今天小编给大家分享一下Java怎么使用字符流读写非文本文件的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
以Java的字符流读取文件为例:它只能读取0-65535之间的字符,可以看出来字符都是正数,但是二进制的byte是可以为负数的。但是读取的时候会被当做正数来读取,或者是无法在编码表中找到的字符会返回一个奇怪的符号(你可能见过那个奇怪的 “?”)。
但是在某些情况下,必须要使用字符来显示二进制数据,也不是没有办法的,下面就来介绍一个我们什么的方式–base64编码。
base64是网络上常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。Base64编码是从二进制到字符的过程,可以用在HTTP环境下传递较长的标识信息。采用Base64编码后具有不可读性,需要解码后才能阅读。它的中文名是基于64个可打印字符来表示二进制数据。
1. 把3个字节变成4个字节.
2. 没76个字符加一个换行符。
3. 最后的结束符也要处理。
从编码规则可以看出来,base64要求把每三个8Bit的字节转换成四个6Bit的字符(38 = 46 = 24),然后把6Bit再添加两位高位0,组成四个8Bit的字节。也就是说,转换后的字符串理论上将要比原来的长1/3(33%)。
这里这是介绍一个概念,关于更加详细的内容,如果感兴趣的话,可以取收集了解更多。
Java的Base64工具类提供了一套静态方法获取下面三种BASE64编解码器:
基本:输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/。
URL:输出映射到一组字符A-Za-z0-9+_,输出是URL和文件。
MIME:输出隐射到MIME友好格式。输出每行不超过76字符,并且使用’\r’并跟随’\n’作为分割。编码输出最后没有行分割。
分别对应如下几个方法:
Encoder basicEncoder = Base64.getEncoder();
Encoder mimeEncoder = Base64.getMimeEncoder();
Encoder urlEncoder = Base64.getUrlEncoder();我写了一个简单的工具类来进行测试 基本(basic) 的编码器。。
package com.dragon;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.util.Base64;
import java.util.Base64.Decoder;
import java.util.Base64.Encoder;
/**
* @author Alfred
* */
public class Base64Util {
private static Encoder encoder = Base64.getEncoder();
private static Decoder decoder = Base64.getDecoder();
private static String ENCODE = "UTF-8";
private static int LENGTH = 1024;
/**
* 静态方法:
* 将文件等二进制数据(文本和非文本都可以)
* 转为base64字符串。
* @throws IOException
* @throws FileNotFoundException
*
* */
public static String dataToBase64(File src) throws FileNotFoundException, IOException {
Encoder encoder = Base64.getEncoder();
int len = (int)src.length();
byte[] bar = new byte[(int)len];
int hasRead = 0;
byte[] b = new byte[LENGTH];
//使用专门处理 byte 的IO流比较方便,一次性读取较大文件对内存压力较大
try (InputStream in = new BufferedInputStream(new FileInputStream(src));
ByteArrayOutputStream bos = new ByteArrayOutputStream(len)) {
while ((hasRead = in.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
bar = bos.toByteArray();
}
return encoder.encodeToString(bar);
}
public static String dataToBase64(String src) throws UnsupportedEncodingException {
return encoder.encodeToString(src.getBytes(ENCODE));
}
public static byte[] base64ToData(String src) {
return decoder.decode(src);
}
}import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.io.Writer;
import java.nio.file.Path;
import java.nio.file.Paths;
public class Base64Test {
public static void main(String[] args) throws FileNotFoundException, IOException {
testPic();
}
static void testPic() throws FileNotFoundException, IOException {
// 测试图片文件。
Path picPath = Paths.get("./src/com/dragon/001.jpg");
File picFile = picPath.toFile();
String picToBase64 = Base64Util.dataToBase64(picFile);
System.out.println(picToBase64);
long oldSize = picFile.length();
long newSize = picToBase64.getBytes("UTF-8").length;
System.out.println("图片原始大小(字节):" + oldSize);
System.out.println("转换后数据大小(字节):" + newSize);
System.out.println("转换后比原来扩大的比例为:" + (double)(newSize-oldSize)/(double)oldSize + " %");
//将数据写入文件
try (Writer writer = new BufferedWriter(new FileWriter("./src/com/dragon/002.txt"))) {
writer.write(picToBase64);
}
//从文件中读取数据
String line = null;
try (BufferedReader reader = new BufferedReader(new FileReader("./src/com/dragon/002.txt"))){
line = reader.readLine();
}
System.out.println(picToBase64.equals(line));
}
}运行截图

说明:这里将图片转为base64字符串后,使用字符流写入了一个文本文件,然后再使用字符流读取出来,再和原来的字符串进行比较结果为 true。 所以,就完成了对图片数据的读取,可能你这里说你读取的并不是图片的二进制数据,但是其实所有的文件都是以二进制来存储的!而且,这个base64字符串,也是可以直接作为图片来使用的。
注意:我这里已经选取了一个非常小的图片,可以看到原始大小才 3639字节,也就是不到 4 KB,但是如果转换成文字那就是不少了(所以,它会显得很长,非常长。)。
测试图片

然后你可能会问怎么证明这个字符串就是上面这张图片呢?这个也很好办到,如果你对前端的知识有所了解的话,应该知道前端的图片是可以使用base64字符串来表示的,下面写一个 html 文件测试一下。
image.html
<!DOCTYPE>
<html>
<head>
<meta charset="UTF-8"/>
<title>base测试</title>
</head>
<body>
<img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAsICAoIBwsKCQoNDAsNERwSEQ8PESIZGhQcKSQrKigkJyctMkA3LTA9MCcnOEw5PUNFSElIKzZPVU5GVEBHSEX/2wBDAQwNDREPESESEiFFLicuRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUVFRUX/wAARCAFGAkQDASIAAhEBAxEB/8QAGgABAQEBAQEBAAAAAAAAAAAAAAMBBgIEBf/EADQQAQABAwEDCwQCAgIDAAAAAAABAgQRAwUhsRIUMTQ1U1VzdJKkQVFhcRMigZEjojLR8P/EABkBAQADAQEAAAAAAAAAAAAAAAABAgMEBf/EACIRAQABAgYDAQEAAAAAAAAAAAACAREDEhMxUWEhMjNBIv/aAAwDAQACEQMRAD8A+DEMbhk9K1HOAJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHb6XZ9h7ajhLWaPZ1h7ajhLXPLd7WD86ACrUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABxG9jc/dk9Lpo8AASAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAO30ezrD01HCWs0ez7D01HCWueW72sH5xAFWoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADh9/wBT9Nx+WOmjwDeAmg3ewCgbwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdvo9n2HpqOEtZo9nWHpqOEtc8t3tYPziAKtQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHETj6SxsxhkY+rq/HgAf5CgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA7fR7PsPTUcJazS7PsPTUcJa55bvawfnEAVagAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOHMZbiPuyd0ul4DZjDASGMAAAAAAAAAAAAD3Gjq1UxNOlqTE74mKJmJ/U4eZoqiumiaaorqmIimYmJmZ6MRO+QYFX9appqxFUTMTE7piY6YmHudDWpnFWlqROJnfTMboiJmf8RMTP2yDwAAAAAAAAAAAAAAADt9Hs+w9NRwlrNHs+w9NRwlrmlu9rB+dABDUAAAAAAAAAAAABuJmMxEzGM5xuxnGf9iK1swbyZzMcmcxumMb4JpmOmJj9xgL0YAJAAAAAAAAAAAAAAAAcRhjd7HTR4AAkAAAAAAAAAAAAdNsiLrTtraudS9/ir0LmKqaKqsRFMRyeTE7onfOPvKWzrmvTvbzXnWupr07fl6endURVXXiOmZmN0RM5iIxmcfl+LTfXVNMU03WvTTERERGrVEREdERGWc7uf5f5JuNWdTk8nlTqTM46cZznH4RZa793aFxTGjYTq13Fxp6s016tGpb00fyRFcxMzVGZpndEY+sft+3TRNdUxqUTqTOpqxFU6NM08mapmYz0zuommc/WqOnEOI1L671qJp1brW1KZmJmmrUmYmY3xOJl5m41qqqqp1dSaqscqZqnM4nMZ3/Sd/73otVF/LxqVTqaldU0xTM1TM0xGIjM9GPpjow84w2apqqmqqZmqZmZmZzMzPTMsW83QAAAAAAAAAAAAAA7fR7PsPTUcJazS7PsPTUcJa55bvawfnQAVagAAAAAAAAAAAD9O31P+Cma6qacU8rETO+mMR/jfE/fe/MbFVUdFUxuxumejOcJpWzOccz7orqp1rirUmmmYimnlRMxEznMb435wX1XK0645WcasfWZxun77v8AW58M1TMTmZnM5nM5zP3bVqVVREVVVVREzMRMzO/7l/CtMO1bvP1GsQ2GsAAAAAAAAAAAAAAAcRmWdLZyzGXTs8AASAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAO30ez7D01HCWs0uz7D01HCWueW72sH50AFWoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADiJ/LM4bM5ZHS6vx4AAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHb6PZ9h7ajhLWaPZ9h7ajhLXPLd7WD86ACrUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABxE4Yf5HV+PAJ6QAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdvo9n2HpqOEtZo9nWHpqOEtc8t3tYPziAKtQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHEZhk9LcR92T0umlngACQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB2+j2dYemo4S1mj2dYemo4S1zy3e1g/OIAq1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAfk42V4X8ioxsrwv5FSA0zVefpx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPC+NleF/IqMbK8L+RUgGappx4Xxsrwv5FRjZXhfyKkAzVNOPDrtDRttSztpjQ5NMaVMU08qZ5MY3Rn6/t75tb9z/ANpZZ9QtfJp4Lo/W0KfyjzW37mfdLea2/df9pVBa3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90nNbfup90rAW7R5rb91Puk5rb91PulYC3aPNbfup90iwFu3EADMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB2Fn1C18mnguhZdQtfJp4Li8PUAQuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4gBLEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB2Fn1C18mnguhZ9QtfJp4Li8PUAQuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4gBLEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB2Fn1C18mnguhZ9QtfJp4Li8PUAQuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA4gBLEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB2Fn1C18mnguhZ9QtfJp4Li8PUAQuAAAAAAAAAAAABkADIAAAAAAAAAAAAAAAAAADiAEsQAAAAAAAAAAABTR/gzM3E6sRGMRpxE5++czH4TfRa3c2lU10aWnXXmJiquJmYjfmI+0zu3xvjAiuz6L62t9PX0o0o1KK9WqJnQqiM6dMzGImYmcTOd0TviOl9mps7QirUp0tGOTE1UxXVpa1e6JmM5jEZjHT0PzueaVOtRq0WdEalNcVzNWrVVmYnO/P5U09qcivR1KrWivU0qcRqTXVEzOZnOInH1n6SUUrSr6dn2NrrWtNerp01TivFUVTEzyfrMTVHTmOiP3MPM2Ohz3Xp5EcnT0qZp06ZmZrmrERMZmejP3xnD46dpXNGhoaVGpXTTpTMf1qmOVEzGI/ERjEftWraurVdzcTTE4oiimmqqZimImJ6emczG/9l0Wk+naWzre2t9XUoiqmY1JmnGJjEzERTO/oxmY+uH4769faFdxbzo1aOlFM4nNMTGJjdExGcbozGOjfnpfILxv+gAsAAAAAAAAAAAA7Cz6ha+TTwXQs+oWvk08FxeHqAIXAAAAAAAAAAG6cUzXTy/8Ax+u9hEzTVTVEZxMThKJeaL16enTFUx0xmYxEzEYj9/l5nSp5ETvziM8mcz0Z6JZVrzVTNPJiIqjEzl4muqrEVb6YxiI3fjpT4Y0jJX+Oj+XUiN/Jxin9/WP9mppcmI/pvmr6RMZjf90/5JmqqqaYnlYzE9G7H/or1a64iKojMYxP1j7/AOzwZZKzp6f9ojP9N0zysf8A32Qh7/nrmKt8xypznlTu/EQ8Fel4UlTcAVaAAAAAAAAAAAAAAOIASxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdhZ9QtfJp4LoWfULXyaeC4vD1AELgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOIASxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdhZ9QtfJp4LoWfULXyaeC4vD1AELgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOIASxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdhZdQtfJp4LoWfULXyaeC4vD1AELgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOIASxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdhZdQtfJp4LoWfULXyaeC4vD1AELgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOIASxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAdhZdQtfJp4LgLw9QBC4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAD//Z"/>
</body>
<html>打开浏览器测试一下
说明: 它的具体用法如下:
<img src="https://img-blog.csdnimg.cn/2022010703315790409.jpeg">
图片的大小相对于字符来说,其实是很庞大了。我这里的html代码是完整的图片的base64编码字符串,然后我的博客的字数就变大了很多。
public class Base64Test {
public static void main(String[] args) throws FileNotFoundException, IOException {
testStr("I love you yesterday and today!");
}
static void testStr(String src) throws UnsupportedEncodingException {
//测试文本数据。
String strToBase64 = Base64Util.dataToBase64(src);
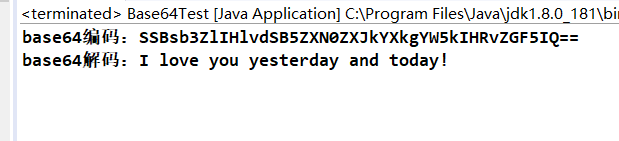
System.out.println("base64编码:" + strToBase64);
String base64ToStr = new String(Base64Util.base64ToData(strToBase64));
System.out.println("base64解码:" + base64ToStr);
}
}测试截图
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME, 在XML中存储复杂数据。 注1:互联网上也有很多可以进行编解码的网站,如果需要使用的话,可以取尝试一下。
注2:可以观察一下这个base64字符串的特点,我上次学习Java爬虫的时候,爬了一个网站,发现这个网站的一个 script 脚本中,含有一个json对象,其中有一个属性是 url,但是对应的链接却看不懂(base64字符串是不可读的),但是我感觉它就是base64字符串,所以我利用base64编解码网站解码一看,真的是一个网站的地址。然后,就可以写一个解码方法,当爬到这个数据时,给它解码了,哈哈。
举一个简单的例子:
{"url":"aHR0cHMlM0ElMkYlMkZ3d3cuYmFpZHUuY29tJTJG"}import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.Base64;
import java.util.Base64.Decoder;
import java.util.Base64.Encoder;
public class TestALittle {
public static void main(String[] args) throws UnsupportedEncodingException {
String base64Str = "aHR0cHMlM0ElMkYlMkZ3d3cuYmFpZHUuY29tJTJG";
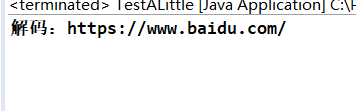
String de_str = base64ToUrlEncoderToURL(base64Str);
System.out.println("解码:" + de_str);
}
//base64解密为urlencoder,再解码为url
public static String base64ToUrlEncoderToURL(String base64Str) throws UnsupportedEncodingException {
Decoder decoder = Base64.getDecoder();
byte[] bt = decoder.decode(base64Str);
String en_str = new String(bt, 0, bt.length);
return URLDecoder.decode(en_str, "UTF-8");
}
}
说明: 这个例子中的 url 进行了两次编码,第一次是将url中的非西欧字符编码(可以去了解一下为什么这么做?),然后再使用base64编码。但是,如果你掌握了解码技术,解码也是很简单的。(但是如果你看不出来它是base64编码,那估计就没有办法了!)
以上就是“Java怎么使用字符流读写非文本文件”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://blog.csdn.net/qq_40734247/article/details/104418843



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



