有的小伙伴会发现在数据统计报表的时候会经常在最后对列进行一个汇总,那么在oracle中是那些函数来实现汇总的呢?今天就来讲一下rollup函数和cube函数的区分。
首先,创建一张表tmp1,数据如下:
那么,我们先看一下cube汇总出来的数据是什么样子的吧?
select t_class,t_address,(t_number) t_number from tmp1 group by cube(t_class,t_address);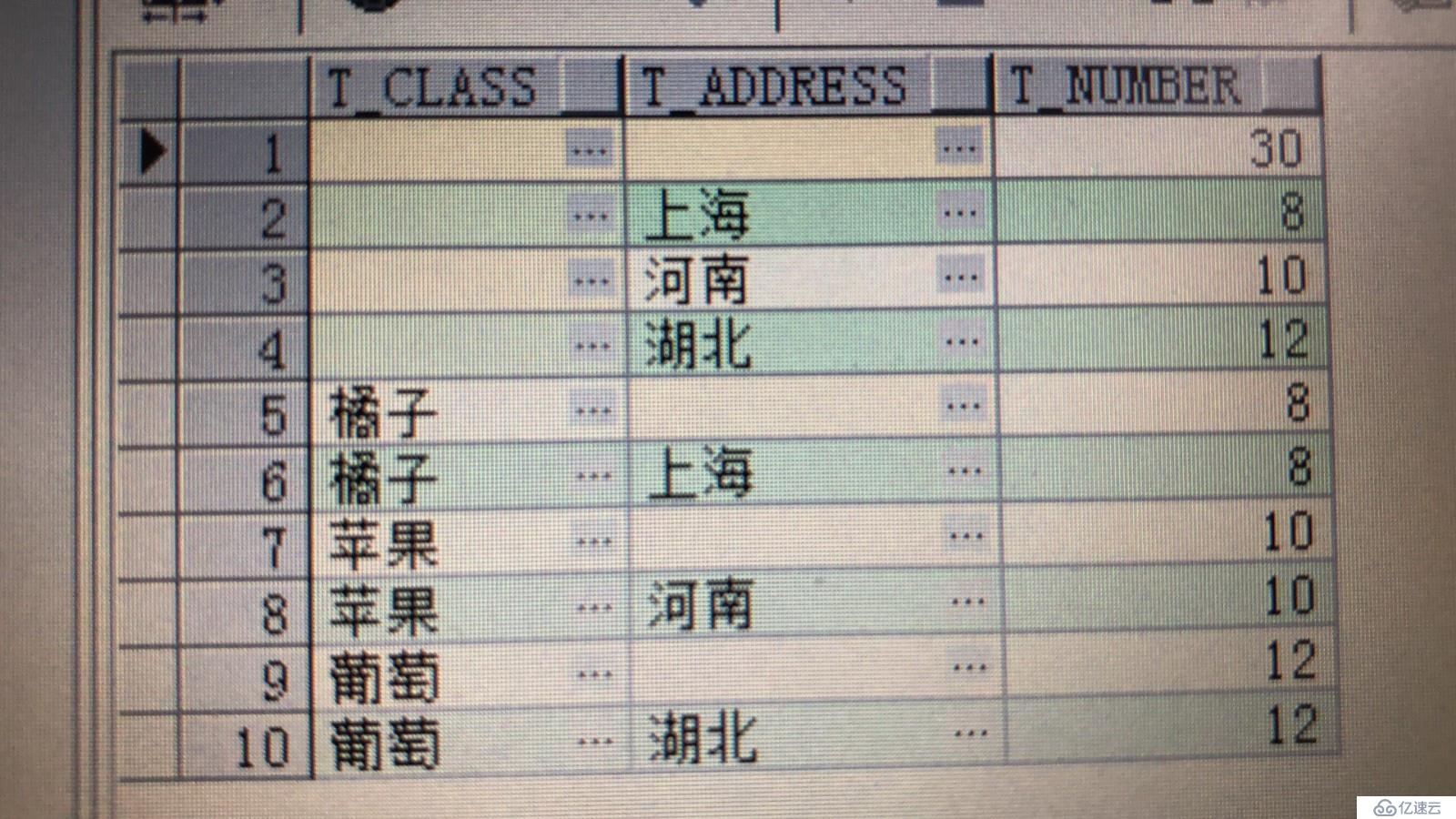
有的小伙伴可能已经发现了,cube函数汇总的数据相当于把所有的可能性的数据汇总了出来。没错,其实这条sql语句相当于以下的union all语句:
select null,null,sum(t_number) t_number from tmp1
union all
select null,t_address,sum(t_number) t_number from tmp1 group by t_address
union all
select t_class,null,sum(t_number) t_number from tmp1 group by t_class
union all
select t_class,t_address,sum(t_number) t_number from tmp1 group by t_class,t_address;
那么,现在我们看一下rollup汇总出来的数据是什么样子的吧?
select t_class,t_address,(t_number) t_number from tmp1 group by rollup(t_class,t_address);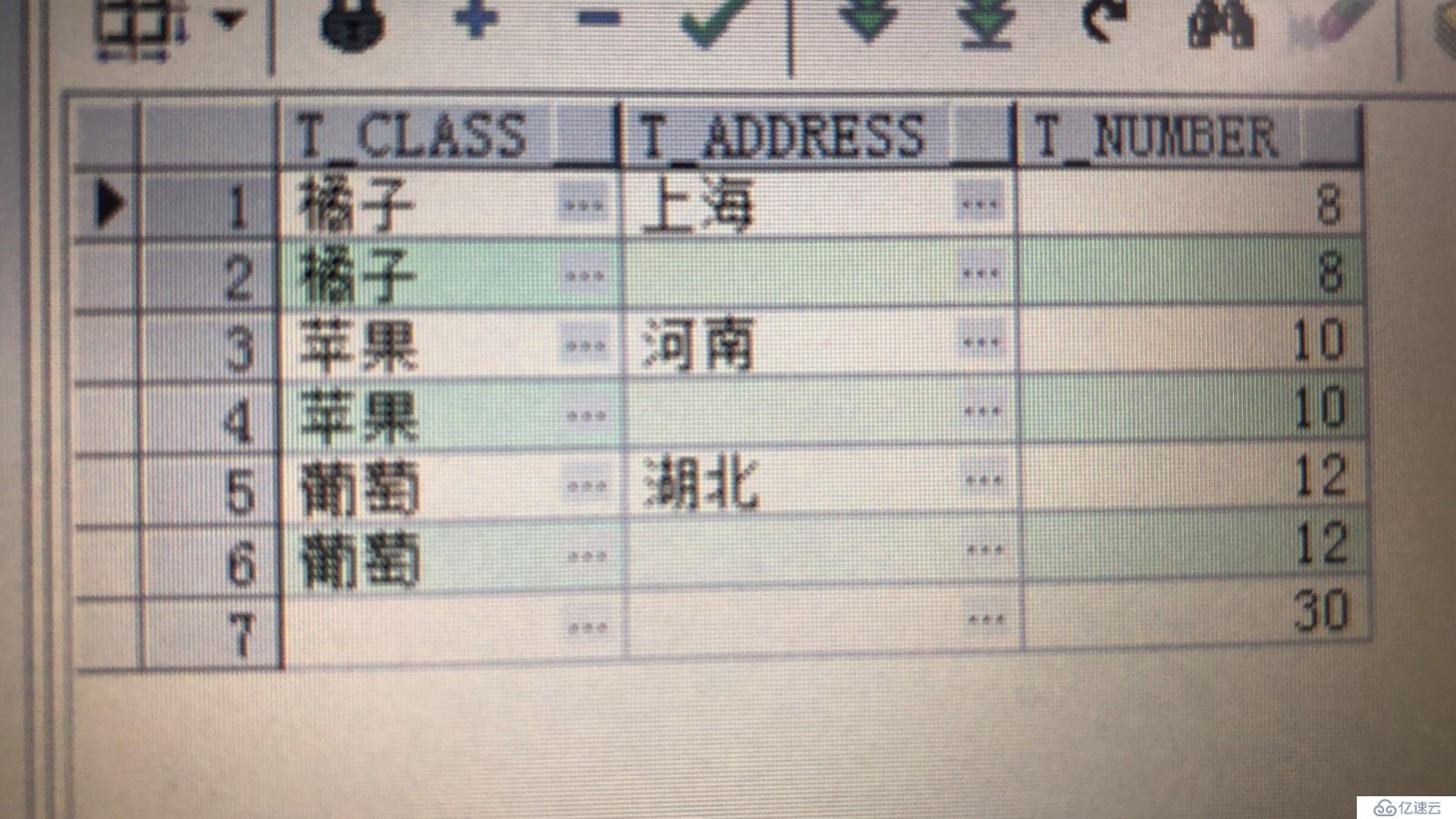
有的小伙伴可能已经发现了,rollup函数汇总的数据也可以用union all语句来实现:
select null,null,sum(t_number) t_number from tmp1
union all
select t_class,null,sum(t_number) t_number from tmp1 group by t_class
union all
select t_class,t_address,sum(t_number) t_number from tmp1 group by t_class,t_address;
**总结:**
如果使用group by rollup(A,B,C),首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。roll up的意思是“卷起”,这也可以帮助我们理解group by rollup就是对选择的列从右到左以一次少一列的方式进行grouping直到所有列都去掉后的grouping(也就是全表grouping),对于n个参数的rollup,有n+1次的grouping。
cube的意思是立方,对cube的每个参数,都可以理解为取值为参与grouping和不参与grouping两个值的一个维度,然后所有维度取值组合的集合就是grouping的集合,对于n个参数的cube,有2^n次的grouping。如果使用group by cube(A,B,C),,则首先会对(A、B、C)进行GROUP BY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行GROUP BY操作,一共是2^3=8次grouping。
另外,当实际表中也存在null值时,如何区分cube和rollup运算符所生成的null值呢?这时我们可以用grouping函数来区分,这里我们就举一个简单的例子来区分t_class列的null值,sql如下:
select t_class,t_address,(t_number) t_number,grouping(t_class) from tmp1group by rollup(t_class,t_address);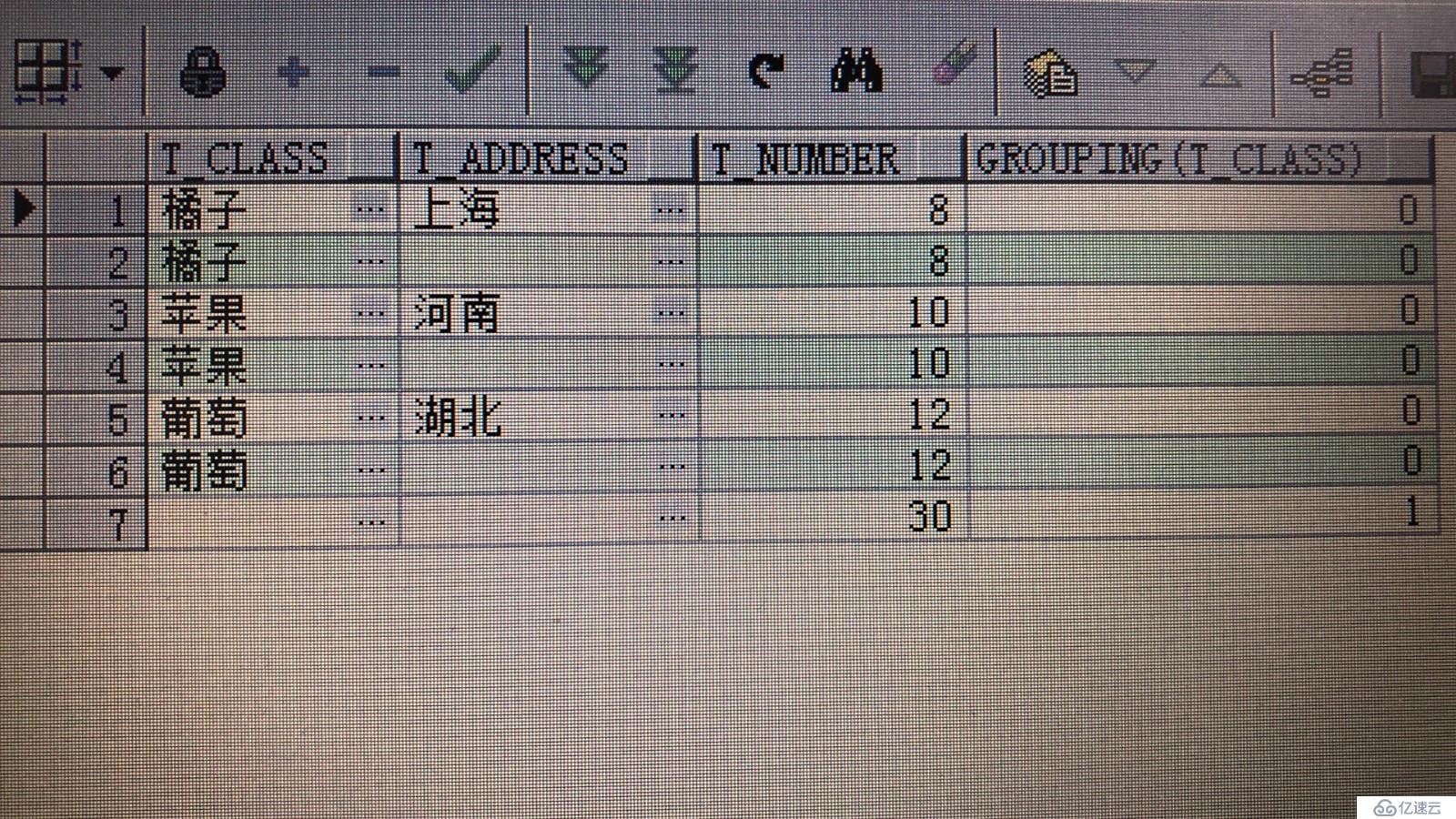
从图中可以看到grouping(t_class)列中有0和1两个数字,其中1表示由rollup运算符造成的null值,其余null值为事实数据的空值。事实上grouping是一个聚合函数,它产生了一个附加的列,当用cube或rollup运算符添加行时,附加的列值为1;当所添加的行不是由cube或rollup产生时,附加列值为0.
希望对大家能有所帮助!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





