MySQL的分库分表有两种方式:垂直拆分和水平拆分。
垂直拆分:垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表。(垂直拆分用于分布式场景)
水平拆分:解决单表大数据量的问题,水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。例如:在大型电商系统中,每天的会员人数不断的增加。达到一定瓶颈后如何优化查询。通过将表数据水平分割成不同的表来实现优化。(实现规则:hash、时间、不同的维度)
通俗理解:水平拆分行,行数据拆分到不同表中, 垂直拆分列,表数据拆分到不同表中。
分表原理:取模拆分(一致性hash),可以将数据分配的比较均匀。
这里我们以3张表为例:
案例:首先我创建三张表 user0 / user1 /user2 , 然后我再创建 uuid表,该表的作用就是提供自增的id。
代码实现:
-- 建表语句
create table user0(
id int unsigned primary key ,
name varchar(22) not null default '',
pwd varchar(22) not null default '')
engine=myisam charset utf8;
create table user1(
id int unsigned primary key ,
name varchar(22) not null default '',
pwd varchar(22) not null default '')
engine=myisam charset utf8;
create table user2(
id int unsigned primary key ,
name varchar(22) not null default '',
pwd varchar(22) not null default '')
engine=myisam charset utf8;
create table uuid(
id int unsigned primary key auto_increment)engine=myisam charset utf8;//分表逻辑
@Service
public class UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public String regit(String name, String pwd) {
// 1.先获取到 自定增长ID
String idInsertSQL = "INSERT INTO uuid VALUES (NULL);";
jdbcTemplate.update(idInsertSQL);
Long insertId = jdbcTemplate.queryForObject("select last_insert_id()", Long.class);
// 2.判断存储表名称
String tableName = "user" + insertId % 3;
// 3.注册数据
String insertUserSql = "INSERT INTO " + tableName + " VALUES ('" + insertId + "','" + name + "','" + pwd
+ "');";
System.out.println("insertUserSql:" + insertUserSql);
jdbcTemplate.update(insertUserSql);
return "success";
}
public String get(Long id) {
String tableName = "user" + id % 3;
String sql = "select name from " + tableName + " where id="+id;
System.out.println("SQL:" + sql);
String name = jdbcTemplate.queryForObject(sql, String.class);
return name;
}
}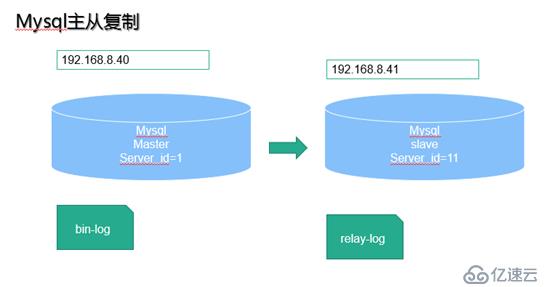
上图中192.168.8.40是主节点(MYSQL-A),192.168.8.41是从节点(MYSQL-B)。
影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的3306端口,通过网络发给MYSQL-B。 MYSQL-B收到后,写入本地日志系统B,然后一条条的将数据库事件在数据库中完成。那么,MYSQL-A的变化,MYSQL-B也会变化,这样就是所谓的MYSQL的复制,即MYSQL replication。
MYSQL的日志类型中的二进制日志,也就是专门用来保存修改数据库表的所有动作,即bin log。【注意MYSQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全】
日志系统B,并不是二进制日志,由于它是从MYSQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
主从复制,所产生的问题:
- 主服务器如何实现负载均衡、高可用。
- 如何保证数据不丢失。
- 如何保证主从数据一致性。
简介:在数据库集群架构中,让主库负责处理事务性查询,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。当然,主数据库另外一个功能就是负责将事务性查询导致的数据变更同步到从库中,也就是写操作。
写分离的好处:分摊服务器压力,提高机器的系统处理效率。增加冗余,提高服务器性能,当一台服务器宕机后可以从另一个库以最快的方式恢复服务。
环境介绍:
① 安装MySQL
#这里小编是通过rpm&&yum安装的MySQL
#下载安装包
$wget http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm
#安装
$rpm -ivh mysql57-community-release-el7-8.noarch.rpm
$yum install mysql-server
#启动MySQL服务
$systemctl start mysqld
#查看root初始密码
$grep 'temporary password' /var/log/mysqld.log
#重设root密码
$mysql_secure_installation
注意:
这里配置N,不然的话无法使用root登录MySQL。
#修改root密码并设置可以远程访问:
mysql> use mysql;
mysql> update user set authentication_string=password("123456") where user="root";
mysql> flush privileges;
mysql> select 'host','user' from user where user='root';
mysql> UPDATE user SET grant_priv = 'Y' WHERE user = 'root';
mysql> select host,user from user;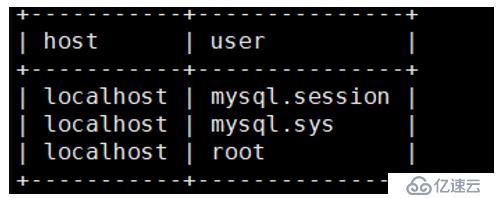
mysql> update user set host = '%' where user = 'root';
mysql> select host,user from user;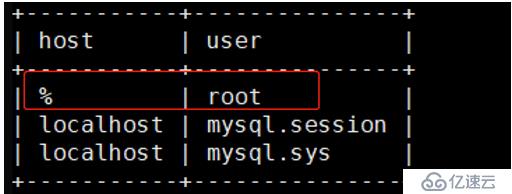
mysql> flush privileges;
mysql> quit
#测试是否配置成功
$mysql -uroot -p -h 192.168.xxx.xxx
② 创建数据库
分别在master和slave中创建一个数据库:
mysql> create database test;注意:这里从数据库中一定要存在于主数据库中同步的库,否则在同步时会报错:
③ 修改master中的配置
$vim /etc/my.cnf
#master 加入
server-id=1
log-bin=mysql-bin
log-slave-updates=1
#需要同步的数据库
binlog-do-db=test
#被忽略的数据
binlog-ignore-db=mysql④ 在master中创建salve同步账号
mysql> grant replication slave on *.* to 'user1'@'192.168.130.133' identified by 'Zy.123456';
mysql> flush privileges;⑤ 重启master并查看日志情况
$systemctl restart mysqld
mysql> show master status;
⑥ 修改slave中MySQL的配置
#slave 加入
server-id=2
log-bin= mysql-bin
relay-log= mysql-relay-bin
read-only=1
log-slave-updates=1
#要同步的数据库,不写本行表示同步所有数据库
replicate-do-db=test⑦ 重启slave并验证是否可以连接master
$systemctl restart mysqld
$mysql -uuser1 -p123456 -h 192.168.130.133
mysql> show grants for user1@192.168.130.133;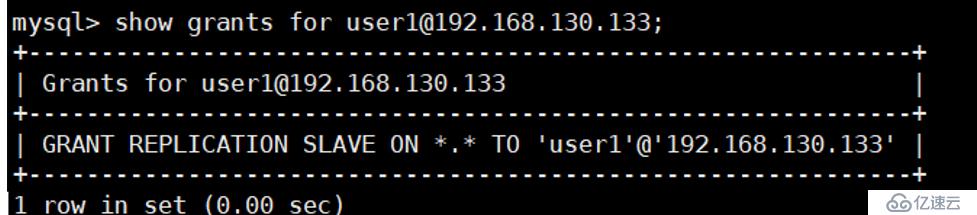
⑧ 设置slave复制 并启动slave
mysql>change master to master_host='192.168.130.134',master_user='user1',master_password='Zy.123456';
-- 启动slave
mysql> start slave;
mysql> SHOW SLAVE STATUS;
主要查看Slave_IO_Running和Slave_SQL_Running 两列是否都为YES。
⑨测试主从服务是否同步
在主服务器中执行:
mysql> use test;
mysql> create table test(id int,name char(10));
mysql> insert into test values(1,'zaq');
mysql> insert into test values(1,'xsw');
mysql> select * from test;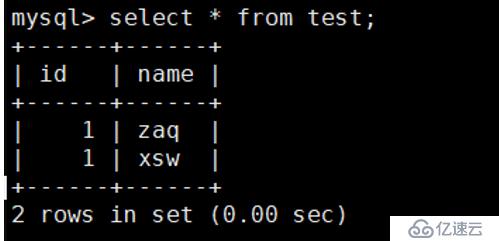
此时查看从服务器: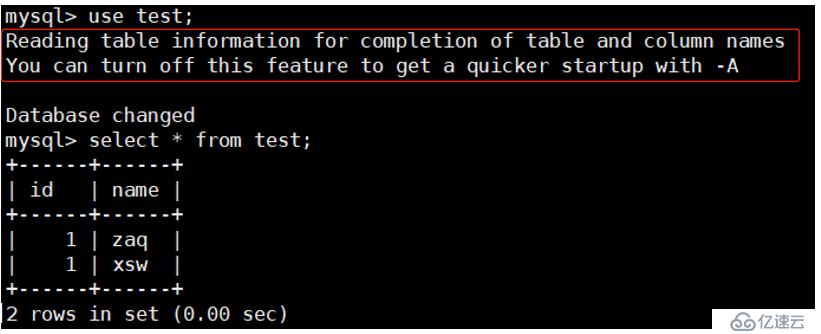
到此主从复制就配置完成!
主库中已有数据的解决方案:
- 方案一:选择忽略主库之前的数据,不做处理。这种方案只适用于不重要的可有可无的数据,并且业务上能够容忍主从库数据不一致的场景。
- 方案二:对主库的数据进行备份,然后将主数据库中导出的数据导入到从数据库,然后再开启主从复制,以此来保证主从数据库数据一致。
这里小编介绍如何使用方案二进行数据同步。
① 备份数据
假设这里我们有一个库:weibo并且数据库中有相应的数据: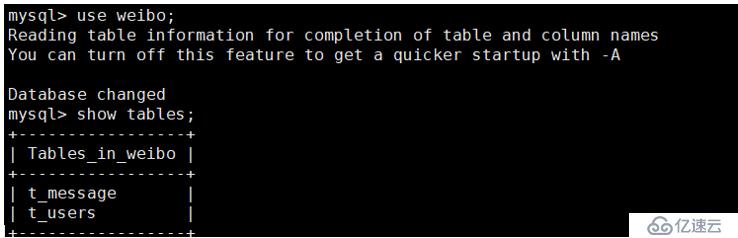
#锁定主表
mysql> flush tables with read lock; #保证表只能做读操作#查看此时主数据库状态,并记录bin-file和pos
mysql>show master status;
#在/etc/my.cnf中加入:
[mysqldump]
user = root
password = rootpassword#重启服务:
[root@zzy ~]# systemctl restart mysqld#备份数据库
mysqldump weibo > weibo_back.sql
然后将备份数据文件传入从机器中,
在mysql中执行:source /path/ weibo_back.sql此时主从数据库的数据已经同步!
② 修改配置
这里主从服务器的配置同上一节说道的相同。
③ 启动slave
mysql>stop slave;
mysql>reset slave; change master to
mysql>master_host='192.168.130.134',
>master_user='user2',
>master_password='Zy.123456',
>master_log_file='mysql-bin.000004',
>master_log_pos=154;
mysql>start slave;
mysql>SHOW SLAVE STATUS;注意:这里的master_log_file和master_log_pos一定要和从主数据库中通过“show master status”命令查到的相同。
④ 解锁主数据库
mysql>unlock tables;然后我们就可以测试,在主数据库中插入一条记录,看看从数据库是否有数据同步。
mycati一个开源的分布式数据库系统,但是因为数据库一般都有自己的数据库引擎,而mycat没有属于自己独有的数据库引擎,所以严格意义上来讲并不能算是一个完整的数据库系统,只能是一个在应用和数据库之间的服务中间件。
在mycat中间件出现之间,MySQL主从复制集群,如果要实现读写分离,一般是在程序段实现,这样就带来了一个问题,即数据段和程序的耦合度太高,如果数据库的地址发生了改变,那么我的程序也要进行相应的修改,如果数据库不小心挂掉了,则同时也意味着程序的不可用,而对于很多应用来说,并不能接受;引入Mycat中间件能很好地对程序和数据库进行解耦,这样,程序只需关注数据库中间件的地址,而无需知晓底层数据库是如何提供服务的,大量的通用数据聚合、事务、数据源切换等工作都由中间件来处理;Mycat中间件的原理是对数据进行分片处理,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成完成的数据库存储,有点类似磁盘阵列中的RAID0。
通过使用mycat可以很轻松的实现数据库的读写分离,并且由于其特点,不仅实现负载均衡,而且提高了集群的安全性。
注意,这里mycat只是做了负载均衡,主从复制并没有做,所以,如果想让MySQL集群可以读写分离,就需要使用mycat并沿用原有的主从复制的配置。
这里小编遇到的一个坑就是,最好使用mycat1.5即以上的版本,不然对一些链接工具会报错:出现no mycat database selected问题!
这里小编使用的是1.6Linux版本。
首先下载相应的版本:http://dl.mycat.io/1.6-RELEASE/
① 保证MySQL的机器环境中有JDK1.8
需要配置JAVA_HOME!
这里注意,经验推荐配置在相应用户的~/.bashrc下,不要都配置在/etc/profile中。
② 配置mycat
这里需要配置4个文件:server.xml 、schema.xml、 rule.xml 、log4j2.xml
这里小编就简单介绍下:
server.xml:配置用户
schema.xml:配置关联的表和库,以及连接MySQL的host和密码
rule.xml:配置相应的分片规则
log4j2.xml:配置日志级别。
#server.xml加入:
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">mycat</property>
</user>
<user name="mycat_read">
<property name="password">123456</property>
<property name="schemas">mycat</property>
<property name="readOnly">true</property>
</user>#schema.xml修改为:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycat" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1" />
<dataNode name="dn1" dataHost="localhost1" database="weibo" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql"
dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.130.134:3306" user="root" password="123456">
</writeHost>
<writeHost host="hostM2" url="192.168.130.133:3306" user="root" password="123456"/>
</dataHost>
</mycat:schema>#rule.xml基本不变
# log4j2.xml将日志修改为debug
<Loggers>
<asyncRoot level="debug" includeLocation="true">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile"/>
</asyncRoot>
</Loggers>③ 启动mycat
进入mycat的bin下
#运行
$sh mycat start /sh startup_nowrap.sh④ 测试连接
这里可以通过MySQL进行连接:
[root@zzy bin]# mysql -umycat -P8066 -p123456 -h227.0.0.1这里的user和password就是在server.xml中配置的。
也可以通过工具连接,但是需要注意,这里连接的数据库一定要是mycat。
这个问题是因为:mycat启动时需要的内存默认最大为4G,最小为1G,小编这里使用的虚拟机没有这么大内存,所以需要修改$MYCAT_HOMT/conf/ wrapper.conf中:
把配置调整下就行。
这个问题就是需要在/etc/hosts中配置当前主机与IP的映射:
这里我们配置了mycat和主从复制,这里我们只需要连接mycat的8066端口,通过mycat用户就可以对数据库进行CRUD,操作。这里我们连接mycat:
在weibo库下的t_message表中插入一条记录:
然后分别查看master数据库和slave数据库:
到此,MySQL的负载均衡高可用版的读写分离就完成了!
以上两张测试表的语句:
DROP TABLE IF EXISTS `t_message`;
CREATE TABLE `t_message` (
`messages_id` varchar(64) NOT NULL COMMENT '微博ID',
`user_id` varchar(64) NOT NULL COMMENT '发表用户',
`messages_info` varchar(255) DEFAULT NULL COMMENT '微博内容',
`messages_time` datetime DEFAULT NULL COMMENT '发布时间',
`messages_commentnum` int(12) DEFAULT NULL COMMENT '评论次数',
`message_deleteflag` tinyint(1) NOT NULL COMMENT '删除标记 1:已删除 0:未删除',
`message_viewnum` int(12) DEFAULT NULL COMMENT '被浏览量',
PRIMARY KEY (`messages_id`),
KEY `user_id` (`user_id`),
CONSTRAINT `t_message_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `t_users` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_message` WRITE;
;
INSERT INTO `t_message` VALUES ('0001','1001','isfnesnfw','2019-09-01 00:00:00',2,1,2),('0002','1002','isfnesnfw','2019-08-21 00:00:00',2,1,2),('0003','1002','isfnesnfw','2019-08-21 00:00:00',2,1,2);
UNLOCK TABLES;
DROP TABLE IF EXISTS `t_users`;
CREATE TABLE `t_users` (
`user_id` varchar(64) NOT NULL COMMENT '注册用户ID',
`user_email` varchar(64) NOT NULL COMMENT '注册用户邮箱',
`user_password` varchar(64) NOT NULL COMMENT '注册用户密码',
`user_nikename` varchar(64) NOT NULL COMMENT '注册用户昵称',
`user_creatime` datetime NOT NULL COMMENT '注册时间',
`user_status` tinyint(1) NOT NULL COMMENT '验证状态 1:已验证 0:未验证',
`user_deleteflag` tinyint(1) NOT NULL COMMENT '删除标记 1:已删除 0:未删除',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_users` WRITE;
INSERT INTO `t_users` VALUES ('1001','www.415511@qq.com','123456','zsa','2019-08-09 00:00:00',1,2),('1002','www.2345@qq.com','4578964','zsa','2019-07-09 00:00:00',2,3),('1003','www.41we11@qq.com','123456','zsa','2019-08-09 00:00:00',1,2),('1004','www.41523511@qq.com','1456','zasdsa','2018-08-09 00:00:00',1,2);
UNLOCK TABLES;免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





