今天小编给大家分享一下怎么使用Python+tkinter实现网站下载工具的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
python 3.8: 解释器
pycharm: 代码编辑器
1.先确定想要的功能,今天这个项目的主要功能为三个
视频
评论
弹幕
2.创建一个简单的用户交互界面,简洁明了

import tkinter as tk from tkinter import ttk import tkinter.messagebox
root = tk.Tk()
root.title('哔站下载软件')
root.geometry('367x134+200+200')
# 透明度的值:0~1 也可以是小数点,0:全透明;1:全不透明
root.attributes("-alpha", 0.9)
root.mainloop()
text_label_1 = tk.Label(root, text='选择: ', font=('黑体', 15))
text_label_1.grid(row=1, column=0, padx=5, pady=5)
number_int_var = tk.StringVar()
# 创建一个下拉列表
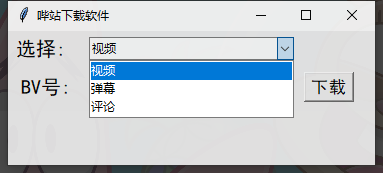
numberChosen = ttk.Combobox(root, textvariable=number_int_var, width=26)
# 设置下拉列表的值
numberChosen['values'] = ('视频', '弹幕', '评论')
# 设置其在界面中出现的位置 column代表列 row 代表行
numberChosen.grid(row=1, column=1, padx=5, pady=5)
# 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值
numberChosen.current(0)
text_label = tk.Label(root, text='BV号:', font=('黑体', 15))
text_label.grid(row=2, column=0, padx=5, pady=5)
bv_va = tk.Variable()
entry_1 = tk.Entry(root, font=('黑体', 15), textvariable=bv_va)
entry_1.grid(row=2, column=1)
Button_1 = tk.Button(root, text='下载', font=('黑体', 13))
Button_1.grid(row=2, column=2, padx=5, pady=5)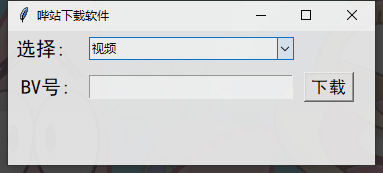
我们用正则来提取数据
正则表达式 —> 对于字符串数据类型进行提取/解析
re模块findall() ----> 告诉程序从什么地方去找什么数据
re.findall() '“title”:“(.?)“,“pubdate”', response.text
从 response.text 里面 去找 “title”:”(.?)”,“pubdate” 其中括号里内容就是我们要的
def Video(bv_id):
url = f'https://www.bilibili.com/video/{bv_id}'
# 把python代码伪装成浏览器 ---> 在开发者工具里面直接复制粘贴
headers = {
# 防盗链
'referer': 'https://www.bilibili.com/video/',
# 浏览器基本身份标识 表示浏览器
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 ---> <Response [200]> 响应对象, 200状态码 表示请求成功
response = requests.get(url=url, headers=headers)
# 获取视频标题
title = re.findall('"title":"(.*?)","pubdate"', response.text)[0].replace(' ', '')
# 获取视频数据信息 前端标签两个两个一起
html_data = re.findall('<script>window.__playinfo__=(.*?)</script>', response.text)[0]
# 转换数据类型 字符串数据转成json字典数据类型
json_data = json.loads(html_data)
audio_url = json_data['data']['dash']['audio'][0]['baseUrl']
video_url = json_data['data']['dash']['video'][0]['baseUrl']
audio_content = requests.get(url=audio_url, headers=headers).content
video_content = requests.get(url=video_url, headers=headers).content
if not os.path.exists('video\\'):
os.mkdir('video\\')
with open('video\\' + title + '.mp3', mode='wb') as audio:
audio.write(audio_content)
with open('video\\' + title + '.mp4', mode='wb') as video:
video.write(video_content)
return title这个功能,前段时间已经发布过相关的文章教程
请看这里:用Python获取弹幕的两种方式(一种简单但量少,另一量大管饱)
def get_response(html_url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def get_Dm_url(bv_id):
link = f'https://www.ibilibili.com/video/{bv_id}/'
html_data = get_response(link).text
Dm_url = re.findall('<a href="(.*?)" rel="external nofollow" class="btn btn-default" target="_blank">弹幕</a>', html_data)[0]
title = re.findall('<input type="text" value="(.*?)"', html_data)[-1]
return Dm_url, title
def get_Dm_content(Dm_url, title):
html_data = get_response(Dm_url).text
content_list = re.findall('<d p=".*?">(.*?)</d>', html_data)
if not os.path.exists('弹幕\\'):
os.mkdir('弹幕\\')
for content in content_list:
with open(f'弹幕\\{title}弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
def main(bv_id):
Dm_url, title = get_Dm_url(bv_id)
get_Dm_content(Dm_url, title)单页少量的数据很简单,但要想翻页,必须分析网站,找到规律
def get_response(html_url, params=None):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=html_url, params=params, headers=headers)
return response
def get_oid(bv_id):
link = f'https://www.bilibili.com/video/{bv_id}/'
html_data = get_response(link).text
oid = re.findall('window.__INITIAL_STATE__={"aid":(\d+),', html_data)[0]
title = re.findall('"title":"(.*?)","pubdate"', html_data)[0].replace(' ', '')
return oid, title
def get_content(oid, page, title):
content_url = 'https://api.bilibili.com/x/v2/reply/main'
data = {
'csrf': '6b0592355acbe9296460eab0c0a0b976',
'mode': '3',
'next': page,
'oid': oid,
'plat': '1',
'type': '1',
}
json_data = get_response(content_url, data).json()
content = '\n'.join([i['content']['message'] for i in json_data['data']['replies']])
if not os.path.exists('评论\\'):
os.mkdir('评论\\')
with open(f'评论\\{title}评论.txt', mode='a', encoding='utf-8') as f:
f.write(content)
def main(bv_id):
oid, title = get_oid(bv_id)
for page in range(1, 6):
try:
get_content(oid, page, title)
except:
pass以上就是“怎么使用Python+tkinter实现网站下载工具”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





