еҰӮдҪ•з”ЁscrapyжЎҶжһ¶зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№Ұзұ»дҝЎжҒҜ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңеҰӮдҪ•з”ЁscrapyжЎҶжһ¶зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№Ұзұ»дҝЎжҒҜвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңеҰӮдҪ•з”ЁscrapyжЎҶжһ¶зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№Ұзұ»дҝЎжҒҜвҖқеҗ§пјҒ
е®үиЈ…ж–№жі•пјҡWindowsпјҡеңЁз»Ҳз«Ҝиҫ“е…Ҙе‘Ҫд»Өпјҡpip install scrapyпјӣmacпјҡеңЁз»Ҳз«Ҝиҫ“е…Ҙе‘Ҫд»Өпјҡpip3 install scrapyпјҢжҢүдёӢenterй”®,еҶҚиҫ“е…Ҙcd PythonпјҢе°ұиғҪи·іиҪ¬еҲ°Pythonж–Ү件еӨ№гҖӮжҺҘзқҖиҫ“е…Ҙcd PythoncodeпјҢе°ұиғҪи·іиҪ¬еҲ°Pythonж–Ү件еӨ№йҮҢзҡ„Pythoncodeеӯҗж–Ү件еӨ№гҖӮжңҖеҗҺиҫ“е…ҘдёҖиЎҢиғҪеё®жҲ‘们еҲӣе»әScrapyйЎ№зӣ®зҡ„е‘Ҫд»Өпјҡscrapy startproject doubanпјҢdoubanе°ұжҳҜScrapyйЎ№зӣ®зҡ„еҗҚеӯ—гҖӮжҢүдёӢenterй”®пјҢдёҖдёӘScrapyйЎ№зӣ®е°ұеҲӣе»әжҲҗеҠҹдәҶгҖӮ
йЎ№зӣ®зӣ®ж Ү:
зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№ҰеҗҚ,еҮәзүҲдҝЎжҒҜе’ҢиҜ„еҲҶ
зӣ®ж Үurlдёә:https://book.douban.com/top250?start=0
ж•ҙдёӘscrapyйЎ№зӣ®зҡ„з»“жһ„пјҢеҰӮдёӢеӣҫ
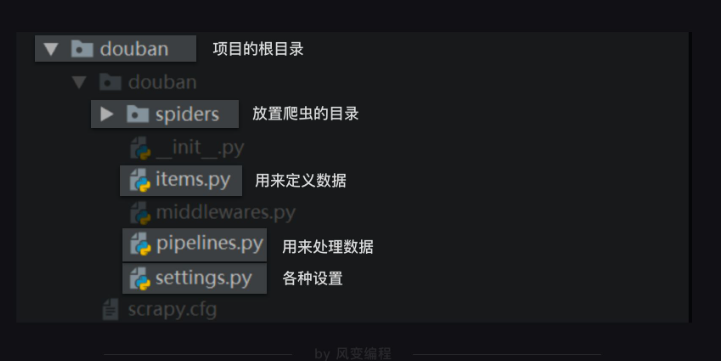
spidersжҳҜж”ҫзҪ®зҲ¬иҷ«зҡ„зӣ®еҪ•гҖӮжҲ‘们еңЁspidersиҝҷдёӘж–Ү件еӨ№йҮҢеҲӣе»әзҲ¬иҷ«ж–Ү件,жҲ‘们жҠҠиҝҷдёӘж–Ү件е‘ҪеҗҚдёәtop250,еӨ§йғЁеҲҶд»Јз ҒйғҪйңҖиҰҒеңЁиҝҷдёӘtop250.pyж–Ү件йҮҢзј–еҶҷгҖӮеңЁtop250.pyж–Ү件йҮҢеҜје…ҘжҲ‘们йңҖиҰҒзҡ„жЁЎеқ—:import scrapy , bs4
еҜје…ҘscrapyжҳҜжҲ‘们иҰҒз”ЁеҲӣе»әзұ»зҡ„ж–№ејҸеҶҷиҝҷдёӘзҲ¬иҷ«пјҢжҲ‘们жүҖеҲӣе»әзҡ„зұ»е°ҶзӣҙжҺҘ继жүҝscrapyдёӯзҡ„scrapy.Spiderзұ»гҖӮиҝҷж ·пјҢжңүи®ёеӨҡеҘҪз”ЁеұһжҖ§е’Ңж–№жі•пјҢе°ұиғҪеӨҹзӣҙжҺҘдҪҝз”ЁгҖӮ
еңЁScrapyдёӯпјҢжҜҸдёӘзҲ¬иҷ«зҡ„д»Јз Ғз»“жһ„еҹәжң¬йғҪеҰӮдёӢжүҖзӨәпјҡ
class DoubanSpider(scrapy.Spider): #е®ҡд№үдёҖдёӘзҲ¬иҷ«зұ»DoubanSpider,DoubanSpiderзұ»з»§жүҝиҮӘscrapy.Spiderзұ»гҖӮ
name = 'douban' #е®ҡд№үзҲ¬иҷ«зҡ„еҗҚеӯ—пјҢиҝҷдёӘеҗҚеӯ—жҳҜзҲ¬иҷ«зҡ„е”ҜдёҖж ҮиҜҶгҖӮ
allowed_domains = ['book.douban.com']#е®ҡд№үе…Ғи®ёзҲ¬иҷ«зҲ¬еҸ–зҡ„зҪ‘еқҖеҹҹеҗҚпјҲдёҚйңҖиҰҒеҠ https://пјүгҖӮеҰӮжһңзҪ‘еқҖзҡ„еҹҹеҗҚдёҚеңЁиҝҷдёӘеҲ—иЎЁйҮҢпјҢе°ұдјҡиў«иҝҮж»ӨжҺүгҖӮallowed_domainsе°ұйҷҗеҲ¶дәҶпјҢжҲ‘们иҝҷз§Қе…іиҒ”зҲ¬еҸ–зҡ„URLпјҢдёҖе®ҡеңЁbook.douban.comиҝҷдёӘеҹҹеҗҚд№ӢдёӢпјҢдёҚдјҡи·іиҪ¬еҲ°жҹҗдёӘеҘҮжҖӘзҡ„е№ҝе‘ҠйЎөйқўгҖӮ
start_urls = ['https://book.douban.com/top250?start=0']#е®ҡд№үиө·е§ӢзҪ‘еқҖпјҢе°ұжҳҜзҲ¬иҷ«д»Һе“ӘдёӘзҪ‘еқҖејҖе§ӢжҠ“еҸ–
def parse(self, response):#parseжҳҜScrapyйҮҢй»ҳи®ӨеӨ„зҗҶresponseзҡ„дёҖдёӘж–№жі•пјҢдёӯж–ҮжҳҜи§ЈжһҗгҖӮ
print(response.text)
#иҝҷйҮҢжҲ‘们并дёҚйңҖиҰҒеҶҷзұ»дјјrequests.get()зҡ„иҜӯеҸҘ,scrapyжЎҶжһ¶дјҡдёәжҲ‘们代еҠіеҒҡиҝҷ件дәӢпјҢеҶҷеҘҪдҪ зҡ„иҜ·жұӮпјҢжҺҘдёӢжқҘдҪ е°ұеҸҜд»ҘзӣҙжҺҘеҶҷеҜ№е“Қеә”еҰӮдҪ•еҒҡеӨ„зҗҶ
жҜҸдёҖж¬ЎпјҢеҪ“ж•°жҚ®е®ҢжҲҗи®°еҪ•пјҢе®ғдјҡзҰ»ејҖspidersпјҢжқҘеҲ°Scrapy EngineпјҲеј•ж“ҺпјүпјҢеј•ж“Һе°Ҷе®ғйҖҒе…ҘItem PipelineпјҲж•°жҚ®з®ЎйҒ“пјүеӨ„зҗҶгҖӮе®ҡд№үиҝҷдёӘзұ»зҡ„pyж–Ү件пјҢжӯЈжҳҜitems.pyгҖӮ
еҰӮжһңиҰҒзҲ¬еҸ–иұҶз“ЈиҜ»д№Ұзҡ„д№ҰеҗҚгҖҒеҮәзүҲдҝЎжҒҜе’ҢиҜ„еҲҶпјҢзӨәдҫӢ:
еңЁitems.pyйҮҢеҰӮдҪ•е®ҡд№үж•°жҚ®:
import scrapy
#еҜје…Ҙscrapy
class DoubanItem(scrapy.Item):
#е®ҡд№үдёҖдёӘзұ»DoubanItemпјҢе®ғ继жүҝиҮӘscrapy.Item
title = scrapy.Field()
#е®ҡд№үд№ҰеҗҚзҡ„ж•°жҚ®еұһжҖ§
publish = scrapy.Field()
#е®ҡд№үеҮәзүҲдҝЎжҒҜзҡ„ж•°жҚ®еұһжҖ§
score = scrapy.Field()
#е®ҡд№үиҜ„еҲҶзҡ„ж•°жҚ®еұһжҖ§
scrapy.Field()иҝҷиЎҢд»Јз Ғе®һзҺ°зҡ„жҳҜпјҢи®©ж•°жҚ®иғҪд»Ҙзұ»дјјеӯ—е…ёзҡ„еҪўејҸи®°еҪ•,е®ғиҫ“еҮәзҡ„з»“жһңйқһеёёеғҸеӯ—е…ёпјҢдҪҶе®ғеҚҙ并дёҚжҳҜdictпјҢе®ғзҡ„ж•°жҚ®зұ»еһӢжҳҜжҲ‘们е®ҡд№үзҡ„DoubanItemпјҢеұһдәҺиҮӘе®ҡд№үзҡ„Pythonеӯ—е…ё.жҲ‘们еҲ©з”Ёзұ»дјјдёҠиҝ°д»Јз Ғзҡ„ж ·ејҸпјҢеҺ»йҮҚж–°еҶҷtop250.py
import scrapy
import bs4
from ..items import DoubanItem
# йңҖиҰҒеј•з”ЁDoubanItemпјҢе®ғеңЁitemsйҮҢйқўгҖӮеӣ дёәжҳҜitemsеңЁtop250.pyзҡ„дёҠдёҖзә§зӣ®еҪ•пјҢжүҖд»ҘиҰҒз”Ё..itemsпјҢиҝҷжҳҜдёҖдёӘеӣәе®ҡз”Ёжі•гҖӮ
class DoubanSpider(scrapy.Spider):
#е®ҡд№үдёҖдёӘзҲ¬иҷ«зұ»DoubanSpiderгҖӮ
name = 'douban'
#е®ҡд№үзҲ¬иҷ«зҡ„еҗҚеӯ—дёәdoubanгҖӮ
allowed_domains = ['book.douban.com']
#е®ҡд№үзҲ¬иҷ«зҲ¬еҸ–зҪ‘еқҖзҡ„еҹҹеҗҚгҖӮ
start_urls = []
#е®ҡд№үиө·е§ӢзҪ‘еқҖгҖӮ
for x in range(3):
url = 'https://book.douban.com/top250?start=' + str(x * 25)
start_urls.append(url)
#жҠҠиұҶз“ЈTop250еӣҫд№Ұзҡ„еүҚ3йЎөзҪ‘еқҖж·»еҠ иҝӣstart_urlsгҖӮ
def parse(self, response):
#parseжҳҜй»ҳи®ӨеӨ„зҗҶresponseзҡ„ж–№жі•гҖӮ
bs = bs4.BeautifulSoup(response.text,'html.parser')
#з”ЁBeautifulSoupи§ЈжһҗresponseгҖӮ
datas = bs.find_all('tr',class_="item")
#з”Ёfind_allжҸҗеҸ–<tr class="item">е…ғзҙ пјҢиҝҷдёӘе…ғзҙ йҮҢеҗ«жңүд№ҰзұҚдҝЎжҒҜгҖӮ
for data in datas:
#йҒҚеҺҶdataгҖӮ
item = DoubanItem()
#е®һдҫӢеҢ–DoubanItemиҝҷдёӘзұ»гҖӮ
item['title'] = data.find_all('a')[1]['title']
#жҸҗеҸ–еҮәд№ҰеҗҚпјҢ并жҠҠиҝҷдёӘж•°жҚ®ж”ҫеӣһDoubanItemзұ»зҡ„titleеұһжҖ§йҮҢгҖӮ
item['publish'] = data.find('p',class_='pl').text
#жҸҗеҸ–еҮәеҮәзүҲдҝЎжҒҜпјҢ并жҠҠиҝҷдёӘж•°жҚ®ж”ҫеӣһDoubanItemзұ»зҡ„publishйҮҢгҖӮ
item['score'] = data.find('span',class_='rating_nums').text
#жҸҗеҸ–еҮәиҜ„еҲҶпјҢ并жҠҠиҝҷдёӘж•°жҚ®ж”ҫеӣһDoubanItemзұ»зҡ„scoreеұһжҖ§йҮҢгҖӮ
print(item['title'])
#жү“еҚ°д№ҰеҗҚгҖӮ
yield item
#yield itemжҳҜжҠҠиҺ·еҫ—зҡ„itemдј йҖ’з»ҷеј•ж“ҺгҖӮеҪ“жҲ‘们жҜҸдёҖж¬ЎпјҢиҰҒи®°еҪ•ж•°жҚ®зҡ„ж—¶еҖҷпјҢжҜ”еҰӮеүҚйқўеңЁжҜҸдёҖдёӘжңҖе°ҸеҫӘзҺҜйҮҢпјҢйғҪиҰҒи®°еҪ•вҖңд№ҰеҗҚвҖқпјҢвҖңеҮәзүҲдҝЎжҒҜвҖқпјҢвҖңиҜ„еҲҶвҖқгҖӮжҲ‘们дјҡе®һдҫӢеҢ–дёҖдёӘitemеҜ№иұЎпјҢеҲ©з”ЁиҝҷдёӘеҜ№иұЎжқҘи®°еҪ•ж•°жҚ®гҖӮ
жҜҸдёҖж¬ЎпјҢеҪ“ж•°жҚ®е®ҢжҲҗи®°еҪ•пјҢе®ғдјҡзҰ»ејҖspidersпјҢжқҘеҲ°Scrapy EngineпјҲеј•ж“ҺпјүпјҢеј•ж“Һе°Ҷе®ғйҖҒе…ҘItem PipelineпјҲж•°жҚ®з®ЎйҒ“пјүеӨ„зҗҶгҖӮиҝҷйҮҢпјҢиҰҒз”ЁеҲ°yieldиҜӯеҸҘгҖӮ
yieldиҜӯеҸҘе®ғжңүзӮ№зұ»дјјreturnпјҢдёҚиҝҮе®ғе’ҢreturnдёҚеҗҢзҡ„зӮ№еңЁдәҺпјҢе®ғдёҚдјҡз»“жқҹеҮҪж•°пјҢдё”иғҪеӨҡж¬Ўиҝ”еӣһдҝЎжҒҜгҖӮ
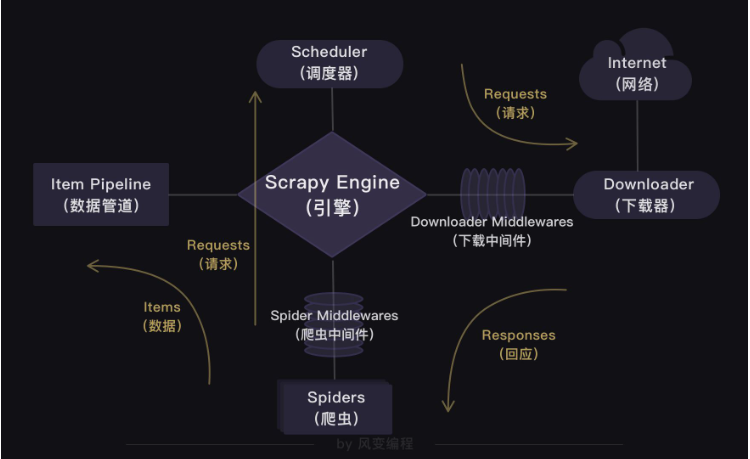
е°ұеҰӮеҗҢдёҠеӣҫжүҖзӨәпјҡзҲ¬иҷ«пјҲSpidersпјүдјҡжҠҠиұҶз“Јзҡ„10дёӘзҪ‘еқҖе°ҒиЈ…жҲҗrequestsеҜ№иұЎпјҢеј•ж“Һдјҡд»ҺзҲ¬иҷ«пјҲSpidersпјүйҮҢжҸҗеҸ–еҮәrequestsеҜ№иұЎпјҢеҶҚдәӨз»ҷи°ғеәҰеҷЁпјҲSchedulerпјүпјҢи®©и°ғеәҰеҷЁжҠҠиҝҷдәӣrequestsеҜ№иұЎжҺ’еәҸеӨ„зҗҶгҖӮ然еҗҺеј•ж“ҺеҶҚжҠҠз»ҸиҝҮи°ғеәҰеҷЁеӨ„зҗҶзҡ„requestsеҜ№иұЎеҸ‘з»ҷдёӢиҪҪеҷЁпјҲDownloaderпјүпјҢдёӢиҪҪеҷЁдјҡз«Ӣ马жҢүз…§еј•ж“Һзҡ„е‘Ҫд»ӨзҲ¬еҸ–пјҢ并жҠҠresponseиҝ”еӣһз»ҷеј•ж“ҺгҖӮ
зҙ§жҺҘзқҖеј•ж“Һе°ұдјҡжҠҠresponseеҸ‘еӣһз»ҷзҲ¬иҷ«пјҲSpidersпјүпјҢиҝҷж—¶зҲ¬иҷ«дјҡеҗҜеҠЁй»ҳи®Өзҡ„еӨ„зҗҶresponseзҡ„parseж–№жі•пјҢи§Јжһҗе’ҢжҸҗеҸ–еҮәд№ҰзұҚдҝЎжҒҜзҡ„ж•°жҚ®пјҢдҪҝз”ЁitemеҒҡи®°еҪ•пјҢиҝ”еӣһз»ҷеј•ж“ҺгҖӮеј•ж“Һе°Ҷе®ғйҖҒе…ҘItem PipelineпјҲж•°жҚ®з®ЎйҒ“пјүеӨ„зҗҶгҖӮ
д»Јз Ғе®һж“Қ——и®ҫзҪ®
зӮ№еҮ»settings.pyж–Ү件пјҢжҠҠUSER _AGENTзҡ„жіЁйҮҠеҸ–ж¶ҲпјҲеҲ йҷӨ#пјүпјҢ然еҗҺжӣҝжҚўжҺүuser-agentзҡ„еҶ…е®№пјҢе°ұжҳҜдҝ®ж”№дәҶиҜ·жұӮеӨҙгҖӮ
еӣ дёәScrapyжҳҜйҒөе®ҲrobotsеҚҸи®®зҡ„пјҢеҰӮжһңжҳҜrobotsеҚҸи®®зҰҒжӯўзҲ¬еҸ–зҡ„еҶ…е®№пјҢScrapyд№ҹдјҡй»ҳи®ӨдёҚеҺ»зҲ¬еҸ–пјҢжүҖд»Ҙдҝ®ж”№Scrapyдёӯзҡ„й»ҳи®Өи®ҫзҪ®гҖӮжҠҠROBOTSTXT_OBEY=Trueж”№жҲҗROBOTSTXT_OBEY=FalseпјҢе°ұжҳҜжҠҠйҒөе®ҲrobotsеҚҸи®®жҚўжҲҗж— йңҖйҒөд»ҺrobotsеҚҸи®®пјҢиҝҷж ·Scrapyе°ұиғҪдёҚеҸ—йҷҗеҲ¶ең°иҝҗиЎҢгҖӮ
1.
жғіиҰҒиҝҗиЎҢScrapyжңүдёӨз§Қж–№жі•пјҢдёҖз§ҚжҳҜеңЁжң¬ең°з”өи„‘зҡ„з»Ҳз«Ҝи·іиҪ¬еҲ°scrapyйЎ№зӣ®зҡ„ж–Ү件еӨ№
пјҲи·іиҪ¬ж–№жі•пјҡcd+ж–Ү件еӨ№зҡ„и·Ҝеҫ„еҗҚеҰӮпјҡ
cd D:\python\Pythoncode\douban\doubanпјү
然еҗҺиҫ“е…Ҙе‘Ҫд»ӨиЎҢпјҡscrapy crawl doubanпјҲdouban е°ұжҳҜжҲ‘们зҲ¬иҷ«зҡ„еҗҚеӯ—пјүгҖӮпјү
2.
еҸҰдёҖз§ҚиҝҗиЎҢж–№ејҸйңҖиҰҒжҲ‘们еңЁжңҖеӨ–еұӮзҡ„еӨ§ж–Ү件еӨ№йҮҢж–°е»әдёҖдёӘmain.pyж–Ү件пјҲдёҺscrapy.cfgеҗҢзә§пјүгҖӮ
然еҗҺеңЁиҝҷдёӘmain.pyж–Ү件йҮҢпјҢиҫ“е…Ҙд»ҘдёӢд»Јз ҒпјҢзӮ№еҮ»иҝҗиЎҢпјҢScrapyзҡ„зЁӢеәҸе°ұдјҡеҗҜеҠЁгҖӮ
from scrapy import cmdline
#еҜје…ҘcmdlineжЁЎеқ—,еҸҜд»Ҙе®һзҺ°жҺ§еҲ¶з»Ҳз«Ҝе‘Ҫд»ӨиЎҢгҖӮ
cmdline.execute(['scrapy','crawl','douban'])
#з”ЁexecuteпјҲпјүж–№жі•пјҢиҫ“е…ҘиҝҗиЎҢscrapyзҡ„е‘Ҫд»ӨгҖӮ
第1иЎҢд»Јз ҒпјҡеңЁScrapyдёӯжңүдёҖдёӘеҸҜд»ҘжҺ§еҲ¶з»Ҳз«Ҝе‘Ҫд»Өзҡ„жЁЎеқ—cmdlineгҖӮеҜје…ҘдәҶиҝҷдёӘжЁЎеқ—пјҢжҲ‘们е°ұиғҪж“ҚжҺ§з»Ҳз«ҜгҖӮ
第2иЎҢд»Јз ҒпјҡеңЁcmdlineжЁЎеқ—дёӯпјҢжңүдёҖдёӘexecuteж–№жі•иғҪжү§иЎҢз»Ҳз«Ҝзҡ„е‘Ҫд»ӨиЎҢпјҢдёҚиҝҮиҝҷдёӘж–№жі•йңҖиҰҒдј е…ҘеҲ—иЎЁзҡ„еҸӮж•°гҖӮжҲ‘们жғіиҫ“е…ҘиҝҗиЎҢScrapyзҡ„д»Јз Ғscrapy crawl doubanпјҢе°ұйңҖиҰҒеҶҷжҲҗ[‘scrapy’,‘crawl’,‘douban’]иҝҷж ·гҖӮ
еңЁе®һйҷ…йЎ№зӣ®е®һжҲҳдёӯпјҢжҲ‘们еә”иҜҘе…Ҳе®ҡд№үж•°жҚ®пјҢеҶҚеҶҷзҲ¬иҷ«гҖӮжүҖд»ҘпјҢжөҒзЁӢеӣҫеә”еҰӮдёӢпјҡ
жңҖеҗҺпјҢеӯҳеӮЁж•°жҚ®йңҖиҰҒдҝ®ж”№pipelines.pyж–Ү件
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңеҰӮдҪ•з”ЁscrapyжЎҶжһ¶зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№Ұзұ»дҝЎжҒҜвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№еҰӮдҪ•з”ЁscrapyжЎҶжһ¶зҲ¬еҸ–иұҶз“ЈиҜ»д№ҰTop250зҡ„д№Ұзұ»дҝЎжҒҜиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





