Pythonж•°жҚ®еҸҜи§ҶеҢ–е®һдҫӢеә”з”ЁеҲҶжһҗ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonж•°жҚ®еҸҜи§ҶеҢ–е®һдҫӢеә”з”ЁеҲҶжһҗвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дёҖгҖҒж•°жҚ®еҸҜи§ҶеҢ–дёҺжҺўзҙўеӣҫ
ж•°жҚ®еҸҜи§ҶеҢ–жҳҜжҢҮз”ЁеӣҫеҪўжҲ–иЎЁж јзҡ„ж–№ејҸжқҘе‘ҲзҺ°ж•°жҚ®гҖӮеӣҫиЎЁиғҪеӨҹжё…жҘҡең°е‘ҲзҺ°ж•°жҚ®жҖ§иҙЁпјҢ д»ҘеҸҠж•°жҚ®й—ҙжҲ–еұһжҖ§й—ҙзҡ„е…ізі»пјҢеҸҜд»ҘиҪ»жҳ“ең°и®©дәәзңӢеӣҫйҮҠд№үгҖӮз”ЁжҲ·йҖҡиҝҮжҺўзҙўеӣҫпјҲExploratory GraphпјүеҸҜд»ҘдәҶи§Јж•°жҚ®зҡ„зү№жҖ§гҖҒеҜ»жүҫж•°жҚ®зҡ„и¶ӢеҠҝгҖҒйҷҚдҪҺж•°жҚ®зҡ„зҗҶи§Јй—Ёж§ӣгҖӮ
дәҢгҖҒеёёи§Ғзҡ„еӣҫиЎЁе®һдҫӢ
жң¬з« дё»иҰҒйҮҮз”Ё Pandas зҡ„ж–№ејҸжқҘз”»еӣҫпјҢиҖҢдёҚжҳҜдҪҝз”Ё Matplotlib жЁЎеқ—гҖӮе…¶е®һ Pandas е·Із»ҸжҠҠ Matplotlib зҡ„з”»еӣҫж–№жі•ж•ҙеҗҲеҲ° DataFrame дёӯпјҢеӣ жӯӨеңЁе®һйҷ…еә”з”ЁдёӯпјҢз”ЁжҲ·дёҚйңҖиҰҒзӣҙжҺҘеј•з”Ё Matplotlib д№ҹеҸҜд»Ҙе®ҢжҲҗз”»еӣҫзҡ„е·ҘдҪңгҖӮ
1.жҠҳзәҝеӣҫ
жҠҳзәҝеӣҫпјҲline chartпјүжҳҜжңҖеҹәжң¬зҡ„еӣҫиЎЁпјҢеҸҜд»Ҙз”ЁжқҘе‘ҲзҺ°дёҚеҗҢж ҸдҪҚиҝһз»ӯж•°жҚ®д№Ӣй—ҙзҡ„е…ізі»гҖӮз»ҳеҲ¶жҠҳзәҝеӣҫдҪҝз”Ёзҡ„жҳҜ plot.line() зҡ„ж–№жі•пјҢеҸҜд»Ҙи®ҫзҪ®йўңиүІгҖҒеҪўзҠ¶зӯүеҸӮж•°гҖӮеңЁдҪҝз”ЁдёҠпјҢжӢҶзәҝеӣҫз»ҳеҲ¶ж–№жі•е®Ң全继жүҝдәҶ Matplotlib зҡ„з”Ёжі•пјҢжүҖд»ҘзЁӢеәҸжңҖеҗҺд№ҹеҝ…йЎ»и°ғз”Ё plt.show() дә§з”ҹеӣҫпјҢеҰӮеӣҫ8.4 жүҖзӨәгҖӮ
df_iris[['sepal length (cm)']].plot.line()
plt.show()
ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--')
ax.set(xlabel="index", ylabel="length")
plt.show()
2.ж•Јеёғеӣҫ
ж•ЈеёғеӣҫпјҲScatter Chartпјүз”ЁдәҺжЈҖи§ҶдёҚеҗҢж ҸдҪҚзҰ»ж•Јж•°жҚ®д№Ӣй—ҙзҡ„е…ізі»гҖӮз»ҳеҲ¶ж•ЈеёғеӣҫдҪҝз”Ёзҡ„жҳҜ df.plot.scatter()пјҢеҰӮеӣҫ8.5жүҖзӨәгҖӮ
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
3.зӣҙж–№еӣҫгҖҒй•ҝжқЎеӣҫ
зӣҙж–№еӣҫпјҲHistogram ChartпјүйҖҡеёёз”ЁдәҺеҗҢдёҖж ҸдҪҚпјҢе‘ҲзҺ°иҝһз»ӯж•°жҚ®зҡ„еҲҶеёғзҠ¶еҶөпјҢдёҺзӣҙж–№еӣҫзұ»дјјзҡ„еҸҰдёҖз§ҚеӣҫжҳҜй•ҝжқЎеӣҫпјҲBar ChartпјүпјҢз”ЁдәҺжЈҖи§ҶеҗҢдёҖж ҸдҪҚпјҢеҰӮеӣҫ 8.6 жүҖзӨәгҖӮ
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist()
2 df.target.value_counts().plot.bar()
4. еңҶйҘјеӣҫгҖҒз®ұеҪўеӣҫ
еңҶйҘјеӣҫпјҲPie ChartпјүеҸҜд»Ҙз”ЁдәҺжЈҖи§ҶеҗҢдёҖж ҸдҪҚеҗ„зұ»еҲ«жүҖеҚ зҡ„жҜ”дҫӢпјҢиҖҢз®ұеҪўеӣҫпјҲBox ChartпјүеҲҷз”ЁдәҺжЈҖи§ҶеҗҢдёҖж ҸдҪҚжҲ–жҜ”иҫғдёҚеҗҢж ҸдҪҚж•°жҚ®зҡ„еҲҶеёғе·®ејӮпјҢеҰӮеӣҫ 8.7 жүҖзӨәгҖӮ
df.target.value_counts().plot.pie(legend=True)
df.boxplot(column=['target'],п¬Ғgsize=(10,5))
ж•°жҚ®жҺўзҙўе®һжҲҳеҲҶдә«
жң¬иҠӮеҲ©з”ЁдёӨдёӘзңҹе®һзҡ„ж•°жҚ®йӣҶе®һйҷ…еұ•зӨәж•°жҚ®жҺўзҙўзҡ„еҮ з§ҚжүӢжі•гҖӮ
дёҖгҖҒ2013е№ҙзҫҺеӣҪзӨҫеҢәи°ғжҹҘ
еңЁзҫҺеӣҪзӨҫеҢәи°ғжҹҘпјҲAmerican Community SurveyпјүдёӯпјҢжҜҸе№ҙзәҰжңү 350 дёҮдёӘ家еәӯиў«й—®еҲ°е…ідәҺ他们жҳҜи°ҒеҸҠ他们еҰӮдҪ•з”ҹжҙ»зҡ„иҜҰз»Ҷй—®йўҳгҖӮи°ғжҹҘзҡ„еҶ…е®№ж¶өзӣ–дәҶи®ёеӨҡдё»йўҳпјҢеҢ…жӢ¬зҘ–е…ҲгҖҒж•ҷиӮІгҖҒе·ҘдҪңгҖҒдәӨйҖҡгҖҒдә’иҒ”зҪ‘дҪҝз”Ёе’Ңеұ…дҪҸгҖӮ
е…Ҳи§ӮеҜҹж•°жҚ®зҡ„ж ·еӯҗдёҺзү№жҖ§пјҢд»ҘеҸҠжҜҸдёӘж ҸдҪҚд»ЈиЎЁзҡ„ж„Ҹд№үгҖҒз§Қзұ»е’ҢиҢғеӣҙгҖӮ
# иҜ»еҸ–ж•°жҚ®
df = pd.read_csv("./ss13husa.csv")
# ж ҸдҪҚз§Қзұ»ж•°йҮҸ
df.shape
# (756065,231)
# ж ҸдҪҚж•°еҖјиҢғеӣҙ
df.describe()е…Ҳе°ҶдёӨдёӘ ss13pusa.csv дёІиҝһиө·жқҘпјҢиҝҷд»Ҫж•°жҚ®жҖ»е…ұеҢ…еҗ« 30 дёҮ笔数жҚ®пјҢ3 дёӘж ҸдҪҚпјҡSCHL ( еӯҰеҺҶпјҢSchool Level)гҖҒ PINCP ( 收е…ҘпјҢIncome) е’Ң ESR ( е·ҘдҪңзҠ¶жҖҒпјҢWork Status)гҖӮ
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# дёІжҺҘдёӨд»Ҫж•°жҚ®
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)дҫқжҚ®еӯҰеҺҶеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзҫӨпјҢи§ӮеҜҹдёҚеҗҢеӯҰеҺҶзҡ„ж•°йҮҸжҜ”дҫӢпјҢжҺҘзқҖ计算他们зҡ„е№іеқҮ收е…ҘгҖӮ
group = df['ac_survey'].groupby(by=['SCHL']) print('еӯҰеҺҶеҲҶеёғ:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('е№іеқҮ收е…Ҙ:' +group.mean())дәҢгҖҒжіўеЈ«йЎҝжҲҝеұӢж•°жҚ®йӣҶ
жіўеЈ«йЎҝжҲҝеұӢж•°жҚ®йӣҶпјҲBoston House Price DatasetпјүеҢ…еҗ«жңүе…іжіўеЈ«йЎҝең°еҢәзҡ„жҲҝеұӢдҝЎжҒҜпјҢ еҢ… 506 дёӘж•°жҚ®ж ·жң¬е’Ң 13 дёӘзү№еҫҒз»ҙеәҰгҖӮ
ж•°жҚ®жқҘжәҗпјҡhttps://archive.ics.uci.edu/ml/machine-learning-databases/housing/гҖӮ
ж•°жҚ®еҗҚз§°пјҡBoston House Price DatasetгҖӮ
е…Ҳи§ӮеҜҹж•°жҚ®зҡ„ж ·еӯҗдёҺзү№жҖ§пјҢд»ҘеҸҠжҜҸдёӘж ҸдҪҚд»ЈиЎЁзҡ„ж„Ҹд№үгҖҒз§Қзұ»е’ҢиҢғеӣҙгҖӮ
еҸҜд»Ҙз”Ёзӣҙж–№еӣҫзҡ„ж–№ејҸз”»еҮәжҲҝд»·пјҲMEDVпјүзҡ„еҲҶеёғпјҢеҰӮеӣҫ 8.8 жүҖзӨәгҖӮ
df = pd.read_csv("./housing.data")
# ж ҸдҪҚз§Қзұ»ж•°йҮҸ
df.shape
# (506, 14)
#ж ҸдҪҚж•°еҖјиҢғеӣҙdf.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()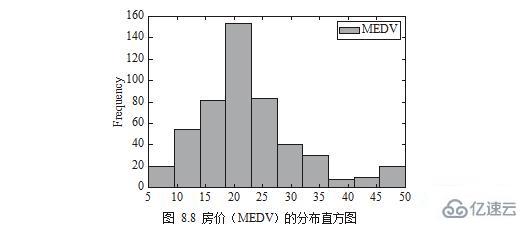
жіЁпјҡеӣҫдёӯиӢұж–ҮеҜ№еә”笔иҖ…еңЁд»Јз ҒдёӯжҲ–ж•°жҚ®дёӯжҢҮе®ҡзҡ„еҗҚеӯ—пјҢе®һи·өдёӯиҜ»иҖ…еҸҜе°Ҷе®ғ们жӣҝжҚўжҲҗиҮӘе·ұйңҖиҰҒзҡ„ж–Үеӯ—гҖӮ
жҺҘдёӢжқҘйңҖиҰҒзҹҘйҒ“зҡ„жҳҜе“Әдәӣз»ҙеәҰдёҺвҖңжҲҝд»·вҖқе…ізі»жҳҺжҳҫгҖӮе…Ҳз”Ёж•Јеёғеӣҫзҡ„ж–№ејҸжқҘи§ӮеҜҹпјҢеҰӮеӣҫ8.9жүҖзӨәгҖӮ
# draw scatter chart
df.plot.scatter(x='MEDV', y='RM') .
plt.show()
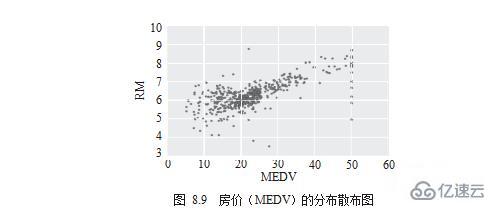
жңҖеҗҺпјҢи®Ўз®—зӣёе…ізі»ж•°е№¶з”ЁиҒҡзұ»зғӯеӣҫпјҲHeatmapпјүжқҘиҝӣиЎҢи§Ҷи§үе‘ҲзҺ°пјҢеҰӮеӣҫ 8.10 жүҖзӨәгҖӮ
# compute pearson correlation
corr = df.corr()
# drawheatmap
import seaborn as sns
corr = df.corr()
sns.heatmap(corr)
plt.show()
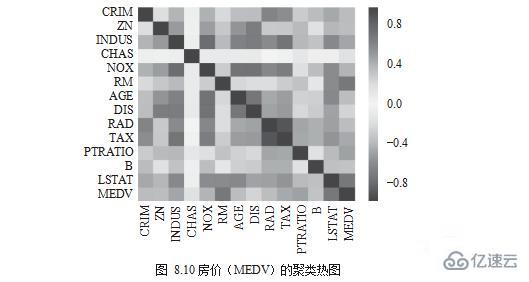
йўңиүІдёәзәўиүІпјҢиЎЁзӨәжӯЈеҗ‘е…ізі»пјӣйўңиүІдёәи“қиүІпјҢиЎЁзӨәиҙҹеҗ‘е…ізі»пјӣйўңиүІдёәзҷҪиүІпјҢиЎЁзӨәжІЎжңүе…ізі»гҖӮRM дёҺжҲҝд»·е…іиҒ”еәҰеҒҸеҗ‘зәўиүІпјҢдёәжӯЈеҗ‘е…ізі»пјӣLSTATгҖҒPTRATIO дёҺжҲҝд»·е…іиҒ”еәҰеҒҸеҗ‘ж·ұи“қпјҢ дёәиҙҹеҗ‘е…ізі»пјӣCRIMгҖҒRADгҖҒAGE дёҺжҲҝд»·е…іиҒ”еәҰеҒҸеҗ‘зҷҪиүІпјҢдёәжІЎжңүе…ізі»гҖӮ
вҖңPythonж•°жҚ®еҸҜи§ҶеҢ–е®һдҫӢеә”з”ЁеҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





