这篇文章给大家分享的是有关HTML元素属性测试的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
code 元素的含义(语义)为“代码内容”,FireFox 在渲染该元素时,会将 code 标签内容显示为“等宽字体”(每个字符的宽度相等),这就造成了元素的语义和呈现形式混杂在一起;正确的做法是:浏览器应该无视 code 元素由于历史原因遗留下来的默认呈现效果(等宽字体)。
语义元素仅仅说明文档内容的结构与含义,例如 code 表示文档中的代码;video 表示文档中的视频;用 CSS 控制这些元素呈现给用户的形式(将 code 元素的内容用等宽字体呈现给用户),这就做到了内容与呈现分离,例如对于下面这个文档:
<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="Content-type" content="text/html;charset=utf-8" />
<title>XssPayloadTest</title>
</head>
<body >
<div>
this is normal textNode<br>
<code>this is normal textNode include in code element</code>
</div>
</body>
</html>渲染效果如下:
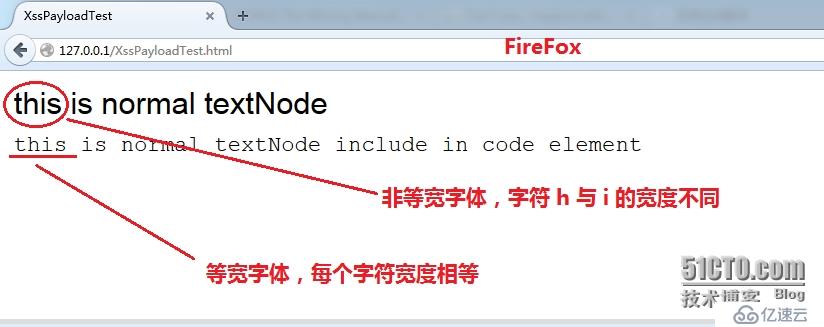

另外,虽然 chrome 默认也会改变 code 标签内部的字体样式,但是其效果不明显,无法区分等宽与非等宽字体,如下:
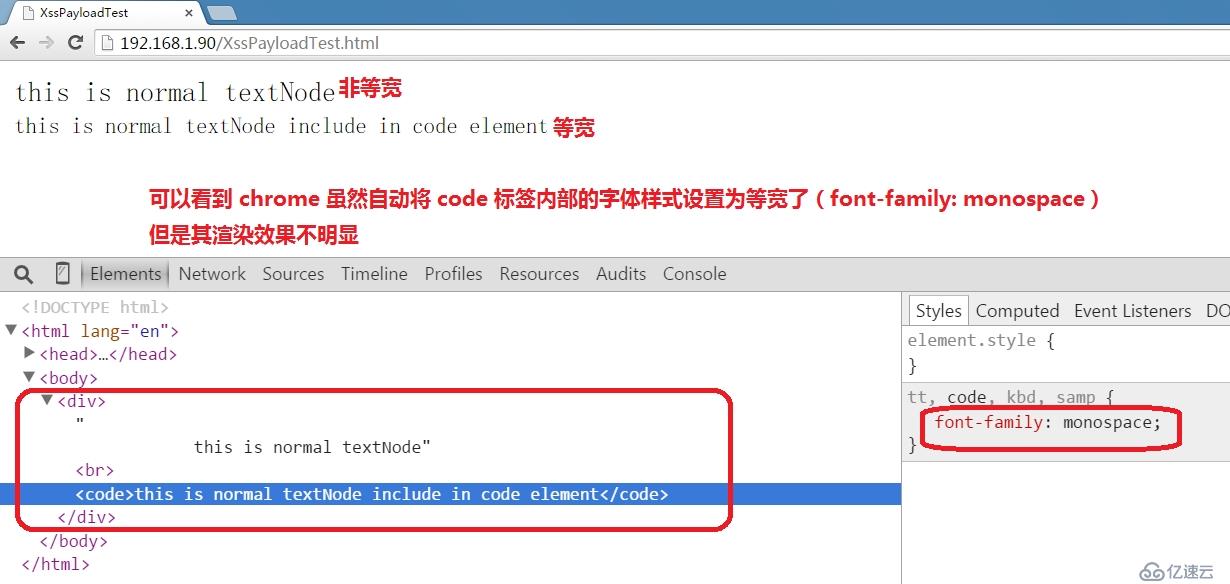
小结:上述三种浏览器都没有将语义元素与其呈现效果分离这一概念实施的很好,开发者可以通过 CSS 改变 code 元素的“默认”样式。
《getElementById(),getElementsByTagName(),getElementsByClassName()的比较》
第一个函数是通过元素的 id 属性选择元素,其 id 属性是独一无二的,不能将2个元素设置相同的 id ,因此第一个函数返回的结果只有一个元素;
第二个函数通过元素的“标签名”选择元素,正如一个 HTML 文档中,可能包含多个 div 元素,a 元素等等,这能够选择所有标签名称相同的元素(从其名称中的 Elements 即可看出,相反,通过 id 选择的函数,其名称中的 Element 后面没有 s),因此它返回的结果是多个拥有相同标签名的元素集合,在实际的开发编程中,通常使用一个 javascript 变量来保存这些元素,然后通过 C 数组风格的语法来访问单独的元素;
第三个函数通过元素的“类名”选择元素,元素的标签名是 HTML 规范定义的,而且构建 DOM 树时依赖于标签名;相反,类名作为元素可选属性的一部分,需要用户定义,且构建 DOM 树时一般不依赖于类名。
类名能够将 HTML 文档中,各种标签相同的和标签不同的元素划分成同一类,然后通过第三个函数就能引用这些元素,因此它返回的同样是元素集合,需要通过数组进行访问,而且经常在一个 for 循环中遍历每个元素,设置每个元素的其余属性;
类名也经常用作为 CSS 的类选择符,为相同类名的元素应用同一种样式;
最后,书写代码时需要注意 Element 单词的形式,少了 s 或多了 s ,浏览器和开发工具都会报错的。
在 Chrome 与 FireFox 的实现中,getElementsByTagName() 返回的是一种叫做“HTMLCollection”(HTML 集合)的类数组,它不是真正的 javascript 语言核心定义的数组,因此两者在“读写性能”上有所差异。
如果在文档中需要通过 getElementsByTagName() 选择大量相同的元素对其进行读写操作,可以先将其转换为 javascript 数组后再进行读写,其速度会有明显的提升。使用 Array.prototype.slice.call() 就可以转换为 javascript 数组。
为了说明两者的性能差距,考虑如下代码:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=utf-8" />
<title>XssPayloadTest</title>
</head>
<body>
<div id="SpanElementTest">
</div>
<script>
for (var i = 0; i < 2000; i++){
var newspanelements = document.createElement("span");
document.getElementById("SpanElementTest").appendChild(newspanelements);
newspanelements.appendChild(document.createTextNode("span" + i + " "));
}
var nodelist = document.getElementsByTagName("span");
document.write(nodelist instanceof HTMLCollection);
document.write("<br>");
document.write(nodelist.length);
document.write("<br>");
var convertnodelistToArray = Array.prototype.slice.call(nodelist);
document.write(convertnodelistToArray instanceof Array);
console.time("逐一获取每个span元素,且每次都读取其长度所花费的总时间");
for (var i = 0; i < 2000; i++){
for (var j = 0; j < nodelist.length; j++){
nodelist[j];
}
}
console.timeEnd("逐一获取每个span元素,且每次都读取其长度所花费的总时间");
console.time("逐一获取每个span元素,所花费的总时间");
for (var i = 0; i < 2000; i++){
for (var j =0, len = nodelist.length; j < len; j++){
nodelist[j];
}
}
console.timeEnd("逐一获取每个span元素,所花费的总时间");
console.time("将span元素集合转换成Array对象后,再逐一读取,且每次都读取其长度所花费的总时间");
for (var i = 0; i <2000; i++){
for (var j = 0; j < convertnodelistToArray.length; j++){
convertnodelistToArray[j];
}
}
console.timeEnd("将span元素集合转换成Array对象后,再逐一读取,且每次都读取其长度所花费的总时间");
console.time("将span元素集合转换成Array对象后,再逐一读取,所花费的总时间");
for (var i = 0; i < 2000; i++){
for (var j =0, len = convertnodelistToArray.length; j < len; j++){
convertnodelistToArray[j];
}
}
console.timeEnd("将span元素集合转换成Array对象后,再逐一读取,所花费的总时间");
</script>
</body>
</html>以上代码第11~15行的 for 循环首先创建 span 元素,然后将其作为 id 为 SpanElementTest 的 div 元素的子元素添加,并且设置 span 元素内部的“文本节点”,如此过程重复2000次,最终结果就是该 HTML 文档页面中包含了2000个span元素,其内部的文本节点从 span0~span1999。
第17行通过 getElementsByTagName() 选择这2000个span元素,用变
量 nodelist 来保存这个 HTMLCollection 对象,浏览器运行第18行的代码应该输
出布尔值 true,表明 nodelist 确实是一个 HTMLCollection 对象;第20行读
取 nodelist 的长度,将输出 2000;第 22 行通过
Array.prototype.slice.call() 将 nodelist 转换为 javascript 内置的
数组类型并用变量 convertnodelistToArray 保存,第 23 行输出 true ,证明
了 convertnodelistToArray 是 Array 对象(javascript 数组)。
第25~31行测量在一个嵌套的 for 循环中,内层循环逐个取得 nodelist 对象中的每个 span 元素,每次都检查是否超过对象长度(nodelist.length),外层循环将这个过程重复 2000 次,计算总花费时间并输出至浏览器开发者工具的控制台窗口;
第 33~39行将同样过程重复 2000 次,但是内层的 for 循环仅读取一次 nodelist 对象的长度,然后保存在另一个变量中,省略每次都去读取 nodelist.length 的操作,然后同样在控制台输出这个过程总花费时间;
第41~47行对 convertnodelistToArray 执行相同的操作并且输出总花费时间,由于它是数组,因此读写速度会快很多,即便每次都访问该对象的长度来判断也一样很快;
第49~54行执行相同操作,并且省去每次访问 convertnodelistToArray 的长度的步骤,后面用浏览器测试代码时我们会看到,因为它已经是数组了,因此这省去的操作并没有获得明显的性能优化,下面是 Chrome 与 FireFox 的测试截图:
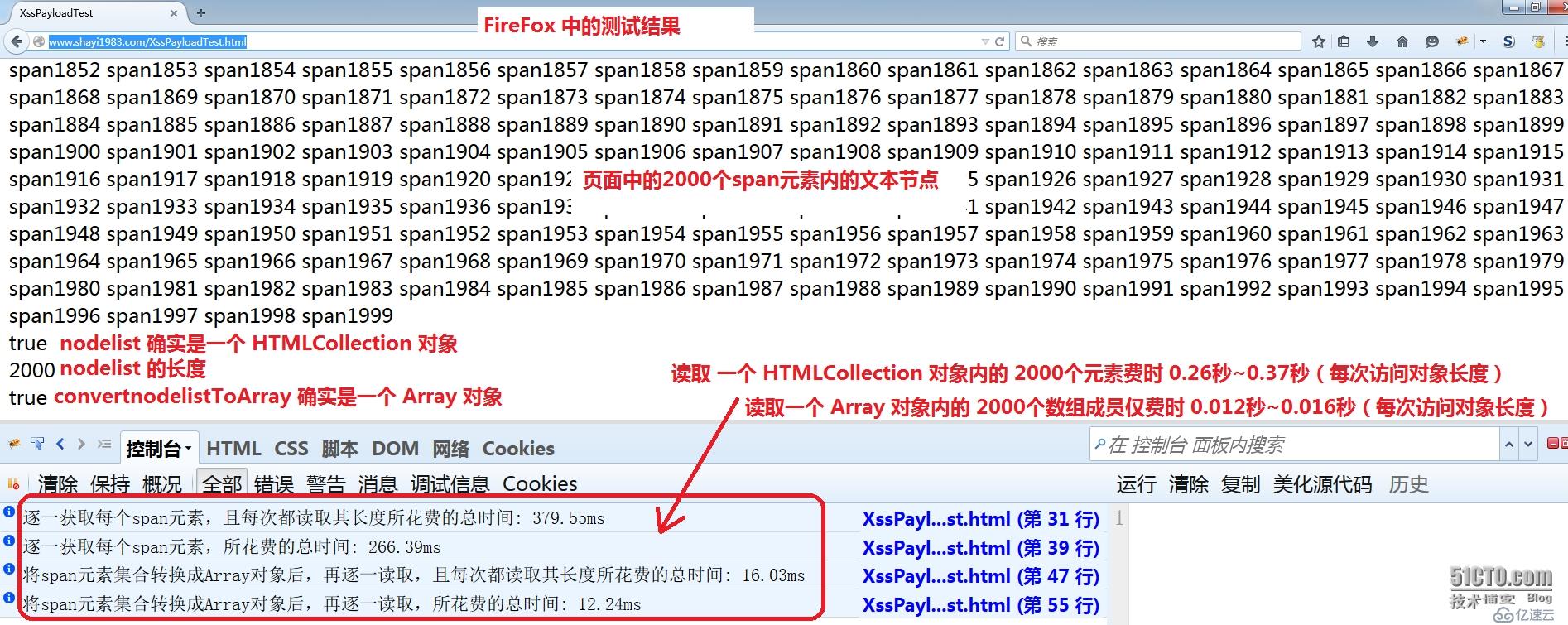
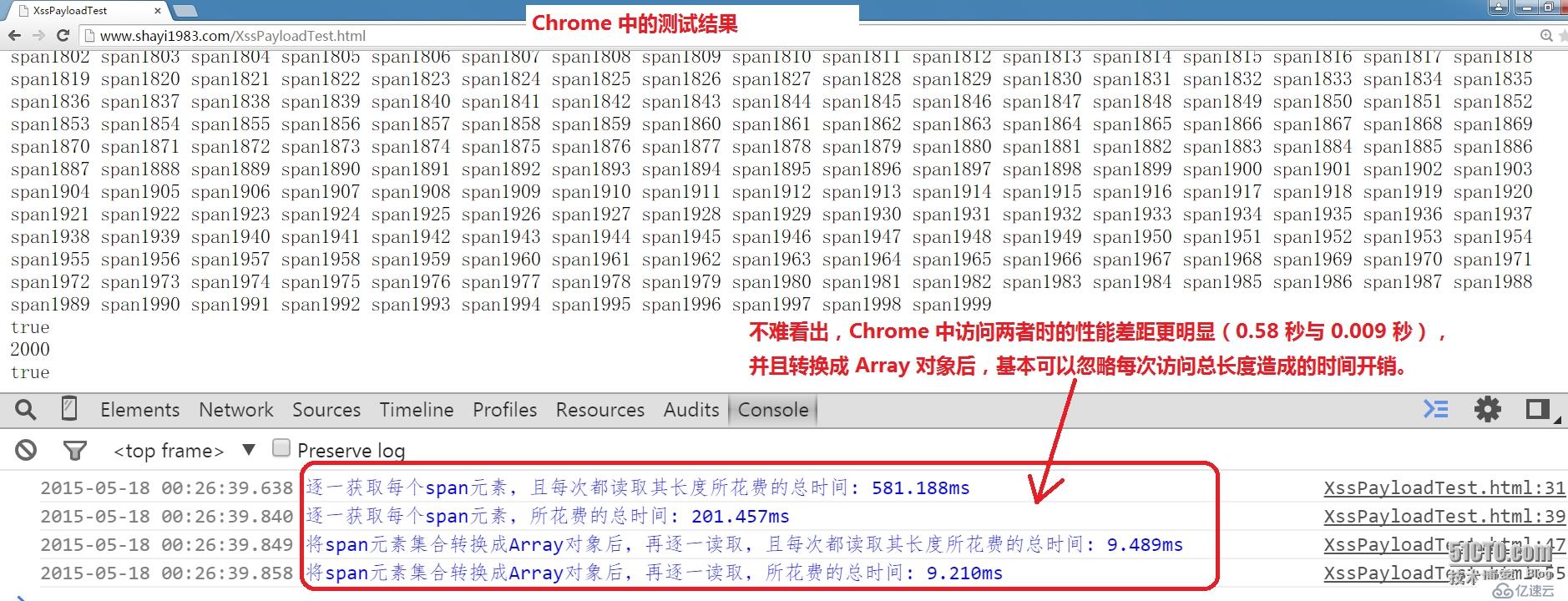
通过上面的测试,前端攻城狮们应该可以在实际开发中按需选择getElementsByTagName() 或者先通过 Array.prototype.slice.call() 调优性能了。
上面提到过 getElementsByTagName() 返回的是 HTMLCollection 对象 ,其它类似的(开发中经常用到的)还有 :
document.p_w_picpaths ,用于表示文档中所有的 img 元素;
document.applets,用于表示文档中所有的 Java Applet 二进制应用程序;
document.links,用于表示文档中所有的设置了 href 属性和值的元素;
document.forms,用于表示文档中所有的表单元素;
上面这些都是 HTMLCollection 对象 ,以 document.p_w_picpaths 为例子:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=utf-8" />
<title>XssPayloadTest</title>
</head>
<body>
<div id="SpanElementTest">
</div>
<script>
for (var i = 0; i < 10; i++){
var newimgelements = document.createElement("img");
document.getElementById("SpanElementTest").appendChild(newimgelements);
}
document.write(document.p_w_picpaths + "<br>");
document.write(document.p_w_picpaths.length + "<br>");
document.write(document.p_w_picpaths[3]);
</script>
</body>
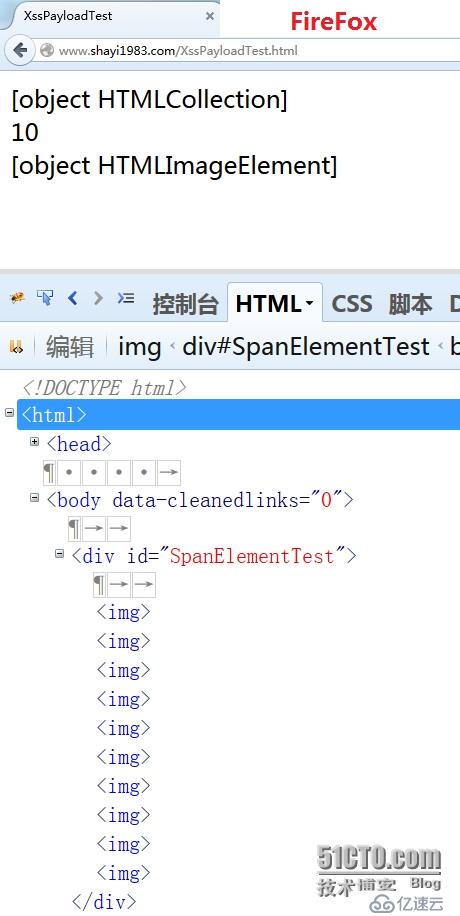
</html>创建10个 img 元素,并且作为 div 元素的子元素(节点)添加,按理讲,我们可以通过 getElementsByTagName() 获取这10个 img 元素并将其保存在一个变量中,然后输出该变量的类型,应该为 HTMLCollection 对象 ;但是这里为了证明
通过 document.p_w_picpaths 访问的就是这10个 img 元素集合,第15行会输出 object HTMLCollection;第16行输出10;第17行以 C 数组表示法访问 HTMLCollection 对象 中,单个 img 元素的类型:HTMLImageElement :

《使用 javascript 操纵 HTML 元素,设置样式,改变页面布局的小例子》
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=utf-8" />
<title>XssPayloadTest</title>
</head>
<body>
<script>
function OutputDebug(msg){
var log = document.getElementById("debuglog");
if (log == null){
log = document.createElement("div");
log.id = "debuglog";
log.innerHTML = "<h2>Debug Log</h2>";
document.body.appendChild(log);
}
var pre = document.createElement("pre");
var text = document.createTextNode(msg);
pre.appendChild(text);
log.appendChild(pre);
}
OutputDebug("hello,shayi1983!");
var TextArea = document.createElement("textarea");
document.body.appendChild(TextArea);
//TextArea.style.display = "none";
TextArea.style.visibility = "hidden";
TextArea.className = "textarea001";
if (TextArea.className == ""){
TextArea.className = "textarea001";
}else{
TextArea.className += " textarea999";
}
</script>
</body>
</html>上面代码第9~21行的函数用于执行选择,创建,修改元素,并赋予元素的各种属性值,以及修改页面布局等操作:
首先第10行通过 id 选择元素,由于代码执行到此处时,页面中不存在 id 为 debuglog 的元素,因此 log 变量为 null,导致执行第11~16行的 if 语句块的内容:创建 div 元素,将其 id 属性的值设置为 debuglog (既可以通过 HTML 元素语法的 id 属性设置,也可以像这里一样通过 javascrip 变量对象来设置 id 属性),然后在 div 元素内部添加 h2 元素及其文本节点,最后将“组装”好的 div 元素作为 body 元素的子元素添加(改变了页面布局和结构);
第17~20行再次通过 javascript 动态组装元素并添加至页面 DOM 树中:
第17行创建 pre 元素,第18行以调用该函数传递的字符串参数为内容来创建文本节点(document.createTextNode() 接收传递进来的字符串作为参数);
第19行将上述文本节点添加至 pre 元素内部;第20行将 pre 元素添加至 div 元素内部。代码执行至此,通过 javascript ,整个页面文档体的结构已经变成如下所示(不考虑 script 标签):
<body>
<script>
<div id="debuglog">
<h2>Debug Log</h2>
<pre></pre>
</div>
</body>可以看出,对象的 appendChild() 方法是按照调用的先后顺序,依次在文档中添加元素的。还有一个容易混淆的地方:document.createElement() 方法的参数为元素(标签名),需要使用单引号或双引号包含;而 appendChild() ,createTextNode() 方法的参数是存储元素的变量,不需要引号包含(createTextNode() 方法的参数也可以是引号包含的“字符串字面值”,不需要一定是用变量保存的字符串引用),这一点必须注意,引号用错对象同样会导致浏览器开发工具或网页开发 IDE 工具报错。
我们继续,第22行实际调用上述函数,导致在 pre 元素内部添加了文本内容“hello,shayi1983!”,该内容最终会输出至页面;
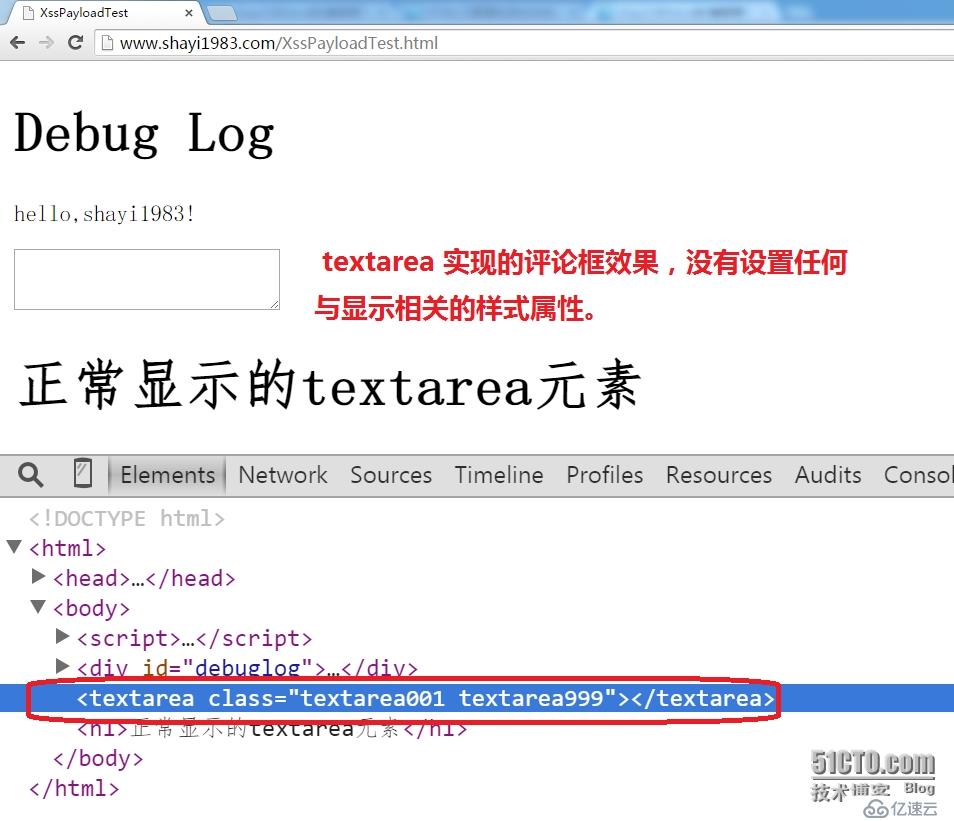
第23行创建元素 textarea,这是一个实现用于发表评论时的文本输入区域的元素;
第24行将 textarea 作为 body 的子元素添加,考虑到 appendChild() 的特性,
textarea 将被添加到 div 元素的后面。
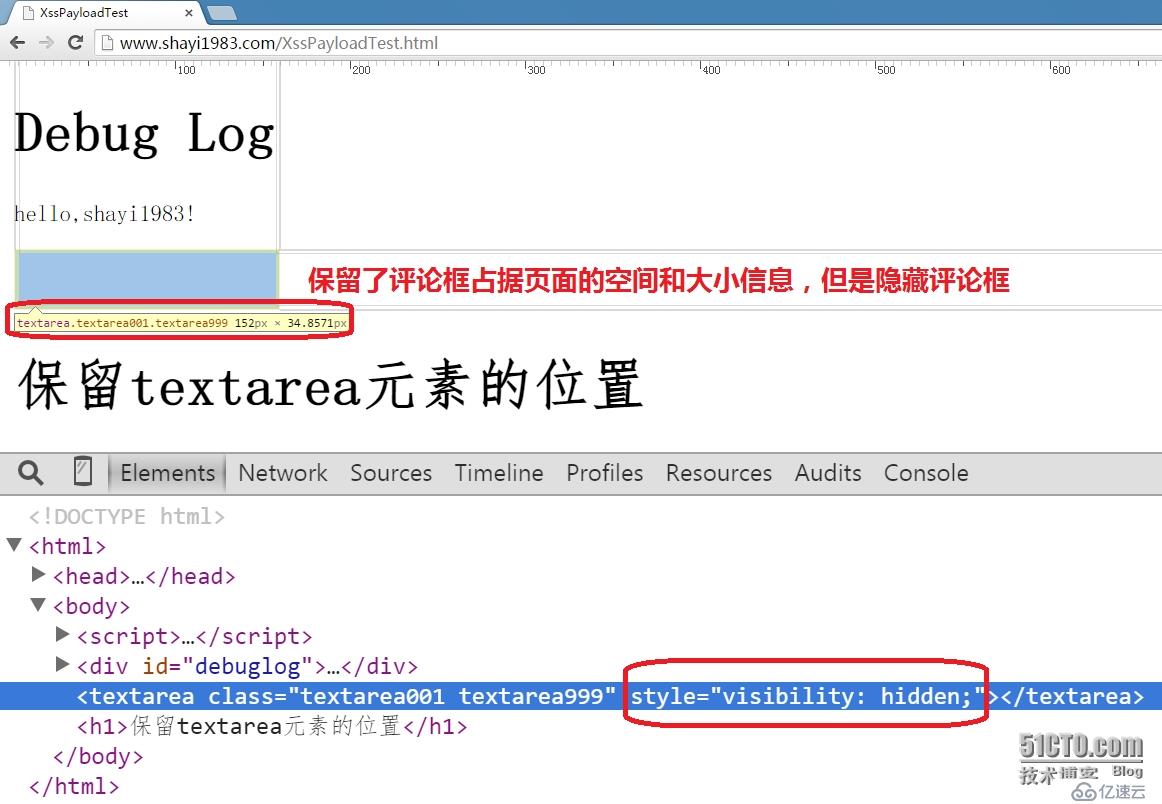
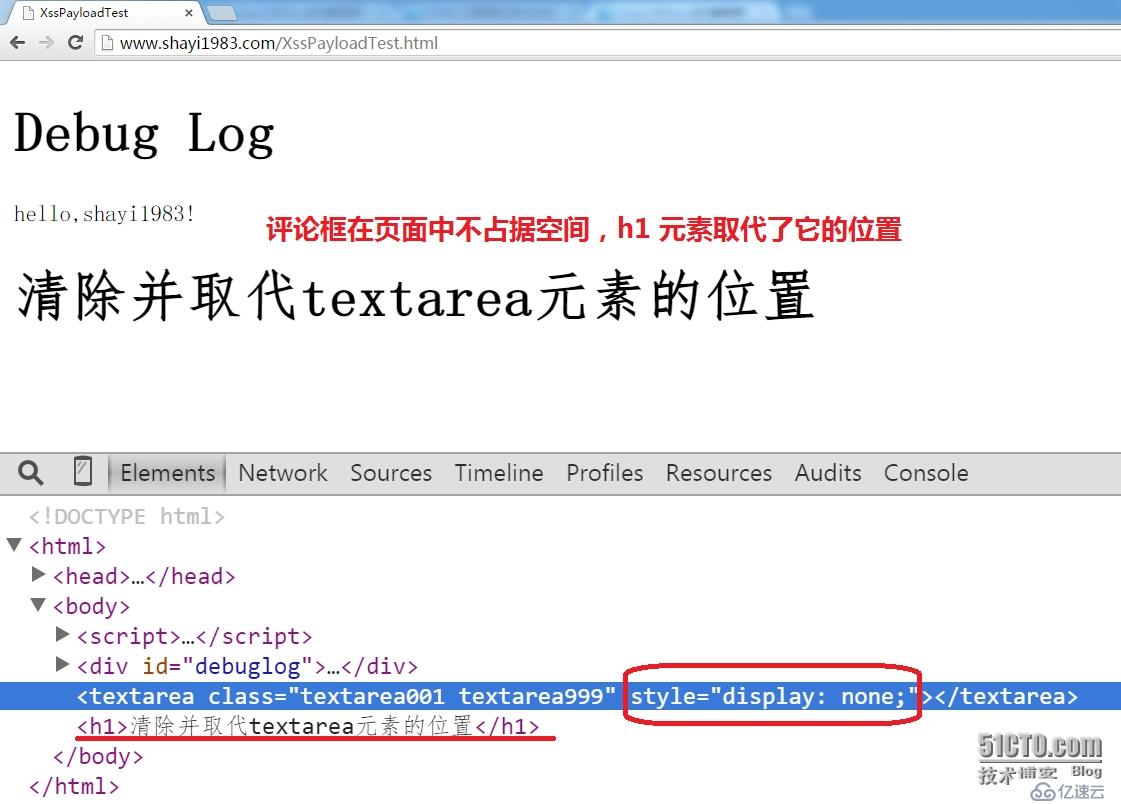
第25行和第26行的代码两者只能选其一,另一个必须注释掉,可以交互注释来测试执行结果:元素的 style 属性是 HTML 规范定义的,存储了(可见)元素的样式,外观视觉效果等信息,我们同样能够借助 javascript 来对其进行操作,不必用到 CSS 样式表。例如,第25行将 textarea 元素样式的 display 属性值设置为 none,其最终效果是浏览器将不显示评论框,尽管该元素实际存在于 DOM 树中;第26行将 textarea 元素样式的 visibility 属性值(可见性)设置为 hidden,浏览器同样不会显示评论框,但是可以通过开发者工具查看该元素在页面中的位置(保留元素占据页面的空间),而 display = "none" 会导致清除元素占据页面的空间 :
我们继续,第27行通过 javascript 来设置元素的“类名”,需要用到 className 这个对象属性(作为对比,HTML 规范中则是设置元素的 class 属性,两者的效果相同);第28~32行展示了通过 javascript 设置元素类名称的灵活性:可以追加多个类名称。重点关注第31行的代码,它结合了字符串连接运算符加号(+)与赋值语句中的等号(=)构成简洁的追加类名称的操作,还要注意,用引号包含的第2个类名称 textarea999 的前面有一个空格符,这是由于 HTML 标准规定了同一个元素的多个类名称必须用空格分开,如果缺少这个空格符,那么浏览器会将其与第一个类名 textarea001 作简单的字符串连接运算,得到单一的类名 textarea001textarea999,各位可以自行测试。
《对比各种HTML页面起始处的文档声明》
下面这个文档声明节选自百度:
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">该文档声明为 HTML5 文档。
html 元素中,应该使用 lang 属性设置页面的语言,这样 web 搜索引擎的爬虫可以在抓取页面时通过语言进行分类,创建索引,然后对搜索用户返回他/她 指定语言的页面。
下面这个文档的起始片断节选自博文视点:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>该文档声明为 XHTML 1.0 严格语法型文档,这导致浏览器能容忍的页面语法错误更少,并且在 html 元素中添加 xmlns 命名空间属性。但是同样没有指定页面语言,与百度不同,前者自身就是 web 搜索引擎,因此其提供信息检索服务的主页面可以不用指定页面语言;但是普通的 web 站点原则上需要指定页面语言。
百度页面中对某个 div 元素直接定义 CSS 样式的例子:
<div id="debug" >如果使用基于元素 id 的 CSS 选择符,通过独立的 style 标签来为该 div 元素定义样式,则上例的效果等同于下例:
<style type="text/css">
#debug{
display:block;
position:absolute;
top:30px;
right:30px;
border:1px solid;
padding:5px 10px;
}
</style>注意,在第一则应用CSS的例子中,通过HTML元素的共同全局属性 style 来设置并应用CSS,称为元素内嵌样式;第二则应用CSS的例子中,通过在HTML文档添加 style 元素,然后在其中使用CSS选择符(包括基于元素id,类名,元素名,以及结合使用三者进行选择)来设置并应用CSS,称为文档内嵌样式;还有一种设置并应用CSS的办法:通过在文档头(head 元素)中添加 link 元素,然后将其 href 属性值设为与该文档相同本地存储路径下的某个以“.css”后缀的文件,称为外部样式表。
下面的代码展示了在一个HTML文档中结合使用这三种方式:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Apocalypse Now</title>
<link rel="stylesheet" href="ApocalypsePage_Original.css">
<style type="text/css">
body {
font-family: "Lucida Sans Unicode", "Lucida Grande", Verdana, sans-serif;
max-width: 1920px;
}
.Header {
background-color: #7695FE;
border: thin #336699 solid;
padding: 10px;
margin: 10px;
text-align: center;
}
.Header h2 {
margin: 0px;
color: white;
font-size: xx-large;
}
.Footer p a {
margin: 5px;
color: red;
}
</style>
</head>
<body>
<div class="Header">
<h2 >How the World Could End</h2>注意,第6行 link 元素的 rel 属性值 “stylesheet”用于告诉浏览器引用的外部文件是层叠样式表;href 属性值为具体的样式表文件名称(可以使用基于 web 服务器定义的网站根目录映射到本地文件系统目录的相对路径。例如,对于 apache web 服务器而言,网站根目录映射到本地文件系统目录为 “X:\apache2.2\htdocs”,则当前HTML文档与样式表文件必须都放置在这个目录下,浏览器在解析 link 元素的时候才能向远程服务器请求相同路径下的样式表文件)
第27行使用CSS的元素类名称选择符(前面有实心ASCII句点)结合多个元素名的方法,选择类名为 Footer 元素内的 p 元素内的 a 元素,对其应用花括号内的样式(正确的方法是对 p 和 a 元素设置类名,然后使用3个以实心ASCII句点起始,后接各自类名称,并以空格符分开的连续CSS选择符来选择 a 元素,当没有设置子元素的类名时,才直接用元素名进行选择)
第37行通过HTML元素的全局属性 style ,直接对 h2 元素设置并应用样式,注意,对 body 和 div 元素应用的样式会累加到 h2 元素上面(因为在该文档的 DOM 树结构中,h2 分别是前2者的子元素和“孙”元素,继承了它们的样式属性),而当产生冲突时,以 h2 元素的 style 属性定义的样式为准。
《Javascript 语言核心,语法重点实践》
下面首先给出某项语法,词法定义,然后在浏览器的控制台中加以验证:
1。javascript 采用 IEEE 754 标准定义的64位浮点格式来表示数字,且不区分整数与浮点数,下面测试遵循 ECMAScript (javascript 的一种国际标准)的浏览器 javascript 解释器支持的数字范围:(以 Chrome 与 FireFox 为例)
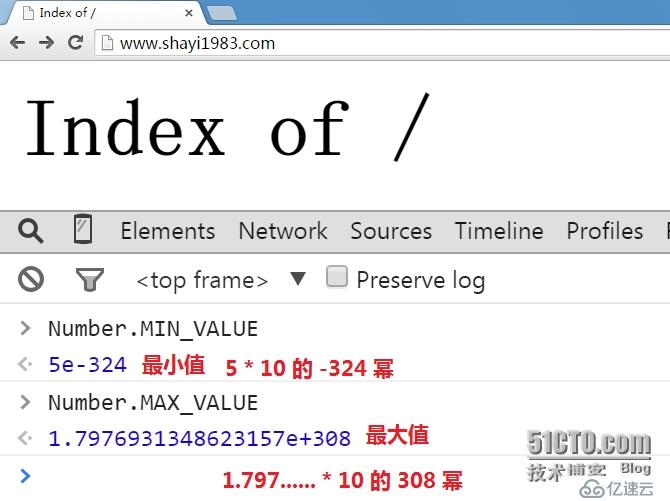
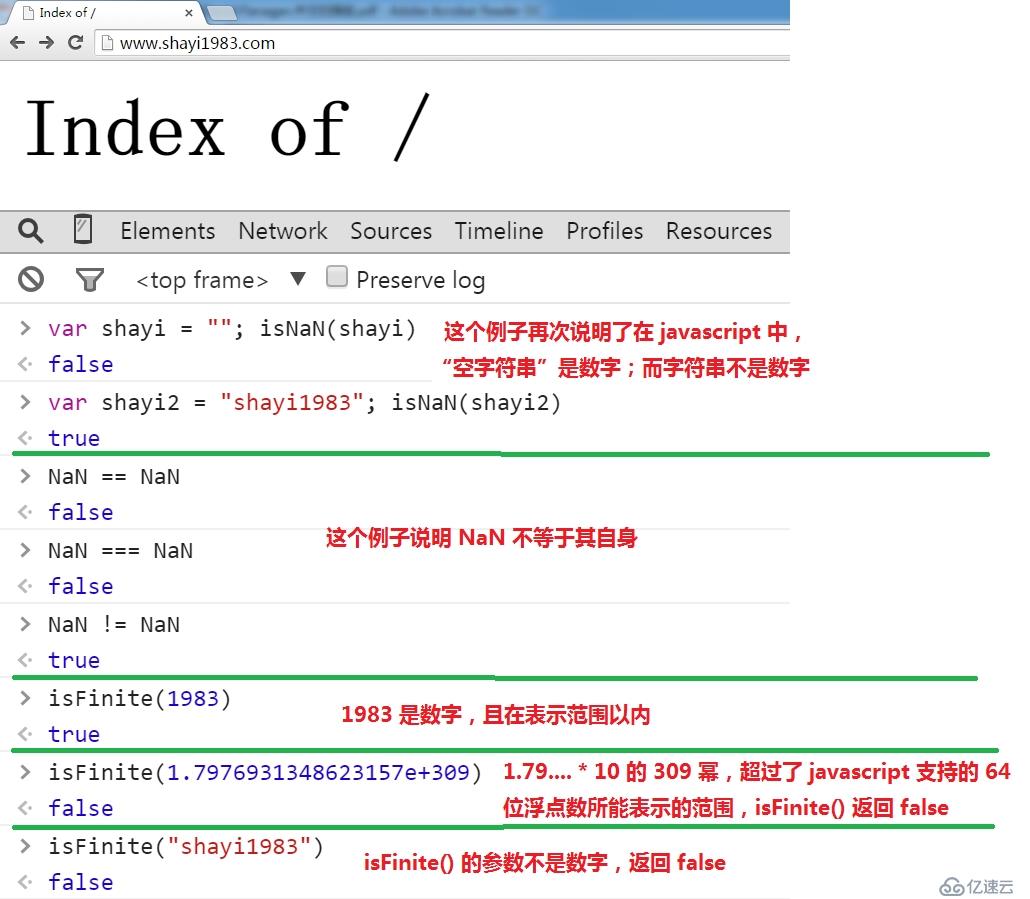
上面的最小与最大值都是 Number 对象的属性之一,在 ECMAScript 5 中,所有 Number 对象的属性值,以及 Infinity(标准预定义的全局变量,正无穷),
-Infinity(负无穷),NaN(标准预定义的全局变量,Not A Number,不是数字)等,都是只读的,其值无法修改:
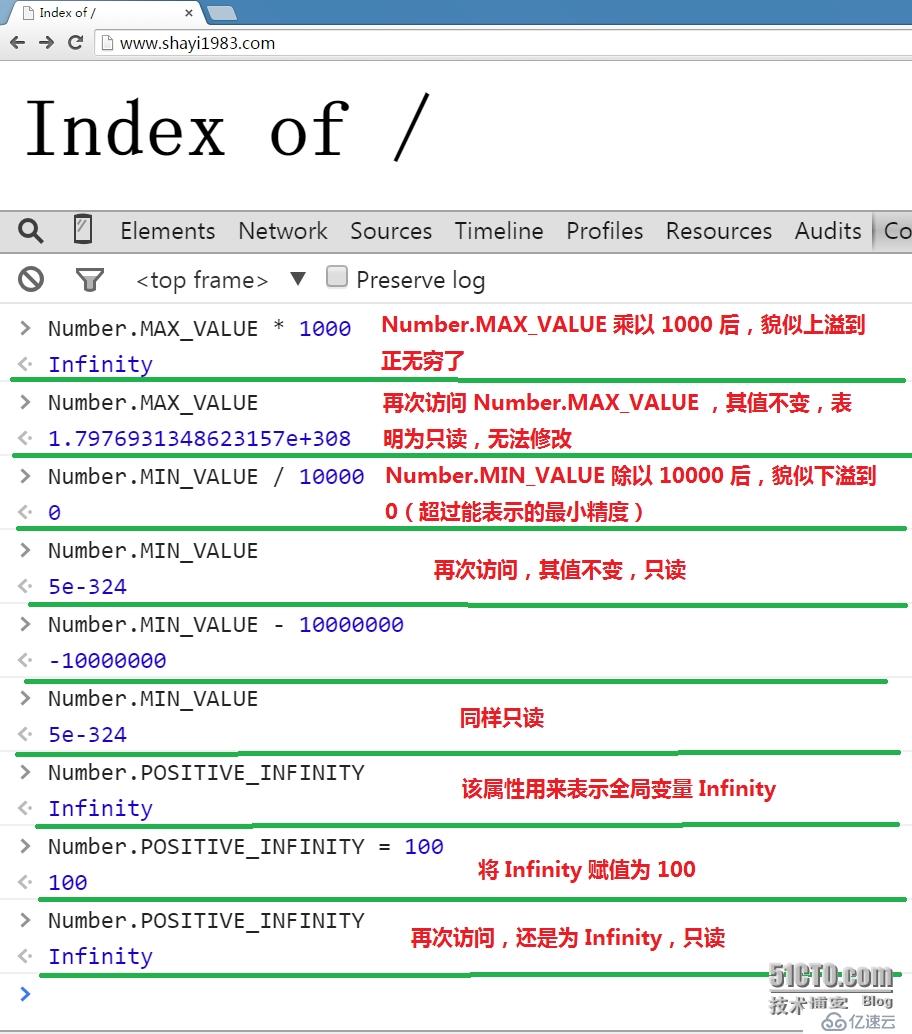
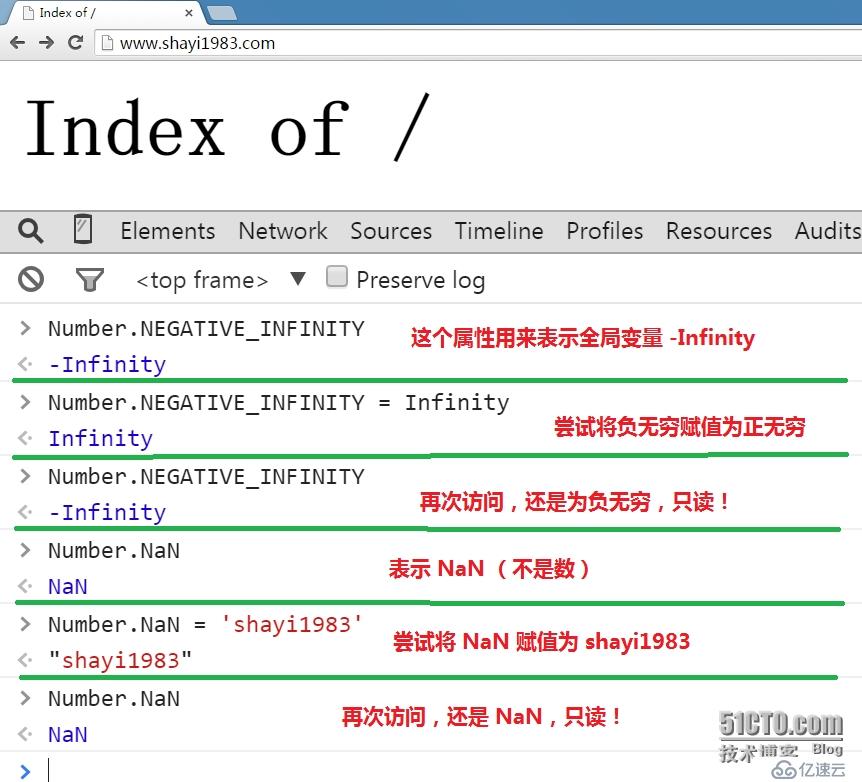
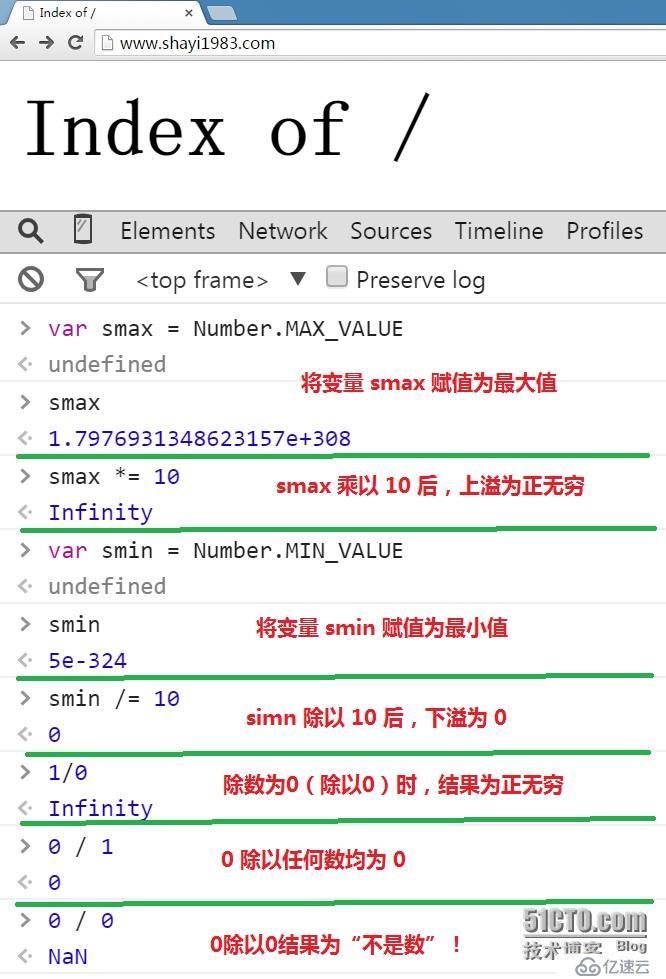
2。一些算术运算规则:
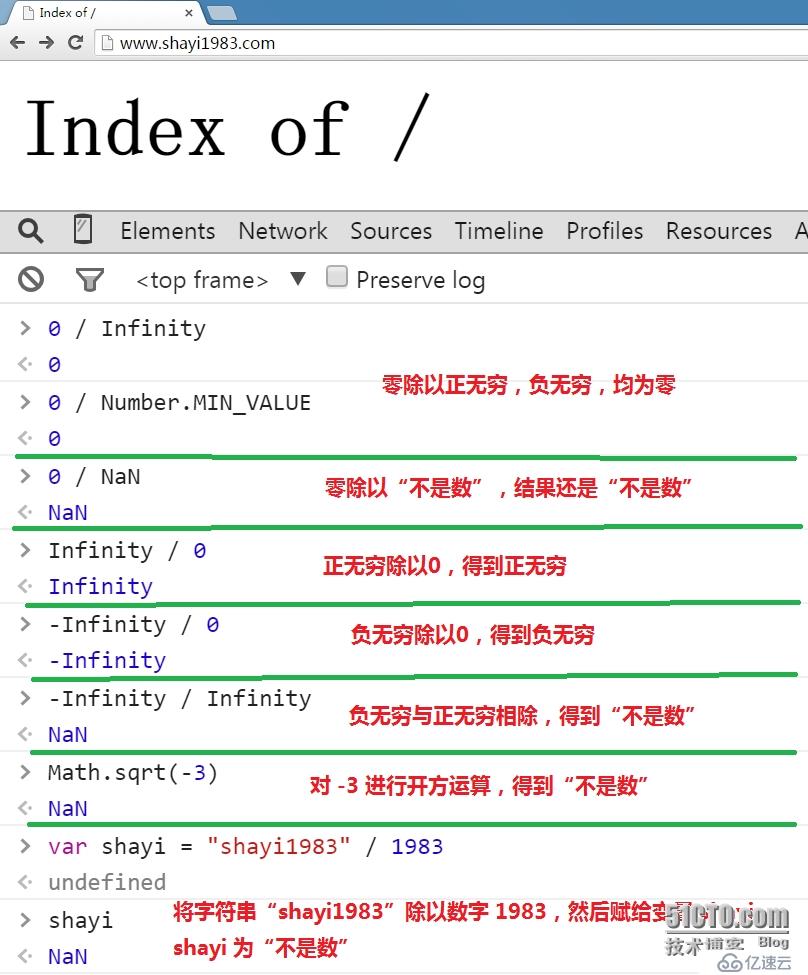

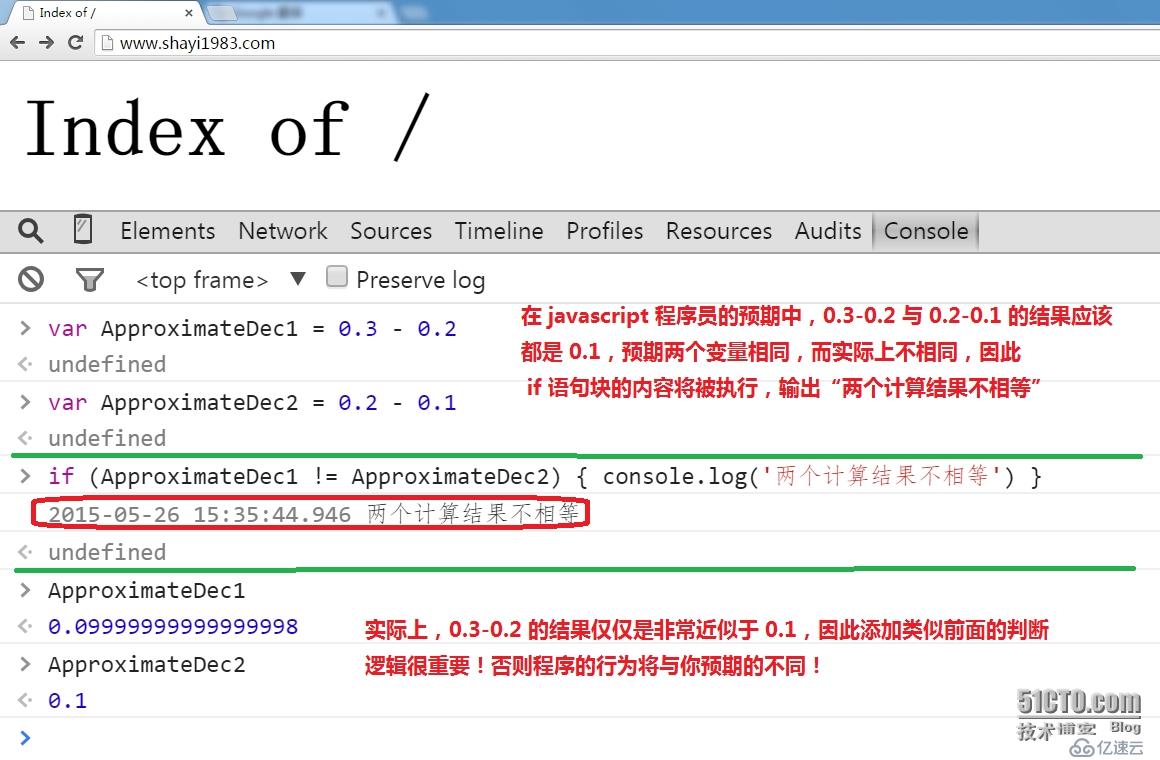
3。javascript(ECMAScript)标准中使用的 IEEE 754 浮点数表示法,可以精确表示基于2的幂的分数转换成的浮点数(1/2,1/8,1/256,1/1024。。。。。),但是无法准确表示基于10的幂的分数转换成的浮点数(1/10,3/10。。。。)在进行2个浮点数的减法运算操作时,尤其要注意这一点,最好能够先判断结果是否相等,看下面的例子:
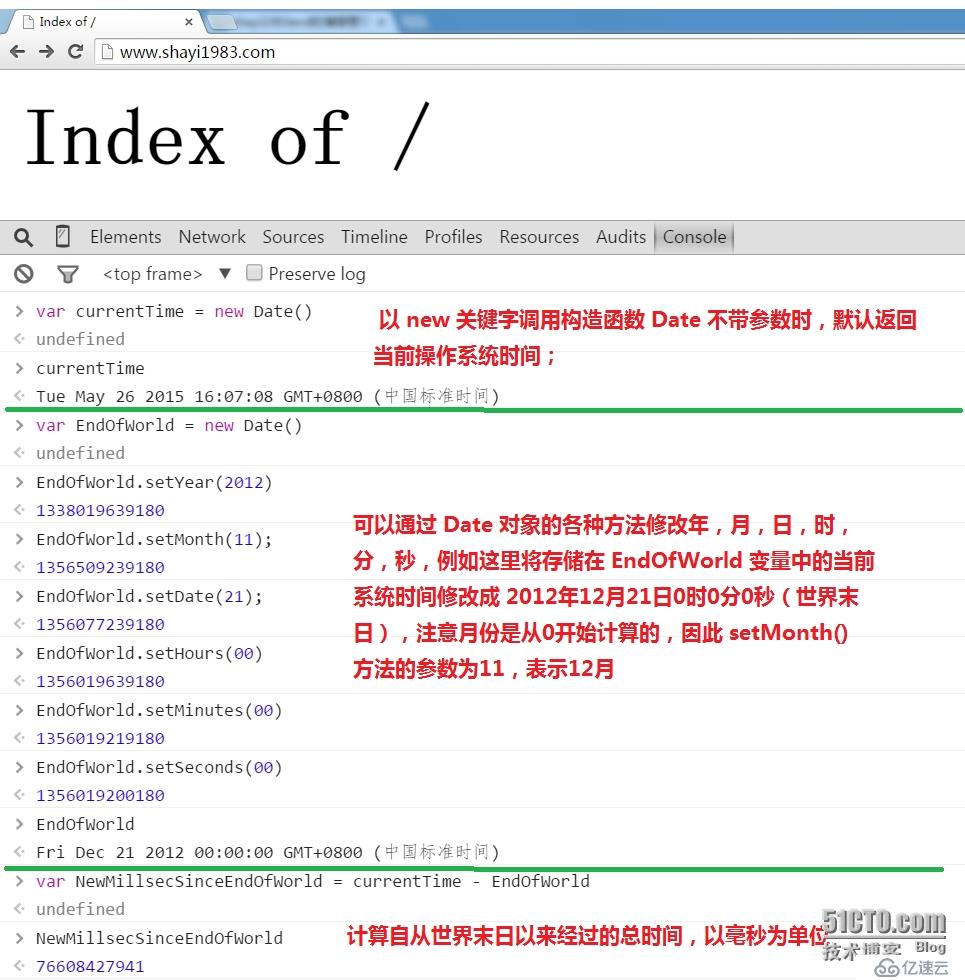
4。Date 类(表示日期和时间)的基本操作:
创建 Date 类的对象需要使用构造函数 Date(),Date 对象包括一系列用来表示日期和时间的属性,方法,下面是简单的演示:
5。在 javascript 中使用 escape sequence (转义序列/字符),unicode 字符,以及字符串连接运算符(加号)
直接来看一个例子:
<p><span class="LeadIn">Right now</span>, you're probably feeling pretty good. After all, life in
the developed world is comfortable<span class="style1">—</span>probably more comfortable than it's
been for the average human being throughout all of recorded history.</p>
<script>
var normalPelement = document.getElementsByTagName('p');
normalPelement[2].textContent += '\u005cI\'m a javascript \u03c0 programmer !\\';
var unicode_pi = '\u03c0';
normalPelement[2].textContent += (unicode_pi + unicode_pi.length);
</script> 假设在上面代码中给出的P元素是整个文档中的第三个,首先获得文档中的所有P元素(通过getElementsByTagName()方法),然后我们可以使用类似C数组下标的形式来索引每个P元素;下标一样从0开始,因此第三个P元素的下标为[2],也就是上面那一段英语;通过textContent属性即可获取其文本内容(所有不含HTML元素的文本)。使用字符串连接运算符(+)结合等号(=)实现在原有文本结尾处添加新内容,第一次添加的内容为一个以单引号包含的字符串,其中的第一个字符使用了以转义字符“\u”为前缀的 unicode 字符,后接16位值(即两个16进制数,共2字节)此处是反斜杠(\)的16位内码表示(使用“\\”有相同的效果),浏览器在解析时会自动解码还原成 unicode 明文(下面会给出截图);
另外,在单引号包含的字符串中如果要使用单引号作为缩写或所有格,则需要借助反斜杠来构成转义字符,否则,javascript 解释引擎(浏览器的)会将第二个单引号看成字符串的结尾,从而造成语法错误;
中间还有一个16位内码表示的unicode 字符,其unicode 明文为“π”,在字符串的结尾,使用“明文”转义字符来表示一个反斜杠。
接下来我们将unicode字符π 赋给一个变量,然后继续在第三个P元素的文本后添加
该变量的长度(即 unicode字符的长度,其输出以“16位”为单位,对于字符串也是相同单位,如果要换算成字节数,则需要将 length 属性的输出结果先乘以16,再除以8,就得到字节数),例如字符π就占2字节(输出为1)

6。定时触发事件函数 setTimeout() 的使用注意事项
在 javascript 中可以使用 setTimeout(),指定间隔某段时间后,执行特定函数(触发事件),但是 setTimeout() 计算实际间隔时间的方式可能与我们预期的不同,具体由浏览器的 javascript 解析引擎决定如何“解释”setTimeout() 。先看一个小例子:
var start = new Date;
setTimeout(function(){
var end = new Date;
console.log('Time elapsed:', end - start, 'ms');
}, 500);上面代码首先获取一次当前系统时间,然后通过 setTimeout() 注册一个回调函数,这个函数预定在 500 毫秒(0.5秒)后触发执行:它将第二次获取当前系统时间,然后在调试控制台输出第二次与第一次系统时间的差值。
在 FireFox 插件 FireBug 的控制台中执行上面这段代码,输出的值在 500~510 毫秒之间(多数是500毫秒左右),我们忽略语法,词法,语义解析和执行过程带来的20毫秒(0.02秒)细微延迟,基本上可以认为这个结果是准确的。
接着我们在上面代码的末尾加上一个空循环(循环体为空),然后再次测试两次获取到的时间间隔:
var start = new Date;
setTimeout(function(){
var end = new Date;
console.log('Time elapsed:', end - start, 'ms');
}, 500);
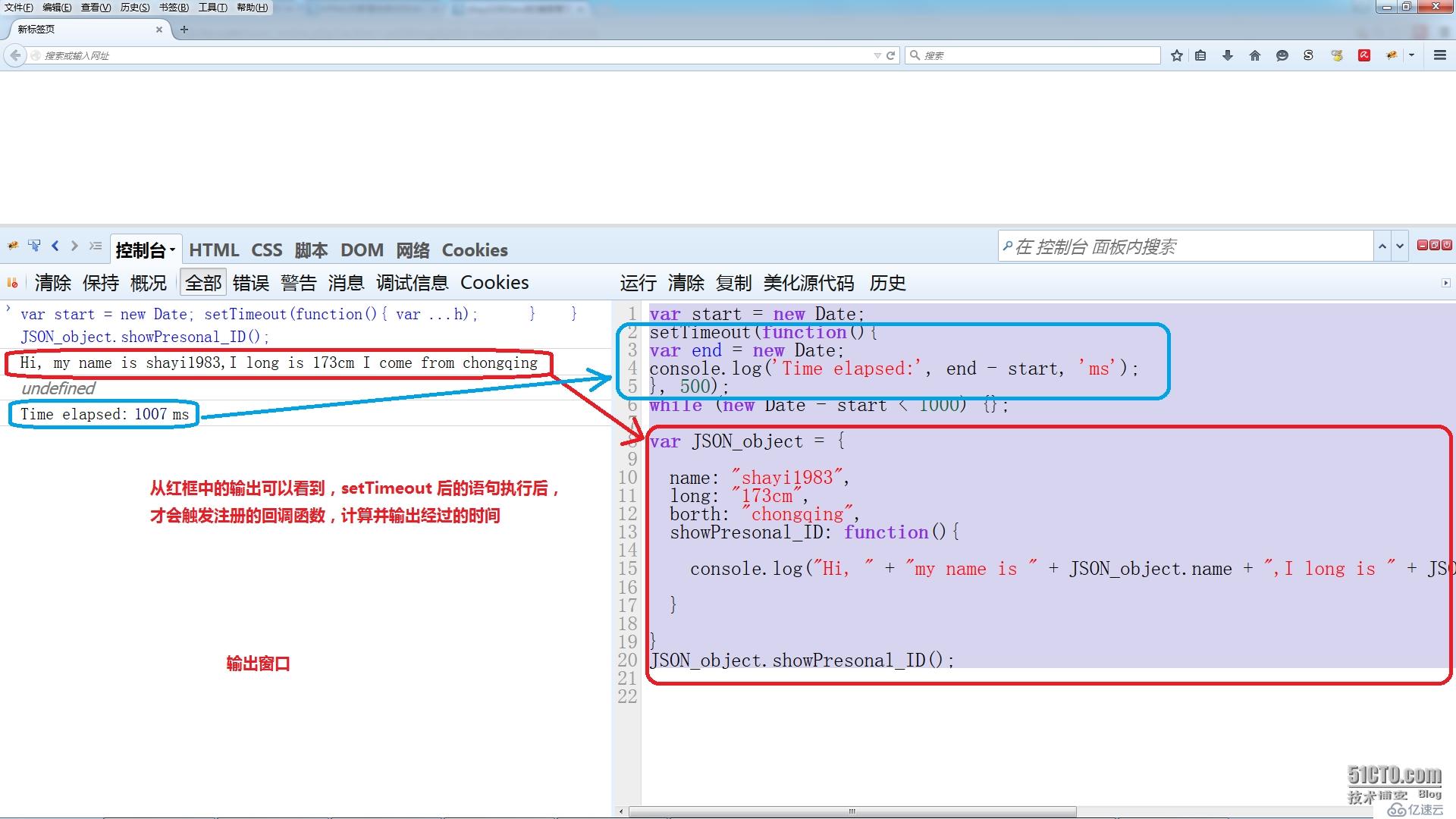
while (new Date - start < 1000) {};在 FireBug 中运行上面代码,这次的输出结果为 100x 毫秒,x 从0~9不等,这表明,当 setTimeout() 后面还有语句时,注册的回调函数会被放置到“待触发的事件队列”中,然后(浏览器)继续解释执行后面的语句,在本例中,它会执行 while 循环的退出条件判断(第三次获取系统当前时间,并将返回值减去第一次获取的系统时间,并判断运算结果是否小于 1000)。待执行完所有语句后,才会触发由 setTimeout() 设置的队列中第一个回调函数。因此我们从输出的 100x 可以得出结论,执行循环并判断大概用了 50x 毫秒(100x - 500 = 50x)。
在通过 setTimeout() 注册一些时间敏感的函数时,最好能够放在代码末尾,否则实际回调的时间可能和你预期的有所延迟。
为了进一步证实 setTimeout() 的延后触发行为,我们将上面代码增量为如下:
var start = new Date;
setTimeout(function(){
var end = new Date;
console.log('Time elapsed:', end - start, 'ms');
}, 500);
while (new Date - start < 1000) {};
var JSON_object = {
name: "shayi1983",
long: "173cm",
borth: "chongqing",
showPresonal_ID: function(){
console.log("Hi, " + "my name is " + JSON_object.name + ",I long is " + JSON_object.long + " I come from " + JSON_object.borth);
}
}
JSON_object.showPresonal_ID();在 while 循环后,创建并初始化了一个名为 JSON_object 的 javascript 对象变量,该对象的前三个属性和值使用 JSON(javascript 对象表示法)格式,并且定义了一个该对象的方法,用于在调试控制台输出前三个属性值;最后调用这个方法来模拟输出自我介绍信息。整段代码在 FireBug 中的运行结果如下:
在 firebug 右侧的窗口输出调试代码时,可以通过 ctrl + z 还原到前几次的代码历史记录,这在无意间清除掉测试代码时非常有用。
《一些元素示例》
关于a元素的 target属性
a元素的target属性取值,用于设置点击该超链接时,打开新页面的位置。如果没有指定target属性,新页面会覆盖当前打开的页面(当前页面的URL变成超链接的URL);当设置 target="_blank" 时,会在一个新的浏览器标签页打开新页面。
下面是一个例子:
<a href="http://twitter.com/virustotal" target="_blank">
<i class="icon-twitter"></i> Twitter</a>如何正确表达“被删除的文本内容”?
在 HTML4.01 里,可以使用元素 strike 实现在文本中间画一条横线,表达被删除的内容;在HTML5 中,该元素因为语义不明被废弃,推荐使用语义元素 del ,或者CSS 样式的 text-decoration:line-through 实现相同的效果,将页面结构与样式分离:
<td id ="deleteTextContent" colspan = "2"><input type = "checkbox" name = "staySigned" />保持登录状态</td>然后在一个外部CSS文件中设置如下:
#deleteTextContent {
text-decoration: line-through;
}最后在上面的复选框控件(checkbox)所在HTML文件中引用这个CSS文件即可。
或者直接使用del元素:
<td colspan = "2"><input type = "checkbox" name = "staySigned" /><del>保持登录状态</del></td>感谢各位的阅读!关于“HTML元素属性测试的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



