这篇文章主要介绍“Go语言进阶freecache源码分析”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Go语言进阶freecache源码分析”文章能帮助大家解决问题。
freecache 是一个用 go 语言实现的本地缓存系统(类似于 lru)。
它有几个特性值得注意:
通过优秀的内存管理方案,实现了 go 语言的零 gc
是线程安全的,同时支持一定程度的并发,非常适合并发场景
支持设置失效时间,动态失效过期缓存
在一定程度上支持 lru,即“最近最少使用”,会在容量不足的时候优先淘汰较早的数据
这几个优秀特性使得他非常适合用在生产环境中作为本地缓存。
cacheSize := 100 * 1024 * 1024
cache := freecache.NewCache(cacheSize)
debug.SetGCPercent(20)
key := []byte("abc")
val := []byte("def")
expire := 60 // expire in 60 seconds
cache.Set(key, val, expire)
got, err := cache.Get(key)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(string(got))
}
affected := cache.Del(key)
fmt.Println("deleted key ", affected)
fmt.Println("entry count ", cache.EntryCount())本文计划先以自然语言描述下列功能的实现方式,再接下来的章节中深入源码,扒出其具体实现
如何做到零 gc?
数据结构
动态索引
缓存失效
这个库之所以做到了 0 gc,是因为设定了很巧妙的数据结构,这个数据结构有以下的特点:
无论存多少数据,都只会存在 512 个指针
所有的具体数据的存储空间,都是预先就分配好的,而不是动态分配的
使用了一些黑科技,比如强制类型转换以及结构体对齐等技术,将所有的动态数据都管理在预先分配好的连续空间内
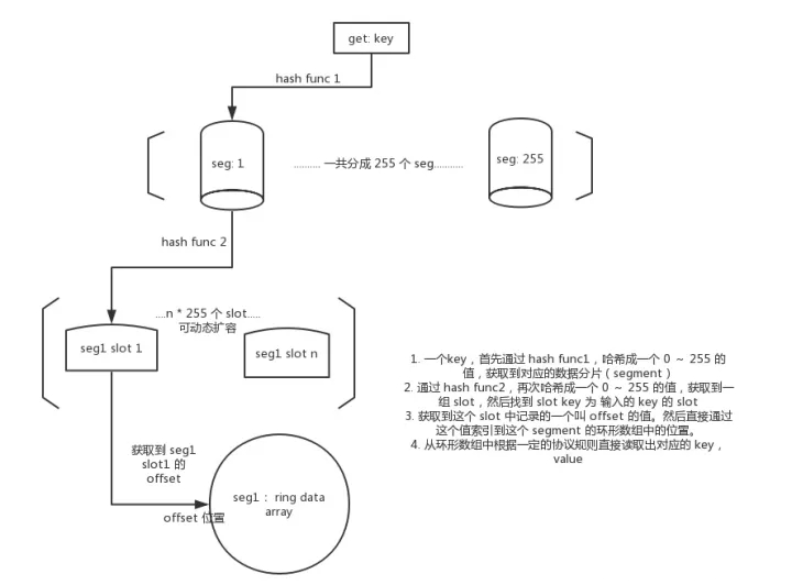
可以将这个数据结构大体上抽象成一个哈希表。即你会看到哈希函数以及对应的数组空间。但是他和传统的哈希表是有区别的,主要有以下几点:
线程安全,支持高并发,内存空间高度优化:
为了做到支持高并发以及线程安全,并且保证内存空间的可用性,freecache 实际上划分出了 256 个独立数组空间用来存储对应的底层数据。
这样在并发访问的时候,通过对 key 进行分片,使得请求只会打到一个数组空间上,即只会对这 256 个空间中的一个空间加锁,这样就大大降低了资源争抢。
数据的组织方式与传统哈希表不同:
传统的哈希表只在数组空间中存 value。而 freecache 则不同,他将 key,value 全部存在了数组空间中。
传统哈希表的数组是稀疏的。freecache 数据并不是稀疏的,而是连续的,即新的值会不断 append 到最后。
传统哈希表使用 hash func 对 key 取索引,索引到稀疏数组中的位置。而 freecache 则通过维护了一个叫“slot(插槽)”的数据结构,通过对 key 进行 hash func,先拿到对应的 slot,然后 slot 中维护着一个索引,可以定位到具体的数据在数组中的位置。
解决哈希冲突的方式不同。当遇到哈希冲突的时候,哈希表需要对底层的稀疏数组进行扩容,会导致可用性大大降低。而 freecache 则是只需要对“slot”的指针数组进行扩容,而无需改变底层数组。因为 slot 指针数组的大小远小于底层数组,所以扩容的成本是非常非常低的。
为了实现缓存淘汰以及定时失效,它的数组空间在逻辑上是一个环状的。这么做有以下原因
数组存的数据逻辑上是连续的,而非稀疏数组。充分利用了CPU对数组读取的缓存优化
通过使用了一系列的首尾计算方式,是足以保证读取和存储在首尾的连续性。比如读数据的时候读到结尾如果还没读完,会跳转到头部继续往下读。
能以 O(1) 的时间复杂度完成新数据对旧数据的淘汰。我们假设如果数组在逻辑上不是环形的,那么当数组写满的时候再写入新的数据,就需要把数组头部的数据删除掉,然后再把之后的数据统统向左移动删除数据的长度,然后再从最右端写入新的数据。反之,如果数组是环形的,只需要在数组头部把旧数据覆盖即可
通过一些算法手段,可以实现一个很 hack 的 lru 功能。在一定程度上能保证“最近最少使用”的淘汰。
通过上面对数据结构的分析,我们知道他和传统的哈希表的实现方式大相径庭。它实际上是使用了一种叫“插槽”的数据结构,专门负责通过 key 索引到数据空间中的某个位置。他的实现比较有意思。它的底层是一个结构体指针数组。他是可以动态扩容的。每个插槽有一个 id,叫 slotId,范围是 0~255。当遇到哈希冲突的时候,比如出现了2个 slotId 为 100 的 slot,他就会检测当前的最大重复 slotID 数量 n。如果这个 2 大于 n,他就会扩容到 2n。
// slot 的数据结构
type entryPtr struct {
offset int64 // 记录了当前 slot 在环形数组中的偏移量
hash26 uint16 // 一个 hash 值,用于在 segment 中定位到具体的 slot
keyLen uint16 // used to compare a key
reserved uint32
}
// 每个分片的数据结构
type segment struct {
rb RingBuf // 环形数组
segId int
hitCount int64
missCount int64
entryCount int64
totalCount int64 // 之后计算 lru 的时候会用到,用于衡量一个数据是否是热点数据
totalTime int64 // 之后计算 lru 的时候会用到,用于衡量一个数据是否是热点数据
totalEvacuate int64 // used for debug
totalExpired int64 // used for debug
overwrites int64 // used for debug
vacuumLen int64 // 环形数组可用容量,主要用于环形数组首尾相接的算法
slotLens [256]int32 // 每个 slotId 的长度的数组
slotCap int32 // 每个 slotId 的容量
slotsData []entryPtr // 存储 slots 的切片,根据 hash26 进行顺序排列。相同的 hash26 拥有相同的 slotId
}缓存失效主要包括两种:
基于过期时间的失效
基于最近最少使用的失效
这两种失效都有缺陷。
首先它是一种被动失效,而不是通过一个额外的线程定期check。而是每次 set 新的值的时候,如果发现空间不够用了,他才会尝试从环形数组的头端进行check。如果发现当前check的数据过期了,或者使用频率过低,就会将记录有效数据的头指针进行偏移,即相当于“失效”。如果检查多次都没能找到需要失效的数据,那么他会将这些检查过的数据转移到尾部,并强制当前的头部的数据失效。
这种失效是不可靠的。比如一个数据,如果在环形数组的中间,那么即便它过期了,也很难被 check 到。并且存在一定的失误概率,即将一个热点数据给失效了。
关于“Go语言进阶freecache源码分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://zhuanlan.zhihu.com/p/67298011



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



