linuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁд»Җд№Ҳж–Ү件дёӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶlinuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁд»Җд№Ҳж–Ү件дёӢзҡ„зӣёе…ізҹҘиҜҶпјҢеҶ…е®№иҜҰз»Ҷжҳ“жҮӮпјҢж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮlinuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁд»Җд№Ҳж–Ү件дёӢж–Үз« йғҪдјҡжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
linuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁ/usr/src/linuxзӣ®еҪ•дёӢгҖӮеҶ…ж ёжәҗд»Јз Ғзҡ„з»„жҲҗпјҡ1гҖҒarchзӣ®еҪ•пјҢеҢ…еҗ«дәҶжӯӨж ёеҝғжәҗд»Јз ҒжүҖж”ҜжҢҒзҡ„硬件дҪ“зі»з»“жһ„зӣёе…ізҡ„ж ёеҝғд»Јз Ғпјӣ2гҖҒincludeзӣ®еҪ•пјҢеҢ…жӢ¬дәҶж ёеҝғзҡ„еӨ§еӨҡж•°includeж–Ү件пјӣ3гҖҒinitзӣ®еҪ•пјҢеҢ…еҗ«ж ёеҝғеҗҜеҠЁд»Јз Ғпјӣ4гҖҒmmзӣ®еҪ•пјҢеҢ…еҗ«жүҖжңүзҡ„еҶ…еӯҳз®ЎзҗҶд»Јз Ғпјӣ5гҖҒdriversзӣ®еҪ•пјҢеҢ…еҗ«зі»з»ҹдёӯжүҖжңүзҡ„и®ҫеӨҮй©ұеҠЁпјӣ6гҖҒIpcзӣ®еҪ•пјҢеҢ…еҗ«ж ёеҝғзҡ„иҝӣзЁӢй—ҙйҖҡи®Ҝд»Јз ҒгҖӮ
linuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁе“ӘйҮҢ
Linuxзҡ„еҶ…ж ёжәҗд»Јз ҒеҸҜд»Ҙд»ҺеҫҲеӨҡйҖ”еҫ„еҫ—еҲ°гҖӮдёҖиҲ¬жқҘи®ІпјҢеңЁе®үиЈ…зҡ„linuxзі»з»ҹдёӢпјҢ/usr/src/linuxзӣ®еҪ•дёӢзҡ„дёңиҘҝе°ұжҳҜеҶ…ж ёжәҗд»Јз ҒгҖӮ
еҜ№дәҺжәҗд»Јз Ғзҡ„йҳ…иҜ»пјҢиҰҒжғіжҜ”иҫғйЎәеҲ©пјҢдәӢе…ҲжңҖеҘҪеҜ№жәҗд»Јз Ғзҡ„зҹҘиҜҶиғҢжҷҜжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
LinuxеҶ…ж ёжәҗд»Јз Ғзҡ„з»„жҲҗеҰӮдёӢ(еҒҮи®ҫзӣёеҜ№дәҺlinuxзӣ®еҪ•):
arch
иҝҷдёӘеӯҗзӣ®еҪ•еҢ…еҗ«дәҶжӯӨж ёеҝғжәҗд»Јз ҒжүҖж”ҜжҢҒзҡ„硬件дҪ“зі»з»“жһ„зӣёе…ізҡ„ж ёеҝғд»Јз ҒгҖӮеҰӮеҜ№дәҺX86е№іеҸ°е°ұжҳҜi386гҖӮ
include
иҝҷдёӘзӣ®еҪ•еҢ…жӢ¬дәҶж ёеҝғзҡ„еӨ§еӨҡж•°includeж–Ү件гҖӮеҸҰеӨ–еҜ№дәҺжҜҸз§Қж”ҜжҢҒзҡ„дҪ“зі»з»“жһ„еҲҶеҲ«жңүдёҖдёӘеӯҗзӣ®еҪ•гҖӮ
init
жӯӨзӣ®еҪ•еҢ…еҗ«ж ёеҝғеҗҜеҠЁд»Јз ҒгҖӮ
mm
жӯӨзӣ®еҪ•еҢ…еҗ«дәҶжүҖжңүзҡ„еҶ…еӯҳз®ЎзҗҶд»Јз ҒгҖӮдёҺе…·дҪ“硬件дҪ“зі»з»“жһ„зӣёе…ізҡ„еҶ…еӯҳз®ЎзҗҶд»Јз ҒдҪҚдәҺarch/*/mmзӣ®еҪ•дёӢпјҢеҰӮеҜ№еә”дәҺX86зҡ„е°ұжҳҜarch/i386/mm/fault.c гҖӮ
drivers
зі»з»ҹдёӯжүҖжңүзҡ„и®ҫеӨҮй©ұеҠЁйғҪдҪҚдәҺжӯӨзӣ®еҪ•дёӯгҖӮе®ғеҸҲиҝӣдёҖжӯҘеҲ’еҲҶжҲҗеҮ зұ»и®ҫеӨҮй©ұеҠЁпјҢжҜҸдёҖз§Қд№ҹжңүеҜ№еә”зҡ„еӯҗзӣ®еҪ•пјҢеҰӮеЈ°еҚЎзҡ„й©ұеҠЁеҜ№еә”дәҺdrivers/soundгҖӮ
Ipc
жӯӨзӣ®еҪ•еҢ…еҗ«дәҶж ёеҝғзҡ„иҝӣзЁӢй—ҙйҖҡи®Ҝд»Јз ҒгҖӮ
modules
жӯӨзӣ®еҪ•еҢ…еҗ«е·Іе»әеҘҪеҸҜеҠЁжҖҒеҠ иҪҪзҡ„жЁЎеқ—гҖӮ
fs Linux
ж”ҜжҢҒзҡ„ж–Ү件系з»ҹд»Јз ҒгҖӮдёҚеҗҢзҡ„ж–Ү件系з»ҹжңүдёҚеҗҢзҡ„еӯҗзӣ®еҪ•еҜ№еә”пјҢеҰӮext2ж–Ү件系з»ҹеҜ№еә”зҡ„е°ұжҳҜext2еӯҗзӣ®еҪ•гҖӮ
Kernel
дё»иҰҒж ёеҝғд»Јз ҒгҖӮеҗҢж—¶дёҺеӨ„зҗҶеҷЁз»“жһ„зӣёе…ід»Јз ҒйғҪж”ҫеңЁarch/*/kernelзӣ®еҪ•дёӢгҖӮ
Net
ж ёеҝғзҡ„зҪ‘з»ңйғЁеҲҶд»Јз ҒгҖӮйҮҢйқўзҡ„жҜҸдёӘеӯҗзӣ®еҪ•еҜ№еә”дәҺзҪ‘з»ңзҡ„дёҖдёӘж–№йқўгҖӮ
Lib
жӯӨзӣ®еҪ•еҢ…еҗ«дәҶж ёеҝғзҡ„еә“д»Јз ҒгҖӮдёҺеӨ„зҗҶеҷЁз»“жһ„зӣёе…іеә“д»Јз Ғиў«ж”ҫеңЁarch/*/lib/зӣ®еҪ•дёӢгҖӮ
Scripts
жӯӨзӣ®еҪ•еҢ…еҗ«з”ЁдәҺй…ҚзҪ®ж ёеҝғзҡ„и„ҡжң¬ж–Ү件гҖӮ
Documentation
жӯӨзӣ®еҪ•жҳҜдёҖдәӣж–ҮжЎЈпјҢиө·еҸӮиҖғдҪңз”ЁгҖӮ
Linux еҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•
1 еҶ…ж ёжәҗз Ғд№ӢжҳҺжҷ°
еҰӮжһңжғійҖҸжһҗLinuxпјҢж·ұе…Ҙж“ҚдҪңзі»з»ҹзҡ„жң¬иҙЁпјҢйҳ…иҜ»еҶ…ж ёжәҗз ҒжҳҜжңҖжңүж•Ҳзҡ„йҖ”еҫ„гҖӮжҲ‘们йғҪзҹҘйҒ“пјҢжғіжҲҗдёәдјҳз§Җзҡ„зЁӢеәҸе‘ҳпјҢйңҖиҰҒеӨ§йҮҸзҡ„е®һи·өе’Ңд»Јз Ғзҡ„зј–еҶҷгҖӮзј–зЁӢеӣә然йҮҚиҰҒпјҢдҪҶжҳҜеҫҖеҫҖеҸӘзј–зЁӢзҡ„дәәеҫҲе®№жҳ“жҠҠиҮӘе·ұеұҖйҷҗеңЁиҮӘе·ұзҡ„зҹҘиҜҶйўҶеҹҹеҶ…гҖӮеҰӮжһңиҰҒжү©еұ•иҮӘе·ұзҹҘиҜҶзҡ„е№ҝеәҰпјҢжҲ‘们йңҖиҰҒеӨҡжҺҘи§Ұе…¶д»–дәәзј–еҶҷзҡ„д»Јз ҒпјҢе°Өе…¶жҳҜж°ҙе№іжҜ”жҲ‘们жӣҙй«ҳзҡ„дәәзј–еҶҷзҡ„д»Јз ҒгҖӮйҖҡиҝҮиҝҷз§ҚйҖ”еҫ„пјҢжҲ‘们еҸҜд»Ҙи·іеҮәиҮӘе·ұзҹҘиҜҶеңҲзҡ„жқҹзјҡпјҢиҝӣе…Ҙд»–дәәзҡ„зҹҘиҜҶеңҲпјҢдәҶи§ЈжӣҙеӨҡз”ҡиҮіжҲ‘们дёҖиҲ¬зҹӯжңҹеҶ…ж— жі•дәҶи§ЈеҲ°зҡ„дҝЎжҒҜгҖӮLinuxеҶ…ж ёз”ұж— ж•°ејҖжәҗзӨҫеҢәзҡ„вҖңеӨ§зҘһ们вҖқзІҫеҝғз»ҙжҠӨпјҢиҝҷдәӣдәәйғҪеҸҜд»Ҙз§°еҫ—дёҠдёҖйЎ¶дёҖзҡ„д»Јз Ғй«ҳжүӢгҖӮйҖҸиҝҮйҳ…иҜ»LinuxеҶ…ж ёд»Јз Ғзҡ„ж–№ејҸпјҢжҲ‘们еӯҰд№ еҲ°зҡ„дёҚе…үжҳҜеҶ…ж ёзӣёе…ізҡ„зҹҘиҜҶпјҢеңЁжҲ‘зңӢжқҘжӣҙе…·д»·еҖјзҡ„жҳҜеӯҰд№ е’ҢдҪ“дјҡе®ғ们зҡ„зј–зЁӢжҠҖе·§д»ҘеҸҠеҜ№и®Ўз®—жңәзҡ„зҗҶи§ЈгҖӮ
жҲ‘д№ҹжҳҜйҖҡиҝҮдёҖдёӘйЎ№зӣ®жҺҘи§ҰдәҶLinuxеҶ…ж ёжәҗз Ғзҡ„еҲҶжһҗпјҢд»Һжәҗз Ғзҡ„еҲҶжһҗе·ҘдҪңдёӯпјҢжҲ‘еҸ—зӣҠйўҮеӨҡгҖӮйҷӨдәҶиҺ·еҸ–зӣёе…ізҡ„еҶ…ж ёзҹҘиҜҶеӨ–пјҢд№ҹж”№еҸҳдәҶжҲ‘еҜ№еҶ…ж ёд»Јз Ғзҡ„иҝҮеҫҖи®ӨзҹҘпјҡ
1пјҺеҶ…ж ёжәҗз Ғзҡ„еҲҶжһҗ并йқһвҖңй«ҳдёҚеҸҜж”ҖвҖқгҖӮеҶ…ж ёжәҗз ҒеҲҶжһҗзҡ„йҡҫеәҰдёҚеңЁдәҺжәҗз Ғжң¬иә«пјҢиҖҢеңЁдәҺеҰӮдҪ•дҪҝз”ЁжӣҙеҗҲйҖӮзҡ„еҲҶжһҗд»Јз Ғзҡ„ж–№ејҸе’ҢжүӢж®өгҖӮеҶ…ж ёзҡ„еәһеӨ§иҮҙдҪҝжҲ‘们дёҚиғҪжҢүз…§еҲҶжһҗдёҖиҲ¬зҡ„demoзЁӢеәҸйӮЈж ·д»Һдё»еҮҪж•°ејҖе§ӢжҢүйғЁе°ұзҸӯзҡ„еҲҶжһҗпјҢжҲ‘们йңҖиҰҒдёҖз§Қд»Һдёӯй—ҙд»Ӣе…Ҙзҡ„жүӢж®өеҜ№еҶ…ж ёжәҗз ҒвҖңеҗ„дёӘеҮ»з ҙвҖқгҖӮиҝҷз§ҚвҖңжҢүйңҖзҙўеҸ–вҖқзҡ„ж–№ејҸдҪҝеҫ—жҲ‘们еҸҜд»ҘжҠҠжҸЎжәҗз Ғзҡ„дё»зәҝпјҢиҖҢйқһиҝҮеәҰзә з»“дәҺе…·дҪ“зҡ„з»ҶиҠӮгҖӮ
2пјҺеҶ…ж ёзҡ„и®ҫи®ЎжҳҜдјҳзҫҺзҡ„гҖӮеҶ…ж ёзҡ„ең°дҪҚзҡ„зү№ж®ҠжҖ§еҶіе®ҡзқҖеҶ…ж ёзҡ„жү§иЎҢж•ҲзҺҮеҝ…йЎ»и¶іеӨҹй«ҳжүҚеҸҜд»Ҙе“Қеә”зӣ®еүҚи®Ўз®—жңәеә”з”Ёзҡ„е®һж—¶жҖ§иҰҒжұӮпјҢдёәжӯӨLinuxеҶ…ж ёдҪҝз”ЁCиҜӯиЁҖе’ҢжұҮзј–зҡ„ж··еҗҲзј–зЁӢгҖӮдҪҶжҳҜжҲ‘们йғҪзҹҘйҒ“иҪҜ件жү§иЎҢж•ҲзҺҮе’ҢиҪҜ件зҡ„еҸҜз»ҙжҠӨжҖ§еҫҲеӨҡжғ…еҶөдёӢжҳҜиғҢйҒ“иҖҢй©°зҡ„гҖӮеҰӮдҪ•еңЁдҝқиҜҒеҶ…ж ёй«ҳж•Ҳзҡ„еүҚжҸҗдёӢжҸҗй«ҳеҶ…ж ёзҡ„еҸҜз»ҙжҠӨжҖ§пјҢиҝҷйңҖиҰҒдҫқиө–дәҺеҶ…ж ёдёӯйӮЈдәӣвҖңдјҳзҫҺвҖқзҡ„и®ҫи®ЎгҖӮ
3пјҺзҘһеҘҮзҡ„зј–зЁӢжҠҖе·§гҖӮеңЁдёҖиҲ¬зҡ„еә”з”ЁиҪҜ件и®ҫи®ЎйўҶеҹҹпјҢзј–з Ғзҡ„ең°дҪҚеҸҜиғҪдёҚиў«иҝҮеәҰзҡ„йҮҚи§ҶпјҢеӣ дёәејҖеҸ‘иҖ…жӣҙжіЁйҮҚиҪҜ件зҡ„иүҜеҘҪи®ҫи®ЎпјҢиҖҢзј–з Ғд»…д»…жҳҜе®һзҺ°жүӢж®өй—®йўҳвҖ”вҖ”е°ұеғҸжӢҝж–§еӯҗеҠҲжҹҙдёҖж ·пјҢдёҚз”ЁеӨӘеӨҡзҡ„жҖқиҖғгҖӮдҪҶжҳҜиҝҷеңЁеҶ…ж ёдёӯ并дёҚжҲҗз«ӢпјҢеҘҪзҡ„зј–з Ғи®ҫи®ЎеёҰжқҘзҡ„дёҚе…үжҳҜеҸҜз»ҙжҠӨжҖ§зҡ„жҸҗй«ҳпјҢз”ҡиҮіжҳҜд»Јз ҒжҖ§иғҪзҡ„жҸҗеҚҮгҖӮ
жҜҸдёӘдәәеҜ№еҶ…ж ёзҡ„дәҶзҗҶи§ЈйғҪдјҡжңүжүҖдёҚеҗҢпјҢйҡҸзқҖжҲ‘们еҜ№еҶ…ж ёзҗҶи§Јзҡ„дёҚж–ӯеҠ ж·ұпјҢеҜ№е…¶и®ҫи®Ўе’Ңе®һзҺ°зҡ„жҖқжғідјҡжңүжӣҙеӨҡзҡ„жҖқиҖғе’ҢдҪ“дјҡгҖӮеӣ жӯӨжң¬ж–ҮжӣҙжңҹжңӣдәҺеј•еҜјжӣҙеӨҡеҫҳеҫҠеңЁLinuxеҶ…ж ёеӨ§й—Ёд№ӢеӨ–зҡ„дәәиҝӣе…ҘLinuxзҡ„дё–з•ҢпјҢеҺ»дәІиҮӘдҪ“дјҡеҶ…ж ёзҡ„зҘһеҘҮдёҺдјҹеӨ§гҖӮиҖҢжҲ‘д№ҹ并йқһеҶ…ж ёжәҗз Ғж–№йқўзҡ„专家пјҢиҝҷд№ҲеҒҡд№ҹеҸӘжҳҜеёҢжңӣеҲҶдә«жҲ‘иҮӘе·ұзҡ„еҲҶжһҗжәҗз Ғзҡ„з»ҸйӘҢе’Ңеҝғеҫ—пјҢдёәйӮЈдәӣйңҖиҰҒзҡ„дәәжҸҗдҫӣеҸӮиҖғе’Ңеё®еҠ©пјҢиҜҙзҡ„вҖңеҶ еҶ•е ӮзҡҮвҖқдёҖзӮ№пјҢд№ҹз®—жҳҜдёәи®Ўз®—жңәиҝҷдёӘиЎҢдёҡпјҢе°Өе…¶жҳҜеңЁж“ҚдҪңзі»з»ҹеҶ…ж ёж–№йқўиҙЎзҢ®иҮӘе·ұзҡ„дёҖд»Ҫз»өи–„д№ӢеҠӣгҖӮй—ІиҜқе°‘еҸҷпјҲе·Із»ҸзҪ—е—ҰдәҶеҫҲеӨҡдәҶпјҢеӣ§~пјүпјҢдёӢйқўжҲ‘е°ұжқҘеҲҶдә«дёҖдёӢиҮӘе·ұзҡ„LinixеҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•гҖӮ
2 еҶ…ж ёжәҗз Ғе®ғеҲ°еә•йҡҫдёҚйҡҫ
д»Һжң¬иҙЁдёҠи®ІпјҢеҲҶжһҗLinuxеҶ…ж ёд»Јз Ғе’ҢзңӢеҲ«дәәзҡ„д»Јз ҒжІЎжңүд»Җд№ҲдёӨж ·пјҢеӣ дёәж‘ҶеңЁдҪ йқўеүҚзҡ„дёҖиҲ¬йғҪдёҚжҳҜдҪ иҮӘе·ұеҶҷеҮәжқҘзҡ„д»Јз ҒгҖӮжҲ‘们е…ҲдёҫдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҢдёҖдёӘйҷҢз”ҹдәәйҡҸдҫҝз»ҷдҪ дёҖдёӘзЁӢеәҸпјҢ并иҰҒдҪ зңӢе®Ңжәҗз ҒеҗҺи®Іи§ЈдёҖдёӢзЁӢеәҸзҡ„еҠҹиғҪзҡ„и®ҫи®ЎпјҢжҲ‘жғіеҫҲеӨҡиҮӘжҲ‘ж„ҹи§үзј–зЁӢиғҪеҠӣиҝҳеҸҜд»Ҙзҡ„дәәиӮҜе®ҡи§үеҫ—иҝҷжІЎд»Җд№ҲпјҢеҸӘиҰҒжҲ‘иҖҗеҝғзҡ„жҠҠд»–зҡ„д»Јз Ғд»ҺеӨҙеҲ°е°ҫзңӢе®ҢпјҢиӮҜе®ҡиғҪжүҫеҲ°зӯ”жЎҲпјҢ并且дәӢе®һзЎ®е®һжҳҜеҰӮжӯӨгҖӮйӮЈд№ҲзҺ°еңЁжҚўдёҖдёӘеҒҮи®ҫпјҢеҰӮжһңиҝҷдёӘдәәжҳҜLinusпјҢз»ҷдҪ зҡ„е°ұжҳҜLinuxеҶ…ж ёзҡ„дёҖдёӘжЁЎеқ—зҡ„д»Јз ҒпјҢдҪ иҝҳдјҡи§үеҫ—дҫқ然йӮЈд№ҲиҪ»жқҫеҗ—пјҹдёҚе°‘дәәеҸҜиғҪдјҡжңүжүҖзҠ№иұ«гҖӮеҗҢж ·жҳҜйҷҢз”ҹдәәпјҲLinusиҰҒжҳҜи®ӨиҜҶдҪ зҡ„иҜқеҪ“然дёҚз®—пјҢе‘өе‘ө~пјүз»ҷдҪ зҡ„д»Јз ҒпјҢдёәд»Җд№Ҳз»ҷжҲ‘们зҡ„ж„ҹи§үеӨ§зӣёеҫ„еәӯе‘ўпјҹжҲ‘и§үеҫ—жңүд»ҘдёӢеҺҹеӣ пјҡ
1пјҺLinuxеҶ…ж ёд»Јз ҒеңЁвҖңеӨ–з•ҢвҖқзңӢжқҘеӨҡе°‘жңүдәӣзҘһз§ҳж„ҹпјҢиҖҢдё”е®ғеҫҲеәһеӨ§пјҢзҢӣең°ж‘ҶеңЁйқўеүҚеҸҜиғҪж„ҹи§үж— жі•дёӢжүӢгҖӮжҜ”еҰӮеҸҜиғҪжқҘжәҗдәҺдёҖдёӘеҫҲз»Ҷе°Ҹзҡ„еҺҹеӣ вҖ”вҖ”жүҫдёҚеҲ°mainеҮҪж•°гҖӮеҜ№дәҺз®ҖеҚ•зҡ„demoзЁӢеәҸпјҢжҲ‘们еҸҜд»Ҙд»ҺеӨҙиҮіе°ҫзҡ„еҲҶжһҗд»Јз Ғзҡ„еҗ«д№үпјҢдҪҶжҳҜеҲҶжһҗеҶ…ж ёд»Јз ҒиҝҷжӢӣе°ұеҪ»еә•еӨұж•ҲдәҶпјҢеӣ дёәжІЎжңүдәәиғҪжҠҠLinuxд»Јз Ғд»ҺеӨҙеҲ°е°ҫзңӢдёҠдёҖйҒҚпјҲеӣ дёәзЎ®е®һжІЎжңүеҝ…иҰҒпјҢз”ЁеҲ°ж—¶зңӢе°ұеҸҜд»ҘдәҶпјүгҖӮ
2пјҺдёҚе°‘дәәд№ҹжҺҘи§ҰиҝҮеӨ§еһӢиҪҜ件зҡ„д»Јз ҒпјҢдҪҶеӨҡж•°еұһдәҺеә”з”ЁеһӢйЎ№зӣ®пјҢд»Јз Ғзҡ„еҪўејҸе’Ңеҗ«д№үйғҪе’ҢиҮӘе·ұеёёжҺҘи§Ұзҡ„дёҡеҠЎйҖ»иҫ‘зӣёе…ігҖӮиҖҢеҶ…ж ёд»Јз ҒдёҚеҗҢпјҢе®ғеӨ„зҗҶзҡ„дҝЎжҒҜеӨҡж•°е’Ңи®Ўз®—жңәеә•еұӮеҜҶеҲҮзӣёе…ігҖӮжҜ”еҰӮж“ҚдҪңзі»з»ҹгҖҒзј–иҜ‘еҷЁгҖҒжұҮзј–гҖҒдҪ“зі»з»“жһ„зӯүзӣёе…ізҡ„зҹҘиҜҶзҡ„ж¬ зјәпјҢд№ҹдјҡи®©йҳ…иҜ»еҶ…ж ёд»Јз ҒйҡңзўҚйҮҚйҮҚгҖӮ
3пјҺеҲҶжһҗеҶ…ж ёд»Јз Ғзҡ„ж–№жі•дёҚеӨҹеҗҲзҗҶгҖӮйқўеҜ№еӨ§йҮҸзҡ„并且еӨҚжқӮзҡ„еҶ…ж ёд»Јз ҒпјҢеҰӮжһңдёҚд»Һе…ЁеұҖзҡ„и§’еәҰе…ҘжүӢпјҢеҫҲе®№жҳ“йҷ·е…Ҙд»Јз Ғз»ҶиҠӮзҡ„жіҘж·–дёӯгҖӮеҶ…ж ёд»Јз ҒиҷҪ然еәһеӨ§пјҢдҪҶжҳҜе®ғд№ҹжңүе®ғзҡ„и®ҫи®ЎеҺҹеҲҷе’Ңжһ¶жһ„пјҢеҗҰеҲҷз»ҙжҠӨе®ғеҜ№д»»дҪ•дәәжқҘиҜҙйғҪжҳҜдёҖдёӘеҷ©жўҰпјҒеҰӮжһңжҲ‘们зҗҶжё…д»Јз ҒжЁЎеқ—зҡ„ж•ҙдҪ“и®ҫи®ЎжҖқи·ҜпјҢеҶҚеҺ»еҲҶжһҗд»Јз Ғзҡ„е®һзҺ°пјҢеҸҜиғҪеҲҶжһҗжәҗз Ғе°ұжҳҜдёҖ件иҪ»жқҫеҝ«д№җзҡ„дәӢжғ…дәҶгҖӮ
й’ҲеҜ№иҝҷдәӣй—®йўҳпјҢжҲ‘дёӘдәәжҳҜиҝҷж ·зҗҶи§Јзҡ„гҖӮеҰӮжһңжІЎжңүжҺҘи§ҰиҝҮеӨ§еһӢиҪҜ件项зӣ®пјҢеҸҜиғҪеҲҶжһҗLinuxеҶ…ж ёд»Јз ҒжҳҜдёҖдёӘеҫҲеҘҪзҡ„з§ҜзҙҜеӨ§еһӢйЎ№зӣ®з»ҸйӘҢзҡ„жңәдјҡпјҲзЎ®е®һпјҢLinuxд»Јз ҒжҳҜжҲ‘зӣ®еүҚжҺҘи§ҰеҲ°зҡ„жңҖеӨ§зҡ„йЎ№зӣ®дәҶпјҒпјүгҖӮеҰӮжһңдҪ еҜ№и®Ўз®—жңәеә•еұӮдәҶи§Јзҡ„дёҚеӨҹйҖҸеҪ»пјҢйӮЈд№ҲжҲ‘们еҸҜд»ҘйҖүжӢ©иҫ№еҲҶжһҗиҫ№еӯҰд№ зҡ„ж–№ејҸеҺ»з§ҜзҙҜеә•еұӮзҡ„зҹҘиҜҶгҖӮеҸҜиғҪеҲҡејҖе§ӢеҲҶжһҗд»Јз Ғзҡ„иҝӣеәҰдјҡзЁҚжҳҫиҝҹзј“пјҢдҪҶжҳҜйҡҸзқҖзҹҘиҜҶзҡ„дёҚж–ӯз§ҜзҙҜпјҢжҲ‘们еҜ№LinuxеҶ…ж ёзҡ„вҖңдёҡеҠЎйҖ»иҫ‘вҖқдјҡйҖҗжёҗжҳҺжң—иө·жқҘгҖӮжңҖеҗҺдёҖзӮ№пјҢеҰӮдҪ•д»Һе…ЁеұҖзҡ„и§’еәҰжҠҠжҸЎеҲҶжһҗзҡ„жәҗз ҒпјҢиҝҷд№ҹжҳҜжҲ‘жғідёҺеӨ§е®¶еҲҶдә«зҡ„з»ҸйӘҢгҖӮ
3 еҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•
3.1 иө„ж–ҷжҗңйӣҶ
д»Һдәәи®ӨиҜҶж–°дәӢзү©зҡ„и§’еәҰжқҘи®ІпјҢеңЁжҺўзҙўдәӢзү©жң¬иҙЁд№ӢеүҚпјҢеҝ…йЎ»жңүдёҖдёӘдәҶи§Јж–°йІңдәӢзү©зҡ„иҝҮзЁӢпјҢиҝҷдёӘиҝҮзЁӢжҳҜзҡ„жҲ‘们еҜ№ж–°йІңдәӢзү©дә§з”ҹдёҖдёӘеҲқжӯҘзҡ„жҰӮеҝөгҖӮжҜ”еҰӮжҲ‘们жғіеӯҰд№ й’ўзҗҙпјҢйӮЈд№ҲжҲ‘们йңҖиҰҒе…ҲдәҶи§Јеј№еҘҸй’ўзҗҙйңҖиҰҒжҲ‘们еӯҰд№ еҹәжң¬зҡ„д№җзҗҶгҖҒз®Җи°ұгҖҒдә”зәҝи°ұзӯүеҹәзЎҖзҹҘиҜҶпјҢ然еҗҺеӯҰд№ й’ўзҗҙеј№еҘҸзҡ„жҠҖе·§е’ҢжҢҮжі•пјҢжңҖеҗҺжүҚиғҪзңҹжӯЈзҡ„ејҖе§Ӣз»ғд№ й’ўзҗҙгҖӮ
еҲҶжһҗеҶ…ж ёд»Јз Ғд№ҹжҳҜеҰӮжӯӨпјҢйҰ–е…ҲжҲ‘们йңҖиҰҒе®ҡдҪҚиҰҒеҲҶжһҗзҡ„д»Јз Ғж¶үеҸҠзҡ„еҶ…е®№гҖӮжҳҜиҝӣзЁӢеҗҢжӯҘе’Ңи°ғеәҰзҡ„д»Јз ҒпјҢжҳҜеҶ…еӯҳз®ЎзҗҶзҡ„д»Јз ҒпјҢиҝҳжҳҜи®ҫеӨҮз®ЎзҗҶзҡ„д»Јз ҒпјҢиҝҳжҳҜзі»з»ҹеҗҜеҠЁзҡ„д»Јз ҒзӯүзӯүгҖӮеҶ…ж ёзҡ„еәһеӨ§еҶіе®ҡзқҖжҲ‘们дёҚиғҪдёҖж¬ЎжҖ§е°ҶеҶ…ж ёд»Јз Ғе…ЁйғЁеҲҶжһҗе®ҢжҲҗпјҢеӣ жӯӨжҲ‘们йңҖиҰҒз»ҷиҮӘе·ұдёҖдёӘеҗҲзҗҶзҡ„еҲҶе·ҘгҖӮжӯЈеҰӮз®—жі•и®ҫи®Ўе‘ҠиҜүжҲ‘们зҡ„пјҢиҰҒи§ЈеҶідёҖдёӘеӨ§й—®йўҳпјҢйҰ–е…ҲиҰҒи§ЈеҶіе®ғжүҖж¶үеҸҠзҡ„еӯҗй—®йўҳгҖӮ
е®ҡдҪҚеҘҪиҰҒеҲҶжһҗзҡ„д»Јз ҒиҢғеӣҙпјҢжҲ‘们е°ұеҸҜд»ҘеҠЁз”ЁжүӢеӨҙзҡ„дёҖеҲҮиө„жәҗпјҢе°ҪеҸҜиғҪзҡ„е…ЁйқўдәҶи§ЈиҜҘйғЁеҲҶд»Јз Ғзҡ„ж•ҙдҪ“з»“жһ„е’ҢеӨ§иҮҙеҠҹиғҪгҖӮ
иҝҷйҮҢжүҖиҜҙзҡ„дёҖеҲҮиө„жәҗжҳҜжҢҮж— и®әжҳҜBaiduгҖҒGoogleеӨ§еһӢзҪ‘з»ңжҗңзҙўеј•ж“ҺпјҢиҝҳжҳҜж“ҚдҪңзі»з»ҹеҺҹзҗҶж•ҷжқҗе’Ңдё“дёҡд№ҰзұҚпјҢдәҰжҲ–жҳҜд»–дәәжҸҗдҫӣзҡ„з»ҸйӘҢе’Ңиө„ж–ҷпјҢз”ҡиҮіжҳҜLinuxжәҗз ҒжҸҗдҫӣзҡ„ж–ҮжЎЈгҖҒжіЁйҮҠе’Ңжәҗз Ғж ҮиҜҶз¬Ұзҡ„еҗҚз§°пјҲдёҚиҰҒе°ҸзңӢд»Јз Ғдёӯзҡ„ж ҮиҜҶз¬Ұзҡ„е‘ҪеҗҚпјҢжңүж—¶е®ғ们иғҪжҸҗдҫӣе…ій”®зҡ„дҝЎжҒҜпјүгҖӮжҖ»д№ӢиҝҷйҮҢзҡ„дёҖеҲҮиө„жәҗжҢҮзҡ„е°ұжҳҜдҪ иғҪжғіеҲ°зҡ„дёҖеҲҮеҸҜз”Ёиө„жәҗгҖӮеҪ“然пјҢжҲ‘们дёҚеӨӘеҸҜиғҪйҖҡиҝҮиҝҷз§ҚеҪўејҸзҡ„дҝЎжҒҜжҗңйӣҶиҺ·еҫ—жүҖжңүзҡ„жҲ‘们жғіиҰҒзҡ„дҝЎжҒҜпјҢжҲ‘们еҸӘжұӮе°ҪеҸҜиғҪе…ЁйқўеҚіеҸҜгҖӮеӣ дёәдҝЎжҒҜжҗңйӣҶзҡ„и¶Ҡе…ЁйқўпјҢд№ӢеҗҺеҲҶжһҗд»Јз Ғзҡ„иҝҮзЁӢиғҪдҪҝз”Ёзҡ„дҝЎжҒҜе°ұжӣҙеӨҡпјҢеҲҶжһҗиҝҮзЁӢзҡ„еӣ°йҡҫе°ұдјҡи¶Ҡе°ҸгҖӮ
иҝҷйҮҢдёҫдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҢеҒҮе®ҡжҲ‘们иҰҒеҲҶжһҗLinuxзҡ„еҸҳйў‘жңәеҲ¶е®һзҺ°зҡ„д»Јз ҒгҖӮзӣ®еүҚдёәжӯўжҲ‘们仅仅жҳҜзҹҘйҒ“иҝҷдёӘеҗҚиҜҚиҖҢе·ІпјҢйҖҸиҝҮеӯ—йқўеҗ«д№үжҲ‘们еҸҜд»ҘеӨ§иҮҙзҢңжөӢе®ғеә”иҜҘе’ҢCPUзҡ„йў‘зҺҮи°ғиҠӮзӣёе…ігҖӮйҖҡиҝҮдҝЎжҒҜжҗңйӣҶпјҢжҲ‘们еә”иҜҘиғҪеҫ—еҲ°еҰӮдёӢзҡ„зӣёе…ізҡ„дҝЎжҒҜпјҡ
1пјҺCPUFreqжңәеҲ¶гҖӮ
2пјҺperformanceгҖҒpowersaveгҖҒuserspaceгҖҒondemandгҖҒconservativeи°ғйў‘зӯ–з•ҘгҖӮ
3пјҺ/driver/cpufreq/гҖӮ
4пјҺ/documention/cpufreqгҖӮ
5пјҺP stateе’ҢC stateгҖӮ
еҲҶжһҗLinuxеҶ…ж ёд»Јз ҒеҰӮжһңиғҪжҗңйӣҶеҲ°иҝҷдәӣдҝЎжҒҜпјҢеә”иҜҘиҜҙжҳҜйқһеёёвҖңе№ёиҝҗвҖқдәҶгҖӮжҜ•з«ҹжңүе…іLinuxеҶ…ж ёзҡ„иө„ж–ҷзЎ®е®һдёҚеҰӮ.NETе’ҢJQueryйӮЈд№Ҳдё°еҜҢпјҢдёҚиҝҮиҝҷзӣёжҜ”дәҺеҚҒж•°е№ҙеүҚпјҢжІЎжңүејәеӨ§зҡ„жҗңзҙўеј•ж“ҺпјҢжІЎжңүзӣёе…ізҡ„з ”з©¶иө„ж–ҷзҡ„ж—¶жңҹеә”иҜҘз§°еҫ—дёҠжҳҜвҖңеӨ§дё°ж”¶вҖқж—¶д»ЈдәҶпјҒжҲ‘们йҖҡиҝҮз®ҖеҚ•зҡ„вҖңжҗңзҙўвҖқпјҲеҸҜиғҪдјҡиҠұиҙ№дёҖеҲ°дёӨеӨ©зҡ„ж—¶й—ҙеҗ§пјүпјҢз”ҡиҮіжүҫеҲ°дәҶиҝҷйғЁеҲҶд»Јз ҒжүҖеңЁзҡ„жәҗз Ғж–Ү件зӣ®еҪ•пјҢдёҚеҫ—дёҚиҜҙиҝҷж ·зҡ„дҝЎжҒҜз®ҖзӣҙжҳҜвҖңд»·еҖјиҝһеҹҺвҖқпјҒ
3.2 жәҗз Ғе®ҡдҪҚ
д»Һиө„ж–ҷжҗңйӣҶдёӯпјҢжҲ‘们вҖңжңүе№ёвҖқжүҫеҲ°дәҶжәҗз Ғзӣёе…ізҡ„жәҗз Ғзӣ®еҪ•гҖӮдҪҶжҳҜиҝҷ并йқһж„Ҹе‘ізқҖжҲ‘们зҡ„зЎ®е°ұжҳҜеҲҶжһҗиҝҷдёӘзӣ®еҪ•дёӢзҡ„жәҗд»Јз ҒгҖӮжңүж—¶жҲ‘们жүҫеҲ°зҡ„зӣ®еҪ•жңүеҸҜиғҪжҳҜеҲҶж•Јзҡ„пјҢд№ҹжңүж—¶жҲ‘们жүҫеҲ°зҡ„зӣ®еҪ•дёӢжңүеҫҲеӨҡе’Ңе…·дҪ“жңәеҷЁзӣёе…ізҡ„д»Јз ҒпјҢиҖҢжҲ‘们жӣҙе…іеҝғзҡ„жҳҜеҫ…еҲҶжһҗд»Јз Ғзҡ„дё»иҰҒжңәеҲ¶пјҢиҖҢйқһдёҺжңәеҷЁзӣёе…ізҡ„зү№еҢ–д»Јз ҒпјҲиҝҷж ·жӣҙжңүеҠ©дәҺжҲ‘们зҗҶи§ЈеҶ…ж ёзҡ„жң¬иҙЁпјүгҖӮеӣ жӯӨпјҢжҲ‘们йңҖиҰҒеҜ№иө„ж–ҷдёӯж¶үеҸҠд»Јз Ғж–Ү件зҡ„иө„ж–ҷиҝӣиЎҢд»”з»Ҷз”„йҖүгҖӮеҪ“然пјҢиҝҷдёҖжӯҘд№ҹдёҚеӨӘеҸҜиғҪдёҖж¬ЎжҖ§е®ҢжҲҗпјҢи°Ғд№ҹдёҚиғҪдҝқиҜҒдёҖж¬Ўе°ұиғҪйҖүжӢ©еҮәжүҖжңүеҫ…еҲҶжһҗзҡ„жәҗз Ғж–Ү件иҖҢдё”дёҖдёӘдёҚжјҸгҖӮдҪҶжҳҜжҲ‘们д№ҹдёҚеҝ…жӢ…еҝғпјҢеҸӘиҰҒжҲ‘们иғҪжҠ“дҪҸеӨ§еӨҡж•°жЁЎеқ—зӣёе…ізҡ„ж ёеҝғжәҗж–Ү件пјҢйҖҡиҝҮеҗҺжңҹеҜ№д»Јз Ғзҡ„е…·дҪ“еҲҶжһҗпјҢе°ұеҫҲиҮӘ然зҡ„жҠҠе®ғ们全йғЁжүҫеҮәжқҘгҖӮ
еӣһеҲ°дёҠиҝ°зҡ„дҫӢеӯҗдёӯпјҢжҲ‘们и®Өзңҹзҡ„йҳ…иҜ»/documention/cpufreqдёӢзҡ„ж–ҮжЎЈиҜҙжҳҺгҖӮзӣ®еүҚзҡ„Linuxжәҗз ҒдјҡжҠҠжЁЎеқ—зӣёе…ізҡ„ж–ҮжЎЈиҜҙжҳҺдҝқеӯҳеңЁжәҗз Ғзӣ®еҪ•зҡ„documentionзҡ„ж–Ү件еӨ№дёӢпјҢеҰӮжһңеҫ…еҲҶжһҗзҡ„жЁЎеқ—жІЎжңүж–ҮжЎЈиҜҙжҳҺпјҢиҝҷеӨҡе°‘дјҡеўһеҠ е®ҡдҪҚе…ій”®жәҗз Ғж–Ү件зҡ„йҡҫеәҰпјҢдҪҶжҳҜдёҚдјҡеҜјиҮҙжҲ‘们жүҫдёҚеҲ°жҲ‘们иҰҒеҲҶжһҗзҡ„жәҗз ҒгҖӮйҖҡиҝҮйҳ…иҜ»ж–ҮжЎЈиҜҙжҳҺпјҢжҲ‘们иҮіе°‘иғҪе…іжіЁеҲ°/driver/cpufreq/cpufreq.cиҝҷдёӘжәҗж–Ү件гҖӮйҖҡиҝҮиҝҷдёӘеҜ№жәҗж–Ү件зҡ„ж–ҮжЎЈиҜҙжҳҺпјҢз»“еҗҲд№ӢеүҚжҗңзҪ—еҲ°зҡ„и°ғйў‘зӯ–з•ҘпјҢжҲ‘们еҫҲе®№жҳ“е…іжіЁеҲ°cpufreq_performance.cгҖҒcpufreq_powersave.cгҖҒcpufreq_userspace.cгҖҒcpufreq_ondemandгҖҒcpufreq_conservative.cиҝҷдә”дёӘжәҗж–Ү件гҖӮжүҖжңүж¶үеҸҠзҡ„ж–Ү件йғҪжүҫе®ҢдәҶеҗ—пјҹдёҚз”ЁжӢ…еҝғпјҢд»Һе®ғ们ејҖе§ӢеҲҶжһҗпјҢиҝҹж—©иғҪжүҫеҲ°е…¶д»–зҡ„жәҗж–Ү件гҖӮеҰӮжһңеңЁwindowsдёӢдҪҝз”Ёsourceinsightйҳ…иҜ»еҶ…ж ёжәҗз Ғзҡ„иҜқпјҢжҲ‘们йҖҡиҝҮеҮҪж•°зҡ„и°ғз”Ёе’ҢжҹҘжүҫз¬ҰеҸ·еј•з”ЁзӯүеҠҹиғҪпјҢз»“еҗҲд»Јз Ғзҡ„еҲҶжһҗеҸҜд»ҘеҫҲж–№дҫҝзҡ„жүҫеҲ°еҸҰеӨ–зҡ„ж–Ү件freq_table.cгҖҒcpufreq_stats.cе’Ң/include/linux/cpufreq.hгҖӮ
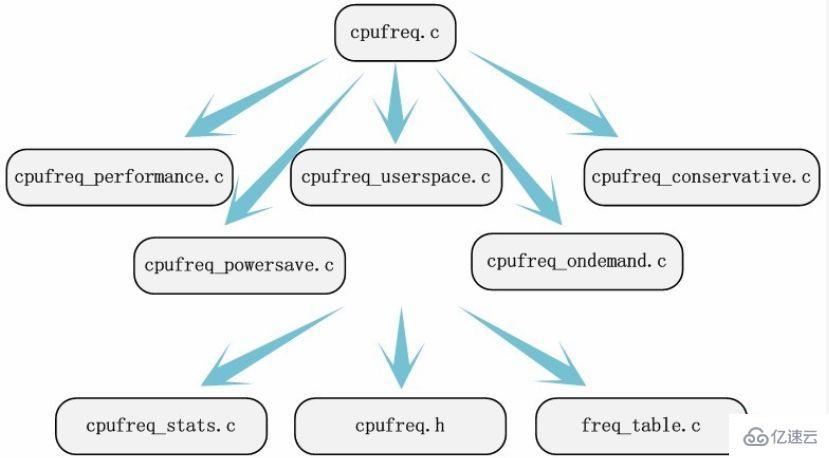
жҢүз…§жҗңзҙўеҮәзҡ„дҝЎжҒҜжөҒеҠЁж–№еҗ‘пјҢжҲ‘们е®Ңе…ЁеҸҜд»Ҙе®ҡдҪҚеҲ°йңҖиҰҒеҲҶжһҗзҡ„жәҗз Ғж–Ү件гҖӮжәҗз Ғе®ҡдҪҚиҝҷдёҖжӯҘ并йқһеҚҒеҲҶе…ій”®пјҢеӣ дёәжҲ‘们дёҚйңҖиҰҒжүҫеҮәжүҖжңүжәҗз Ғж–Ү件пјҢжҲ‘们еҸҜд»ҘжҠҠйғЁеҲҶе·ҘдҪңжҺЁиҝҹеҲ°еҲҶжһҗд»Јз Ғзҡ„иҝҮзЁӢдёӯгҖӮжәҗз Ғе®ҡдҪҚд№ҹжҜ”иҫғе…ій”®пјҢжүҫеҲ°дёҖйғЁеҲҶжәҗз Ғж–Ү件жҳҜеҲҶжһҗжәҗз Ғзҡ„еҹәзЎҖгҖӮ
3.3 з®ҖеҚ•жіЁйҮҠ
з®ҖеҚ•жіЁйҮҠ
еңЁе·Іе®ҡдҪҚеҘҪзҡ„жәҗз Ғж–Ү件дёӯпјҢеҲҶжһҗжҜҸдёӘеҸҳйҮҸгҖҒе®ҸгҖҒеҮҪж•°гҖҒз»“жһ„дҪ“зӯүд»Јз Ғе…ғзҙ зҡ„еӨ§иҮҙеҗ«д№үе’ҢеҠҹиғҪгҖӮд№ӢжүҖд»Ҙз§°жӯӨдёәз®ҖеҚ•жіЁйҮҠпјҢ并йқһжҢҮиҝҷйғЁеҲҶзҡ„жіЁйҮҠе·ҘдҪңеҫҲз®ҖеҚ•пјҢиҖҢжҳҜжҢҮиҝҷйғЁеҲҶзҡ„жіЁйҮҠеҸҜд»ҘдёҚеҝ…иҝҮеҲҶз»ҶеҢ–пјҢеҸӘиҰҒеӨ§иҮҙжҸҸиҝ°еҮәзӣёе…ід»Јз Ғе…ғзҙ зҡ„еҗ«д№үеҚіеҸҜгҖӮзӣёеҸҚпјҢиҝҷйҮҢзҡ„е·ҘдҪңе…¶е®һжҳҜж•ҙдёӘеҲҶжһҗжөҒзЁӢдёӯжңҖеӣ°йҡҫзҡ„дёҖжӯҘгҖӮеӣ дёәиҝҷжҳҜ第дёҖж¬Ўж·ұе…ҘеҲ°еҶ…ж ёд»Јз Ғзҡ„еҶ…йғЁпјҢе°Өе…¶жҳҜеҜ№дәҺйҰ–ж¬ЎеҲҶжһҗеҶ…ж ёжәҗз Ғзҡ„дәәжқҘиҜҙпјҢеӨ§йҮҸзҡ„з”ҹз–ҸGNUзҡ„CиҜӯжі•е’Ңй“әеӨ©зӣ–ең°зҡ„е®Ҹе®ҡд№үдјҡд»ӨдәәеҫҲз»қжңӣгҖӮжӯӨж—¶еҸӘиҰҒжІүдёӢеҝғжқҘпјҢеј„жё…жҜҸдёӘе…ій”®зҡ„йҡҫзӮ№пјҢжүҚиғҪдҝқиҜҒд»ҘеҗҺзў°еҲ°зұ»дјјзҡ„йҡҫзӮ№дёҚдјҡеҶҚиў«еӣ°дҪҸгҖӮиҖҢдё”пјҢжҲ‘们еҜ№еҶ…ж ёзӣёе…ізҡ„е…¶д»–зҹҘиҜҶдјҡдёҚж–ӯзҡ„еғҸж ‘дёҖж ·жү©еұ•ејҖжқҘгҖӮ
жҜ”еҰӮеңЁcpufreq.cж–Ү件ејҖе§Ӣе°ұдјҡеҮәзҺ°вҖңDEFINE_PER_CPUвҖқе®Ҹзҡ„дҪҝз”ЁпјҢжҲ‘们йҖҡиҝҮжҹҘйҳ…иө„ж–ҷеҸҜд»Ҙеҹәжң¬еј„жё…иҝҷдёӘе®Ҹзҡ„еҗ«д№үе’ҢеҠҹиғҪгҖӮиҝҷйҮҢдҪҝз”Ёзҡ„жүӢж®өе’Ңд№ӢеүҚжҗңйӣҶиө„ж–ҷдҪҝз”Ёзҡ„ж–№жі•еҹәжң¬дёҖиҮҙпјҢеҸҰеӨ–жҲ‘们д№ҹеҸҜд»ҘдҪҝз”ЁsourceinsightжҸҗдҫӣзҡ„иҪ¬еҲ°е®ҡд№үзӯүеҠҹиғҪжҹҘзңӢе®ғзҡ„е®ҡд№үпјҢжҲ–иҖ…дҪҝз”ЁLKMLпјҲLinux Kernel Mail ListпјүжҹҘйҳ…гҖӮжҖ»д№ӢеҲ©з”ЁжүҖжңүеҸҜиғҪзҡ„жүӢж®өпјҢжҲ‘们жҖ»иғҪеҫ—еҲ°иҝҷдёӘе®Ҹзҡ„еҗ«д№үвҖ”вҖ”дёәжҜҸдёӘCPUе®ҡд№үдёҖдёӘзӢ¬з«ӢдҪҝз”Ёзҡ„еҸҳйҮҸгҖӮ
жҲ‘们д№ҹдёҚиҰҒејәжұӮдёҖж¬Ўе°ұиғҪжҠҠжіЁйҮҠжҸҸиҝ°зҡ„еҫҲеҮҶзЎ®пјҲжҲ‘们з”ҡиҮійғҪжІЎеҝ…иҰҒеј„жё…жҜҸдёӘеҮҪж•°зҡ„е…·дҪ“е®һзҺ°жөҒзЁӢпјҢеҸӘиҰҒеј„жё…еӨ§иҮҙеҠҹиғҪеҗ«д№үеҚіеҸҜпјүпјҢжҲ‘们结еҗҲжҗңйӣҶеҲ°зҡ„иө„ж–ҷе’ҢеҗҺиҫ№д»Јз Ғзҡ„еҲҶжһҗдёҚж–ӯзҡ„е®Ңе–„жіЁйҮҠзҡ„еҗ«д№үпјҲжәҗз ҒдёӯеҺҹжңүзҡ„жіЁйҮҠе’Ңж ҮиҜҶз¬Ұе‘ҪеҗҚеңЁжӯӨеҫҲжңүеҲ©з”Ёд»·еҖјпјүгҖӮйҖҡиҝҮдёҚж–ӯзҡ„жіЁйҮҠпјҢдёҚж–ӯзҡ„жҹҘйҳ…иө„ж–ҷпјҢдёҚж–ӯзҡ„дҝ®ж”№жіЁйҮҠзҡ„еҗ«д№үгҖӮ
еҪ“жҲ‘们жҠҠжүҖжңүж¶үеҸҠзҡ„жәҗз Ғж–Ү件з®ҖеҚ•жіЁйҮҠе®ҢжҜ•еҗҺжҲ‘们еҸҜд»ҘиҫҫеҲ°еҰӮдёӢж•Ҳжһңпјҡ
1пјҺеҹәжң¬еј„жё…дәҶжәҗз Ғдёӯд»Јз Ғе…ғзҙ еӯҳеңЁзҡ„еҗ«д№үгҖӮ
2пјҺжүҫеҮәдәҶиҜҘжЁЎеқ—жүҖж¶үеҸҠзҡ„еҹәжң¬дёҠе…ЁйғЁзҡ„е…ій”®жәҗз Ғж–Ү件гҖӮ
з»“еҗҲд№ӢеүҚжҗңйӣҶеҲ°зҡ„дҝЎжҒҜе’Ңиө„ж–ҷеҜ№иҜҘеҫ…еҲҶжһҗд»Јз Ғзҡ„ж•ҙдҪ“жҲ–иҖ…жһ¶жһ„жҸҸиҝ°пјҢжҲ‘们еҸҜд»Ҙе°ҶеҲҶжһҗзҡ„з»“жһңе’Ңиө„ж–ҷеҜ№жҜ”пјҢд»ҘзЎ®е®ҡе’Ңдҝ®жӯЈжҲ‘们еҜ№д»Јз Ғзҡ„зҗҶи§ЈгҖӮиҝҷж ·пјҢйҖҡиҝҮдёҖйҒҚзҡ„з®ҖеҚ•жіЁйҮҠпјҢжҲ‘们е°ұеҸҜд»Ҙд»Һж•ҙдҪ“дёҠжҠҠжҸЎдәҶжәҗз ҒжЁЎеқ—зҡ„дё»иҰҒз»“жһ„гҖӮиҝҷд№ҹиҫҫеҲ°дәҶжҲ‘们з®ҖеҚ•жіЁйҮҠзҡ„еҹәжң¬зӣ®зҡ„гҖӮ
3.4 иҜҰз»ҶжіЁйҮҠ
е®ҢжҲҗд»Јз Ғзҡ„з®ҖеҚ•жіЁйҮҠеҗҺпјҢеҸҜд»Ҙи®ӨдёәеҜ№жЁЎеқ—зҡ„еҲҶжһҗе·ҘдҪңе®ҢжҲҗдәҶдёҖеҚҠдәҶпјҢеү©дёӢзҡ„еҶ…е®№е°ұжҳҜеҜ№д»Јз Ғзҡ„ж·ұе…ҘеҲҶжһҗе’ҢеҪ»еә•зҗҶи§ЈгҖӮз®ҖеҚ•жіЁйҮҠжҖ»жҳҜдёҚиғҪе°Ҷд»Јз Ғе…ғзҙ зҡ„е…·дҪ“еҗ«д№үжҸҸиҝ°зҡ„еҚҒеҲҶзІҫзЎ®пјҢеӣ жӯӨиҜҰз»ҶжіЁйҮҠжҳҜеҚҒеҲҶжңүеҝ…иҰҒзҡ„гҖӮиҝҷдёҖжӯҘдёӯпјҢжҲ‘们йңҖиҰҒеј„жё…д»ҘдёӢеҶ…е®№пјҡ
1пјҺеҸҳйҮҸе®ҡд№үеңЁдҪ•ж—¶иў«дҪҝз”ЁгҖӮ
2пјҺе®Ҹе®ҡд№үзҡ„д»Јз ҒдҪ•ж—¶иў«дҪҝз”ЁгҖӮ
3пјҺеҮҪж•°зҡ„еҸӮж•°е’Ңиҝ”еӣһеҖјзҡ„еҗ«д№үгҖӮ
4пјҺеҮҪж•°зҡ„жү§иЎҢжөҒзЁӢе’Ңи°ғз”Ёе…ізі»гҖӮ
5пјҺз»“жһ„дҪ“еӯ—ж®өзҡ„е…·дҪ“еҗ«д№үе’ҢдҪҝз”ЁжқЎд»¶гҖӮ
жҲ‘们з”ҡиҮіеҸҜд»ҘжҠҠиҝҷдёҖжӯҘз§°дёәеҮҪж•°иҜҰз»ҶжіЁйҮҠпјҢеӣ дёәеҮҪж•°д№ӢеӨ–зҡ„д»Јз Ғе…ғзҙ зҡ„еҗ«д№үеҹәжң¬дёҠеңЁз®ҖеҚ•жіЁйҮҠдёӯе·Із»ҸжҜ”иҫғжҳҺзЎ®дәҶгҖӮиҖҢеҮҪж•°жң¬иә«зҡ„жү§иЎҢжөҒзЁӢгҖҒз®—жі•зӯүжҳҜиҝҷйғЁеҲҶжіЁйҮҠе’ҢеҲҶжһҗзҡ„дё»иҰҒд»»еҠЎгҖӮ
жҜ”еҰӮcpufreq_ondemandзӯ–з•Ҙзҡ„е®һзҺ°з®—жі•пјҲеҮҪж•°dbs_check_cpuдёӯпјүжҳҜеҰӮдҪ•е®һзҺ°зҡ„гҖӮжҲ‘们йңҖиҰҒйҖҗжӯҘеҲҶжһҗиҜҘеҮҪж•°дҪҝз”Ёзҡ„еҸҳйҮҸе’Ңи°ғз”Ёзҡ„еҮҪж•°зӯүдҝЎжҒҜпјҢеј„жё…з®—жі•зҡ„жқҘйҫҷеҺ»и„үгҖӮжңҖеҘҪзҡ„з»“жһңпјҢжҲ‘们йңҖиҰҒиҝҷдәӣеӨҚжқӮеҮҪж•°зҡ„жү§иЎҢжөҒзЁӢеӣҫе’ҢеҮҪж•°и°ғз”Ёе…ізі»еӣҫпјҢиҝҷжҳҜжңҖзӣҙи§Ӯзҡ„иЎЁиҫҫж–№ејҸгҖӮ
йҖҡиҝҮиҝҷдёҖжӯҘзҡ„жіЁйҮҠпјҢжҲ‘们еҹәжң¬дёҠиғҪе®Ңе…ЁжҠҠжҸЎеҫ…еҲҶжһҗд»Јз Ғж•ҙдҪ“зҡ„е®һзҺ°жңәеҲ¶дәҶгҖӮиҖҢжүҖжңүзҡ„еҲҶжһҗе·ҘдҪңеҸҜд»Ҙи®Өдёәе®ҢжҲҗдәҶ80%гҖӮиҝҷдёҖжӯҘе·ҘдҪңе°Өе…¶е…ій”®пјҢжҲ‘们еҝ…йЎ»е°ҪйҮҸи®©жіЁйҮҠзҡ„дҝЎжҒҜи¶іеӨҹзҡ„еҮҶзЎ®пјҢжүҚиғҪжӣҙеҘҪзҡ„зҗҶи§Јеҫ…еҲҶжһҗд»Јз Ғзҡ„еҶ…йғЁжЁЎеқ—зҡ„еҲ’еҲҶгҖӮиҷҪ然LinuxеҶ…ж ёдёӯдҪҝз”ЁдәҶе®ҸиҜӯжі•вҖңmodule_initвҖқе’ҢвҖңmodule_exitвҖқеЈ°жҳҺжЁЎеқ—ж–Ү件пјҢдҪҶжҳҜеҜ№жЁЎеқ—еҶ…йғЁеӯҗеҠҹиғҪзҡ„еҲ’еҲҶжҳҜе»әз«ӢеңЁе……еҲҶдәҶи§ЈжЁЎеқ—зҡ„еҠҹиғҪеҹәзЎҖдёҠзҡ„гҖӮеҸӘжңүжӯЈзЎ®еҲ’еҲҶеҘҪжЁЎеқ—пјҢжҲ‘们жүҚиғҪеј„жё…жЁЎеқ—жҸҗдҫӣдәҶе“ӘдәӣеӨ–йғЁеҮҪж•°е’ҢеҸҳйҮҸпјҲдҪҝз”ЁEXPORT_SYMBOL_GPLжҲ–иҖ…EXPORT_SYMBOLеҜјеҮәзҡ„з¬ҰеҸ·пјүгҖӮжүҚиғҪ继з»ӯдёӢдёҖжӯҘзҡ„жЁЎеқ—еҶ…ж ҮиҜҶз¬Ұдҫқиө–е…ізі»еҲҶжһҗгҖӮ
3.5 жЁЎеқ—еҶ…йғЁж ҮиҜҶз¬Ұдҫқиө–е…ізі»
йҖҡиҝҮ第еӣӣжӯҘеҜ№д»Јз ҒжЁЎеқ—зҡ„еҲ’еҲҶпјҢжҲ‘们е°ұеҸҜд»ҘеҫҲвҖңиҪ»жқҫвҖқең°йҖҗдёӘеҜ№жЁЎеқ—иҝӣиЎҢеҲҶжһҗгҖӮдёҖиҲ¬зҡ„пјҢжҲ‘们еҸҜд»Ҙд»Һж–Ү件еә•йғЁзҡ„жЁЎеқ—еҮәе…ҘеҸЈеҮҪж•°ејҖе§ӢпјҲвҖңmodule_initвҖқе’ҢвҖңmodule_exitвҖқеЈ°жҳҺзҡ„еҮҪж•°пјҢдёҖиҲ¬йғҪеңЁж–Ү件жңҖеҗҺпјүпјҢж №жҚ®е®ғ们и°ғз”Ёзҡ„еҮҪж•°пјҲиҮӘе·ұе®ҡд№үзҡ„жҲ–иҖ…е…¶д»–жЁЎеқ—зҡ„еҮҪж•°пјүе’ҢдҪҝз”Ёзҡ„е…ій”®еҸҳйҮҸпјҲжң¬ж–Ү件еҶ…зҡ„е…ЁеұҖеҸҳйҮҸжҲ–иҖ…е…¶д»–жЁЎеқ—зҡ„еӨ–йғЁеҸҳйҮҸпјүз”»еҮәвҖңеҮҪж•°-еҸҳйҮҸ-еҮҪж•°вҖқдҫқиө–е…ізі»еӣҫвҖ”вҖ”жҲ‘们称дёәж ҮиҜҶз¬Ұдҫқиө–е…ізі»еӣҫгҖӮ
еҪ“然пјҢжЁЎеқ—еҶ…ж ҮиҜҶз¬Ұдҫқиө–关系并йқһжҳҜеҚ•зәҜзҡ„ж ‘еҪўз»“жһ„пјҢеҫҲеӨҡжғ…еҶөжҳҜй”ҷз»јеӨҚжқӮзҡ„зҪ‘з»ңе…ізі»гҖӮиҝҷж—¶еҖҷпјҢжҲ‘们еҜ№д»Јз Ғзҡ„иҜҰз»ҶжіЁйҮҠзҡ„дҪңз”Ёе°ұдҪ“зҺ°еҮәжқҘдәҶгҖӮжҲ‘д»¬ж №жҚ®еҮҪж•°жң¬иә«зҡ„еҗ«д№үпјҢе°ҶжЁЎеқ—иҝӣиЎҢеӯҗеҠҹиғҪеҲ’еҲҶпјҢжҠҪеҸ–еҮәжҜҸдёӘеӯҗеҠҹиғҪзҡ„ж ҮиҜҶз¬Ұдҫқиө–ж ‘гҖӮ
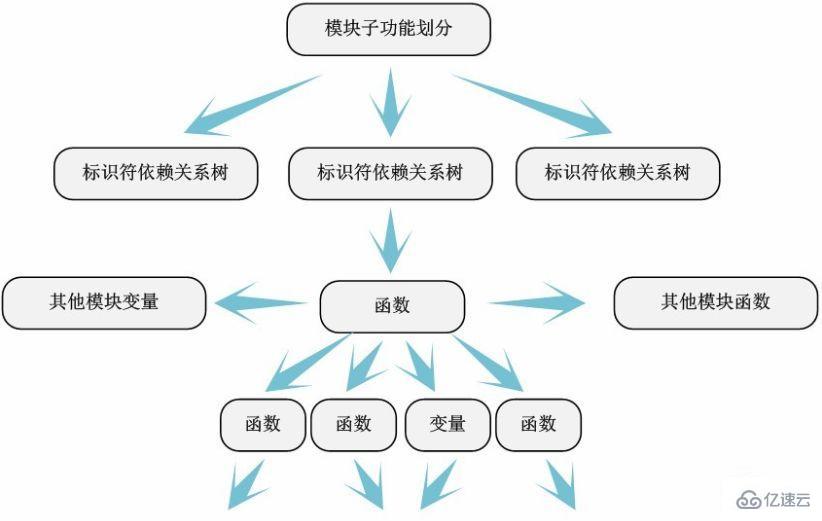
йҖҡиҝҮж ҮиҜҶз¬Ұдҫқиө–е…ізі»еҲҶжһҗпјҢеҸҜд»ҘеҫҲжё…жҷ°зҡ„еұ•зӨәжЁЎеқ—е®ҡд№үзҡ„еҮҪж•°и°ғз”ЁдәҶйӮЈдәӣеҮҪж•°пјҢдҪҝз”ЁдәҶе“ӘдәӣеҸҳйҮҸпјҢд»ҘеҸҠжЁЎеқ—еӯҗеҠҹиғҪд№Ӣй—ҙзҡ„дҫқиө–е…ізі»вҖ”вҖ”е…¬з”ЁдәҶе“ӘдәӣеҮҪж•°е’ҢеҸҳйҮҸзӯүгҖӮ
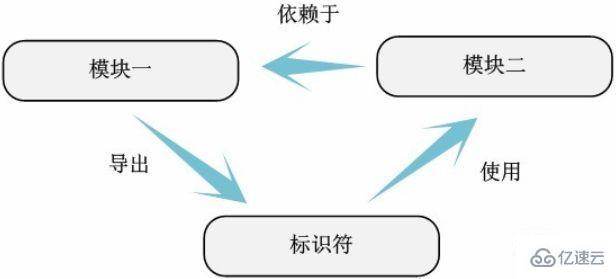
3.6 жЁЎеқ—й—ҙзӣёдә’дҫқиө–е…ізі»
жЁЎеқ—й—ҙзӣёдә’дҫқиө–е…ізі»
дёҖж—Ұе°ҶжүҖжңүзҡ„жЁЎеқ—еҶ…йғЁж ҮиҜҶз¬Ұдҫқиө–е…ізі»еӣҫж•ҙзҗҶе®ҢжҜ•пјҢж №жҚ®жЁЎеқ—дҪҝз”Ёзҡ„е…¶д»–жЁЎеқ—зҡ„еҸҳйҮҸжҲ–еҮҪж•°пјҢеҸҜд»ҘеҫҲе®№жҳ“еҫ—еҲ°жЁЎеқ—д№Ӣй—ҙзҡ„дҫқиө–е…ізі»гҖӮ
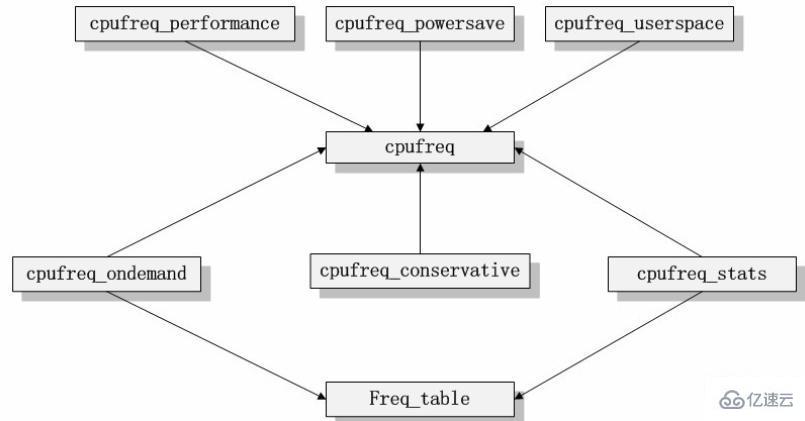
cpufreqд»Јз Ғзҡ„жЁЎеқ—дҫқиө–е…ізі»еҸҜд»ҘиЎЁзӨәдёәеҰӮдёӢе…ізі»гҖӮ
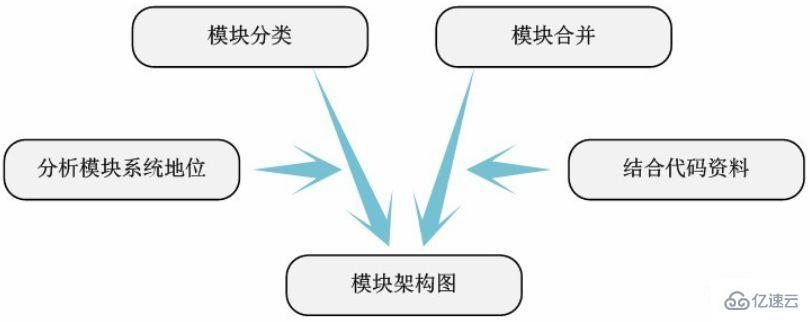
3.7 жЁЎеқ—жһ¶жһ„еӣҫ
йҖҸиҝҮжЁЎеқ—й—ҙзҡ„дҫқиө–е…ізі»еӣҫпјҢеҸҜд»ҘеҫҲжё…жҘҡзҡ„иЎЁиҫҫжЁЎеқ—еңЁж•ҙдёӘеҫ…еҲҶжһҗд»Јз Ғдёӯзҡ„ең°дҪҚе’ҢеҠҹиғҪгҖӮеҹәдәҺжӯӨпјҢжҲ‘们еҸҜд»Ҙе°ҶжЁЎеқ—еҲҶзұ»пјҢж•ҙзҗҶеҮәд»Јз Ғзҡ„жһ¶жһ„е…ізі»гҖӮ
еҰӮcpufreqзҡ„жЁЎеқ—дҫқиө–е…ізі»еӣҫжүҖзӨәпјҢжҲ‘们еҸҜд»ҘеҫҲжё…жҘҡзҡ„зңӢеҲ°жүҖжңүзҡ„и°ғйў‘зӯ–з•ҘжЁЎеқ—йғҪжҳҜдҫқиө–дәҺж ёеҝғжЁЎеқ—cpufreqгҖҒcpufreq_statsе’Ңfreq_tableзҡ„гҖӮеҰӮжһңжҲ‘们жҠҠиў«дҫқиө–зҡ„дёүдёӘжЁЎеқ—жҠҪиұЎдёәд»Јз Ғзҡ„ж ёеҝғжЎҶжһ¶зҡ„иҜқпјҢиҝҷдәӣи°ғйў‘зӯ–з•ҘжЁЎеқ—йғҪжҳҜе»әз«ӢеңЁиҝҷдёӘжЎҶжһ¶д№ӢдёҠзҡ„пјҢе®ғ们иҙҹиҙЈе’Ңз”ЁжҲ·еұӮдәӨдә’гҖӮиҖҢж ёеҝғжЁЎеқ—cpufreqжҸҗдҫӣдәҶй©ұеҠЁзӯүзӣёе…ізҡ„жҺҘеҸЈиҙҹиҙЈдёҺзі»з»ҹеә•еұӮдәӨдә’гҖӮеӣ жӯӨпјҢжҲ‘们еҸҜд»Ҙеҫ—еҲ°еҰӮдёӢзҡ„жЁЎеқ—жһ¶жһ„еӣҫгҖӮ
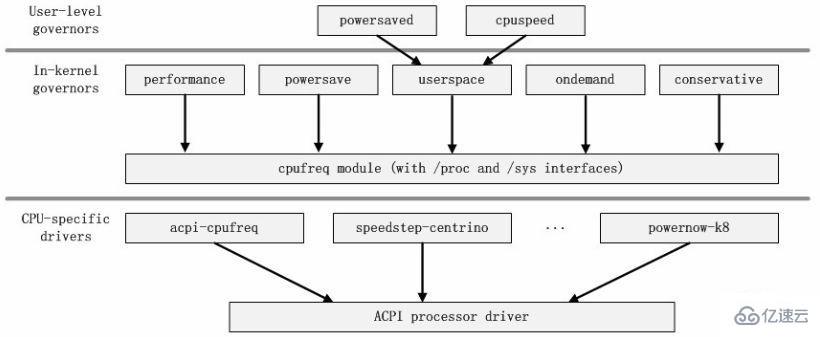
еҪ“然пјҢжһ¶жһ„еӣҫ并йқһжЁЎеқ—зҡ„ж— жңәжӢјжҺҘпјҢжҲ‘们иҝҳйңҖиҰҒз»“еҗҲжҹҘйҳ…зҡ„иө„ж–ҷеҺ»дё°еҜҢжһ¶жһ„еӣҫзҡ„еҗ«д№үгҖӮеӣ жӯӨпјҢиҝҷйҮҢзҡ„жһ¶жһ„еӣҫзҡ„з»ҶиҠӮдјҡйҡҸзқҖдёҚеҗҢзҡ„дәәзҡ„зҗҶи§ЈжңүжүҖеҒҸе·®гҖӮдҪҶжҳҜжһ¶жһ„еӣҫдё»дҪ“зҡ„еҗ«д№үеҫҲеҹәжң¬дёҖиҮҙзҡ„гҖӮиҮіжӯӨпјҢжҲ‘们е®ҢжҲҗдәҶеҫ…еҲҶжһҗзҡ„еҶ…ж ёд»Јз Ғзҡ„жүҖжңүеҲҶжһҗе·ҘдҪңгҖӮ
е…ідәҺвҖңlinuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁд»Җд№Ҳж–Ү件дёӢвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢпјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶еҜ№вҖңlinuxеҶ…ж ёзҡ„жәҗд»Јз Ғж”ҫеңЁд»Җд№Ҳж–Ү件дёӢвҖқзҹҘиҜҶйғҪжңүдёҖе®ҡзҡ„дәҶи§ЈпјҢеӨ§е®¶еҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





