java并жҹҘйӣҶжҖҺд№Ҳе®һзҺ°
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңjava并жҹҘйӣҶжҖҺд№Ҳе®һзҺ°вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁjava并жҹҘйӣҶжҖҺд№Ҳе®һзҺ°й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқjava并жҹҘйӣҶжҖҺд№Ҳе®һзҺ°вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒжҰӮиҝ°
并жҹҘйӣҶпјҡдёҖз§Қж ‘еһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺи§ЈеҶідёҖдәӣдёҚзӣёдәӨйӣҶеҗҲзҡ„еҗҲ并еҸҠжҹҘиҜўй—®йўҳгҖӮдҫӢеҰӮпјҡжңүnдёӘжқ‘еә„пјҢжҹҘиҜў2дёӘжқ‘еә„д№Ӣй—ҙжҳҜеҗҰжңүиҝһжҺҘзҡ„и·ҜпјҢиҝһжҺҘ2дёӘжқ‘еә„
дёӨеӨ§ж ёеҝғпјҡ
жҹҘжүҫ (Find) : жҹҘжүҫе…ғзҙ жүҖеңЁзҡ„йӣҶеҗҲ
еҗҲ并 (Union) : е°ҶдёӨдёӘе…ғзҙ жүҖеңЁйӣҶеҗҲеҗҲ并дёәдёҖдёӘйӣҶеҗҲ
дәҢгҖҒе®һзҺ°
并жҹҘйӣҶжңүдёӨз§Қеёёи§Ғзҡ„е®һзҺ°жҖқи·Ҝ
еҝ«жҹҘпјҲQuick Findпјү
еҝ«е№¶пјҲQuick Unionпјү
дҪҝз”Ёж•°з»„е®һзҺ°ж ‘еһӢз»“жһ„пјҢж•°з»„дёӢж Үдёәе…ғзҙ пјҢж•°з»„еӯҳеӮЁзҡ„еҖјдёәзҲ¶иҠӮзӮ№зҡ„еҖј
еҲӣе»әжҠҪиұЎзұ»Union Find
public abstract class UnionFind {
int[] parents;
/**
* еҲқе§ӢеҢ–并жҹҘйӣҶ
* @param capacity
*/
public UnionFind(int capacity){
if(capacity < 0) {
throw new IllegalArgumentException("capacity must be >=0");
}
//еҲқе§Ӣж—¶жҜҸдёҖдёӘе…ғзҙ зҲ¶иҠӮзӮ№пјҲж №з»“зӮ№пјүжҳҜиҮӘе·ұ
parents = new int[capacity];
for(int i = 0; i < parents.length;i++) {
parents[i] = i;
}
}
/**
* жЈҖжҹҘv1 v2 жҳҜеҗҰеұһдәҺеҗҢдёҖдёӘйӣҶеҗҲ
*/
public boolean isSame(int v1,int v2) {
return find(v1) == find(v2);
}
/**
* жҹҘжүҫvжүҖеұһзҡ„йӣҶеҗҲ пјҲж №иҠӮзӮ№пјү
*/
public abstract int find(int v);
/**
* еҗҲ并v1 v2 жүҖеұһзҡ„йӣҶеҗҲ
*/
public abstract void union(int v1, int v2);
// иҢғеӣҙжЈҖжҹҘ
public void rangeCheck(int v) {
if(v<0 || v > parents.length)
throw new IllegalArgumentException("v is out of capacity");
}
}2.1 Quick Findе®һзҺ°
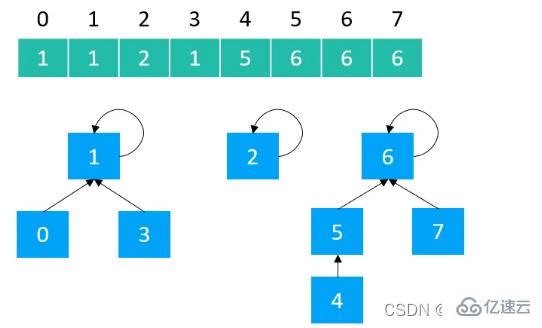
д»ҘQuick Findе®һзҺ°зҡ„并жҹҘйӣҶпјҢж ‘зҡ„й«ҳеәҰжңҖй«ҳдёә2пјҢжҜҸдёӘиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№е°ұжҳҜж №иҠӮзӮ№
public class UnionFind_QF extends UnionFind {
public UnionFind_QF(int capacity) {
super(capacity);
}
// жҹҘ
@Override
public int find(int v) {
rangeCheck(v);
return parents[v];
}
// 并 е°Ҷv1жүҖеңЁйӣҶеҗҲ并еҲ°v2жүҖеңЁйӣҶеҗҲдёҠ
@Override
public void union(int v1, int v2) {
// жҹҘжүҫv1 v2 зҡ„зҲ¶пјҲж №пјүиҠӮзӮ№
int p1= find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//е°ҶжүҖжңүд»Ҙv1зҡ„ж №иҠӮзӮ№дёәж №иҠӮзӮ№зҡ„е…ғзҙ е…ЁйғЁе№¶еҲ°v2жүҖеңЁйӣҶеҗҲдёҠ еҚізҲ¶иҠӮзӮ№ж”№дёәv2зҡ„зҲ¶иҠӮзӮ№
for(int i = 0; i< parents.length; i++) {
if(parents[i] == p1) {
parents[i] = p2;
}
}
}
}2.2 Quick Unionе®һзҺ°
public class UnionFind_QU extends UnionFind {
public UnionFind_QU(int capacity) {
super(capacity);
}
//жҹҘжҹҗдёҖдёӘе…ғзҙ зҡ„ж №иҠӮзӮ№
@Override
public int find(int v) {
//жЈҖжҹҘдёӢж ҮжҳҜеҗҰи¶Ҡз•Ң
rangeCheck(v);
// дёҖзӣҙеҫӘзҺҜжҹҘжүҫиҠӮзӮ№зҡ„ж №иҠӮзӮ№
while (v != parents[v]) {
v = parents[v];
}
return v;
}
//V1 并еҲ° v2 дёӯ
@Override
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//е°Ҷv1 ж №иҠӮзӮ№ зҡ„ зҲ¶иҠӮзӮ№ дҝ®ж”№дёә v2зҡ„ж №з»“зӮ№ е®ҢжҲҗеҗҲ并
parents[p1] = p2;
}
}дёүгҖҒдјҳеҢ–
并жҹҘйӣҶеёёз”Ёеҝ«е№¶жқҘе®һзҺ°пјҢдҪҶжҳҜеҝ«е№¶жңүж—¶дјҡеҮәзҺ°ж ‘дёҚе№іиЎЎзҡ„жғ…еҶө
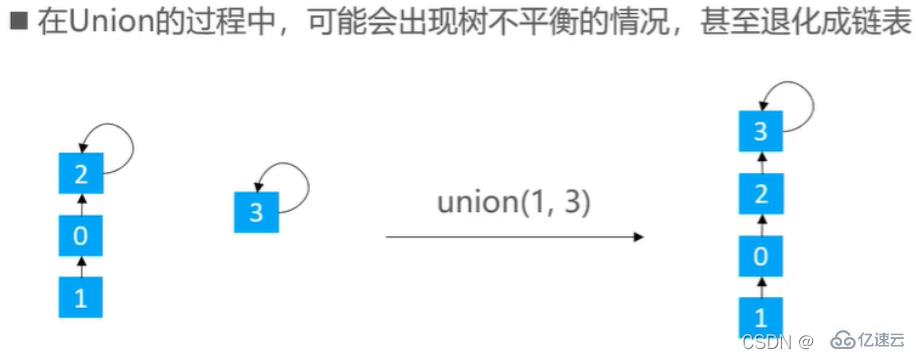
жңүдёӨз§ҚдјҳеҢ–жҖқи·ҜпјҡrankдјҳеҢ–пјҢsizeдјҳеҢ–
3.1еҹәдәҺsizeзҡ„дјҳеҢ–
ж ёеҝғжҖқжғіпјҡе…ғзҙ е°‘зҡ„ж ‘ е«ҒжҺҘеҲ° е…ғзҙ еӨҡзҡ„ж ‘
public class UniondFind_QU_S extends UnionFind{
// еҲӣе»әsizes ж•°з»„и®°еҪ• д»Ҙе…ғзҙ пјҲдёӢж Үпјүдёәж №з»“зӮ№зҡ„е…ғзҙ пјҲиҠӮзӮ№пјүдёӘж•°
private int[] sizes;
public UniondFind_QU_S(int capacity) {
super(capacity);
sizes = new int[capacity];
//еҲқе§ӢйғҪдёә 1
for(int i = 0;i < sizes.length;i++) {
sizes[i] = 1;
}
}
@Override
public int find(int v) {
rangeCheck(v);
while (v != parents[v]) {
v = parents[v];
}
return v;
}
@Override
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
//еҰӮжһңд»Ҙp1дёәж №з»“зӮ№зҡ„е…ғзҙ дёӘж•° е°ҸдәҺ д»Ҙp2дёәж №з»“зӮ№зҡ„е…ғзҙ дёӘж•° p1并еҲ°p2дёҠпјҢ并且жӣҙж–°p2дёәж №з»“зӮ№зҡ„е…ғзҙ дёӘж•°
if(sizes[p1] < sizes[p2]) {
parents[p1] = p2;
sizes[p2] += sizes[p1];
// еҸҚд№Ӣ еҲҷp2 并еҲ° p1 дёҠпјҢжӣҙж–°p1дёәж №з»“зӮ№зҡ„е…ғзҙ дёӘж•°
}else {
parents[p2] = p1;
sizes[p1] += sizes[p2];
}
}
}еҹәдәҺsizeдјҳеҢ–иҝҳжңүеҸҜиғҪдјҡеҜјиҮҙж ‘дёҚе№іиЎЎ
3.2еҹәдәҺrankдјҳеҢ–
ж ёеҝғжҖқжғіпјҡзҹ®зҡ„ж ‘ е«ҒжҺҘеҲ° й«ҳзҡ„ж ‘
public class UnionFind_QU_R extends UnionFind_QU {
// еҲӣе»әrankж•°з»„ ranks[i] д»ЈиЎЁд»Ҙiдёәж №иҠӮзӮ№зҡ„ж ‘зҡ„й«ҳеәҰ
private int[] ranks;
public UnionFind_QU_R(int capacity) {
super(capacity);
ranks = new int[capacity];
for(int i = 0;i < ranks.length;i++) {
ranks[i] = 1;
}
}
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if(p1 == p2) return;
// p1 并еҲ° p2 дёҠ p2дёәж № ж ‘зҡ„й«ҳеәҰдёҚеҸҳ
if(ranks[p1] < ranks[p2]) {
parents[p1] = p2;
// p2 并еҲ° p1 дёҠ p1дёәж № ж ‘зҡ„й«ҳеәҰдёҚеҸҳ
} else if(ranks[p1] > ranks[p2]) {
parents[p2] = p1;
}else {
// й«ҳеәҰзӣёеҗҢ p1 并еҲ° p2дёҠпјҢp2дёәж № ж ‘зҡ„й«ҳеәҰ+1
parents[p1] = p2;
ranks[p2] += 1;
}
}
}еҹәдәҺrankдјҳеҢ–пјҢйҡҸзқҖUnionж¬Ўж•°зҡ„еўһеӨҡпјҢж ‘зҡ„й«ҳеәҰдҫқ然дјҡи¶ҠжқҘи¶Ҡй«ҳ еҜјиҮҙfindж“ҚдҪңеҸҳж…ў
жңүдёүз§ҚжҖқи·ҜеҸҜд»Ҙ继з»ӯдјҳеҢ– пјҡи·Ҝеҫ„еҺӢзј©гҖҒи·Ҝеҫ„еҲҶиЈӮгҖҒи·Ҝеҫ„еҮҸеҚҠ
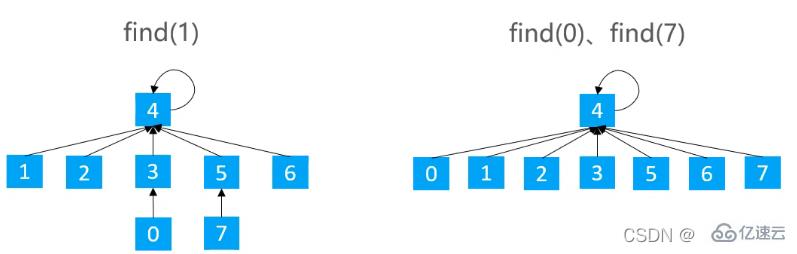
3.2.1и·Ҝеҫ„еҺӢзј©пјҲPath Compression пјү
еңЁfindж—¶дҪҝи·Ҝеҫ„дёҠзҡ„жүҖжңүиҠӮзӮ№йғҪжҢҮеҗ‘ж №иҠӮзӮ№пјҢд»ҺиҖҢйҷҚдҪҺж ‘зҡ„й«ҳеәҰ
/**
* Quick Union -еҹәдәҺrankзҡ„дјҳеҢ– -и·Ҝеҫ„еҺӢзј©
*
*/
public class UnionFind_QU_R_PC extends UnionFind_QU_R {
public UnionFind_QU_R_PC(int capacity) {
super(capacity);
}
@Override
public int find(int v) {
rangeCheck(v);
if(parents[v] != v) {
//йҖ’еҪ’ дҪҝеҫ—д»ҺеҪ“еүҚv еҲ°ж №иҠӮзӮ№ д№Ӣй—ҙзҡ„ жүҖжңүиҠӮзӮ№зҡ„ зҲ¶иҠӮзӮ№йғҪж”№дёәж №иҠӮзӮ№
parents[v] = find(parents[v]);
}
return parents[v];
}
}иҷҪ然иғҪйҷҚдҪҺж ‘зҡ„й«ҳеәҰпјҢдҪҶжҳҜе®һзҺ°жҲҗжң¬зЁҚй«ҳ
3.2.2и·Ҝеҫ„еҲҶиЈӮпјҲPath Splitingпјү
дҪҝи·Ҝеҫ„дёҠзҡ„жҜҸдёӘиҠӮзӮ№йғҪжҢҮеҗ‘е…¶зҘ–зҲ¶иҠӮзӮ№

/**
* Quick Union -еҹәдәҺrankзҡ„дјҳеҢ– -и·Ҝеҫ„еҲҶиЈӮ
*
*/
public class UnionFind_QU_R_PS extends UnionFind_QU_R {
public UnionFind_QU_R_PS(int capacity) {
super(capacity);
}
@Override
public int find(int v) {
rangeCheck(v);
while(v != parents[v]) {
int p = parents[v];
parents[v] = parents[parents[v]];
v = p;
}
return v;
}
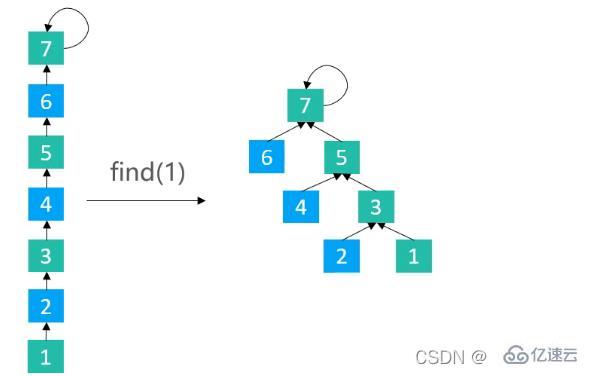
}3.2.3и·Ҝеҫ„еҮҸеҚҠпјҲPath Halvingпјү
дҪҝи·Ҝеҫ„дёҠжҜҸйҡ”дёҖдёӘиҠӮзӮ№е°ұжҢҮеҗ‘е…¶зҘ–зҲ¶иҠӮзӮ№
/**
* Quick Union -еҹәдәҺrankзҡ„дјҳеҢ– -и·Ҝеҫ„еҮҸеҚҠ
*
*/
public class UnionFind_QU_R_PH extends UnionFind_QU_R {
public UnionFind_QU_R_PH(int capacity) {
super(capacity);
}
public int find(int v) {
rangeCheck(v);
while(v != parents[v]) {
parents[v] = parents[parents[v]];
v = parents[v];
}
return v;
}
}дҪҝз”ЁQuick Union + еҹәдәҺrankзҡ„дјҳеҢ– + и·Ҝеҫ„еҲҶиЈӮ жҲ– и·Ҝеҫ„еҮҸеҚҠ
еҸҜд»ҘдҝқиҜҒжҜҸдёӘж“ҚдҪңзҡ„еқҮж‘Ҡж—¶й—ҙеӨҚжқӮеәҰдёәO(a(n)) , a(n) < 5
еҲ°жӯӨпјҢе…ідәҺвҖңjava并жҹҘйӣҶжҖҺд№Ҳе®һзҺ°вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





