > (r-w2), tmp_ds < (r+w2))
idx = (idx.nonzero())[0]
if data.shape[0] == 0:
data = tmp.take(idx, axis=0)
else:
data = np.concatenate((data, tmp.take(idx, axis=0)), axis=0)
if data.shape[0] >= N:
done = False
#print (data)
db_moon = data[0:N, :]
#print (db_moon)
#generate double moon data ----down
data_t = np.empty([N, 2])
data_t[:, 0] = data[0:N, 0] + r
data_t[:, 1] = -data[0:N, 1] - d
db_moon = np.concatenate((db_moon, data_t), axis=0)
return db_moondef k_means(input_cells, k_count):
count = len(input_cells) #点的个数
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
#随机选择K个点
k = rd.sample(range(count), k_count)
k_point = [[x[i], [y[i]]] for i in k] #保证有序
k_point.sort()
global frames
#global step
while True:
km = [[] for i in range(k_count)] #存储每个簇的索引
#遍历所有点
for i in range(count):
cp = [x[i], y[i]] #当前点
#计算cp点到所有质心的距离
_sse = [distance(k_point[j], cp) for j in range(k_count)]
#cp点到那个质心最近
min_index = _sse.index(min(_sse))
#把cp点并入第i簇
km[min_index].append(i)
#更换质心
k_new = []
for i in range(k_count):
_x = sum([x[j] for j in km[i]]) / len(km[i])
_y = sum([y[j] for j in km[i]]) / len(km[i])
k_new.append([_x, _y])
k_new.sort() #排序
if (k_new != k_point):#一直循环直到聚类中心没有变化
k_point = k_new
else:
return k_point,km高斯核函数,主要的作用是衡量两个对象的相似度,当两个对象越接近,即a与b的距离趋近于0,则高斯核函数的值趋近于1,反之则趋近于0,换言之:
两个对象越相似,高斯核函数值就越大
作用:
用于分类时,衡量各个类别的相似度,其中sigma参数用于调整过拟合的情况,sigma参数较小时,即要求分类器,加差距很小的类别也分类出来,因此会出现过拟合的问题;
用于模糊控制时,用于模糊集的隶属度。
def gaussian (a,b, sigma):
return np.exp(-norm(a-b)**2 / (2 * sigma**2)) Sigma_Array = []
for j in range(k_count):
Sigma = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
Sigma.append(temp)
Sigma = np.array(Sigma)
Sigma_Array.append(np.cov(Sigma))gaussian_kernel_array = []
fig = plt.figure()
ax = Axes3D(fig)
for j in range(k_count):
gaussian_kernel = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
temp1 = gaussian(temp,Sigma_Array[0])
gaussian_kernel.append(temp1)
gaussian_kernel_array.append(gaussian_kernel)
ax.scatter(center_array[j][0], center_array[j][1], gaussian_kernel_array[j],s=20)
plt.show()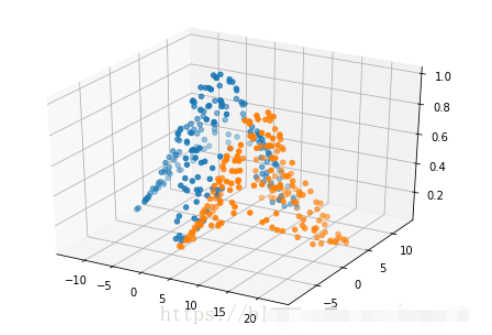
# coding:utf-8
import numpy as np
import pylab as pl
import random as rd
import imageio
import math
import random
import matplotlib.pyplot as plt
import numpy as np
import mpl_toolkits.mplot3d
from mpl_toolkits.mplot3d import Axes3D
from scipy import *
from scipy.linalg import norm, pinv
from matplotlib import pyplot as plt
random.seed(0)
#定义sigmoid函数和它的导数
def sigmoid(x):
return 1.0/(1.0+np.exp(-x))
def sigmoid_derivate(x):
return x*(1-x) #sigmoid函数的导数
class moon_data_class(object):
def __init__(self,N,d,r,w):
self.N=N
self.w=w
self.d=d
self.r=r
def sgn(self,x):
if(x>0):
return 1;
else:
return -1;
def sig(self,x):
return 1.0/(1+np.exp(x))
def dbmoon(self):
N1 = 10*self.N
N = self.N
r = self.r
w2 = self.w/2
d = self.d
done = True
data = np.empty(0)
while done:
#generate Rectangular data
tmp_x = 2*(r+w2)*(np.random.random([N1, 1])-0.5)
tmp_y = (r+w2)*np.random.random([N1, 1])
tmp = np.concatenate((tmp_x, tmp_y), axis=1)
tmp_ds = np.sqrt(tmp_x*tmp_x + tmp_y*tmp_y)
#generate double moon data ---upper
idx = np.logical_and(tmp_ds > (r-w2), tmp_ds < (r+w2))
idx = (idx.nonzero())[0]
if data.shape[0] == 0:
data = tmp.take(idx, axis=0)
else:
data = np.concatenate((data, tmp.take(idx, axis=0)), axis=0)
if data.shape[0] >= N:
done = False
#print (data)
db_moon = data[0:N, :]
#print (db_moon)
#generate double moon data ----down
data_t = np.empty([N, 2])
data_t[:, 0] = data[0:N, 0] + r
data_t[:, 1] = -data[0:N, 1] - d
db_moon = np.concatenate((db_moon, data_t), axis=0)
return db_moon
def distance(a, b):
return (a[0]- b[0]) ** 2 + (a[1] - b[1]) ** 2
#K均值算法
def k_means(input_cells, k_count):
count = len(input_cells) #点的个数
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
#随机选择K个点
k = rd.sample(range(count), k_count)
k_point = [[x[i], [y[i]]] for i in k] #保证有序
k_point.sort()
global frames
#global step
while True:
km = [[] for i in range(k_count)] #存储每个簇的索引
#遍历所有点
for i in range(count):
cp = [x[i], y[i]] #当前点
#计算cp点到所有质心的距离
_sse = [distance(k_point[j], cp) for j in range(k_count)]
#cp点到那个质心最近
min_index = _sse.index(min(_sse))
#把cp点并入第i簇
km[min_index].append(i)
#更换质心
k_new = []
for i in range(k_count):
_x = sum([x[j] for j in km[i]]) / len(km[i])
_y = sum([y[j] for j in km[i]]) / len(km[i])
k_new.append([_x, _y])
k_new.sort() #排序
if (k_new != k_point):#一直循环直到聚类中心没有变化
k_point = k_new
else:
pl.figure()
pl.title("N=%d,k=%d iteration"%(count,k_count))
for j in range(k_count):
pl.plot([x[i] for i in km[j]], [y[i] for i in km[j]], color[j%4])
pl.plot(k_point[j][0], k_point[j][1], dcolor[j%4])
return k_point,km
def Phi(a,b):
return norm(a-b)
def gaussian (x, sigma):
return np.exp(-x**2 / (2 * sigma**2))
if __name__ == '__main__':
#计算平面两点的欧氏距离
step=0
color=['.r','.g','.b','.y']#颜色种类
dcolor=['*r','*g','*b','*y']#颜色种类
frames = []
N = 200
d = -4
r = 10
width = 6
data_source = moon_data_class(N, d, r, width)
data = data_source.dbmoon()
# x0 = [1 for x in range(1,401)]
input_cells = np.array([np.reshape(data[0:2*N, 0], len(data)), np.reshape(data[0:2*N, 1], len(data))]).transpose()
labels_pre = [[1] for y in range(1, 201)]
labels_pos = [[0] for y in range(1, 201)]
labels=labels_pre+labels_pos
k_count = 2
center,km = k_means(input_cells, k_count)
test = Phi(input_cells[1],np.array(center[0]))
print(test)
test = distance(input_cells[1],np.array(center[0]))
print(np.sqrt(test))
count = len(input_cells)
x = input_cells[0:count, 0]
y = input_cells[0:count, 1]
center_array = []
for j in range(k_count):
center_array.append([[x[i] for i in km[j]], [y[i] for i in km[j]]])
Sigma_Array = []
for j in range(k_count):
Sigma = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
Sigma.append(temp)
Sigma = np.array(Sigma)
Sigma_Array.append(np.cov(Sigma))
gaussian_kernel_array = []
fig = plt.figure()
ax = Axes3D(fig)
for j in range(k_count):
gaussian_kernel = []
for i in range(len(center_array[j][0])):
temp = Phi(np.array([center_array[j][0][i],center_array[j][1][i]]),np.array(center[j]))
temp1 = gaussian(temp,Sigma_Array[0])
gaussian_kernel.append(temp1)
gaussian_kernel_array.append(gaussian_kernel)
ax.scatter(center_array[j][0], center_array[j][1], gaussian_kernel_array[j],s=20)
plt.show()关于“python中怎么实现径向基核函数”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“python中怎么实现径向基核函数”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



