本文是《Java中注解学习系列教程》第四篇文章也是小案例文章。
自定义注解小案例是:使用自定义注解实现excel导出。
Excel导出分析:

有表头、数据值。一般第一行是表头,从第二行开始就是数据了。而且我们可以发现,每个表头都会对于一列。
如上图中的。主键ID对应的是A列 、姓名对应的是B列、生日对应的是C列、性别对应的是D列。
我们来分析自定义主键需要定义哪些?
1:主键范围
2:列对应的中文
3:所在那一列
经过分析我们知道,Excel中每一列对应的其实就是对象中的属性。所有我们知道了:
1:自定义注解Target的范围是Filed即@Target({ElementType.FIELD})
2:自定义注解的成员变量有一个是中文名称这个字段。我们取名为:String ZHName() ;
3:还需要有个成员变量就是指定当前这个属性或者是中文(表头)位于哪一列。我们取名为: String colum();
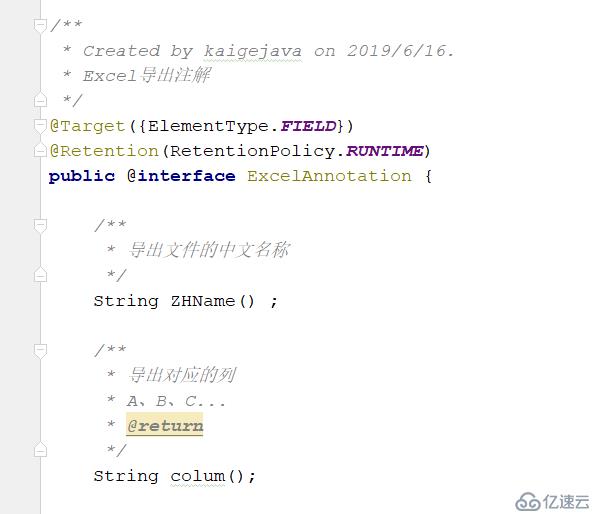
经过上面分析,我们可以得到这个自定义注解具体了。
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelAnnotation {
/**
* 导出文件的中文名称
*/
String ZHName() ;
/**
* 导出对应的列
* A、B、C...
* @return
*/
String colum();
}
接下来我们创建对象。开始测试:
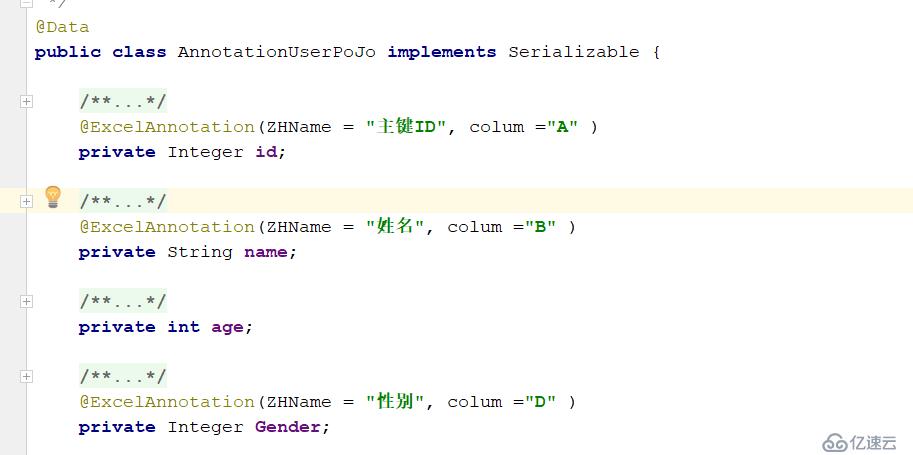
一:创建POJO对象
创建用户对象:AnnotationUserPoJo
属性有:
/** *注解id **/ private Integer id; /** *用户名 **/ private String name; /** *性别 **/ private Integer Gender;
在需要的字段上使用我们自定义的ExcelAnnotation注解。
具体用法:
/** * 主键id */ @ExcelAnnotation(ZHName = "主键ID", colum ="A" ) private Integer id;
编写Excel工具类:
在这里凯哥就不贴出全码了,因为工具类中代码太多。只讲重要的。代码会放在git上的。
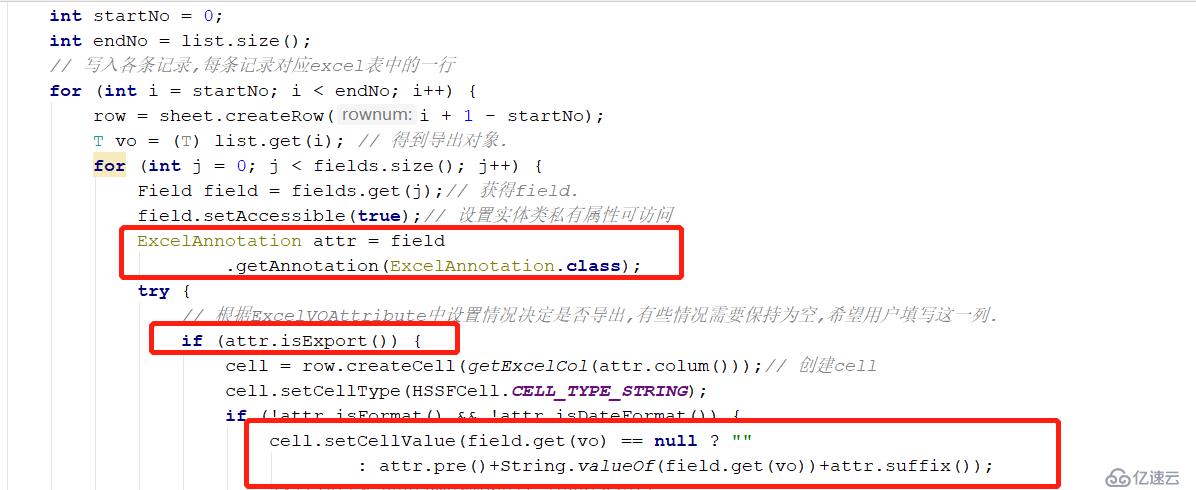
我们在解析的时候,先判断每个自读是否使用了注解。如使用了注解就进行解析。
三:创建junit测试类:
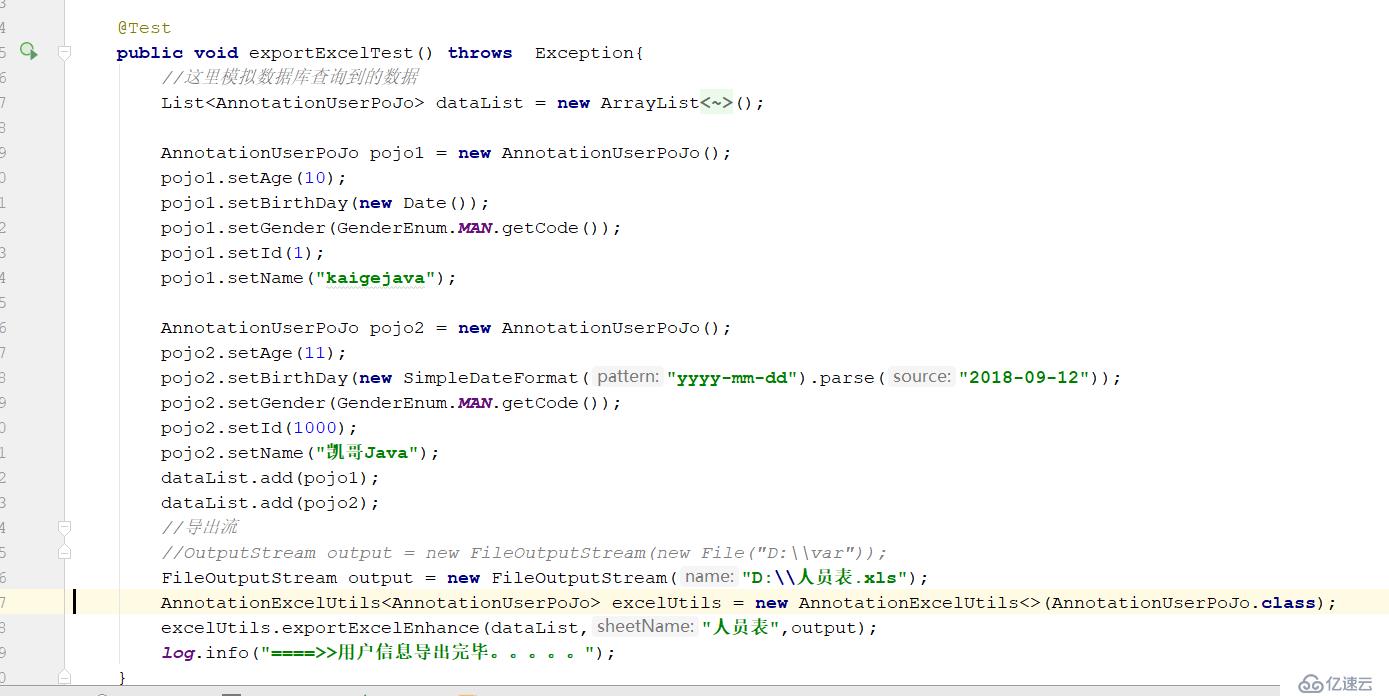
执行test测试。查看结果。
问题分析:
1:如果是date类型的数据,怎么格式化?在文章刚开始凯哥贴出的图中,生日是格式化好的
2:枚举类型。如性别。在文章刚开始凯哥贴出的图中,性别还是数字1.而非男或者女。
以上两个问题怎么解决呢?
凯哥将在下一篇文章中详细讲解。以及工作中常用到的怎么处理。
声明:本文由凯哥Java系列教程中Java注解讲解第四篇文章。
本文出处:http://www.kaigejava.com/article/detail/442
凯哥博客:www.kaigejava.com
凯哥公众号:凯哥Java(kaigejava)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





