C++В BloomFilterеёғйҡҶиҝҮж»ӨеҷЁеҰӮдҪ•еә”з”Ё
иҝҷзҜҮвҖңC++ BloomFilterеёғйҡҶиҝҮж»ӨеҷЁеҰӮдҪ•еә”з”ЁвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңC++ BloomFilterеёғйҡҶиҝҮж»ӨеҷЁеҰӮдҪ•еә”з”ЁвҖқж–Үз« еҗ§гҖӮ
дёҖгҖҒеёғйҡҶиҝҮж»ӨеҷЁжҰӮеҝө
еёғйҡҶиҝҮж»ӨеҷЁжҳҜз”ұеёғйҡҶпјҲBurton Howard BloomпјүеңЁ1970е№ҙжҸҗеҮәзҡ„ дёҖз§Қзҙ§еҮ‘еһӢзҡ„гҖҒжҜ”иҫғе·§еҰҷзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢзү№зӮ№жҳҜй«ҳж•Ҳең°жҸ’е…Ҙе’ҢжҹҘиҜўпјҢеҸҜд»Ҙз”ЁжқҘе‘ҠиҜүдҪ вҖңжҹҗж ·дёңиҘҝдёҖе®ҡдёҚеӯҳеңЁжҲ–иҖ…еҸҜиғҪеӯҳеңЁвҖқпјҢе®ғжҳҜз”ЁеӨҡдёӘе“ҲеёҢеҮҪж•°пјҢе°ҶдёҖдёӘж•°жҚ®жҳ е°„еҲ°дҪҚеӣҫз»“жһ„дёӯгҖӮжӯӨз§Қж–№ејҸдёҚд»…еҸҜд»ҘжҸҗеҚҮжҹҘиҜўж•ҲзҺҮпјҢд№ҹеҸҜд»ҘиҠӮзңҒеӨ§йҮҸзҡ„еҶ…еӯҳз©әй—ҙ .
дҪҚеӣҫзҡ„дјҳзӮ№жҳҜиҠӮзңҒз©әй—ҙпјҢеҝ«пјҢзјәзӮ№жҳҜиҰҒжұӮиҢғеӣҙзӣёеҜ№йӣҶдёӯпјҢеҰӮжһңиҢғеӣҙеҲҶж•ЈпјҢз©әй—ҙж¶ҲиҖ—дёҠеҚҮпјҢеҗҢж—¶еҸӘиғҪй’ҲеҜ№ж•ҙеһӢпјҢеӯ—з¬ҰдёІйҖҡиҝҮе“ҲеёҢиҪ¬еҢ–жҲҗж•ҙеһӢпјҢеҶҚеҺ»жҳ е°„пјҢеҜ№дәҺж•ҙеһӢжІЎжңүеҶІзӘҒпјҢеӣ дёәж•ҙеһӢжҳҜжңүйҷҗзҡ„пјҢжҳ е°„е”ҜдёҖзҡ„дҪҚзҪ®пјҢдҪҶжҳҜеҜ№дәҺеӯ—з¬ҰдёІжқҘиҜҙпјҢжҳҜж— йҷҗзҡ„пјҢдјҡеҸ‘з”ҹеҶІзӘҒпјҢдјҡеҸ‘з”ҹиҜҜеҲӨпјҡжӯӨж—¶зҡ„жғ…еҶөзҡ„жҳҜдёҚеңЁжҳҜжӯЈзЎ®зҡ„пјҢеңЁжҳҜдёҚжӯЈзЎ®зҡ„пјҢеӣ дёәеҸҜиғҪдёҚжқҘжҳҜдёҚеңЁзҡ„пјҢдҪҶжҳҜдҪҚзҪ®и·ҹеҲ«дәәеҸ‘з”ҹеҶІзӘҒпјҢеҸ‘з”ҹиҜҜеҲӨ
жӯӨж—¶еёғйҡҶиҝҮж»ӨеҷЁе°ұзҷ»еңәдәҶпјҢеҸҜд»ҘйҷҚдҪҺиҜҜеҲӨзҺҮпјҡи®©дёҖдёӘеҖјжҳ е°„еӨҡдёӘдҪҚзҪ®пјҢдҪҶжҳҜ并дёҚжҳҜж¶ҲйҷӨиҜҜеҲӨ
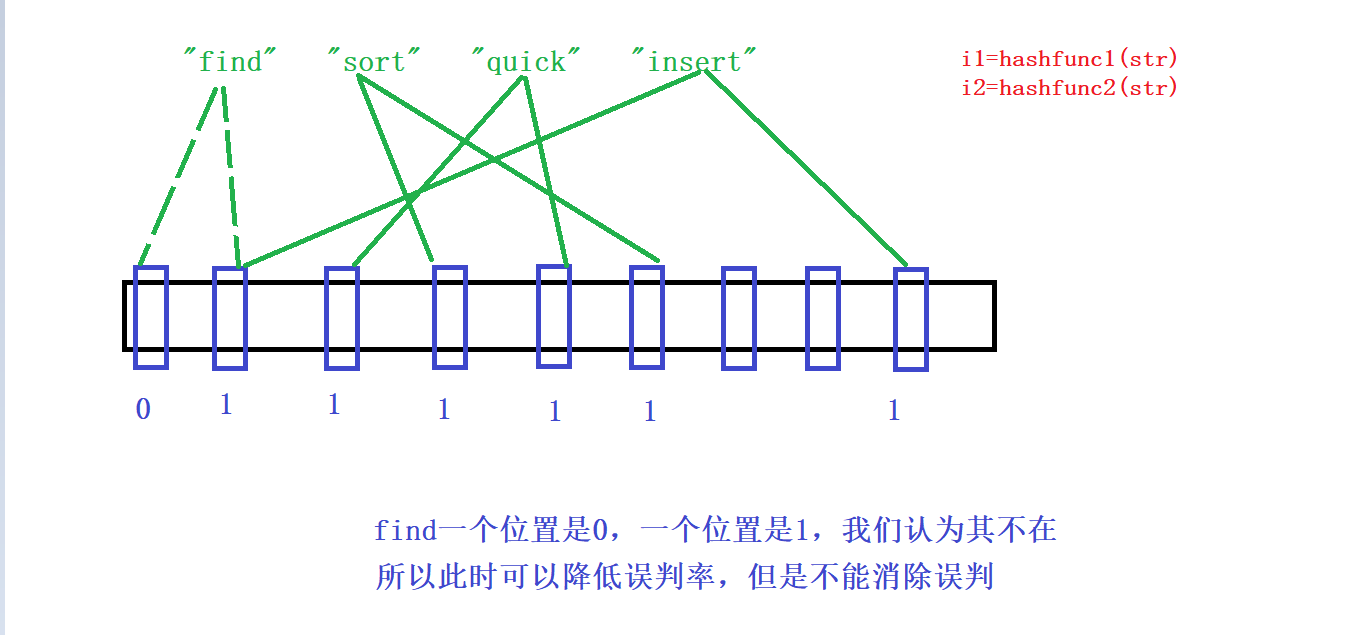
еҸҜиғҪиҝҳжҳҜдјҡеҮәзҺ°иҜҜеҲӨпјҡ
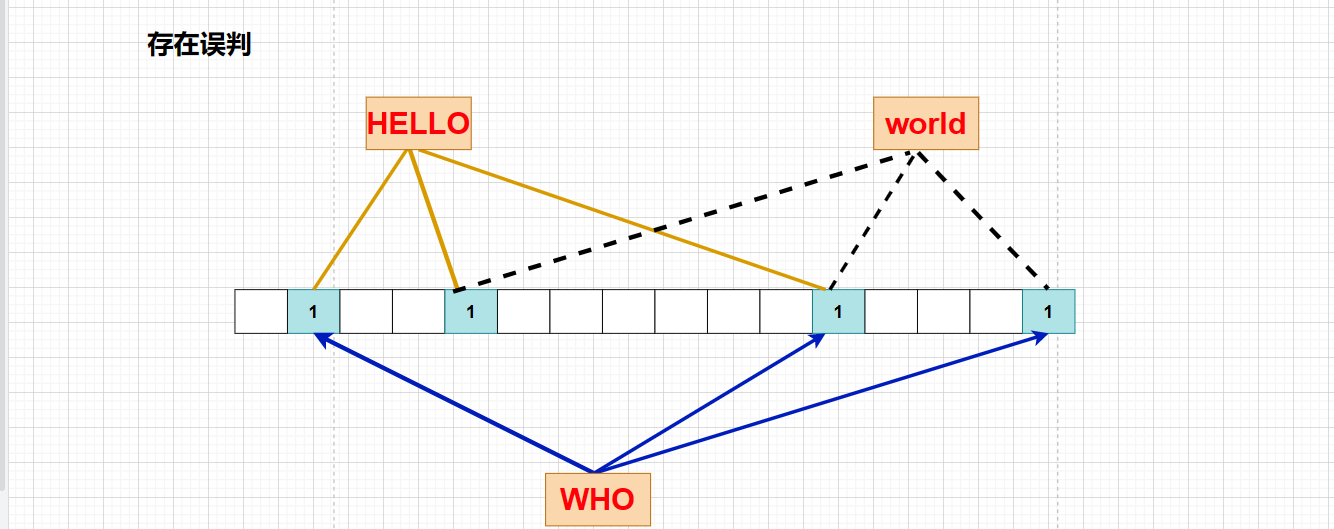
иҷҪ然еёғйҡҶиҝҮж»ӨеҷЁиҝҳжҳҜдјҡеҮәзҺ°иҜҜеҲӨпјҢеӣ дёәиҝҷдёӘж•°жҚ®зҡ„жҜ”зү№дҪҚиў«е…¶д»–ж•°жҚ®жүҖеҚ пјҢдҪҶжҳҜеҲӨж–ӯдёҖдёӘж•°жҚ®дёҚеӯҳеңЁжҳҜеҮҶзЎ®пјҢдёҚеӯҳеңЁе°ұжҳҜ0пјҒ
еёғйҡҶиҝҮж»ӨеҷЁж”№иҝӣпјҡжҳ е°„еӨҡдёӘдҪҚзҪ®пјҢйҷҚдҪҺиҜҜеҲӨзҺҮпјҲдҪҚзҪ®и¶ҠеӨҡпјҢж¶ҲиҖ—д№ҹи¶ҠеӨҡпјү
еҰӮжһңеёғйҡҶиҝҮж»ӨеҷЁй•ҝеәҰжҜ”иҫғе°ҸпјҢжҜ”зү№дҪҚеҫҲеҝ«дјҡиў«еҚ дёә1пјҢиҜҜеҲӨзҺҮиҮӘ然дјҡдёҠеҚҮпјҢжүҖд»ҘеёғйҡҶиҝҮж»ӨеҷЁзҡ„й•ҝеәҰдјҡеҪұе“ҚиҜҜеҲӨзҺҮпјҢзҗҶи®әдёҠжқҘиҜҙпјҢеҰӮжһңдёҖдёӘеҖјжҳ е°„зҡ„дҪҚзҪ®и¶ҠеӨҡпјҢеҲҷиҜҜеҲӨзҡ„жҰӮзҺҮи¶Ҡе°ҸпјҢдҪҶжҳҜ并дёҚжҳҜдҪҚзҪ®и¶ҠеӨҡи¶ҠеҘҪпјҢз©әй—ҙд№ҹдјҡж¶ҲиҖ—пјҡеӨ§дҪ¬д»¬иҮӘ然д№ҹиғҪеӨҹжғіеҫ—еҲ°пјҢжүҖд»Ҙжңүе…¬ејҸпјҡ

жҲ‘们еҸҜд»ҘжқҘдј°з®—дёҖдёӢпјҢеҒҮи®ҫз”Ё 3 дёӘе“ҲеёҢеҮҪж•°пјҢеҚіK=3пјҢln2 зҡ„еҖјжҲ‘们еҸ– 0.7пјҢйӮЈд№Ҳ m е’Ң n зҡ„е…ізі»еӨ§жҰӮжҳҜ m = n×k/ln2=4.2n пјҢд№ҹе°ұжҳҜиҝҮж»ӨеҷЁй•ҝеәҰеә”иҜҘжҳҜжҸ’е…Ҙе…ғзҙ дёӘж•°зҡ„ 4 -5еҖҚ
дәҢгҖҒеёғйҡҶиҝҮж»ӨеҷЁеә”з”Ё
дёҚйңҖиҰҒдёҖе®ҡеҮҶзЎ®зҡ„еңәжҷҜгҖӮжҜ”еҰӮжёёжҲҸжіЁеҶҢж—¶еҖҷзҡ„жҳөз§°зҡ„еҲӨйҮҚпјҡеҰӮжһңдёҚеңЁйӮЈе°ұжҳҜдёҚеңЁпјҢжІЎиў«дҪҝз”ЁпјҢеңЁзҡ„иҜқеҸҜиғҪдјҡиў«иҜҜеҲӨгҖӮ
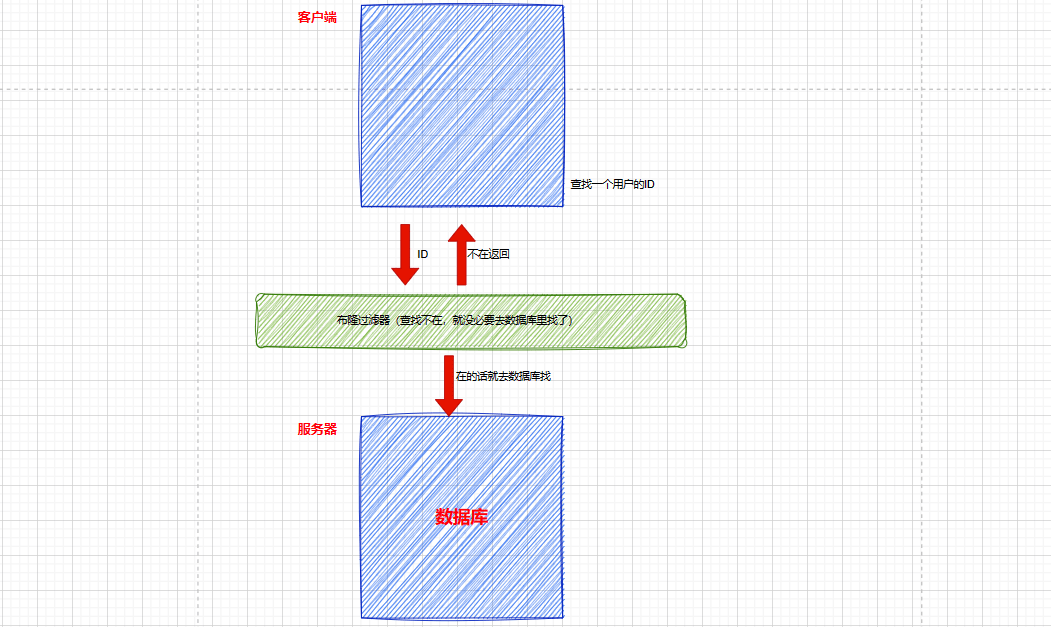
жҸҗй«ҳжҹҘжүҫж•ҲзҺҮпјҡе®ўжҲ·з«ҜдёӯжҹҘжүҫдёҖдёӘз”ЁжҲ·зҡ„IDдёҺжңҚеҠЎеҷЁдёӯзҡ„жҳҜеҗҰзӣёеҗҢпјҢеңЁеўһеҠ дёҖеұӮеёғйҡҶиҝҮж»ӨеҷЁжҸҗй«ҳжҹҘжүҫж•ҲзҺҮпјҡ
дёүгҖҒеёғйҡҶиҝҮж»ӨеҷЁе®һзҺ°
еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҸ’е…Ҙе…ғзҙ еҸҜиғҪжҳҜеӯ—з¬ҰдёІпјҢд№ҹеҸҜиғҪжҳҜе…¶д»–зұ»еһӢпјҢеҸӘиҰҒжҸҗдҫӣеҜ№еә”зҡ„е“ҲеёҢеҮҪж•°е°ҶиҜҘзұ»еһӢзҡ„ж•°жҚ®иҪ¬жҚўжҲҗж•ҙеһӢе°ұеҸҜд»ҘдәҶгҖӮ
дёҖиҲ¬жғ…еҶөдёӢеёғйҡҶиҝҮж»ӨеҷЁйғҪжҳҜз”ЁжқҘеӨ„зҗҶеӯ—з¬ҰдёІзҡ„пјҢжүҖд»ҘеёғйҡҶиҝҮж»ӨеҷЁеҸҜд»Ҙе®һзҺ°дёәдёҖдёӘжЁЎжқҝзұ»пјҢе°ҶжЁЎжқҝеҸӮж•° T зҡ„зјәзңҒзұ»еһӢи®ҫзҪ®дёә stringпјҡ
template <size_t N,size_t X = 5,class K=string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
private:
bitset<N * X> _bs;
};иҝҷйҮҢеёғйҡҶиҝҮж»ӨеҷЁжҸҗдҫӣдёүдёӘе“ҲеёҢеҮҪж•°пјҢз”ұдәҺеёғйҡҶиҝҮж»ӨеҷЁдёҖиҲ¬еӨ„зҗҶзҡ„жҳҜеӯ—з¬ҰдёІзұ»еһӢзҡ„ж•°жҚ®пјҢжүҖд»ҘжҲ‘们й»ҳи®ӨжҸҗдҫӣеҮ дёӘе°Ҷеӯ—з¬ҰдёІиҪ¬жҚўжҲҗж•ҙеһӢзҡ„е“ҲеёҢеҮҪж•°пјҡйҖүеҸ–з»јеҗҲиҜ„еҲҶжңҖй«ҳзҡ„ BKDRHashгҖҒAPHash е’Ң DJBHashиҝҷдёүз§Қе“ҲеёҢз®—жі•пјҡ
struct BKDRHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
int i = 0;
for (auto ch : key)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));
}
++i;
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
size_t hash = 5318;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};1.жҸ’е…Ҙ
еёғйҡҶиҝҮж»ӨеҷЁеӨҚз”Ёbitsetзҡ„ set жҺҘеҸЈз”ЁдәҺжҸ’е…Ҙе…ғзҙ пјҢжҸ’е…Ҙе…ғзҙ ж—¶пјҢжҲ‘们йҖҡиҝҮдёҠйқўзҡ„дёүдёӘе“ҲеёҢеҮҪж•°еҲҶеҲ«и®Ўз®—еҮәиҜҘе…ғзҙ еҜ№еә”зҡ„дёүдёӘжҜ”зү№дҪҚпјҢ然еҗҺеңЁдҪҚеӣҫдёӯи®ҫзҪ®дёә1еҚіеҸҜпјҡ
void set(const K& key)
{
size_t hash2 = HashFunc1()(key) % (N * X);
size_t hash3 = HashFunc2()(key) % (N * X);
size_t hash4 = HashFunc3()(key) % (N * X);
_bs.set(hash2);
_bs.set(hash3);
_bs.set(hash4);
_bs.set(hash5);
}2.жҹҘжүҫ
йҖҡиҝҮдёүдёӘе“ҲеёҢеҮҪж•°еҲҶеҲ«з®—еҮәеҜ№еә”е…ғзҙ зҡ„дёүдёӘе“ҲеёҢең°еқҖпјҢеҫ—еҲ°еҜ№еә”зҡ„жҜ”зү№дҪҚпјҢ然еҗҺеҺ»еҲӨж–ӯиҝҷдёүдёӘжҜ”зү№дҪҚжҳҜеҗҰйғҪиў«и®ҫзҪ®жҲҗдәҶ1
еҰӮжһңеҮәзҺ°дёҖдёӘжҜ”зү№дҪҚжңӘиў«и®ҫзҪ®жҲҗ1иҜҙжҳҺиҜҘе…ғзҙ дёҖе®ҡдёҚеӯҳеңЁпјҢд№ҹе°ұжҳҜеҰӮжһңдёҖдёӘжҜ”зү№дҪҚдёә0е°ұжҳҜfalseпјӣиҖҢеҰӮжһңдёүдёӘжҜ”зү№дҪҚе…ЁйғЁйғҪиў«и®ҫзҪ®пјҢеҲҷreturn trueиЎЁзӨәиҜҘе…ғзҙ е·Із»ҸеӯҳеңЁпјҲжіЁпјҡеҸҜиғҪдјҡеҮәзҺ°иҜҜеҲӨпјү
bool test(const K& key)
{
size_t hash2 = HashFunc1()(key) % (N * X);
if (!_bs.test(hash2))
{
return false;
}
size_t hash3 = HashFunc2()(key) % (N * X);
if (!_bs.test(hash3))
{
return false;
}
size_t hash4 = HashFunc3()(key) % (N * X);
if (!_bs.test(hash4))
{
return false;
}
return true;
}3.еҲ йҷӨ
еёғйҡҶиҝҮж»ӨеҷЁдёҖиҲ¬жІЎжңүеҲ йҷӨпјҢеӣ дёәеёғйҡҶиҝҮж»ӨеҷЁеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜдјҡеӯҳеңЁиҜҜеҲӨпјҢжӯӨж—¶ж— жі•дҝқиҜҒиҰҒеҲ йҷӨзҡ„е…ғзҙ еңЁеёғйҡҶиҝҮж»ӨеҷЁдёӯпјҢеҰӮжһңжӯӨж—¶е°ҶдҪҚеӣҫдёӯеҜ№еә”зҡ„жҜ”зү№дҪҚжё…0пјҢе°ұдјҡеҪұе“ҚеҲ°е…¶д»–е…ғзҙ дәҶпјҡ
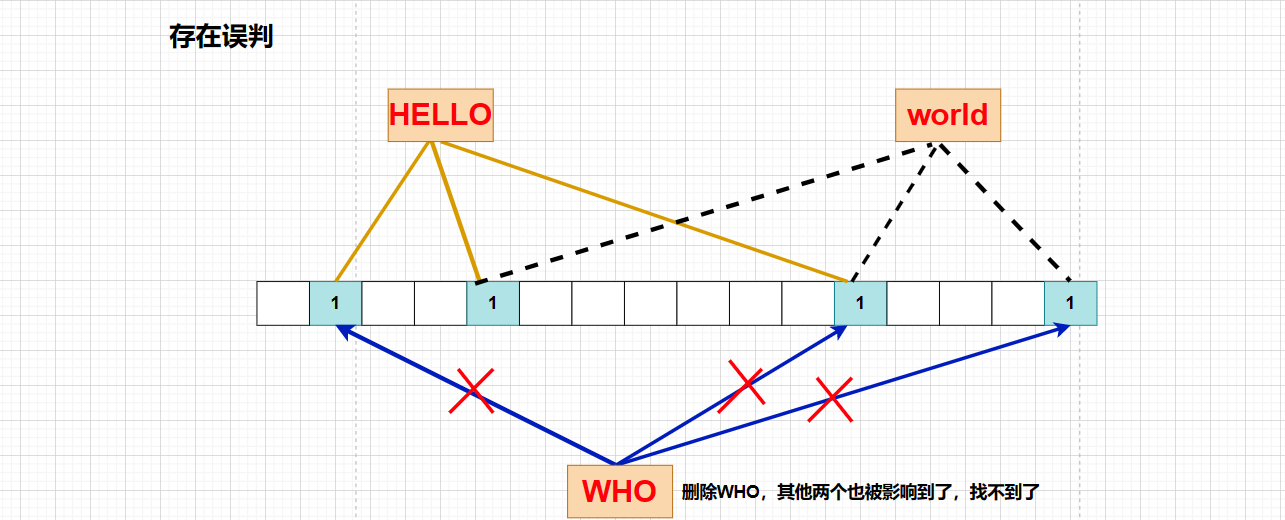
иҝҷж—¶еҖҷжҲ‘们еҸӘйңҖиҰҒеңЁжҜҸдёӘжҜ”зү№дҪҚеҠ дёҖдёӘи®Ўж•°еҷЁпјҢеҪ“еӯҳеңЁжҸ’е…Ҙж“ҚдҪңж—¶пјҢеңЁи®Ўж•°еҷЁйҮҢйқўиҝӣиЎҢ ++пјҢеҲ йҷӨеҗҺеҜ№иҜҘдҪҚзҪ®иҝӣиЎҢ -- еҚіеҸҜ
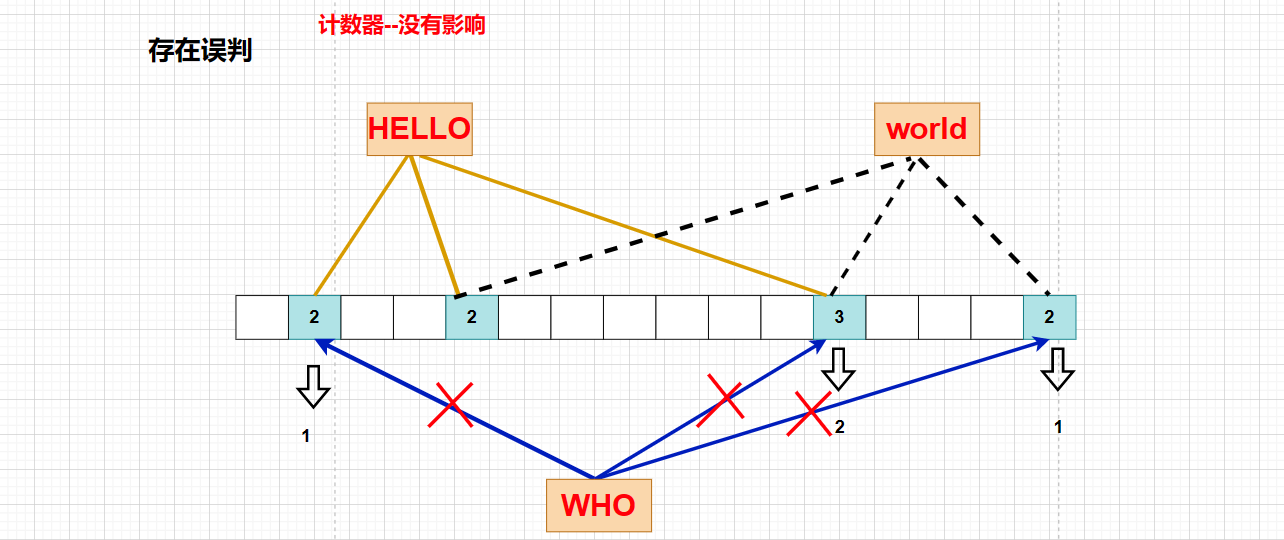
дҪҶжҳҜеёғйҡҶиҝҮж»ӨеҷЁзҡ„жң¬жқҘзӣ®зҡ„е°ұжҳҜдёәдәҶжҸҗй«ҳж•ҲзҺҮе’ҢиҠӮзңҒз©әй—ҙпјҢеңЁжҜҸдёӘжҜ”зү№дҪҚеўһеҠ йўқеӨ–зҡ„и®Ўж•°еҷЁпјҢз©әй—ҙж¶ҲиҖ—йӮЈе°ұжӣҙеӨҡдәҶ
еӣӣгҖҒеёғйҡҶиҝҮж»ӨеҷЁдјҳзјә
дјҳ
\1. еўһеҠ е’ҢжҹҘиҜўе…ғзҙ зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёә:O(K), (Kдёәе“ҲеёҢеҮҪж•°зҡ„дёӘж•°пјҢдёҖиҲ¬жҜ”иҫғе°Ҹ)пјҢдёҺж•°жҚ®йҮҸеӨ§е°Ҹж— е…і
\2. е“ҲеёҢеҮҪж•°зӣёдә’д№Ӣй—ҙжІЎжңүе…ізі»пјҢж–№дҫҝ硬件并иЎҢиҝҗз®—
\3. еёғйҡҶиҝҮж»ӨеҷЁдёҚйңҖиҰҒеӯҳеӮЁе…ғзҙ жң¬иә«пјҢеңЁжҹҗдәӣеҜ№дҝқеҜҶиҰҒжұӮжҜ”иҫғдёҘж јзҡ„еңәеҗҲжңүеҫҲеӨ§дјҳеҠҝ
\4. еңЁиғҪеӨҹжүҝеҸ—дёҖе®ҡзҡ„иҜҜеҲӨж—¶пјҢеёғйҡҶиҝҮж»ӨеҷЁжҜ”е…¶д»–ж•°жҚ®з»“жһ„жңүиҝҷеҫҲеӨ§зҡ„з©әй—ҙдјҳеҠҝ
\5. ж•°жҚ®йҮҸеҫҲеӨ§ж—¶пјҢеёғйҡҶиҝҮж»ӨеҷЁеҸҜд»ҘиЎЁзӨәе…ЁйӣҶпјҢе…¶д»–ж•°жҚ®з»“жһ„дёҚиғҪ
\6. дҪҝз”ЁеҗҢдёҖз»„ж•ЈеҲ—еҮҪж•°зҡ„еёғйҡҶиҝҮж»ӨеҷЁеҸҜд»ҘиҝӣиЎҢдәӨгҖҒ并гҖҒе·®иҝҗз®—
зјә
\1. жңүиҜҜеҲӨзҺҮпјҢдёҚиғҪеҮҶзЎ®еҲӨж–ӯе…ғзҙ жҳҜеҗҰеңЁйӣҶеҗҲдёӯ(иЎҘж•‘ж–№жі•пјҡеҶҚе»әз«ӢдёҖдёӘзҷҪеҗҚеҚ•пјҢеӯҳеӮЁеҸҜиғҪдјҡиҜҜеҲӨзҡ„ж•°жҚ®)
\2. дёҚиғҪиҺ·еҸ–е…ғзҙ жң¬иә«
\3. дёҖиҲ¬жғ…еҶөдёӢдёҚиғҪд»ҺеёғйҡҶиҝҮж»ӨеҷЁдёӯеҲ йҷӨе…ғзҙ
дә”гҖҒз»“иҜӯ
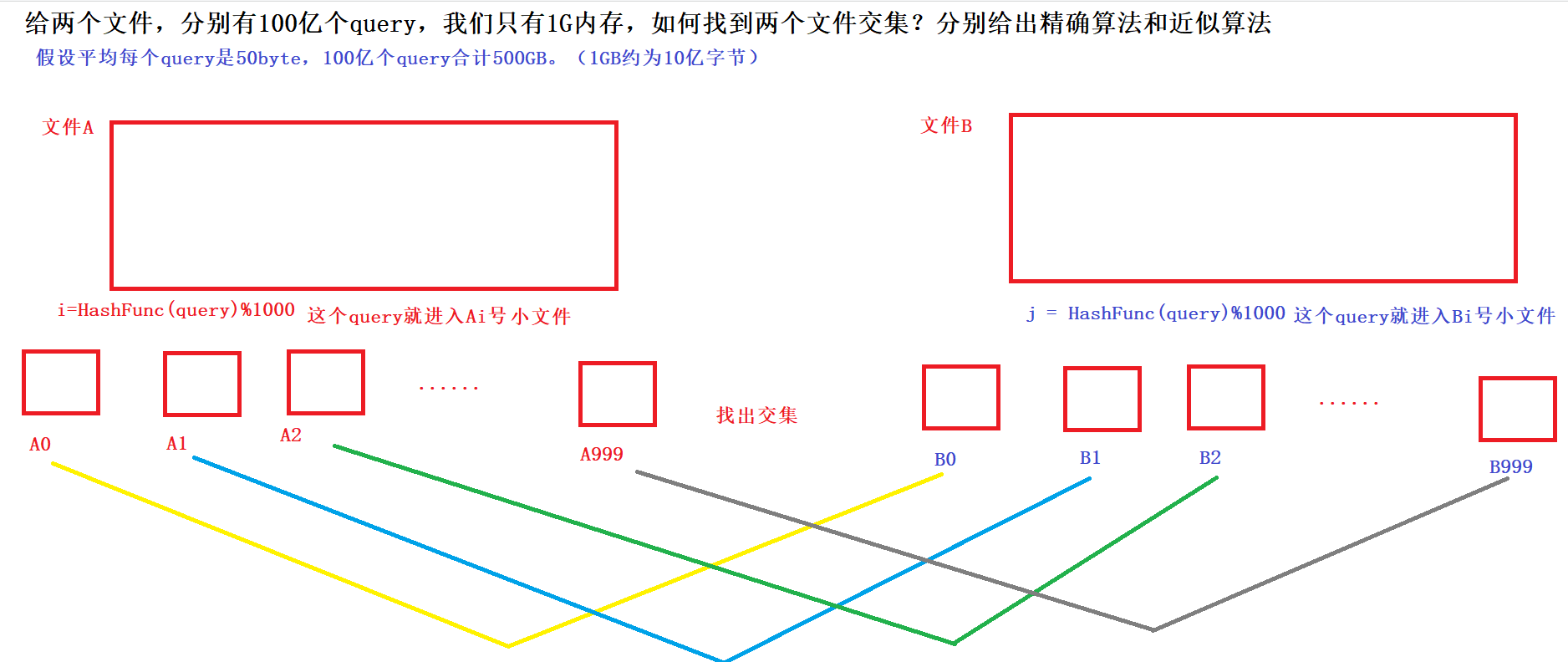
з»ҷдёӨдёӘж–Ү件пјҢеҲҶеҲ«жңү100дәҝдёӘqueryпјҢжҲ‘们еҸӘжңү1GеҶ…еӯҳпјҢеҰӮдҪ•жүҫеҲ°дёӨдёӘж–Ү件дәӨйӣҶпјҹеҲҶеҲ«з»ҷеҮәзІҫзЎ®з®—жі•е’Ңиҝ‘дјјз®—жі•пјҹ
иҝ‘дјјз®—жі•пјҡеҲ©з”ЁеёғйҡҶиҝҮж»ӨеҷЁпјҢдәӨйӣҶзҡ„е°ұдёҖе®ҡдјҡиҝӣеҺ»пјҢдҪҶжҳҜеҸҜиғҪдјҡеӯҳеңЁиҜҜеҲӨпјҡдёҚеҗҢзҡ„д№ҹдјҡиҝӣеҺ»пјҢиҝҷжҳҜиҝ‘дјј
зІҫеҮҶз®—жі•пјҡqueryдёҖиҲ¬жҳҜжҹҘиҜўжҢҮд»ӨпјҢжҜ”еҰӮеҸҜиғҪжҳҜзҪ‘з»ңиҜ·жұӮпјҢжҲ–иҖ…жҳҜдёҖдёӘж•°жҚ®еә“sqlиҜӯеҸҘ
100дәҝдёӘquery,еҒҮи®ҫе№іеқҮжҜҸдёӘqueryжҳҜ50byteпјҢеҲҷ100дәҝдёӘqueryйӮЈе°ұжҳҜеҗҲи®Ў500GB
зӣёеҗҢзҡ„queryпјҢжҳҜдёҖе®ҡиҝӣе…ҘзӣёеҗҢзј–еҸ·зҡ„е°Ҹж–Ү件пјҢеҶҚеҜ№иҝҷдәӣж–Ү件ж”ҫиҝӣеҶ…еӯҳзҡ„дёӨдёӘsetдёӯпјҢзј–еҸ·зӣёеҗҢзҡ„Aiе’ҢBiе°Ҹж–Ү件жүҫдәӨйӣҶеҚіеҸҜ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңC++ BloomFilterеёғйҡҶиҝҮж»ӨеҷЁеҰӮдҪ•еә”з”ЁвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





