本文小编为大家详细介绍“C++怎么实现数据库连接池”,内容详细,步骤清晰,细节处理妥当,希望这篇“C++怎么实现数据库连接池”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
为了提高Mysql数据库的访问瓶颈,常用的方法有如下两个:
增加连接池,来提高MYsql Server的访问效率,在高并发的情况下,每一个用户大量的TCP三次握手。Mysql Server的连接认证,Mysql Server关闭连接回收资源和TCP四次挥手所耗费的性能时间也是明显的,增加连接池就是为了减少这一部分的性能损耗。
注:常见的MySQL、Oracle、SQLServer等数据库都是基于C/S架构设计的。
市面上主流的Mysql数据库连接池,对于短时间内的大量增删改查操作的性能提升很明显,但大多数都是Java实现的,该项目的开展就是为了提高Mysql Server的访问效率,实现基于C++代码的数据库连接池模块。
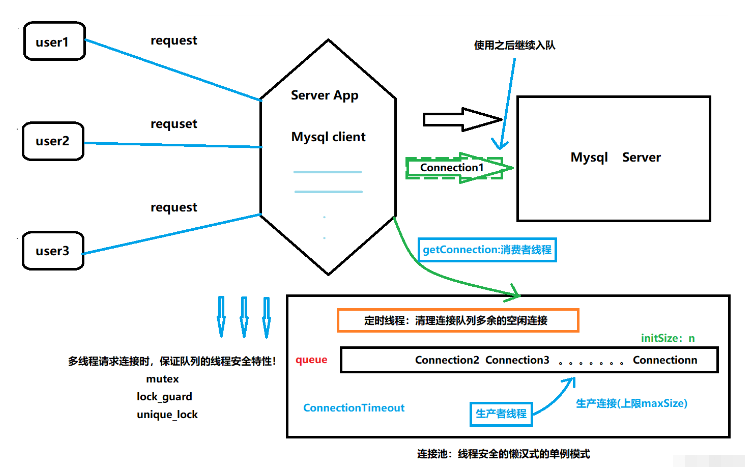
针对于系统启动时就创建一定数量的连接,用户一旦执行CURD操作,直接拿出一条连接即可,不需要TCP的连接过程和资源回收过程,使用完该连接后归还给连接池的连接队列,供之后使用。
连接池一般包含了数据库连接所用的ip地址、port端口号、username用户名、password密码以及其他一些性能参数:比如初始连接量、最大连接量、最大空闲时间、连接超时时间等
本项目重点实现上述通用功能:
初始连接量表示连接池事先会和MySQL Server创建的initSize数量的Connection连接。在完成初始连接量之后,当应用发起MySQL访问时,不用创建新的MySQLServer连接,而是从连接池中直接获取一个连接,当使用完成后,再把连接归还到连接池中。
当并发访问MySQL Server的请求增加,初始连接量不够用了,此时会增加连接量,但是增加的连接量的上限就是maxSIze。因为每一个连接都会占用一个socket资源,一般连接池和服务器都是部署在一台主机上,如果连接池的连接数量过多,那么服务器就不能响应太多的客户端请求了。
当高并发过去,因为高并发而新创建的连接在很长时间(maxIdleTime)内没有得到使用,那么这些新创建的连接处于空闲,并且占用着一定的资源,这个时候就需要将其释放掉,最终只用保存iniSize个连接就行。
当MySQL的并发访问请求量过大,连接池中的连接数量已经达到了maxSize,并且此时连接池中没有可以使用的连接,那么此时应用阻塞connectionTimeOut的时间,如果此时间内有使用完的连接归还到连接池,那么他就可以使用,如果超过这个时间还是没有连接,那么它获取数据库连接池失败,无法访问数据库。
连接池只需要一个实例,所以ConnectionPool以单例`模式设计;
从ConnectionPool中可以获取和Mysql的连接Connection;
空闲连接Connection全部维护在一个线程安全的Connection队列中,使用线程互斥锁保证队列的线程安;
如果Connection队列为空,还需要再获取连接,此时需要动态创建连接,上限数量是maxSize;
队列中空闲连接时间超过maxIdleTime的就会被释放掉,只保留初始的initSize个连接就可以了,这个功能点肯定要放在独立的线程中去做;
如果Connection队列为空,而此时连接的数量已达上限maxSize,那么等待ConnectionTimeout时间还获取不到空闲的连接,那么获取连接失败,此处从Connection队列获取空闲连接,可以使用带超时时间的mutex互斥锁来实现连接超时时间;
用户获取的连接用shared_ptr智能指针来管理,用lambda表达式定制连接释放的功能(不真正释放连接,而是把连接归还到连接池中);
连接的生产和连接的消费采用生产者-消费者线程模型来设计,使用了线程间的同步通信机制条件变量和互斥锁。
图示如下:
目的:在C++下输入Sql语句对数据库进行操作的代码封装
说明:这里的MYSQL的数据库编程直接采用oracle公司提供的C++客户端开发包 , 读者可以自己查阅资料或搜索官方文档自行学习相关API的使用方法。
Connection.h:
class Connection
{
public:
// 初始化数据库连接
Connection();
// 释放数据库连接资源
~Connection();
// 连接数据库
bool connect(string ip,
unsigned short port,
string user,
string password,
string dbname);
// 更新操作 insert、delete、update
bool update(string sql);
// 查询操作 select
MYSQL_RES* query(string sql);
// 刷新一下连接的起始的空闲时间点
void refreshAliveTime() { _alivetime = clock(); }
// 返回存活的时间
clock_t getAliveeTime()const { return clock() - _alivetime; }
private:
MYSQL* _conn; // 表示和MySQL Server的一条连接
clock_t _alivetime; // 记录进入空闲状态后的起始存活时间
};Connection.cpp:
Connection::Connection()
{
// 初始化数据库连接
_conn = mysql_init(nullptr);
}
Connection::~Connection()
{
// 释放数据库连接资源
if (_conn != nullptr)
mysql_close(_conn);
}
bool Connection::connect(string ip, unsigned short port,
string username, string password, string dbname)
{
// 连接数据库
MYSQL* p = mysql_real_connect(_conn, ip.c_str(), username.c_str(),
password.c_str(), dbname.c_str(), port, nullptr, 0);
return p != nullptr;
}
bool Connection::update(string sql)
{
// 更新操作 insert、delete、update
if (mysql_query(_conn, sql.c_str()))
{
LOG("更新失败:" + sql);
return false;
}
return true;
}
MYSQL_RES* Connection::query(string sql)
{
// 查询操作 select
if (mysql_query(_conn, sql.c_str()))
{
LOG("查询失败:" + sql);
return nullptr;
}
return mysql_use_result(_conn);
}这里需要说明的是:在Windows上使用数据库需要进行相关配置
大致配置内容如下:
右键项目- C/C++ - 常规 -附加包含目录 - 增加mysql.h的头文件路径;
右键项目 - 链接器 - 常规 - 附加库目录 - 填写libmysql.lib的路径;
右键项目 - 链接器 - 输入 - 附加依赖项 - 填写libmysql.lib的路径;
把libmysql.dll的动态链接库(Linux下后缀名是.so库)放在工程目录下。
连接池仅需要一个实例,同时服务器肯定是多线程的,必须保证线程安全,所以采用懒汉式线程安全的单例:
CommonConnectionPool.h: 部分代码
class ConnectionPool
{
public:
// 获取连接池对象实例
static ConnectionPool* getConnectionPool();
// 给外部提供接口,从连接池中获取一个可用的空闲连接
shared_ptr<Connection> getConnection();
private:
// 单例#1 构造函数私有化
ConnectionPool();
};CommonConnectionPool.cpp: 部分代码
// 线程安全的懒汉单例函数接口
ConnectionPool* ConnectionPool::getConnectionPool()
{
static ConnectionPool pool; //静态对象初始化由编译器自动进行lock和unlock
return &pool;
}连接池的数据结构是queue队列,最早生成的连接connection放在队头,此时记录一个起始时间,这一点在后面最大空闲时间时会发挥作用:如果队头都没有超过最大空闲时间,那么其他的一定没有
CommonConnectionPool.cpp 的连接池构造函数:
// 连接池的构造
ConnectionPool::ConnectionPool()
{
// 加载配置项了
if (!loadConfigFile())
{
return;
}
// 创建初始数量的连接
for (int i = 0; i < _initSize; ++i)
{
Connection* p = new Connection();//创建一个新的连接
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // 刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}
}连接数量没有到达上限,继续创建新的连接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // 刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}扫描整个队列,释放多余的连接(高并发过后,新建的连接超过最大超时时间时)
unique_lock<mutex> lock(_queueMutex);
while (_connectionCnt > _initSize)
{
Connection* p = _connectionQue.front();
if (p->getAliveTime() >= (_maxIdleTime * 1000))
{
_connectionQue.pop();
_connectionCnt--;
// 调用~Connection()释放连接
delete p;
}
else
{
// 如果队头的连接没有超过_maxIdleTime,其他连接肯定没有
break;
}
}为了将多线程编程的相关操作应用到实际,也为了进行压力测试,用结果证明使用连接池之后对数据库的访问效率确实比不使用连接池的时候高很多,使用了多线程来进行数据库的访问操作,并且观察多线程下连接池对于性能的提升。
代码如下:
int main()
{
thread t1([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t2([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t3([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t4([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "male");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}连接池中连接队列的连接的生产和消费需要保证其线程安全,于是我们需要引入互斥锁mutex,线程同步通信确保执行顺序,以及唯一锁。
代码如下:
class ConnectionPool
{
private:
// 设置条件变量,用于连接生产线程和连接消费线程的通信
condition_variable cv;
// 维护连接队列的线程安全互斥锁
mutex _queueMutex;
};
for (;;)
{
unique_lock<mutex> lock(_queueMutex);
while (!_connectionQue.empty())
{
// 队列不为空,此处生产线程进入等待状态
cv.wait(lock);
}
// 连接数量没有达到上限,继续创建新的连接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
// 刷新一下开始空闲的起始时间
p->refreshAliveTime();
_connectionQue.push(p);
_connectionCnt++;
}
// 通知消费者线程,可以消费连接了
cv.notify_all();
}// 启动一个新的线程,作为连接的生产者 linux thread => pthread_create thread produce(std::bind(&ConnectionPool::produceConnectionTask, this)); produce.detach(); // 启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行对于的连接回收 thread scanner(std::bind(&ConnectionPool::scannerConnectionTask, this)); scanner.detach();
对于连接池内的连接数量,生产者和消费者线程都会去改变其值,那么这个变量的修改就必须保证其原子性,于是使用C++11中提供的原子类:atomic_int
atomic_int _connectionCnt; // 记录连接所创建的connection连接的总数量 // 生产新连接时: _connectionCnt++; // 当新连接超过最大超时时间后被销毁时 _connectionCnt--;
对于使用完成的连接,不能直接销毁该连接,而是需要将该连接归还给连接池的队列,供之后的其他消费者使用,于是我们使用智能指针,自定义其析构函数,完成放回的操作:
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon) {
// 这里是在服务器应用线程中调用的,所以一定要考虑队列的线程安全操作
unique_lock<mutex> lock(_queueMutex);
pcon->refreshAliveTime();
_connectionQue.push(pcon);
});测试添加连接池后效率是否提升:
未使用连接池
单线程
int main()
{
clock_t begin = clock();
for (int i = 0; i < 1000; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
}运行时间如下:

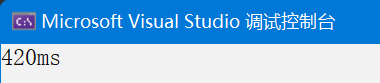
多线程
int main()
{
Connection conn;
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
clock_t begin = clock();
thread t1([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t2([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t3([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t4([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
}运行时间如下:
使用连接池
单线程
int main()
{
clock_t begin = clock();
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 1000; ++i)
{
shared_ptr<Connection> sp = cp->getConnection();
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
sp->update(sql);
}
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
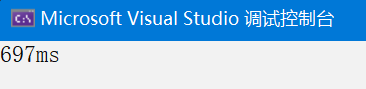
}运行时间如下
多线程
int main()
{
clock_t begin = clock();
thread t1([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t2([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t3([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t4([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
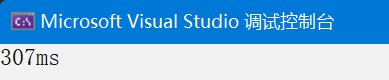
}
比较
在使用了连接池之后,性能确实提升了不少
数据量1000,单线程从1417ms变成697ms
数据量1000,多线程从420ms变成了307ms
读到这里,这篇“C++怎么实现数据库连接池”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





