本文的目的并不是让你对Hashtable更加了解,然后灵活运用;因为Hashtable的一个历史遗留的类,目前并不建议使用,所以本文主要和HashMap对比,感受同样功能的不同实现,知道什么是好的代码;所以在阅读本文之前最好先了解一下 HashMap,可以参考 HashMap 相关;
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable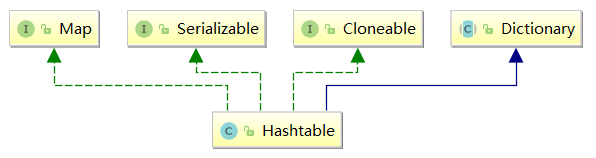
可以看到它和HashMap虽然都是哈希表,但是结构完全不一样,他是继承于Dictionary;
/**
* Maps the specified <code>key</code> to the specified
* <code>value</code> in this dictionary. Neither the key nor the
* value can be <code>null</code>.
*/abstract public V put(K key, V value);abstract public Enumeration<K> keys();abstract public Enumeration<V> elements();public interface Enumeration<E> { boolean hasMoreElements(); E nextElement();
}同AbstractMap相比功能结构基本一样,但是有两点很重要的区别:
Hashtable要求 key 和 value,都不能为 null,也就意味着这每次 put 元素的时候都需要判空,真是想想都好痛苦;
另外 keys 和 elements 返回的居然是 Enumeration,这也是一个比较古老的接口,用于枚举(一次获得一个)对象集合中的元素;但是目前大多已经被Iterator给取代了;
private transient Entry<?,?>[] table; // 哈希槽private int threshold; // 阈值private float loadFactor; // 负载系数以上三个应该就是 Map 中最重要的成员变量了,阈值和负载系数控制扩容时机,同HashMap的作用是一样的,哈希槽也是一样的,但是注意Entry<?,?>[]这里用的居然是通配符,而不是K V,也就意味着在取 entry 的时候,还需要强转类型,这也是非常神奇的地方;
public Hashtable(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1; this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}public Hashtable(int initialCapacity) { this(initialCapacity, 0.75f);
}public Hashtable() { this(11, 0.75f);
}public Hashtable(Map<? extends K, ? extends V> t) { this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}如代码所示四个构造函数,主要就是为了初始化以上三个成员变量,但是注意table的容量;熟悉HashMap的肯定知道,HashMap的容量要求是2的幂,目的是为了使用hash % length = hash & (length-1),优化哈希槽的定位;但是如上面代码所示Hashtable的容量却不是,初始容量默认11,扩容是2倍加1;这样做的优缺点有什么呢:
缺点,不能利用“与”来优化哈希槽定位;
优点,减小了哈希冲突的几率(hashmap 的容量虽然是偶数,但是对哈希做了高位与低位,以及红黑树,使得即使hash冲突十分严重,性能也能得以保证);
int index = (hash & 0x7FFFFFFF) % tab.length;哈希表中最重要的方法肯定是哈希槽定位,如上面的原因Hashtable寻址的时候并不能做优化,所以只是用的典型除留余数法,(hash & 0x7FFFFFFF)则是为了保证第一位符号位是0,也就是正数,保证最终的余数是正数;
public synchronized V get(Object key) {
Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value;
}
} return null;
}注意Hashtable的所有方法都是synchronized修饰的,所以Hashtable是线程安全的容器;
代码很简单,就是得到哈希,计算哈希桶,再一次遍历链表;但是需要注意:
int hash = key.hashCode();,这里是直接取的 key 的 hashCode,所以这里不能避免极端哈希的情况;
另外就是不能使用可变 key (所有容器都不能使用可变 key),例如:
private static class A {
String name;
public A(String name) {this.name = name;} @Override
public boolean equals(Object o) { ... } @Override
public int hashCode() { ... }
}private static void test01() {
Map<A, String> map = new Hashtable<>();
A a1 = new A("a");
A a2 = new A("a");
map.put(a1, "a");
map.put(a2, "a");
System.out.println(map.get(a1));
a1.name = "b";
System.out.println(map.get(a1));
}// 打印:
a
null
public synchronized V put(K key, V value) { // Make sure the value is not null
if (value == null) { throw new NullPointerException();
} // Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value; return old;
}
}
addEntry(hash, key, value, index); return null;
}Hashtable的put方法和HashMap相比,就显得十分清晰,先判空,在查找,找到就替换,找不到就插入新节点;但是在插入顺序(后面会讲到),红黑树性能保证等方面也就不能和HashMap相比了;另外这里取出来的Entry也是进行了类型强制转换;
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table; if (count >= threshold) { // Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
} // Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}private static class Entry<K,V> implements Map.Entry<K,V> { final int hash; final K key;
V value;
Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next;
}
...
}这里添加元素的时候首先判断是否扩容,然后添加节点;值得注意的是添加的节点是直接放在哈希槽里的(tab[index] = new Entry<>(hash, key, value, e);)大部分的 Map 实现都是将添加的节点放在链表尾部;所以Hashtable中节点的相对顺序是不断变化的;
protected void rehash() { int oldCapacity = table.length;
Entry<?,?>[] oldMap = table; // overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) // Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}扩容的时候也是,先计算新容量,在得到一个新的哈希槽,然后将节点在依次放入;同添加节点一样是将节点直接放到哈希槽中,那么在扩容完毕之后,链表的相对顺序会反向;
Hashtable的 key 和 value 都不能为 null,在使用的时候需要判空。。。。蛋疼
哈希值完全依赖 key 的 hashCode方法,所以在使用的时候,需要额外注意
Hashtable的容量可以是任意值,默认是11,不能使用“与”来优化寻址
Hashtable的节点相对位置是不断变化的;
Hashtable是线程安全的。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



