[TOC]
PriorityBlockingQueue 是一个支持优先级的×××阻塞队列,数据结构采用的是最小堆是通过一个数组实现的,队列默认采用自然排序的升序排序,如果需要自定义排序,需要在构造队列时指定Comparetor比较器,队列也是使用ReentrantLock锁来实现的同步机制。
// 数组的最大容量 2^31 - 8
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 二叉堆数组
private transient Object[] queue;
// 总数
private transient int size;
// /默认比较器
private transient Comparator<? super E> comparator;
// 锁
private final ReentrantLock lock;
// 为空队列
private final Condition notEmpty;
// 自旋锁,在数组扩容时使用
private transient volatile int allocationSpinLock;注意:这里解释下这个Integer.MAX_VALUE - 8,为什么数组的最大长度是这么多了,这其实和int的最大值有关,最大值就是(1 << 32) -1 ,大家有没有发现数组的长度类型是int,为什么是int了???我也不知道,我也试了其它数据类型发现数组的长度必须是int类型,哈哈,所以也可以理解为什么是最大值了,至于为什么要减八了,是因为创建数组本身的信息(对象头,class信息啊)也是需要存储空间的,所以需要这8位的空间。
public boolean add(E e) {
return offer(e);
}由于是×××队列所以put方法不会阻塞,也是直接调用了offer方法.
public void put(E e) {
offer(e); // never need to block
} public boolean offer(E e, long timeout, TimeUnit unit) {
return offer(e); // never need to block
} // 添加元素
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
// size大于等于数组的长度
while ((n = size) >= (cap = (array = queue).length))
// 扩容
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null) // 默认排序
siftUpComparable(n, e, array);
else // 自定义排序
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}这里我们主要分析下offer方法里面的两个重要方法,扩容和入队,tryGrow,siftUpComparable方法。
// 扩容方法
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
// 只允许一个线程去扩容
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
// oldCap小于64 就加2 ,小于等于64就扩容50%
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// 不可以超过MAX_ARRAY_SIZE
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // back off if another thread is allocating
Thread.yield(); // 扩容获取锁失败的线程,尽量让出cpu
lock.lock(); // 重新获取锁
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}分析扩容:
最小堆的构建
// 保证了每条链的顺序小到大
private static <T> void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (key.compareTo((T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = key;
}分析:
先得解释下(k - 1) >>> 1,就是求的商,我们来模拟插入五个数吧,默认容量是11.
第一次插入一个1,此时的k是0,x是1,k不大于0,直接插入。
| 索引 | 0 | ||||
|---|---|---|---|---|---|
| 值 | 1 |
第二次我们插入一个0,此时的k是1,x是0,parent是0,然后获取0位置索引的值和现在的比较,现在其实是不大于0的,所以此时交换了位置,array[k] = e; k = parent;parent是0,所以结束循环然后在0的位置设置当前x是1。
| 索引 | 0 | 1 | |||
|---|---|---|---|---|---|
| 值 | 0 | 1 |
第三次我们插入一个5,此时的k是2,x是5,parent 是0,然后获取0位置的值和插入值标记,发现是大于0的所以直接插入,在2的位置插入5。
| 索引 | 0 | 1 | 2 | ||
|---|---|---|---|---|---|
| 值 | 0 | 1 | 5 |
第四次我们插入一个4,此时的k是3,x是4,parent是1,然后获取1位置的值和插入值比较,发现是大于0的,所以直接插入在3的位置插入。
| 索引 | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| 值 | 0 | 1 | 5 | 4 |
第五次我们插入一个3,此时的k是4,x是3,parent是1,然后获取1位置值和插入值做比较,发现大于0的,所以直接在4的位置插入。
| 索引 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 值 | 0 | 1 | 5 | 4 | 3 |
我们用一个图来描绘下这个数组,怎么出现的这个图了,我们发现每次插入的数的索引就是数组的长度,然后通过(i - 1)>>> 2 = n求父节点,通过比较和父节点比较确认自己的位置,左右子节点其实就是2n+1,2n+2,左右子节点就是数组的相邻元素,我们发现子节点一定比父节点大,这就是最小堆;每次插入一个元素都是从最底层向上冒泡,维护最小堆的次序。
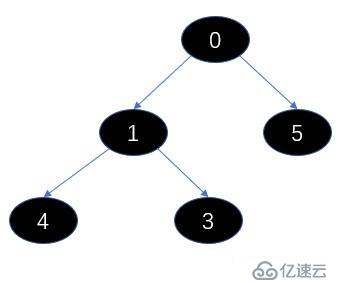
调用了 dequeue方法。
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 弹出根节点
return dequeue();
} finally {
lock.unlock();
}
}
// 带超时时间
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null && nanos > 0)
nanos = notEmpty.awaitNanos(nanos);
} finally {
lock.unlock();
}
return result;
}也是调用了dequeue方法,这个方法支持线程的中断。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}private E dequeue() {
int n = size - 1;
// 队列还没有初始化
if (n < 0)
return null;
else {
Object[] array = queue;
// 获取根节点
E result = (E) array[0];
// 获取尾节点
E x = (E) array[n];
// 尾节点置位null
array[n] = null;
Comparator<? super E> cmp = comparator;
// 重新排序最小堆
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}其实上面就是返回了根节点,然后获取尾节点放在根节点的位置调整最小堆请看siftDownComparable方法。
private static <T> void siftDownComparable(int k, T x, Object[] array,
int n) {
// n是数组的最大索引 k开始是0 x就是尾节点的值
if (n > 0) {
// x是最后一个节点的值
Comparable<? super T> key = (Comparable<? super T>)x;
int half = n >>> 1; // 最后一个节点的父节点 // loop while a non-leaf
while (k < half) { // k是头节点 k> 了 说明到最后了
int child = (k << 1) + 1; // assume left child is least // 左子节点
Object c = array[child]; // 左节点的值
int right = child + 1; // 右子节点
if (right < n && // 左子节点大于由子节点
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
c = array[child = right]; // c就是右子节点
if (key.compareTo((T) c) <= 0) // 找到了子节点比自己大的
break;
array[k] = c;
k = child;
}
array[k] = key;
}
}分析:
我们上图的5个元素为例,进行一次出队操作。
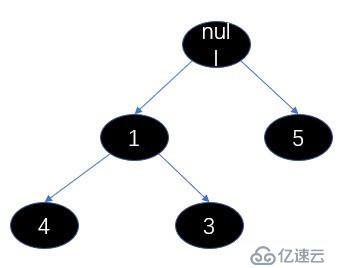
我们调用siftDownComparable 方法调整最小堆,我们看下参数,此时的k是0,x是3,array就是这个数组,n就是4,key就是3,然后算half(half可以理解为堆中父节点最大索引位置,找到这个节点说明已经没有子节点了),half = 2。
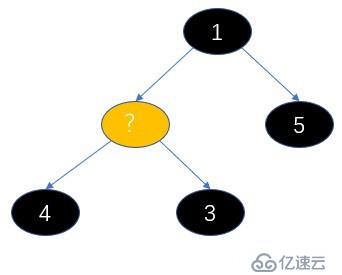
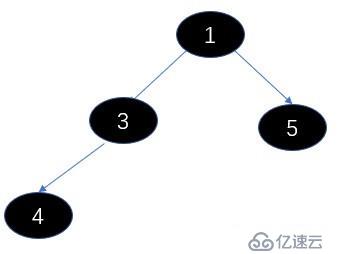
说下调整最小堆的过程,其实就是从根节点开始,重新构建父节点的过程,不过不是每个都需要重新构建,只需要构造子节点小的那边的的父节点,因为小的节点都去顶替原来的父节点了;我们弹出的是根节点,所以要从他的左右子节点找个根节点(但是要满足子节点大于父节点的规则),那么左右子节点有一个去当父节点了,它的位置也需要有节点代替,所以又从他的子节点开始找接替的节点,以此类推,直到找到最后一个父节点的位置。
使用了锁,这个是精确的值。
public int size() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return size;
} finally {
lock.unlock();
}
}PriorityBlockingQueue 是一个wujie的队列,使用put方法不会阻塞,使用时一定要注意内存溢出的问题;整个队列的出队和入队都是通过最小堆来实现的,理解最小堆是这个队列的关键;这个一个优先级的队列,适合有优先级的场景。
参考《Java 并发编程的艺术》
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





