本篇文章给大家分享的是有关使用python怎么截取XML中bndbox的坐标,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
1、简单易用,与C/C++、Java、C# 等传统语言相比,Python对代码格式的要求没有那么严格;2、Python属于开源的,所有人都可以看到源代码,并且可以被移植在许多平台上使用;3、Python面向对象,能够支持面向过程编程,也支持面向对象编程;4、Python是一种解释性语言,Python写的程序不需要编译成二进制代码,可以直接从源代码运行程序;5、Python功能强大,拥有的模块众多,基本能够实现所有的常见功能。
文件目录
Annotations中是XML文件。
JPEGImages中是对应的JPG文件

XML文件
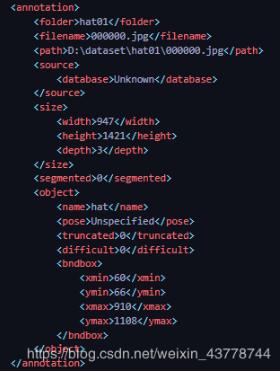
要截取bndbox坐标中的内容。
python代码
# -*- coding: utf-8 -*-
# @Time : 2020/2/8 22:14
# @Author : SanZhi
# @File : get_xml.py
# @Software: PyCharm
import cv2
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = 'D:/ser/JPEGImages/'
# XML文件的地址
anno_path = 'D:/ser/Annotations/'
# 存结果的文件夹
cut_path = 'D:/ser/cut/'
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
DOMTree = xml.dom.minidom.parse(xml_file)
collection = DOMTree.documentElement
objects = collection.getElementsByTagName("object")
for object in objects:
print("start")
bndbox = object.getElementsByTagName('bndbox')[0]
xmin = bndbox.getElementsByTagName('xmin')[0]
xmin_data = xmin.childNodes[0].data
ymin = bndbox.getElementsByTagName('ymin')[0]
ymin_data = ymin.childNodes[0].data
xmax = bndbox.getElementsByTagName('xmax')[0]
xmax_data = xmax.childNodes[0].data
ymax = bndbox.getElementsByTagName('ymax')[0]
ymax_data = ymax.childNodes[0].data
xmin = int(xmin_data)
xmax = int(xmax_data)
ymin = int(ymin_data)
ymax = int(ymax_data)
img_cut = img[ymin:ymax, xmin:xmax, :]
cv2.imwrite(cut_path + 'cut_img_{}.jpg'.format(image_pre), img_cut)
if __name__ == '__main__':
main()补充知识:python读取XML中bndbox和object name的方法
直接贴代码了,封装为了函数,直接调用即可。其中有几个点需要注意。
1、bndbox下面有4个子对象,因此不能直接使用firstChild来找到内容,需要从该对象里面继续寻找标签为xmin等这样的对象,注意要加[0]才正确,有问题的可以直接调试,然后看变量的结构,根据变量的结构来调用某一对象。
2、将空格' '替换为'_',方便命名。但是使用str.replace(' ', '_')不会直接改变str的内容,返回的字符串是改变后的,因此需要变量保存。
import xml.dom.minidom as xmldom
def get_bndboxfromxml(imageNum, xmlfilebasepath):
# 读取xml文件
bndbox = [0, 0, 0, 0]
xmlfilepath = xmlfilebasepath + "\%06d" % imageNum+'.xml'
# print(xmlfilepath)
domobj = xmldom.parse(xmlfilepath)
elementobj = domobj.documentElement
sub_element_obj = elementobj.getElementsByTagName('bndbox')
if sub_element_obj is not None:
bndbox[0] = int(sub_element_obj[0].getElementsByTagName('xmin')[0].firstChild.data)
bndbox[1] = int(sub_element_obj[0].getElementsByTagName('ymin')[0].firstChild.data)
bndbox[2] = int(sub_element_obj[0].getElementsByTagName('xmax')[0].firstChild.data)
bndbox[3] = int(sub_element_obj[0].getElementsByTagName('ymax')[0].firstChild.data)
return bndbox
def get_bndboxnamefromxml(imageNum, xmlfilebasepath):
bndbox = [0, 0, 0, 0]
xmlfilepath = xmlfilebasepath + "\%06d" % imageNum + '.xml'
domobj = xmldom.parse(xmlfilepath)
elementobj = domobj.documentElement
sub_element_obj = elementobj.getElementsByTagName('name')
name = sub_element_obj[0].firstChild.data.replace(' ', '_')
return name以上就是使用python怎么截取XML中bndbox的坐标,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



