django中,如何将网站数据csv文件给用户下载?我们前面有学习过httpResponse,结合起来一起用。
1. 案例描述
我们将数据库中的信息,直接提供给客户端下载;
2. 数据库代码
from django.db import models
# Create your models here.
class Article(models.Model):
id = models.BigAutoField(primary_key=True)
title = models.CharField(max_length=100)
content = models.TextField()
price = models.FloatField(default=0)
create_time = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = 'k1_method_article'
#使用makegrations生成迁移脚本
#python manage.py makemigrations
# 将新生成的脚本文件映射到数据库中
# python manage.py migrate3. 视图代码
def csv_downloads1(request):
data = [] #最终要返回的列表数据
db_result = Article.objects.all()
for row in db_result:
source_data = [] #将数据库的每行信息生成一个列表
source_data.append(row.title)
source_data.append(row.content)
source_data.append(row.price)
data.append(source_data) #将每一行数据列表,加入到一个大列表中
response = HttpResponse(content_type='text/csv') #定义一个HttpResponse,类型是CSV
response['Content-Disposition'] = "attachment;filename=huangjaijin.csv" #定义返回的信息,附件方式及文件名称;
writer = csv.writer(response) #利用csv模块写入response
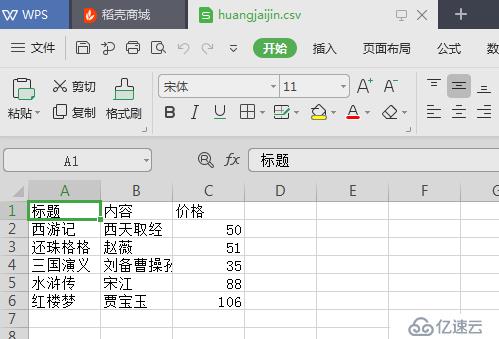
writer.writerow(['标题', '内容', '价格']) #标题行
for row in data:
writer.writerow(row) #循环写入数据库信息
return response3. URL代码
urlpatterns = [
path('csv_downloads1/', views.csv_downloads1, name='csv_downloads1'),
]4. URL代码
数据库插入数据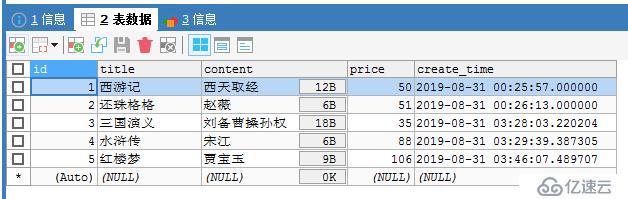
5. 访问下载
http://127.0.0.1:8000/k02_httpresponse/csv_downloads1/
def csv_downloads2(request):
data = [
['Name', 'Height'],
['Keys', '176cm'],
['HongPing', '160cm'],
['WenChao', '176cm']
]
with open('templates/abc.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f, dialect='excel')
for row in data:
writer.writerow(row)
return HttpResponse("成功")假设我们需要导出一份1000W行的数据csv文件,使用案例1的方法是生成数据,然后csv写入response(等待写入),写入完成后,网页返回下载;那么在写入过程,就有可能因为服务器超时异常。有没有边生成,边下载的方式呢?我们可以使用StreamingHttpResponse对象实现。代码如下:
(1)利用使用StreamingHttpResponse实现
def large_csv_downloads(request):
# 使用StreamingHttpResponse
response = StreamingHttpResponse(content_type='text/csv')
response['Content-Disposition'] = "attachment;filename=huangjaijin.csv"
result = ("Row {}, {} \n".format(row, row) for row in range(0, 10000000)) #生成器
'''
print(type(result)): <class 'generator'>
print(result): <generator object large_csv_downloads.<locals>.<genexpr> at 0x0000000004512660>
'''
response.streaming_content = result
return response注:生成器案例讲解
In [38]: L = [x*2 for x in range(5)]
In [39]: L
Out[39]: [0, 2, 4, 6, 8]
In [40]: G = (x*2 for x in range(5)) #区别就是[]变成()
In [41]: G
Out[41]: <generator object <genexpr> at 0x7fad5268d910>
In [42]: for num in G:
...: print(num)
...:
0
2
4
6
8下载地址:http://127.0.0.1:8000/k02_httpresponse/large_csv_downloads
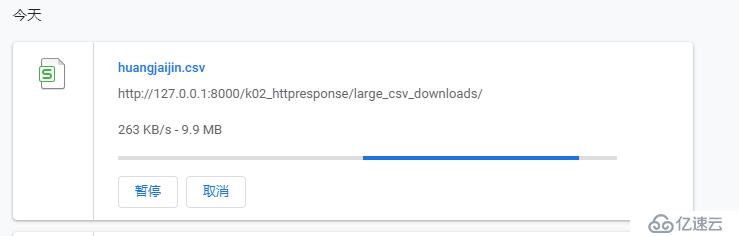
我们可以看到,在打开网页在瞬间就开始下载,因为是边生成数据,边下载。
(2)普通csv和HttpResponse
这里的案例就是,我们使用普通的方式下载同样的打的文件,试试。
def large_csv_downloads(request):
#使用HttpResponse
response = HttpResponse(content_type='text/csv')
response['Content-Disposition'] = "attachment;filename=huangjaijin.csv"
writer = csv.writer(response)
for row in range(0, 10000000):
writer.writerow(['Row {}'.format(row), ''.format(row)])
return response
我们就可以发现,当我们打开网页的时候,就是一只链接等待
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



