让我们快乐的开始到结束-经过漫长的搜索,我们设法在我们的一个日志侦听器中发现了Netty内存泄漏,并能够在服务崩溃之前及时解决并修复问题。
备份一下,让我们提供一些背景信息。
Logz.io的日志侦听器充当从我们的用户收集的数据的入口,然后被推送到我们的Kafka实例。 它们是基于Netty的Dockerized Java服务,旨在处理极高的吞吐量。
网络内存泄漏并非罕见。 过去,我们分享了从ByteBuf内存泄漏中汲取的一些经验教训,并且还会出现其他类型的内存问题,尤其是在处理大量数据时。 手动调整未使用对象的清理过程非常棘手,并且消耗内存的情况是许多伤痕累累的工程团队遇到的情况(不相信我吗?
但是,在每天要处理数百万条日志消息的生产环境中,这些事件冒着被忽视的风险,直到灾难来临和内存用完为止。 然后,他们非常受关注。
那么,在这种情况下如何识别Netty内存泄漏?
答案就是Logz.io的Cognitive Insights,该技术将机器学习与众包相结合,可以准确地揭示此类事件。 它通过识别日志和技术论坛中的讨论之间的相关性并将它们标记为Kibana中的事件来工作。 然后,它将它们与可操作的信息一起显示,这些信息可用于调试并防止将来发生同一事件。
在相关日子(即1月15日),我们的系统记录了超过4亿条日志消息。 在这些消息中,Cognitive Insights识别了由侦听器服务生成的一条日志消息-NettyBufferLeak。
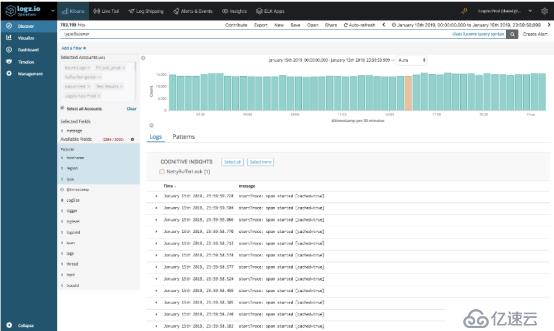
打开洞察力,揭示了更多细节。 事实证明,该事件在最近一周内发生了四次,并且该特定事件已在Netty的技术文档中进行了讨论。
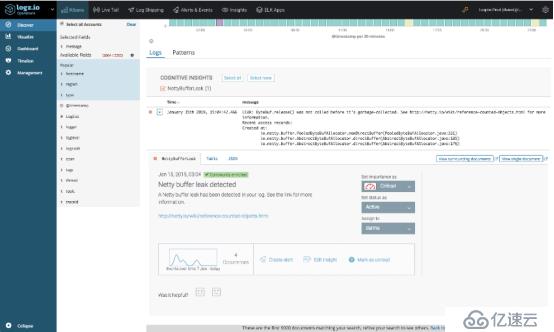
通过查看消息中包含的实际堆栈跟踪,我们的团队能够了解泄漏的原因并进行修复。
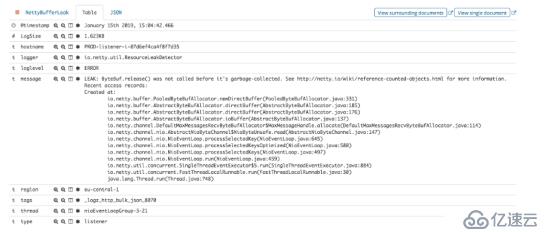
尽管有针对失败的侦听器的故障安全机制,但Logz.io不能承受这种情况,因此,我们宁愿避免唤醒一位待命的工程师。
为防止将来发生类似的内存泄漏,我们根据见解中提供给我们的信息执行了许多措施。 首先,我们根据特定的日志消息创建了测试,洞察力浮出水面,然后使用它们来验证我们对漏洞的修复未生成日志。 其次,如果此确切事件将来发生,我们将创建警报以通知我们。
4、结论
在日志分析领域,工程师面临的最大挑战之一是如何在大海捞针中找到针头并识别出单个日志消息,这表明环境中的某些内容已损坏并将使我们的服务崩溃。通常,事件不会在被摄入系统中的大数据流中被忽略。
有多种方法可用来克服这一挑战,一种流行的方法是异常检测。确定正常行为的基准,并偏离该基准触发警报。尽管在某些情况下足够了,但传统的异常检测系统很可能无法识别Netty内存泄漏,这是一个非常缓慢和逐渐的事件,随着时间的推移会间歇性地发生泄漏。
利用特定日志消息和网络上大量技术知识之间的关联性,可以帮助您发现那些本来不会引起注意的关键事件。我们的许多用户已经为此目的而利用了Cognitive Insights,接下来我将介绍一些我们帮助发现的事件的示例。
文章写到这里,如有不足之处欢迎补充评论。
抽丝剥茧细说架构那些事--优锐课
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





