HashTable-散列表/哈希表,是根据关键字(key)而直接访问在内存存储位置的数据结构。它通过一个关键值的函数将所需的数据映射到表中的位置来访问数据,这个映射函数叫做散列函数,存放记录的数组叫做散列表。 构造哈希表的几种方法 直接定址法--取关键字的某个线性函数为散列地址,Hash(Key)= Key 或 Hash(Key)= A*Key + B,A、B为常数。 除留余数法--取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址。Hash(Key)= Key % P。 平方取中法 折叠法 随机数法 数学分析法 哈希冲突/哈希碰撞 不同的Key值经过哈希函数Hash(Key)处理以后可能产生相同的值哈希地址,我们称这种情况为哈希冲突。任意的散列函数都不能避免产生冲突。

处理哈希冲突的闭散列方法
线性探测

#pragma once
#include <string>
#include <iostream>
using namespace std;
namespace First
{
enum State
{
EMPTY,
DELETE,
EXIST,
};
template<class K>
struct __HashFunc // 产生键值(如把string的转化成数字) 默认的返回哈希键值key的 仿函数
{
size_t operator()(const K& key)
{
return key;
}
};
template<class K>
class HashTable
{
// Key形式的线性探测
public:
HashTable(size_t capacity = 10)
:_tables(new K[capacity])
,_size(0)
,_capacity(capacity)
,_states(new State[capacity])
{
// memset 有问题 是以字节为单位初始化的 但第二个参数值为int
// 会出问题 本来初始化为0x00000001 结果初始化为0x01010101
//memset(_states, EMPTY, sizeof(State) * capacity);
for (size_t i = 0; i < capacity; i++)
{
_states[i] = EMPTY;
}
}
HashTable(const HashTable<K>& ht)
:_tables(new K[ht._capacity])
,_size(0)
,_capacity(ht._capacity)
,_states(new State[ht._capacity])
{
for (size_t i = 0; i < ht._capacity; i++)
{
if (EXIST == ht._states[i])
{
Insert(ht._tables[i]);
}
}
}
HashTable& operator=(const HashTable<K>& ht)
{
if (ht._tables != _tables && ht._states != _states)
{
HashTable<K> tmp(ht);
Swap(tmp);
}
return *this;
}
~HashTable()
{
if (NULL != _tables)
{
delete[] _tables;
}
if (NULL != _states)
{
delete[] _states;
}
}
bool Insert(const K& key)
{
// 静态哈希表 不扩容的
/*if (_size == _capacity)
{
cout<<"HashTable is full"<<endl;
return false;
}*/
_CheckCapacity();
size_t index = _HashFunc(key);
while (EXIST == _states[index])
{
index++;
if (_capacity == index)
{
index=0;
}
}
_tables[index] = key;
_states[index] = EXIST;
_size++;
return true;
}
int Find(const K& key)
{
size_t index = _HashFunc(key);
size_t start = index;
// 存在 或者 被删除 两种状态
while (EMPTY != _states[index])
{
if (_tables[index] == key)
{
if (_states[index] == EXIST)
{
return index;
}
else // 被删除 DELETE
{
return -1;
}
}
index++;
if (index == _capacity)
{
index = 0;
}
// 找一圈 没找到就停止 防止死循环
if (index == start)
{
return -1;
}
}
return -1;
}
bool Remove(const K& key)
{
int index = Find(key);
if (-1 != index)
{
_states[index] = DELETE;
--_size;
return true;
}
return false;
}
// 线性探测计算出存放位置(假设不哈希冲突)
size_t _HashFunc(const K& key)
{
__HashFunc<K> hf;
return hf(key) % _capacity; // 仿函数hf()
// 匿名对象
// return __HashFunc<K>()(key) % _capacity;
}
void Print()
{
for (size_t i = 0; i < _capacity; i++)
{
if (EXIST == _states[i])
{
cout<< i << "EXIST:" << _tables[i] << endl;
}
else if (DELETE == _states[i])
{
cout<< i << "DELETE:" << _tables[i] << endl;
}
else
{
cout << i << "EMPTY" << _tables[i] <<endl;
}
}
}
void Swap(HashTable<K>& ht)
{
swap(_size, ht._size);
swap(_states, ht._states);
swap(_tables, ht._tables);
swap(_capacity, ht._capacity);
}
protected:
void _CheckCapacity() // 扩容
{
// 动态的 可扩容的
// 高效哈希表的载荷因子大概在0.7-0.8较好
if (10 * _size / _capacity >= 7) // _size/_capacity为0 因为都是××× 所以乘10
// 保证载荷因子在0.7之内
{
HashTable<K> tmp(2 * _capacity);
for (size_t i = 0; i < _capacity; i++)
{
if (EXIST == _states[i])
{
tmp.Insert(_tables[i]);
}
}
Swap(tmp);
}
}
protected:
K* _tables; // 哈希表
State* _states; // 状态表
size_t _size;
size_t _capacity;
};
}
void test_namespace_First()
{
using namespace First;
HashTable<int> ht;
ht.Insert(89);
ht.Insert(18);
ht.Insert(49);
ht.Insert(58);
ht.Insert(9);
ht.Print();
int ret = ht.Find(49);
cout<<ret<<endl;
ht.Remove(89);
ht.Print();
ht.Remove(18);
ht.Print();
cout<<"---------------------------"<<endl;
HashTable<int> ht2 = ht;
ht2.Print();
cout<<"---------------------------"<<endl;
ht = ht2;
ht.Print();
cout<<"---------------------------"<<endl;
}
//============================================================================2 二次探测

namespace Second
{
enum State
{
EMPTY,
DELETE,
EXIST,
};
// Key/Value
template<class K, class V>
struct HashTableNode
{
K _key;
V _value;
};
template<class K>
struct __HashFunc // 默认的返回哈希键值key的 仿函数
{
size_t operator()(const K& key)
{
return key;
}
};
// 特化string的__HashFunc 仿函数
template<>
struct __HashFunc<string>
{
//下面这种缺点 产生重复key 如“abcd” 与 “bcda”
size_t operator()(const string& str)
{
size_t key = 0;
for (size_t i = 0; i < str.size(); i++)
{
key += str[i];
}
return key;
}
};
// 实现哈希表的Key/Value形式的二次探测
template<class K, class V, class HashFunc = __HashFunc<K>>
class HashTable
{
typedef HashTableNode<K,V> Node;
public:
HashTable(size_t capacity = 10)
:_tables(new Node[capacity])
,_size(0)
,_capacity(capacity)
,_states(new State[capacity])
{
// memset 有问题 是以字节为单位初始化的 但第二个参数值为int
// 会出问题 本来初始化为0x00000001 结果初始化为0x01010101
//memset(_states, EMPTY, sizeof(State) * capacity);
for (size_t i = 0; i < capacity; i++)
{
_states[i] = EMPTY;
}
}
HashTable(const HashTable<K, V, HashFunc>& ht)
:_tables(new Node[ht._capacity])
,_size(0)
,_capacity(ht._capacity)
,_states(new State[ht._capacity])
{
for (size_t i = 0; i < ht._capacity; i++)
{
if (EXIST == ht._states[i])
{
Insert(ht._tables[i]._key, ht._tables[i]._value);
}
}
}
HashTable& operator=(const HashTable<K, V, HashFunc>& ht)
{
if (ht._tables != _tables && ht._states != _states)
{
HashTable<K, V, HashFunc> tmp(ht);
Swap(tmp);
}
return *this;
}
~HashTable()
{
if (NULL != _tables)
{
delete[] _tables;
}
if (NULL != _states)
{
delete[] _states;
}
}
bool Insert(const K& key, const V& value)
{
// 静态哈希表 不扩容的
/*if (_size == _capacity)
{
cout<<"HashTable is full"<<endl;
return false;
}*/
_CheckCapacity();
//size_t hashKeyStart = _HashFunc(key);
//size_t add_more = 1;
//size_t index = hashKeyStart;
//// ****************************************
//// 二次探测 Hash(key) + 0 Hash(key) + 1^2 Hash(key) + 2^2
//while (EXIST == _states[index])
//{
// index = hashKeyStart + add_more * add_more;
// add_more++;
// if (index >= _capacity)
// {
// index = index % _capacity;
// }
//}
// ****************************************
// 改进 用GetNextIndex 解决哈希冲突
size_t index = _HashFunc(key);
// 二次探测
size_t i = 1;
while (EXIST == _states[index])
{
index = _GetNextIndex(index, i++);
if (index >= _capacity)
{
index = index % _capacity;
}
}
_tables[index]._key = key;
_tables[index]._value = value;
_states[index] = EXIST;
_size++;
return true;
}
int Find(const K& key)
{
size_t index = _HashFunc(key);
size_t start = index;
size_t i = 1;
// 存在 或者 被删除 两种状态
while (EMPTY != _states[index])
{
if (_tables[index]._key == key)
{
if (_states[index] == EXIST)
{
return index;
}
else // 被删除 DELETE
{
return -1;
}
}
index = _GetNextIndex(index, i++);
if (index >= _capacity)
{
index = index % _capacity;
}
// 因为有填充因子 不为100% 不会出现全满且key!=_key 导致死循环的情况
}
return -1;
}
bool Remove(const K& key)
{
int index = Find(key);
if (-1 != index)
{
_states[index] = DELETE;
--_size;
return true;
}
return false;
}
// 二次探测计算出存放位置
size_t _HashFunc(const K& key)
{
// __HashFunc<K> hf;
HashFunc hf;
return hf(key) % _capacity; // 仿函数hf()
// 匿名对象
// return __HashFunc<K>()(key) % _capacity;
}
// 哈希冲突时 得到下一个index的可以利用上一个index的值 这样能提高效率 比如 string的index计算就比较费时
size_t _GetNextIndex(size_t prev, size_t i)
{
//二次探测
// 公式推导 Hash(i) = Hash(0) + i^2
// Hash(i-1) = Hash(0) + (i -1)^2=Hash(0)+i^2-2i+1
// 上面两式相减 得 Hash(i) = Hash(i-1) + +2*i - 1;
return prev + 2*i - 1;
}
void Print()
{
for (size_t i = 0; i < _capacity; i++)
{
if (EXIST == _states[i])
{
cout<< i << "EXIST:" <<_tables[i]._key << "-------" <<_tables[i]._value <<endl;
}
else if (DELETE == _states[i])
{
cout<< i << "DELETE:" << _tables[i]._key << "-------" << _tables[i]._value <<endl;
}
else
{
cout << i << "EMPTY:" << _tables[i]._key << "-------" << _tables[i]._value <<endl;
}
}
}
void Swap(HashTable<K, V, HashFunc>& ht)
{
swap(_size, ht._size);
swap(_states, ht._states);
swap(_tables, ht._tables);
swap(_capacity, ht._capacity);
}
protected:
void _CheckCapacity() // 扩容
{
// 动态的 可扩容的
// 高效哈希表的载荷因子大概在0.7-0.8较好
if (10 * _size / _capacity >= 7) // _size/_capacity为0 因为都是××× 所以乘10
// 保证载荷因子在0.7之内
{
HashTable<K, V, HashFunc> tmp(2 * _capacity);
for (size_t i = 0; i < _capacity; i++)
{
if (EXIST == _states[i])
{
tmp.Insert(_tables[i]._key, _tables[i]._value);
}
}
Swap(tmp);
}
}
protected:
Node* _tables; // 哈希表
State* _states; // 状态表
size_t _size;
size_t _capacity;
};
}
void test_namespace_Second()
{
using namespace Second;
HashTable<string, string> ht;
ht.Insert("one","一");
ht.Insert("two","二");
ht.Insert("three","三");
ht.Insert("four","四");
ht.Insert("five","五");
ht.Print();
int ret = ht.Find("two");
cout<<ret<<endl;
ret = ht.Find("hfjks");
cout<<ret<<endl;
ht.Remove("one");
ht.Print();
ht.Remove("two");
ht.Print();
cout<<"---------------------------"<<endl;
HashTable<string, string> ht2 = ht;
ht2.Print();
cout<<"---------------------------"<<endl;
ht = ht2;
ht.Print();
cout<<"---------------------------"<<endl;
}3 处理哈希冲突的开链法(哈希桶)
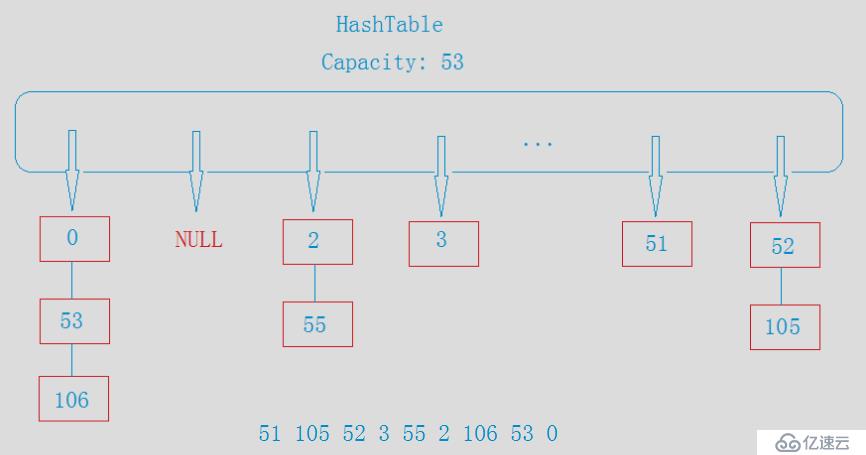
#pragma once
#include<iostream>
#include<vector>
#include<string>
/*********
* 哈希桶 (处理哈希冲突的开链法)
*
****************/
template<class K, class V>
struct HashTableNode
{
K _key;
V _value;
HashTableNode* _next;
HashTableNode()
:_next(NULL)
{}
HashTableNode(const K& key, const V& value)
:_key(key)
,_value(value)
,_next(NULL)
{}
};
template<class K>
struct DefaultHashFunc
{
size_t operator()(const K& key)
{
return key ;
}
};
template<>
struct DefaultHashFunc<std::string>
{
size_t operator()(const std::string& str)
{
size_t key = 0;
for (size_t i = 0; i < str.size(); i++)
{
key += str[i];
}
return key;
}
};
template<class K, class V, class HashFunc = DefaultHashFunc<K>>
class HashTableBucket
{
typedef HashTableNode<K, V> Node;
public:
HashTableBucket()
:_size(0)
{}
HashTableBucket(const HashTableBucket<K, V, HashFunc>& ht)
:_size(ht._size)
{
_tables.resize(ht._tables.size());
for (size_t i = 0; i < ht._tables.size(); i++)
{
Node* cur = ht._tables[i];
while (NULL != cur)
{
Node* newNode = new Node(cur->_key, cur->_value);
newNode->_next = _tables[i];
_tables[i] = newNode;
cur = cur->_next;
}
}
}
HashTableBucket& operator=(const HashTableBucket& ht)
{
if (this != &ht)
{
HashTableBucket tmp(ht);
_tables.swap(tmp._tables);
std::swap(_size, tmp._size);
}
return *this;
}
~HashTableBucket()
{
for (size_t index = 0 ; index < _tables.size(); index++)
{
Node* cur = _tables[index];
while (NULL != cur)
{
Node* del = cur;
cur = cur->_next;
delete del;
}
}
_size = 0;
}
bool Insert(const K& key, const V& value)
{
// 检测容量
_CheckExpand();
size_t index = _HashFunc(key, _tables.size());
Node* cur = _tables[index];
// 防止冗余
while (NULL != cur)
{
// 键值重复
if (key == cur->_key)
{
return false;
}
cur = cur->_next;
}
// 头插 (同一单链表上 顺序无关)
Node* newNode = new Node(key, value);
newNode->_next = _tables[index];
_tables[index] = newNode;
++_size;
return true;
}
Node* Find(const K& key)
{
size_t index = _HashFunc(key, _tables.size());
Node* cur = _tables[index];
while (NULL != cur)
{
if (key == cur->_key)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = _HashFunc(key, _tables.size());
Node* cur = _tables[index];
Node* prev = cur;
if (NULL == cur)
{
return false;
}
// 一个结点
if (NULL == cur->_next && cur->_key == key)
{
delete cur;
_tables[index] = NULL;
--_size;
return true;
}
cur = cur->_next;
while (NULL != cur)
{
if (key == cur->_key)
{
prev->_next = cur->_next;
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
void PrintTables()
{
for (size_t index = 0; index < _tables.size(); index++)
{
Node* cur = _tables[index];
while (NULL != cur)
{
std::cout<<index<<" {"<<cur->_key<<"---"<<cur->_value<<"} ";
cur = cur->_next;
if (NULL == cur)
{
std::cout<<std::endl;
}
}
}
}
protected:
size_t _HashFunc(const K& key, const size_t size)
{
// _table.size90 哈希桶空间大小 vector 数组大小(相当于哈希表的空间)
return HashFunc()(key) % size;
}
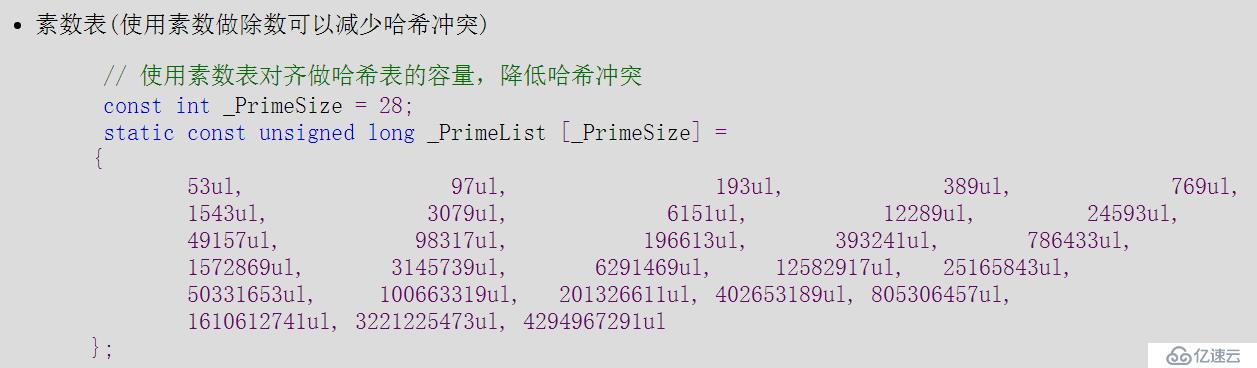
size_t _GetNextPrime() // 得到下一个扩容的素数
{
static const size_t _PrimeSize = 28;
static const unsigned long _PrimeList [_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i < _PrimeSize; i++)
{
if (_PrimeList[i] > _size)
{
return _PrimeList[i];
}
}
return _PrimeList[_PrimeSize - 1];
}
void _CheckExpand() // 扩容(容量都是素数)
{
if (_size == _tables.size())
{
size_t newSize = _GetNextPrime();
std::vector<Node*> newTables;
newTables.resize(newSize);
// newTables.resize() 已经初始化成0x00000000
/*for (size_t i = 0; i < newSize; i++)
{
newTables[i] = NULL;
}*/
// 将每个单链表上的元素摘下来 挂到新表上
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (NULL != cur)
{
// 摘结点
Node* pTmp = cur;
cur = cur->_next;
// 挂结点
size_t index = _HashFunc(pTmp->_key, newSize);
pTmp->_next = newTables[index];
newTables[index] = pTmp;
}
_tables[i] = NULL;
}
_tables.swap(newTables);
}
}
protected:
std::vector<Node*> _tables; // 存放头指针
size_t _size; // _tables中已有元素(头指针)的个数
};================测试=====================================
#define _CRT_SECURE_NO_WARNINGS 1
//#include"HashTable.hpp
#include"HashTableBucket.hpp"
void test_HashTable()
{
// test_namespace_First();
// test_namespace_Second();
}
void test_HashTableBucket1()
{
HashTableBucket<int,int> ht;
ht.Insert(1,1);
ht.Insert(2,2);
ht.Insert(3,3);
ht.Insert(4,4);
ht.Insert(53 + 1,53);
ht.PrintTables();
HashTableBucket<int,int>ht2(ht);
ht2.PrintTables();
HashTableNode<int,int>* pht2 = ht2.Find(4);
bool brm = ht2.Remove(4);
pht2 = ht2.Find(4);
brm = ht2.Remove(5); // false
ht = ht2;
ht.PrintTables();
HashTableBucket<int,int> ht3;
//扩容测试 _CheckExpand() //
for (size_t i = 0; i < 53; i++)
{
ht3.Insert(i,1);
}
// 增容
ht3.Insert(53,4);
std::cout<<"-------------------"<<std::endl;
ht3.PrintTables();
}
void test_HashTableBucket2()
{
// 特殊类型测试
HashTableBucket<std::string,std::string> ht;
ht.Insert("one","一");
ht.Insert("two","二");
ht.Insert("three","三");
ht.Insert("four","四");
ht.PrintTables();
HashTableBucket<std::string,std::string>ht2(ht);
ht2.PrintTables();
HashTableNode<std::string,std::string>* pht2 = ht2.Find("two");
bool brm = ht2.Remove("two");
pht2 = ht2.Find("two");
brm = ht2.Remove("five"); // false
ht = ht2;
ht.PrintTables();
HashTableBucket<std::string,std::string> ht3;
//扩容测试 _CheckExpand() //
for (size_t i = 0; i < 53; i++)
{
ht3.Insert(std::string().append(i,'0'),"ooooo");
}
// 增容
ht3.Insert("53","4");
std::cout<<"-------------------"<<std::endl;
ht3.PrintTables();
}
int main()
{
test_HashTableBucket2();
return 0;
}
字符串哈希算法
http://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
static size_t BKDRHash(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str )
{
hash = hash * seed + (* str++);
}
return (hash & 0x7FFFFFFF);
}
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





