д»Һеә“ж•°жҚ®жҹҘжүҫе’ҢеҸӮж•°slave_rows_search_alg
гҖҖгҖҖжң¬иҠӮжҲ‘们еҒҮе®ҡеҸӮж•°binlog_row_imageи®ҫзҪ®дёәвҖҳFULLвҖҷд№ҹе°ұжҳҜй»ҳи®ӨеҖјгҖӮ
гҖҖгҖҖдёҖгҖҒд»ҺдёҖдёӘеҲ—еӯҗеҮәеҸ‘
гҖҖгҖҖеңЁејҖе§Ӣд№ӢеүҚжҲ‘们е…ҲеҒҮе®ҡеҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷдёәй»ҳи®ӨеҖјпјҢеҚіпјҡ
гҖҖгҖҖTABLE_SCAN,INDEX_SCAN
гҖҖгҖҖеӣ дёәиҝҷдёӘеҸӮж•°дјҡзӣҙжҺҘеҪұе“ҚеҲ°еҜ№зҙўеј•зҡ„еҲ©з”Ёж–№ејҸгҖӮ
гҖҖгҖҖжҲ‘们иҝҳжҳҜд»ҘвҖҳDeleteвҖҷж“ҚдҪңдёәдҫӢпјҢе®һйҷ…дёҠеҜ№дәҺзҙўеј•зҡ„йҖүжӢ©вҖҳUpdateвҖҷж“ҚдҪңд№ҹжҳҜдёҖж ·зҡ„пјҢеӣ дёәйғҪжҳҜйҖҡиҝҮbefore_imageеҺ»жҹҘжүҫж•°жҚ®гҖӮжҲ‘жөӢиҜ•зҡ„иЎЁз»“жһ„гҖҒж•°жҚ®е’Ңж“ҚдҪңеҰӮдёӢпјҡ
гҖҖгҖҖmysql> show create table tkkk \G
гҖҖгҖҖ*************************** 1. row ***************************
гҖҖгҖҖTable: tkkk
гҖҖгҖҖCreate Table: CREATE TABLE `tkkk` (
гҖҖгҖҖ`a` int(11) DEFAULT NULL,
гҖҖгҖҖ`b` int(11) DEFAULT NULL,
гҖҖгҖҖ`c` int(11) DEFAULT NULL,
гҖҖгҖҖKEY `a` (`a`)
гҖҖгҖҖ) ENGINE=InnoDB DEFAULT CHARSET=utf8
гҖҖгҖҖ1 row in set (0.00 sec)
гҖҖгҖҖmysql> select * from tkkk;
гҖҖгҖҖ+------+------+------+
гҖҖгҖҖ| a | b | c |
гҖҖгҖҖ+------+------+------+
гҖҖгҖҖ| 1 | 1 | 1 |
гҖҖгҖҖ| 2 | 2 | 2 |
гҖҖгҖҖ| 3 | 3 | 3 |
гҖҖгҖҖ| 4 | 4 | 4 |
гҖҖгҖҖ| 5 | 5 | 5 |
гҖҖгҖҖ| 6 | 6 | 6 |
гҖҖгҖҖ| 7 | 7 | 7 |
гҖҖгҖҖ| 8 | 8 | 8 |
гҖҖгҖҖ| 9 | 9 | 9 |
гҖҖгҖҖ| 10 | 10 | 10 |
гҖҖгҖҖ| 11 | 11 | 11 |
гҖҖгҖҖ| 12 | 12 | 12 |
гҖҖгҖҖ| 13 | 13 | 13 |
гҖҖгҖҖ| 15 | 15 | 15 |
гҖҖгҖҖ| 15 | 16 | 16 |
гҖҖгҖҖ| 15 | 17 | 17 |
гҖҖгҖҖ+------+------+------+
гҖҖгҖҖ16 rows in set (2.21 sec)
гҖҖгҖҖmysql> delete from tkkk where a=15;
гҖҖгҖҖQuery OK, 3 rows affected (6.24 sec)
гҖҖгҖҖеӣ дёәжҲ‘еҒҡдәҶdebugзҙўеј•иҝҷйҮҢж—¶й—ҙзңӢиө·жқҘеҫҲй•ҝ
гҖҖгҖҖеҜ№дәҺиҝҷж ·дёҖдёӘвҖҳDeleteвҖҷиҜӯеҸҘжқҘи®Ідё»еә“дјҡеҲ©з”ЁеҲ°зҙўеј• KEY aпјҢеҲ йҷӨзҡ„дёүжқЎж•°жҚ®жҲ‘们е®һйҷ…дёҠеҸӘйңҖиҰҒдёҖж¬Ўзҙўеј•зҡ„е®ҡдҪҚ(еҸӮиҖғbtr_cur_search_to_nth_levelеҮҪж•°)пјҢ然еҗҺйЎәеәҸжү«жҸҸжҺҘдёӢжқҘзҡ„ж•°жҚ®иҝӣиЎҢеҲ йҷӨе°ұеҸҜд»ҘдәҶгҖӮеӨ§жҰӮзҡ„жөҒзЁӢеҰӮдёӢеӣҫпјҡ
гҖҖгҖҖ
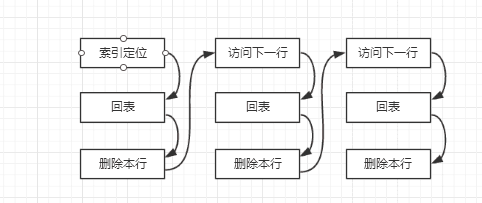
гҖҖгҖҖиҝҷжқЎж•°жҚ®еҲ йҷӨзҡ„дёүжқЎж•°жҚ®зҡ„before_imageе°Ҷдјҡи®°еҪ•еҲ°дёҖдёӘDELETE_ROWS_EVENTдёӯгҖӮд»Һеә“еә”з”Ёзҡ„ж—¶еҖҷдјҡйҮҚж–°иҜ„дј°еә”иҜҘдҪҝз”Ёе“ӘдёӘзҙўеј•пјҢдјҳе…ҲдҪҝз”Ёдё»й”®е’Ңе”ҜдёҖй”®гҖӮеҜ№дәҺEventдёӯзҡ„жҜҸжқЎж•°жҚ®йғҪйңҖиҰҒиҝӣиЎҢзҙўеј•е®ҡдҪҚж“ҚдҪңпјҢ并且еҜ№дәҺйқһе”ҜдёҖзҙўеј•жқҘ讲第дёҖж¬Ўиҝ”еӣһзҡ„第дёҖиЎҢж•°жҚ®еҸҜиғҪ并дёҚжҳҜеҲ йҷӨзҡ„ж•°жҚ®пјҢиҝҳйңҖиҰҒйңҖиҰҒ继з»ӯжү«жҸҸдёӢдёҖиЎҢпјҢеңЁеҮҪж•°Rows_log_event::do_index_scan_and_updateдёӯжңүеҰӮдёӢд»Јз Ғпјҡ
гҖҖгҖҖwhile (record_compare(m_table, &m_cols))//жҜ”иҫғжҜҸдёҖдёӘеӯ—ж®ө еҰӮжһңдёҚзӣёзӯү жү«жҸҸдёӢдёҖиЎҢ
гҖҖгҖҖ{
гҖҖгҖҖwhile((error= next_record_scan(false)))//жү«жҸҸдёӢдёҖиЎҢ
гҖҖгҖҖ{
гҖҖгҖҖ/* We just skip records that has already been deleted */
гҖҖгҖҖif (error == HA_ERR_RECORD_DELETED)
гҖҖгҖҖcontinue;
гҖҖгҖҖDBUG_PRINT("info",("no record matching the given row found"));
гҖҖгҖҖgoto end;
гҖҖгҖҖ}
гҖҖгҖҖ}
гҖҖгҖҖиҝҷдәӣд»Јд»·жҳҜжҜ”дё»еә“жӣҙеӨ§зҡ„гҖӮеңЁиҝҷдёӘеҲ—еӯҗдёӯжІЎжңүдё»й”®е’Ңе”ҜдёҖй”®пјҢеӣ жӯӨдҫқж—§дҪҝз”Ёзҡ„жҳҜзҙўеј•KEY aпјҢеӨ§жҰӮжөҒзЁӢеҰӮдёӢеӣҫпјҡ
гҖҖгҖҖ
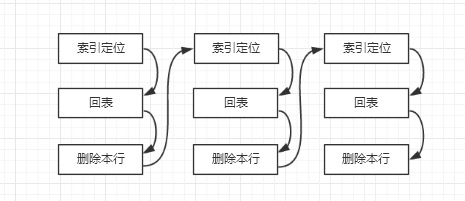
гҖҖгҖҖдҪҶжҳҜеҰӮжһңжҲ‘们еңЁд»Һеә“еўһеҠ дёҖдёӘдё»й”®пјҢйӮЈд№ҲеңЁд»Һеә“иҝӣиЎҢеә”з”Ёзҡ„ж—¶еҖҷжөҒзЁӢеҰӮдёӢпјҡ
гҖҖгҖҖ
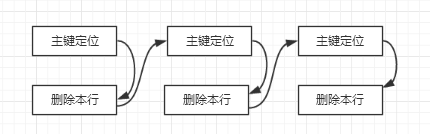
гҖҖгҖҖжҲ‘们д»ҺдёҠйқўзҡ„жөҒзЁӢжқҘзңӢпјҢдё»еә“вҖҳDeleteвҖҷж“ҚдҪңе’Ңд»Һеә“вҖҳDeleteвҖҷж“ҚдҪңдё»иҰҒзҡ„еҢәеҲ«еңЁдәҺпјҡ
гҖҖгҖҖд»Һеә“жҜҸжқЎж•°жҚ®йғҪйңҖиҰҒзҙўеј•е®ҡдҪҚжҹҘжүҫж•°жҚ®гҖӮ
гҖҖгҖҖд»Һеә“еңЁжҹҗдәӣжғ…еҶөдёӢйҖҡиҝҮйқһе”ҜдёҖзҙўеј•жҹҘжүҫзҡ„ж•°жҚ®з¬¬дёҖжқЎж•°жҚ®еҸҜиғҪ并дёҚжҳҜеҲ йҷӨзҡ„ж•°жҚ®пјҢеӣ жӯӨиҝҳйңҖиҰҒ继з»ӯиҝӣиЎҢзҙўеј•е®ҡдҪҚе’ҢжҹҘжүҫгҖӮ
гҖҖгҖҖеҜ№дәҺдё»еә“жқҘи®ІдёҖиҲ¬еҸӘйңҖиҰҒдёҖж¬Ўж•°жҚ®е®ҡдҪҚжҹҘжүҫеҚіеҸҜпјҢжҺҘдёӢжқҘи®ҝй—®дёӢдёҖжқЎж•°жҚ®е°ұеҘҪдәҶгҖӮе…¶е®һеҜ№дәҺзңҹжӯЈзҡ„еҲ йҷӨж“ҚдҪңжқҘ讲并没жңүеӨӘеӨҡзҡ„еҢәеҲ«гҖӮеҰӮжһңеҗҲзҗҶзҡ„дҪҝз”ЁдәҶдё»й”®е’Ңе”ҜдёҖй”®еҸҜд»Ҙе°ҶдёҠйқўжҸҗеҲ°зҡ„дёӨзӮ№еҪұе“ҚйҷҚдҪҺгҖӮеңЁйҖ жҲҗд»Һеә“延иҝҹзҡ„жғ…еҶөдёӯпјҢжІЎжңүеҗҲзҗҶзҡ„дҪҝз”Ёдё»й”®е’Ңе”ҜдёҖй”®жҳҜдёҖдёӘжҜ”иҫғйҮҚиҰҒзҡ„еҺҹеӣ гҖӮ
гҖҖгҖҖжңҖеҗҺеҰӮжһңиЎЁдёҠдёҖдёӘзҙўеј•йғҪжІЎжңүзҡ„иҜқпјҢйӮЈд№Ҳжғ…еҶөеҸҳеҫ—жӣҙеҠ дёҘйҮҚпјҢз®ҖеҚ•зҡ„еӣҫеҰӮдёӢпјҡ
гҖҖгҖҖ
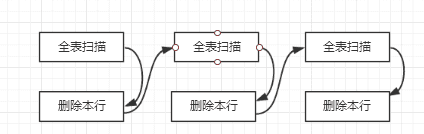
гҖҖгҖҖжҲ‘们еҸҜд»ҘзңӢеҲ°жҜҸдёҖиЎҢж•°жҚ®зҡ„жӣҙж”№йғҪйңҖиҰҒиҝӣиЎҢе…ЁиЎЁжү«жҸҸпјҢиҝҷз§Қй—®йўҳе°ұйқһеёёдёҘйҮҚдәҶгҖӮиҝҷз§Қжғ…еҶөдҪҝз”ЁеҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷзҡ„HASH_SCANйҖүйЎ№д№ҹи®ёеҸҜд»ҘжҸҗй«ҳжҖ§иғҪпјҢдёӢйқўжҲ‘们е°ұжқҘиҝӣиЎҢи®Ёи®әгҖӮ
гҖҖгҖҖдәҢгҖҒзЎ®и®ӨжҹҘжүҫж•°жҚ®зҡ„ж–№ејҸ
гҖҖгҖҖеүҚйқўзҡ„дҫӢеӯҗдёӯжҲ‘们жҺҘи§ҰдәҶеҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷпјҢиҝҷдёӘеҸӮж•°дё»иҰҒз”ЁдәҺзЎ®и®ӨеҰӮдҪ•жҹҘжүҫж•°жҚ®гҖӮе…¶еҸ–еҖјеҸҜд»ҘжҳҜдёӢйқўеҮ дёӘз»„еҗҲ(жқҘиҮӘе®ҳж–№ж–ҮжЎЈ)пјҢжәҗз ҒдёӯдҪ“зҺ°дёәдёҖдёӘдҪҚеӣҫпјҡж— й”ЎеҰҮ科еҢ»йҷўжҺ’иЎҢ http://www.0510bhyy.com/
гҖҖгҖҖTABLE_SCAN,INDEX_SCAN(й»ҳи®ӨеҖј)
гҖҖгҖҖINDEX_SCAN,HASH_SCAN
гҖҖгҖҖTABLE_SCAN,HASH_SCAN
гҖҖгҖҖTABLE_SCAN,INDEX_SCAN,HASH_SCAN
гҖҖгҖҖеңЁжәҗз ҒдёӯжңүеҰӮдёӢзҡ„иҜҙжҳҺпјҢеҪ“然е®ҳж–№ж–ҮжЎЈд№ҹжңүзұ»дјјзҡ„иҜҙжҳҺпјҡ
гҖҖгҖҖ/*
гҖҖгҖҖDecision table:
гҖҖгҖҖ- I --> Index scan / search
гҖҖгҖҖ- T --> Table scan
гҖҖгҖҖ- Hi --> Hash over index
гҖҖгҖҖ- Ht --> Hash over the entire table
гҖҖгҖҖ|--------------+-----------+------+------+------|
гҖҖгҖҖ| Index\Option | I , T , H | I, T | I, H | T, H |
гҖҖгҖҖ|--------------+-----------+------+------+------|
гҖҖгҖҖ| PK / UK | I | I | I | Hi |
гҖҖгҖҖ| K | Hi | I | Hi | Hi |
гҖҖгҖҖ| No Index | Ht | T | Ht | Ht |
гҖҖгҖҖ|--------------+-----------+------+------+------|
гҖҖгҖҖ*/
гҖҖгҖҖе®һйҷ…дёҠжәҗз Ғдёӯдјҡжңүдёүз§Қж•°жҚ®жҹҘжүҫзҡ„ж–№ејҸпјҢеҲҶеҲ«жҳҜпјҡ
гҖҖгҖҖROW_LOOKUP_INDEX_SCAN
гҖҖгҖҖеҜ№еә”еҮҪж•°жҺҘеҸЈпјҡRows_log_event::do_index_scan_and_update
гҖҖгҖҖROW_LOOKUP_HASH_SCAN
гҖҖгҖҖеҜ№еә”еҮҪж•°жҺҘеҸЈпјҡRows_log_event::do_hash_scan_and_update
гҖҖгҖҖROW_LOOKUP_TABLE_SCAN
гҖҖгҖҖеҜ№еә”еҮҪж•°жҺҘеҸЈпјҡRows_log_event::do_table_scan_and_update
гҖҖгҖҖеңЁжәҗз ҒдёӯеҰӮдёӢпјҡ
гҖҖгҖҖswitch (m_rows_lookup_algorithm)//ж №жҚ®дёҚеҗҢзҡ„з®—жі•еҶіе®ҡдҪҝз”Ёе“ӘдёӘж–№жі•
гҖҖгҖҖ{
гҖҖгҖҖcase ROW_LOOKUP_HASH_SCAN:
гҖҖгҖҖdo_apply_row_ptr= &Rows_log_event::do_hash_scan_and_update;
гҖҖгҖҖbreak;
гҖҖгҖҖcase ROW_LOOKUP_INDEX_SCAN:
гҖҖгҖҖdo_apply_row_ptr= &Rows_log_event::do_index_scan_and_update;
гҖҖгҖҖbreak;
гҖҖгҖҖcase ROW_LOOKUP_TABLE_SCAN:
гҖҖгҖҖdo_apply_row_ptr= &Rows_log_event::do_table_scan_and_update;
гҖҖгҖҖbreak;
гҖҖгҖҖеҶіе®ҡеҰӮдҪ•жҹҘжүҫж•°жҚ®д»ҘеҸҠйҖҡиҝҮе“ӘдёӘзҙўеј•жҹҘжүҫжӯЈжҳҜйҖҡиҝҮеҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷзҡ„и®ҫзҪ®е’ҢиЎЁдёӯжҳҜеҗҰжңүеҗҲйҖӮзҡ„зҙўеј•е…ұеҗҢеҶіе®ҡзҡ„пјҢ并дёҚжҳҜе®Ңе…Ёз”ұвҖҳslave_rows_search_algorithmsвҖҷеҸӮж•°еҶіе®ҡгҖӮ
гҖҖгҖҖдёӢйқўиҝҷдёӘеӣҫе°ұжҳҜеҶіе®ҡзҡ„иҝҮзЁӢпјҢеҸҜд»ҘеҸӮиҖғеҮҪж•°decide_row_lookup_algorithm_and_key(еҰӮдёӢеӣҫ)гҖӮ
гҖҖгҖҖдёүгҖҒROW_LOOKUP_HASH_SCANж–№ејҸзҡ„ж•°жҚ®жҹҘжүҫ
гҖҖгҖҖжҖ»зҡ„жқҘи®Іиҝҷз§Қж–№ејҸе’ҢROW_LOOKUP_INDEX_SCANе’ҢROW_LOOKUP_TABLE_SCANйғҪдёҚеҗҢпјҢе®ғжҳҜйҖҡиҝҮиЎЁдёӯзҡ„ж•°жҚ®е’ҢEventдёӯзҡ„ж•°жҚ®иҝӣиЎҢжҜ”еҜ№пјҢиҖҢдёҚжҳҜйҖҡиҝҮEventдёӯзҡ„ж•°жҚ®е’ҢиЎЁдёӯзҡ„ж•°жҚ®иҝӣиЎҢжҜ”еҜ№пјҢдёӢйқўжҲ‘们е°ҶиҜҰз»ҶжҸҸиҝ°иҝҷз§Қж–№жі•гҖӮ
гҖҖгҖҖеҒҮи®ҫжҲ‘们е°ҶеҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷи®ҫзҪ®дёәINDEX_SCAN,HASH_SCANпјҢдё”иЎЁдёҠжІЎжңүдё»й”®е’Ңе”ҜдёҖй”®зҡ„иҜқпјҢйӮЈд№ҲдёҠеӣҫзҡ„жөҒзЁӢе°ҶдјҡжҠҠж•°жҚ®жҹҘжүҫзҡ„ж–№ејҸи®ҫзҪ®дёәROW_LOOKUP_HASH_SCANгҖӮ
гҖҖгҖҖеңЁROW_LOOKUP_HASH_SCANеҸҲеҢ…еҗ«дёӨз§Қж•°жҚ®жҹҘжүҫзҡ„ж–№ејҸпјҡ
гҖҖгҖҖHi --> Hash over index
гҖҖгҖҖHt --> Hash over the entire table
гҖҖгҖҖеҜ№дәҺROW_LOOKUP_HASH_SCANжқҘи®ІпјҢе…¶йҰ–е…Ҳдјҡе°ҶEventдёӯзҡ„жҜҸдёҖиЎҢж•°жҚ®иҜ»еҸ–еҮәжқҘеӯҳе…ҘеҲ°HASHз»“жһ„дёӯпјҢеҰӮжһңиғҪеӨҹдҪҝз”ЁеҲ°HiйӮЈд№ҲиҝҳдјҡйўқеӨ–з»ҙжҠӨдёҖдёӘйӣҶеҗҲ(set)пјҢе°Ҷзҙўеј•й”®еҖјеӯҳе…ҘйӣҶеҗҲпјҢдҪңдёәзҙўеј•жү«жҸҸзҡ„дҫқжҚ®гҖӮеҰӮжһңжІЎжңүзҙўеј•иҝҷдёӘйӣҶеҗҲ(set)е°ҶдёҚдјҡз»ҙжҠӨзӣҙжҺҘдҪҝз”Ёе…ЁиЎЁжү«жҸҸпјҢеҚіHtгҖӮ
гҖҖгҖҖйңҖиҰҒжіЁж„ҸдёҖзӮ№иҝҷдёӘиҝҮзЁӢзҡ„еҚ•дҪҚжҳҜEventпјҢжҲ‘们еүҚйқўиҜҙиҝҮдёҖдёӘDELETE_ROWS_EVENTеҸҜиғҪеҢ…еҗ«дәҶеӨҡиЎҢж•°жҚ®пјҢEventжңҖеӨ§дёә8Kе·ҰеҸігҖӮеӣ жӯӨдҪҝз”ЁHt --> Hash over the entire tableзҡ„ж–№ејҸпјҢе°Ҷдјҡд»ҺеҺҹжқҘзҡ„жҜҸиЎҢж•°жҚ®иҝӣиЎҢдёҖж¬Ўе…ЁиЎЁжү«жҸҸеҸҳдёәжҜҸдёӘEventжүҚиҝӣиЎҢдёҖж¬Ўе…ЁиЎЁжү«жҸҸгҖӮ
гҖҖгҖҖдҪҶжҳҜеҜ№дәҺHi --> Hash over indexжқҘи®Іж•Ҳжһңе°ұжІЎжңүйӮЈд№ҲжҳҺжҳҫдәҶпјҢеӣ дёәеҰӮжһңеҲ йҷӨзҡ„ж•°жҚ®йҮҚеӨҚеҖјеҫҲе°‘зҡ„жғ…еҶөдёӢпјҢдҫқ然йңҖиҰҒи¶іеӨҹеӨҡзҡ„зҙўеј•е®ҡдҪҚжҹҘжүҫжүҚиЎҢпјҢдҪҶжҳҜеҰӮжһңеҲ йҷӨзҡ„ж•°жҚ®йҮҚеӨҚеҖјиҫғеӨҡйӮЈд№Ҳжһ„йҖ зҡ„йӣҶеҗҲ(set)е…ғзҙ е°ҶдјҡеӨ§еӨ§еҮҸе°‘пјҢд№ҹе°ұеҮҸе°‘дәҶзҙўеј•жҹҘжүҫе®ҡдҪҚзҡ„ејҖй”ҖгҖӮ
гҖҖгҖҖиҖғиҷ‘еҸҰеӨ–дёҖз§Қжғ…еҶөпјҢеҰӮжһңжҲ‘зҡ„жҜҸжқЎdeleteиҜӯеҸҘдёҖж¬ЎеҸӘеҲ йҷӨдёҖиЎҢж•°жҚ®иҖҢдёҚжҳҜdeleteдёҖжқЎиҜӯеҸҘеҲ йҷӨеӨ§йҮҸзҡ„ж•°жҚ®пјҢйӮЈиҝҷз§Қжғ…еҶөжҜҸдёӘDELETE_ROWS_EVENTеҸӘжңүдёҖжқЎж•°жҚ®еӯҳеңЁпјҢйӮЈд№ҲдҪҝз”ЁROW_LOOKUP_HASH_SCANж–№ејҸ并дёҚдјҡжҸҗй«ҳжҖ§иғҪпјҢеӣ дёәиҝҷжқЎж•°жҚ®иҝҳжҳҜйңҖиҰҒиҝӣиЎҢдёҖж¬Ўе…ЁиЎЁжү«жҸҸжҲ–иҖ…зҙўеј•е®ҡдҪҚжүҚиғҪжҹҘжүҫеҲ°ж•°жҚ®пјҢе’Ңй»ҳи®Өзҡ„ж–№ејҸжІЎд»Җд№ҲеҢәеҲ«гҖӮ
гҖҖгҖҖж•ҙдёӘиҝҮзЁӢеҸӮиҖғеҰӮдёӢжҺҘеҸЈпјҡ
гҖҖгҖҖRows_log_event::do_hash_scan_and_updateпјҡжҖ»жҺҘеҸЈпјҢи°ғз”ЁдёӢйқўдёӨдёӘжҺҘеҸЈгҖӮ
гҖҖгҖҖRows_log_event::do_hash_rowпјҡе°Ҷж•°жҚ®еҠ е…ҘеҲ°hashз»“жһ„пјҢеҰӮжһңжңүзҙўеј•иҝҳйңҖиҰҒз»ҙжҠӨйӣҶеҗҲ(set)гҖӮ
гҖҖгҖҖRows_log_event::do_scan_and_updateпјҡжҹҘжүҫ并且иҝӣиЎҢеҲ йҷӨж“ҚдҪңпјҢдјҡи°ғз”ЁRows_log_event::next_record_scanиҝӣиЎҢж•°жҚ®жҹҘжүҫгҖӮ
гҖҖгҖҖRows_log_event::next_record_scanпјҡе…·дҪ“зҡ„жҹҘжүҫж–№ејҸе®һзҺ°дәҶHi --> Hash over indexе’ҢHt --> Hash over the entire tableзҡ„жҹҘжүҫж–№ејҸ
гҖҖгҖҖдёӢйқўжҲ‘们иҝҳжҳҜз”ЁжңҖејҖе§Ӣзҡ„еҲ—еӯҗпјҢжҲ‘们еҲ йҷӨдәҶдёүжқЎж•°жҚ®пјҢеӣ жӯӨDELETE_ROW_EVENTдёӯеҢ…еҗ«дәҶдёүжқЎж•°жҚ®гҖӮеҒҮи®ҫжҲ‘们еҸӮж•°вҖҳslave_rows_search_algorithmsвҖҷи®ҫзҪ®дёәINDEX_SCAN,HASH_SCANгҖӮеӣ дёәжҲ‘зҡ„иЎЁдёӯжІЎжңүдё»й”®е’Ңе”ҜдёҖй”®пјҢеӣ жӯӨдјҡжңҖз»ҲдҪҝз”ЁROW_LOOKUP_HASH_SCANиҝӣиЎҢж•°жҚ®жҹҘжүҫгҖӮдҪҶжҳҜеӣ дёәжҲ‘们жңүдёҖдёӘзҙўеј•key aпјҢеӣ жӯӨдјҡдҪҝз”ЁеҲ°Hi --> Hash over indexгҖӮдёәдәҶжӣҙеҘҪзҡ„жҸҸиҝ°Hiе’ҢHtдёӨз§Қж–№ејҸпјҢжҲ‘们д№ҹеҒҮе®ҡеҸҰдёҖз§Қжғ…еҶөжҳҜиЎЁдёҠдёҖдёӘзҙўеј•йғҪжІЎжңүпјҢжҲ‘е°ҶдёӨз§Қж–№ејҸж”ҫеҲ°дёҖдёӘеӣҫдёӯж–№дҫҝеӨ§е®¶еҸ‘зҺ°дёҚеҗҢзӮ№пјҢеҰӮдёӢеӣҫпјҡ
гҖҖгҖҖеӣӣгҖҒжҖ»з»“
гҖҖгҖҖжҲ‘и®°еҫ—д»ҘеүҚжңүдҪҚжңӢеҸӢй—®жҲ‘дё»еә“жІЎжңүдё»й”®еҰӮжһңжҲ‘еңЁд»Һеә“е»әз«ӢдёҖдёӘдё»й”®иғҪйҷҚдҪҺ延иҝҹеҗ—?иҝҷйҮҢжҲ‘们е°ұжё…жҘҡдәҶзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„пјҢеӣ дёәд»Һеә“дјҡж №жҚ®Eventдёӯзҡ„иЎҢж•°жҚ®иҝӣиЎҢдҪҝз”Ёзҙўеј•зҡ„йҖүжӢ©гҖӮйӮЈд№ҲжҖ»з»“дёҖдёӢпјҡ
гҖҖгҖҖslave_rows_search_algorithmsеҸӮж•°и®ҫзҪ®дәҶHASH_SCAN并дёҚдёҖе®ҡдјҡжҸҗй«ҳжҖ§иғҪпјҢеҸӘжңүж»Ўи¶іеҰӮдёӢдёӨдёӘжқЎд»¶жүҚдјҡжҸҗй«ҳжҖ§иғҪпјҡ
гҖҖгҖҖд»Һеә“зҙўеј•зҡ„еҲ©з”ЁжҳҜиҮӘиЎҢеҲӨж–ӯзҡ„пјҢйЎәеәҸдёәдё»й”®->е”ҜдёҖй”®->жҷ®йҖҡзҙўеј•гҖӮ
гҖҖгҖҖеҰӮжһңslave_rows_search_algorithmsеҸӮж•°жІЎжңүи®ҫзҪ®HASH_SCANпјҢ并且没жңүдё»й”®/е”ҜдёҖй”®йӮЈд№ҲжҖ§иғҪе°ҶдјҡжҖҘеү§дёӢйҷҚйҖ жҲҗ延иҝҹгҖӮеҰӮжһңиҝһзҙўеј•йғҪжІЎжңүйӮЈд№ҲиҝҷдёӘжғ…еҶөжӣҙеҠ дёҘйҮҚпјҢеӣ дёәжӣҙж”№зҡ„жҜҸдёҖиЎҢж•°жҚ®йғҪдјҡеј•еҸ‘дёҖж¬Ўе…ЁиЎЁжү«жҸҸгҖӮ
гҖҖгҖҖеӣ жӯӨжҲ‘们еҸ‘зҺ°еңЁMySQLдёӯејәеҲ¶и®ҫзҪ®дё»й”®еҸҲеӨҡдәҶдёҖдёӘзҗҶз”ұгҖӮ





