小编给大家分享一下python如何爬取ajax,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
使用python包:requests。
具体方法:
首先是定义自己headers,注意headers里面的User-Agent这一字段可以根据自己需求设计一个列表,用于随机调换。
ajax数据的网页特点:NetWork中的XHR网络流中有一些ajax请求,其中它们request_url必定是一个ajax请求接口,并且headers里面的referer是其跳转前的url,在构造自己的headers的时候需要设置referer字段。
以拉勾网主页搜索“java”为例:
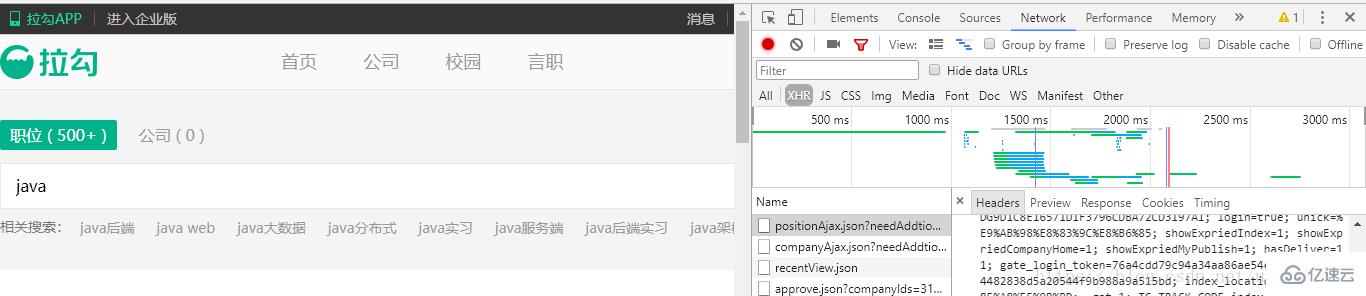 ajax数据的抓取爬虫和普通的网页爬取多了一个url,一个是referer的url,放置于headers中。另外一个就是ajax_url,这个也是主要访问url。
ajax数据的抓取爬虫和普通的网页爬取多了一个url,一个是referer的url,放置于headers中。另外一个就是ajax_url,这个也是主要访问url。
最重要的一点,ajax一般返回json数据,所以抓取下来的数据解析形式有所不同。直接将结果集转换成json结果集即可,访问方式就是普通字典、列表访问形式。
另外一个就是访问参数,若请求中带有param,就将其构造。若没有可忽略。本例中有参数,注意参数字典构造方法
下面就展示出来一个简单的完整代码
from urllib.request import quote,unquote
import random
import requests
keyword = quote('java').strip()
print(keyword, type(keyword))
city = quote('郑州').strip()
print(unquote(city))
refer_url = 'https://www.lagou.com/jobs/list_%s?city=%s&cl=false&fromSearch=true&labelWords=&suginput=' % (keyword, city)
ajax_url = 'https://www.lagou.com/jobs/positionAjax.json?city=%s&needAddtionalResult=false' %city
user_agents=[
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
]
data ={
'first': 'true',
'pn': '1',
'kd': keyword,
}
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '46',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': refer_url,
'User-Agent': user_agents[random.randrange(0,3)],
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
}
resp = requests.post(ajax_url,data=data, headers=headers)
result = resp.json()
print(result)
# print(result)
#result 就是最终获得的json格式数据
item = result['content']['positionResult']['result'][0]
print(item)
#item就是单个招聘条目信息
print("程序结束")看完了这篇文章,相信你对python如何爬取ajax有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





