目录
阶段一:Elasticsearch概念与架构
Elasticsearch的功能
Elasticsearch-Linux安装
Elasticsearch核心概念
Elasticsearch基础分布式架构
Elasticsearch的shard和replica机制、单node环境shard分配
横向扩容过程,如何超出扩容极限,以及如何提升容错性
阶段二:ElasticSearch分布式文件架构
7.分布式文件系统-document各种操作内部原理
阶段一:Elasticsearch概念与架构
Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
(2)全文检索,结构化检索,数据分析
(3)对海量数据进行近实时的处理
Elasticsearch-Linux安装
把程序放到后台运行: nohup ./your_command &
1.下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
2.解压授权(es 规定 root 用户不能启动 es,所以需要使用一个其他用户来启动 es)
useradd esuser
passwd esuser
cd /home/esuser/
tar zxvf elasticsearch-6.0.0.tar.gz
chown -R esuser:esuser elasticsearch-6.0.0
3.启动(切换到普通用户)
cd elasticsearch-6.0.0
sh ./bin/elasticsearch
(如果报错jdk版本问题,可以修改系统环境变量;但是本机环境变量使用系统自带的jdk1.7,由于其他业务需要,不能改变,可以在bin/elasticsearch-env下配置临时变量
JAVA_HOME=/usr/java/jdk1.8.0_144)
4.访问测试
curl localhost:9200
注:这里不能直接使用IP,需要配置(在配置前先停了线程),下面是开始配置。
5.停止es
cd elasticsearch-6.0.0/bin
ps -ef |grep elasticsearch
kill -9 上面查出来的进程号(第一行用户名后第一个)
6.修改
config/elasticsearch.yml文件里面的:network.host: 0.0.0.0
7.重启
sh elasticsearch (-d后台启动)
发现报错:
前三个错误:
ERROR: [4] bootstrap checks failed
#文件句柄太少,至少要65536
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
#最大线程数太少,至少2048个(经典的2048游戏)
[2]: max number of threads [1024] for user [king] is too low, increase to at least [2048]
#虚拟内存太少,至少262144
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改:
1.更改文件句柄数
[root@localhost ~]# vi /etc/security/limits.conf
在文件中加入如下内容(*表示任何用户)
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
2.增加线程数
[root@localhost ~]# vi /etc/security/limits.d/90-nproc.conf
将其中的
* soft nproc 1024
1
修改为
* soft nproc 2048
3.增加虚拟内存
[root@localhost ~]# vim /etc/sysctl.conf
在其中添加
vm.max_map_count=655360
使配置生效(完成后最好换个客户端重启):
sysctl -p
第四个错误:
[4]system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
原因:
这是在因为Centos6不支持SecComp,而ES5.2.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
解决:
在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
8.再次重启(最好换另外一个客户端)
[esuser@localhost bin]$ ./elasticsearch
[root@localhost ~]# curl xxx.xx.30.27:9200
9.配置防火墙
这个时候可以在本机通过本机ip访问,还没有开防火墙,外网是不可以访问的。
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
我是临时关闭防火墙。
Elasticsearch-Windows安装
1、安装JDK,至少1.8.0_73以上版本,java -version
2、下载和解压缩Elasticsearch安装包,目录结构
3、启动Elasticsearch:bin\elasticsearch.bat,es本身特点之一就是开箱即用,如果是中小型应用,数据量少,操作不是很复杂,直接启动就可以用了
4、检查ES是否启动成功:http://localhost:9200/?pretty
name: node名称
cluster_name: 集群名称(默认的集群名称就是elasticsearch)
version.number: 5.2.0,es版本号
{
"name" : "4onsTYV",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "nKZ9VK_vQdSQ1J0Dx9gx1Q",
"version" : {
"number" : "5.2.0",
"build_hash" : "24e05b9",
"build_date" : "2017-01-24T19:52:35.800Z",
"build_snapshot" : false,
"lucene_version" : "6.4.0"
},
"tagline" : "You Know, for Search"
}
5、修改集群名称:elasticsearch.yml
6、下载和解压缩Kibana安装包,使用里面的开发界面,去操作elasticsearch,作为我们学习es知识点的一个主要的界面入口
7、启动Kibana:bin\kibana.bat
8、进入Dev Tools界面
9、GET _cluster/health
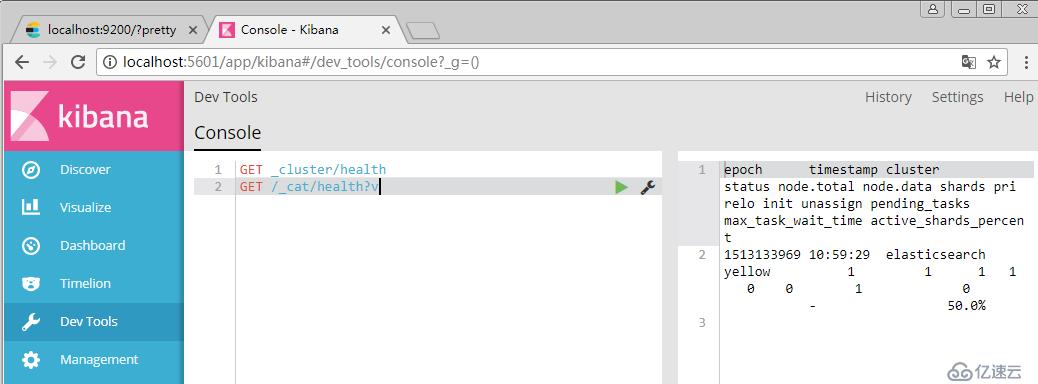
Elasticsearch核心概念
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(6)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
(7)shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
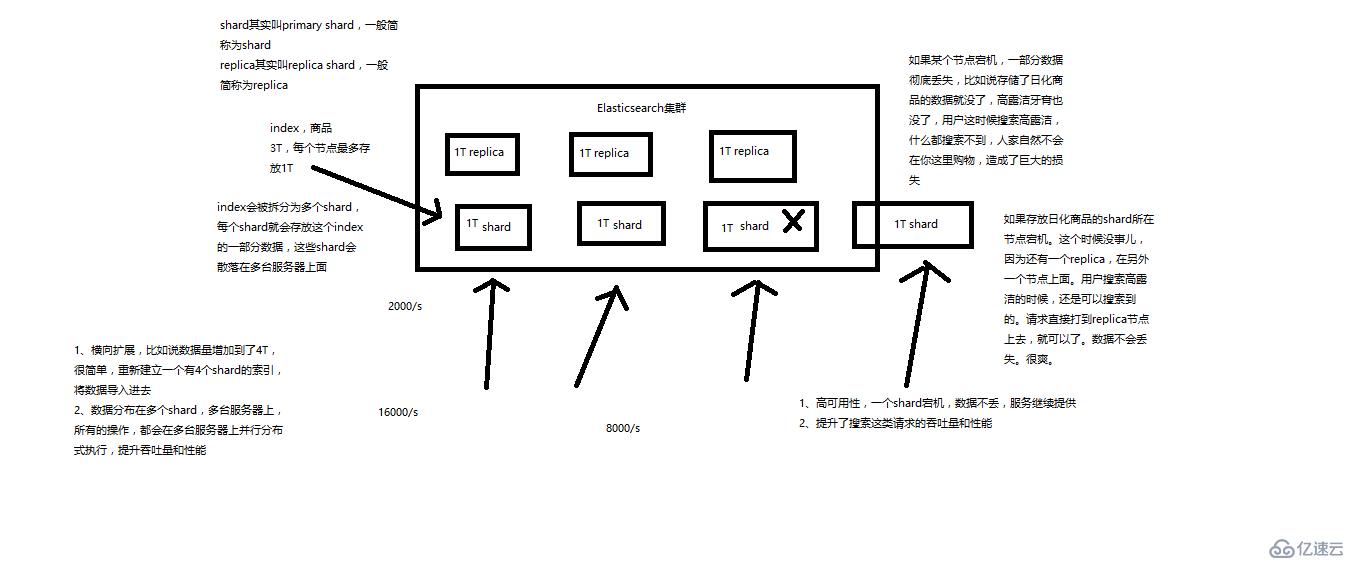
Elasticsearch基础分布式架构
1、Elasticsearch对复杂分布式机制的透明隐藏特性
2、Elasticsearch的垂直扩容与水平扩容
3、增减或减少节点时的数据rebalance
4、master节点
5、节点对等的分布式架构
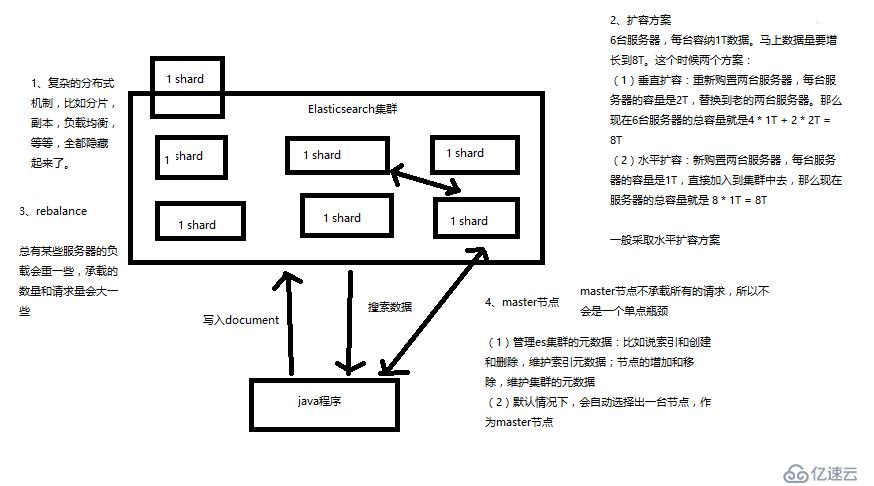
Elasticsearch的shard和replica机制、单node环境shard分配
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
------------------------------------------------------------------------------------------------
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
(1)primary&replica自动负载均衡,6个shard,3 primary,3 replica
(2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
(3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
(4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
(5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳0台机器宕机
(6)这里的这些知识点,你综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失
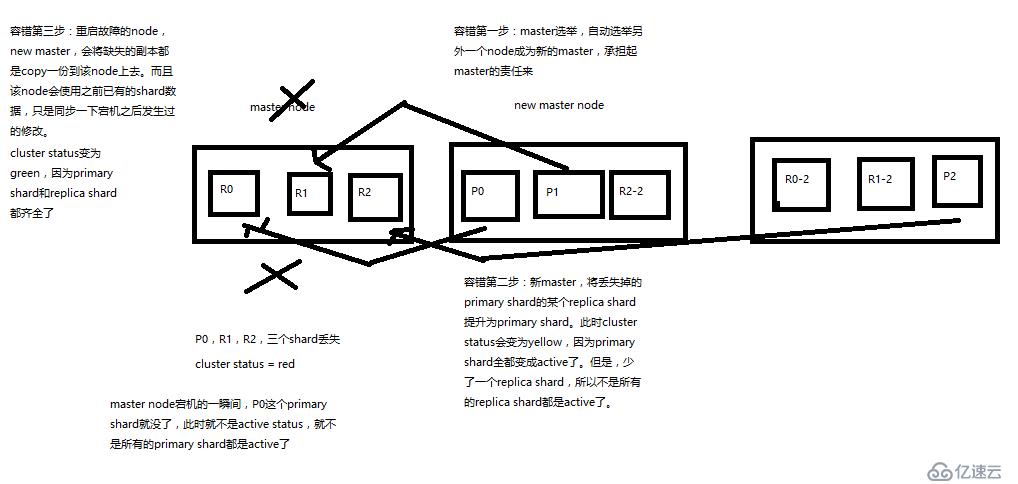
(1)9 shard,3 node
(2)master node宕机,自动master选举,red
(3)replica容错:新master将replica提升为primary shard,yellow
(4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green
阶段二:ElasticSearch分布式文件架构
1、_index元数据
2、_type元数据
3、_id元数据
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"test_content": "test test"
}
}
1.1、_index元数据
(1)代表一个document存放在哪个index中
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
1.2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
1.3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document
(2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id
1、手动指定document id
(1)根据应用情况来说,是否满足手动指定document id的前提:
一般来说,是从某些其他的系统中,导入一些数据到es时,会采取这种方式,就是使用系统中已有数据的唯一标识,作为es中document的id。举个例子,比如说,我们现在在开发一个电商网站,做搜索功能,或者是OA系统,做员工检索功能。这个时候,数据首先会在网站系统或者IT系统内部的数据库中,会先有一份,此时就肯定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到es中,此时就比较适合采用数据在数据库中已有的primary key。
如果说,我们是在做一个系统,这个系统主要的数据存储就是es一种,也就是说,数据产生出来以后,可能就没有id,直接就放es一个存储,那么这个时候,可能就不太适合说手动指定document id的形式了,因为你也不知道id应该是什么,此时可以采取下面要讲解的让es自动生成id的方式。
(2)put /index/type/id
PUT /test_index/test_type/2
{
"test_content": "my test"
}
2、自动生成document id
(1)post /index/type
POST /test_index/test_type
{
"test_content": "my test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
(2)自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
2.1、_source元数据
put /test_index/test_type/1
{
"test_field1": "test field1",
"test_field2": "test field2"
}
get /test_index/test_type/1
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
}
_source元数据:就是说,我们在创建一个document的时候,使用的那个放在request body中的json串,默认情况下,在get的时候,会原封不动的给我们返回回来。
2.2、定制返回结果
定制返回的结果,指定_source中,返回哪些field
GET /test_index/test_type/1?_source=test_field1,test_field2
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field2": "test field2"
}
}
3.1、document的全量替换
(1)语法与创建文档是一样的,如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换document的json串内容
(2)document是不可变的,如果要修改document的内容,第一种方式就是全量替换,直接对document重新建立索引,替换里面所有的内容
(3)es会将老的document标记为deleted,然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除标记为deleted的document
3.2、document的强制创建
(1)创建文档与全量替换的语法是一样的,有时我们只是想新建文档,不想替换文档,如果强制进行创建呢?
(2)PUT /index/type/id?op_type=create,PUT /index/type/id/_create
3.3、document的删除
(1)DELETE /index/type/id
(2)不会理解物理删除,只会将其标记为deleted,当数据越来越多的时候,在后台自动删除
4.1、批量查询的好处
就是一条一条的查询,比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的
如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的性能开销缩减100倍
4.2、mget的语法
(1)一条一条的查询
GET /test_index/test_type/1
GET /test_index/test_type/2
(2)mget批量查询
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 2
}
]
}
{
"docs": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"_version": 1,
"found": true,
"_source": {
"test_content": "my test"
}
}
]
}
(3)如果查询的document是一个index下的不同type种的话
GET /test_index/_mget
{
"docs" : [
{
"_type" : "test_type",
"_id" : 1
},
{
"_type" : "test_type",
"_id" : 2
}
]
}
(4)如果查询的数据都在同一个index下的同一个type下,最简单了
GET /test_index/test_type/_mget
{
"ids": [1, 2]
}4.3、mget的重要性
可以说mget是很重要的,一般来说,在进行查询的时候,如果一次性要查询多条数据的话,那么一定要用batch批量操作的api
尽可能减少网络开销次数,可能可以将性能提升数倍,甚至数十倍,非常非常之重要
5.1、bulk语法
POST /_bulk
{ "delete": { "_index": "test_index", "_type": "test_type", "_id": "3" }}
{ "create": { "_index": "test_index", "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_index": "test_index", "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_index": "test_index", "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }每一个操作要两个json串,语法如下:
{"action": {"metadata"}}
{"data"}
举例,比如你现在要创建一个文档,放bulk里面,看起来会是这样子的:
{"index": {"_index": "test_index", "_type", "test_type", "_id": "1"}}
{"test_field1": "test1", "test_field2": "test2"}
有哪些类型的操作可以执行呢?
(1)delete:删除一个文档,只要1个json串就可以了
(2)create:PUT /index/type/id/_create,强制创建
(3)index:普通的put操作,可以是创建文档,也可以是全量替换文档
(4)update:执行的partial update操作
bulk api对json的语法,有严格的要求,每个json串不能换行,只能放一行,同时一个json串和一个json串之间,必须有一个换行
bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志
POST /test_index/_bulk
{ "delete": { "_type": "test_type", "_id": "3" }}
{ "create": { "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_type": "test_type" }}
{ "test_field": "auto-generate id test" }
{ "index": { "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
POST /test_index/test_type/_bulk
{ "delete": { "_id": "3" }}
{ "create": { "_id": "12" }}
{ "test_field": "test12" }
{ "index": { }}
{ "test_field": "auto-generate id test" }
{ "index": { "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }5.2、bulk size最佳大小
bulk request会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的bulk size。一般从1000~5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在5~15MB之间
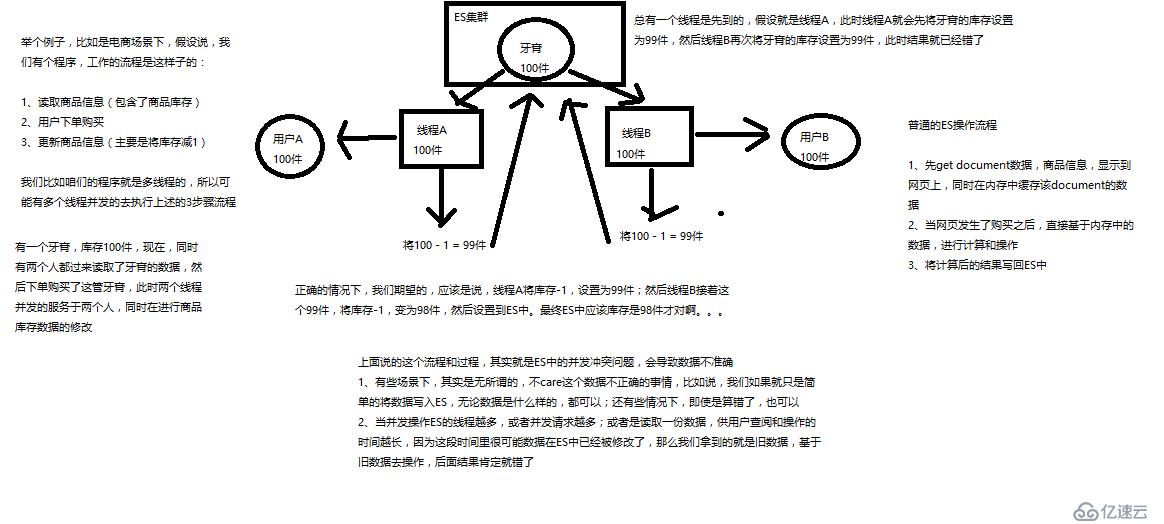

(1)_version元数据
PUT /test_index/test_type/6
{
"test_field": "test test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
第一次创建一个document的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1
{
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}会发现,在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1
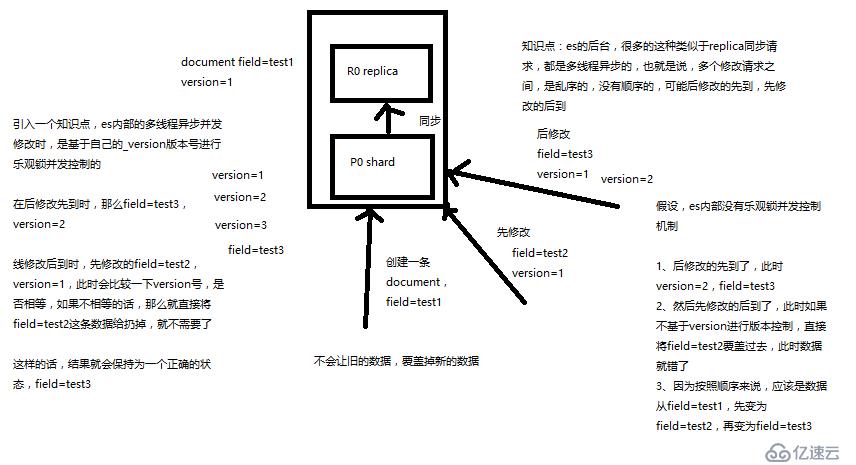
es提供了一个feature,就是说,你可以不用它提供的内部_version版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。举个列子,加入你的数据在mysql里也有一份,然后你的应用系统本身就维护了一个版本号,无论是什么自己生成的,程序控制的。这个时候,你进行乐观锁并发控制的时候,可能并不是想要用es内部的_version来进行控制,而是用你自己维护的那个version来进行控制。
什么是partial update?
PUT /index/type/id,创建文档&替换文档,就是一样的语法
一般对应到应用程序中,每次的执行流程基本是这样的:
(1)应用程序先发起一个get请求,获取到document,展示到前台界面,供用户查看和修改
(2)用户在前台界面修改数据,发送到后台
(3)后台代码,会将用户修改的数据在内存中进行执行,然后封装好修改后的全量数据
(4)然后发送PUT请求,到es中,进行全量替换
(5)es将老的document标记为deleted,然后重新创建一个新的document
partial update
post /index/type/id/_update
{
"doc": {
"要修改的少数几个field即可,不需要全量的数据"
}
}
看起来,好像就比较方便了,每次就传递少数几个发生修改的field即可,不需要将全量的document数据发送过去
图解partial update实现原理以及其优点
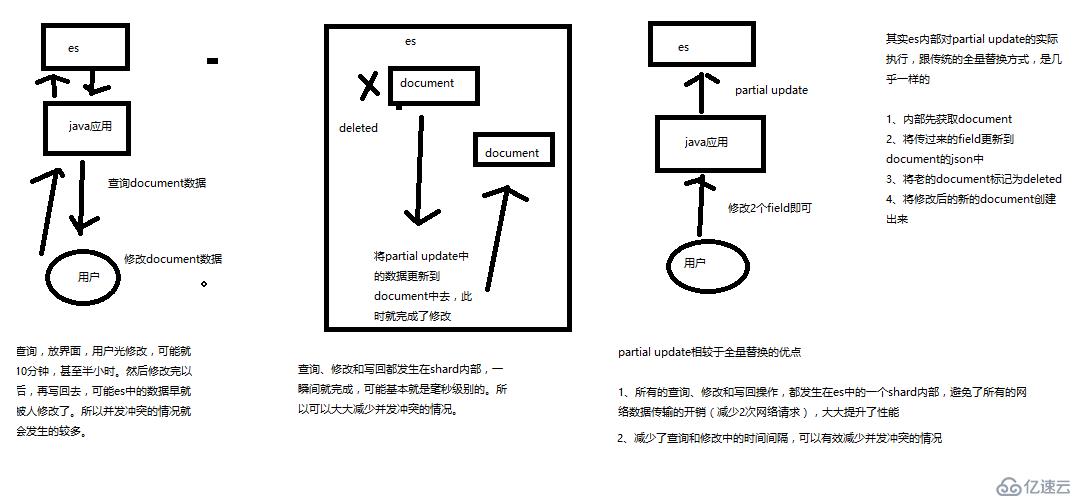
Partial update相比全量请求的优缺点:
所有的查询、修改和写回操作,都发生在es中的一个shard内部,避免了所有的网络数据传输的开销(如果全量请求的话,会从es中找一批数据放回Java应用中,然后Java应用修改,传回es中修改请求,这就是两次网络开销,而partial update只在一个shard中操作所有)
7.1.document数据路由原理(shard为什么不可变)
(1)document路由到shard上是什么意思?
(2)路由算法:shard = hash(routing) % number_of_primary_shards
举个例子,一个index有3个primary shard,P0,P1,P2
每次增删改查一个document的时候,都会带过来一个routing number,默认就是这个document的_id(可能是手动指定,也可能是自动生成)
routing = _id,假设_id=1
会将这个routing值,传入一个hash函数中,产出一个routing值的hash值,hash(routing) = 21
然后将hash函数产出的值对这个index的primary shard的数量求余数,21 % 3 = 0
就决定了,这个document就放在P0上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的
无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
(3)_id or custom routing value
默认的routing就是_id
也可以在发送请求的时候,手动指定一个routing value,比如说put /index/type/id?routing=user_id
手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的
(4)primary shard数量不可变的谜底
7.2.es增删改内部原理
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
7.3.写一致性原理以及quorum机制
(1)consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如说put /index/type/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么?
put /index/type/id?consistency=quorum
one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
(2)quorum机制,写之前必须确保大多数shard都可用,int( (primary + number_of_replicas) / 2 ) + 1,当number_of_replicas>1时才生效
quroum = int( (primary + number_of_replicas) / 2 ) + 1
举个例子,3个primary shard,number_of_replicas=1,总共有3 + 3 * 1 = 6个shard
quorum = int( (3 + 1) / 2 ) + 1 = 3
所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
(3)如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
3个primary shard,replica=1,要求至少3个shard是active,3个shard按照之前学习的shard&replica机制,必须在不同的节点上,如果说只有2台机器的话,是不是有可能出现说,3个shard都没法分配齐全,此时就可能会出现写操作无法执行的情况
es提供了一种特殊的处理场景,就是说当number_of_replicas>1时才生效,因为假如说,你就一个primary shard,replica=1,此时就2个shard
(1 + 1 / 2) + 1 = 2,要求必须有2个shard是活跃的,但是可能就1个node,此时就1个shard是活跃的,如果你不特殊处理的话,导致我们的单节点集群就无法工作
(4)quorum不齐全时,wait,默认1分钟,timeout,100,30s
等待期间,期望活跃的shard数量可以增加,最后实在不行,就会timeout
我们其实可以在写操作的时候,加一个timeout参数,比如说put /index/type/id?timeout=30,这个就是说自己去设定quorum不齐全的时候,es的timeout时长,可以缩短,也可以增长
7.4.es查询内部原理
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3、接收请求的node返回document给coordinate node
4、coordinate node返回document给客户端
5、特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了
7.5.json格式
bulk api奇特的json格式
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
[{
"action": {
},
"data": {
}
}]
1、bulk中的每个操作都可能要转发到不同的node的shard去执行
2、如果采用比较良好的json数组格式
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理
(1)将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组
(4)将这个请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
3、耗费更多内存,更多的jvm gc开销
我们之前提到过bulk size最佳大小的那个问题,一般建议说在几千条那样,然后大小在10MB左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多
4、现在的奇特格式
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
(1)不用将其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的json,读取meta,进行document路由
(3)直接将对应的json发送到node上去
5、最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,尽可能地保证性能
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





