这篇文章将为大家详细讲解有关怎么在Python中使用py2neo操作neo4j数据库,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
图:数据结构中的图由节点和其之间的边组成。节点表示一个实体,边表示实体之间的联系。
图数据库:以图的结构存储管理数据的数据库。其中一些数据库将原生的图结构经过优化后直接存储,即原生图存储。还有一些图数据库将图数据序列化后保存到关系型或其他数据库中。
之所以使用图数据库存储数据是因为它在处理实体之间存在复杂关系的数据具有很大的优势。使用传统的关系型数据库在处理数据之间的关系时其实很不方便。例如查询选修一个课程的同学时需要join两个表,查询选修某个课程的同学还选修什么课程,这就需要两次join操作,当涉及到十分复杂的关系以及庞大的数据量时,关系型数据库效率十分低下。而通过图存储,可以通过节点之间的边十分便捷地查询到结果。
图模型:
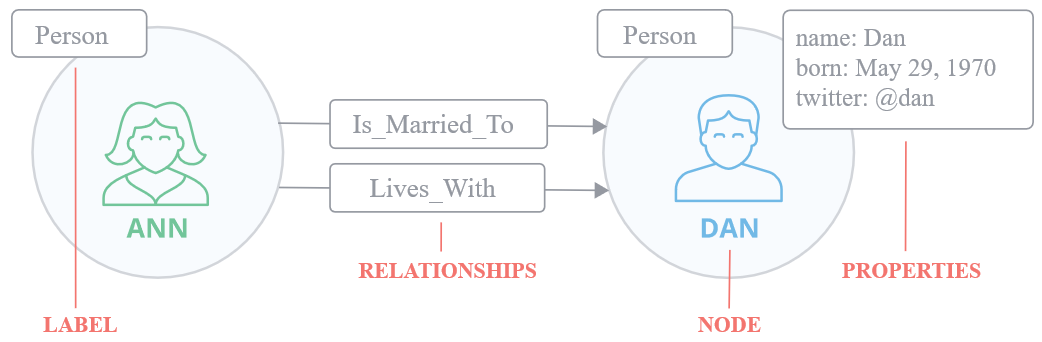
节点(Node)是主要的数据元素,表示一个实体。
属性(Properties)用于描述实体的特征,以键值对的方式表示,其中键是字符串,可以对属性创建索引和约束。
关系(Relationships)表示实体之间的联系,关系具有方向,实体之间可以有多个关系,关系也可以具有属性
标签(Label)用于将实体分类,一个实体可以具有多个标签,对标签进行索引可以加速查找
Neo4j是目前最流行的图数据库,它采用原生图存储,在windows中下载安装访问如下地址https://neo4j.com/download/community-edition/。在Linux下通过如下命令下载解压
curl -O http://dist.neo4j.org/neo4j-community-3.4.5-unix.tar.gz tar -axvf neo4j-community-3.4.5-unix.tar.gz
修改配置文件conf/neo4j.conf
# 修改第22行load csv时l路径,在前面加个#,可从任意路径读取文件 #dbms.directories.import=import # 修改35行和36行,设置JVM初始堆内存和JVM最大堆内存 # 生产环境给的JVM最大堆内存越大越好,但是要小于机器的物理内存 dbms.memory.heap.initial_size=5g dbms.memory.heap.max_size=10g # 修改46行,可以认为这个是缓存,如果机器配置高,这个越大越好 dbms.memory.pagecache.size=10g # 修改54行,去掉改行的#,可以远程通过ip访问neo4j数据库 dbms.connectors.default_listen_address=0.0.0.0 # 默认 bolt端口是7687,http端口是7474,https关口是7473,不修改下面3项也可以 # 修改71行,去掉#,设置http端口为7687,端口可以自定义,只要不和其他端口冲突就行 #dbms.connector.bolt.listen_address=:7687 # 修改75行,去掉#,设置http端口为7474,端口可以自定义,只要不和其他端口冲突就行 dbms.connector.http.listen_address=:7474 # 修改79行,去掉#,设置http端口为7473,端口可以自定义,只要不和其他端口冲突就行 dbms.connector.https.listen_address=:7473 # 去掉#,允许从远程url来load csv dbms.security.allow_csv_import_from_file_urls=true # 修改250行,去掉#,设置neo4j-shell端口,端口可以自定义,只要不和其他端口冲突就行 dbms.shell.port=1337 # 修改254行,设置neo4j可读可写 dbms.read_only=false
在bin目录下执行 ./neo4j start,启动服务,在浏览器http://服务器ip地址:7474/browser/可以看到neo4j的可视化界面
py2neo是一个社区第三方库,通过它可以更为便捷地使用python来操作neo4j
安装py2neo:pip install py2neo,我安装的版本是4.3.0
创建节点和它们之间的关系,注意在使用下面的py2neo相关类之前首先需要import导入:
# 引入库
from py2neo import Node, Relationship
# 创建节点a、b并定义其标签为Person,属性name
a = Node("Person", name="Alice",height=166)
b = Node("Person", name="Bob")
# 节点添加标签
a.add_label('Female')
# 创建ab之间的关系
ab = Relationship(a, "KNOWS", b)
# 输出节点之间的关系:(Alice)-[:KNOWS]->(Bob)
print(ab)Node 和 Relationship 都继承了 PropertyDict 类,类似于python的dictionary,可以通过如下方式对 Node 或 Relationship 进行属性赋值和访问
# 节点和关系添加、修改属性
a['age']=20
ab['time']='2019/09/03'
# 删除属性
del a['age']
# 打印属性
print(a[name])
# 设置默认属性,如果没有赋值,使用默认值,否则设置的新值覆盖默认值
a.setdefault('sex','unknown')
# 更新属性
a.update(age=22, sex='female')
ab.update(time='2019/09/03')由节点和关系组成的集合就是子图,通过关系运算符求交集&、并集|、差集-、对称差集^
subgraph.labels返回子图中所有标签集合,keys()返回所有属性集合,nodes返回所有节点集,relationships返回所有关系集
# 构建一个子图
s = a | b | ab
# 对图中的所有节点集合进行遍历
for item in s.nodes:
print('s的节点:', item)通常将图中的所有节点和关系构成一个子图后再统一写入数据库,与多次写入单个节点相比效率更高
# 连接neo4j数据库,输入地址、用户名、密码
graph = Graph('http://localhost:7474', username='neo4j', password='123456')
# 将节点和关系通过关系运算符合并为一个子图,再写入数据库
s=a | b | ab
graph.create(s)walkable是在子图subgraph的基础上增加了遍历信息的对象,通过它可以便捷地遍历图数据库。
通过+号将关系连接起来就构成了一个walkable对象。通过walk()函数对其进行遍历,可以利用 start_node、end_node、nodes、relationships属性来获取起始 Node、终止 Node、所有 Node 和 Relationship
# 组合成一个walkable对象w
w = ab + bc + ac
# 对w进行遍历
for item in walk(w):
print(item)
# 访问w的初始、终止节点
print('起始节点:', w.start_node, ' 终止节点:', w.end_node)
# 访问w的所有节点、关系列表
print('节点列表:', w.nodes)
print('关系列表:', w.relationships)运行结果为:
(:Person {age: 20, name: 'Bob'})
(Bob)-[:KNOWS {}]->(Alice)
(:Person {age: 21, name: 'Alice'})
(Alice)-[:LIKES {}]->(Mike)
(:Person {name: 'Mike'})
(Bob)-[:KNOWS {}]->(Mike)
(:Person {age: 20, name: 'Bob'})
起始节点: (:Person {age: 22, name: 'Bob', sex: 'female'}) 终止节点: (:Person {age: 22, name: 'Bob', sex: 'female'})
节点列表: ((:Person {age: 22, name: 'Bob', sex: 'female'}), (:Person {age: 21, name: 'Alice'}), (:Person {name: 'Mike'}), (:Person {age: 22, name: 'Bob', sex: 'female'}))
关系列表: ((Bob)-[:KNOWS {time: '2019/09/03'}]->(Alice), (Alice)-[:LIKES {}]->(Mike), (Bob)-[:KNOWS {}]->(Mike))
py2neo通过graph对象操作neo4j数据库,目前的neo4j只支持一个数据库定义一张图
通过Graph的初始化函数完成对数据库的连接并创建一个graph对象
graph.create()可以将子图写入数据库,也可以一次只写入一个节点或关系
graph.delete()删除指定子图,graph.delete_all()删除所有子图
graph.seperate()删除指定关系
# 初始化连接neo4j数据库,参数依次为url、用户名、密码
graph = Graph('http://localhost:7474', username='neo4j', password='123456')
# 写入子图w
graph.create(w)
# 删除子图w
graph.delete(w)
# 删除所有图
graph.delete_all()
# 删除关系rel
graph.separate(rel)graph.match(nodes=None, r_type=None, limit=None)查找符合条件的关系,第一个参数为节点集合或者集合(起始节点,终止节点),如果省略代表所有节点。第二个参数为关系的属性,第三个为返回结果的数量。也可以使用match_one()代替,返回一条结果。例如查找所有节点a认识的人:
# 查找所有以a为起点,并且属性为KNOWS的关系 res = graph.match((a, ), r_type="KNOWS") # 打印关系的终止节点,即为a所有认识的人 for rel in res: print(rel.end_node["name"])
使用graph.nodes.match()查找指定节点,可以使用first()、where()、order_by()等函数对查找做高级限制
还可以通过节点或关系的id查找
# 查找标签为Person,属性name="Alice"的节点,并返回第一个结果
graph.nodes.match("Person", name="Alice").first()
# 查找所有标签为Person,name以B开头的节点,并将结果按照age字段排序
res = graph.nodes.match("Person").where("_.name =~ 'B.*'").order_by('_.age')
for node in res:
print(node['name'])
# 查找id为4的节点
t_node = graph.nodes[4]
# 查找id为196的关系
rel = graph.relationships[196]通过Graph对象进行Cypher操作并处理返回结果
graph.evaluate()执行一个Cypher语句并返回结果的第一条数据
# 执行Cypher语句并返回结果集的第一条数据
res = graph.evaluate('MATCH (p:Person) return p')
# 输出:(_3:Person {age: 20, name: 'Bob'})
print(res)graph.run()执行Cypher语句并返回结果数据流的游标Cursor,通过forward()方法不断向前移动游标可以向前切换结果集的每条记录Record对象
# 查询(p1)-[k]->(p2),并返回所有节点和关系 gql="MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *" cursor=graph.run(gql) # 循环向前移动游标 while cursor.forward(): # 获取并打印当前的结果集 record=cursor.current print(record)
打印的每条Record记录对象如下所示,可以看到其中的元素是key=value的集合,通过方法get(key)可以取出具体元素。通过方法items(keys)可以将记录中指定的key按(key,value)元组的形式返回
<Record k=(xiaowang)-[:KNOWS {}]->(xiaozhang) p1=(_96:Person {name: 'xiaowang'}) p2=(_97:Person {name: 'xiaozhang'})>
record = cursor.current
print('通过get返回:', record.get('k'))
for (key, value) in record.items('p1', 'p2'):
print('通过items返回元组:', key, ':', value)
# 运行结果如下
'''
通过get返回: (xiaowang)-[:KNOWS {}]->(xiaozhang)
通过items返回元组: p1 : (_92:Person {name: 'xiaowang'})
通过items返回元组: p2 : (_93:Person {name: 'xiaozhang'})
'''还可以将graph.run()返回的结果通过data()方法转化为字典列表,所有结果整体上是一个列表,其中每一条结果是字典的格式,其查询与结果如下,可以通过访问列表与字典的方式获取数据:
# 查询(p1)-[k]->(p2),并返回所有节点和关系
gql = "MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *"
res = graph.run(gql).data()
print(res)
#结果如下:
'''
[{'k': (xiaowang)-[:KNOWS {}]->(xiaozhang),
'p1': (_196:Person {name: 'xiaowang'}),
'p2': (_197:Person {name: 'xiaozhang'})},
{'k': (xiaozhang)-[:KNOWS {}]->(xiaozhao),
'p1': (_197:Person {name: 'xiaozhang'}),
'p2': (_198:Person {name: 'xiaozhao'})},
{'k': (xiaozhao)-[:KNOWS {}]->(xiaoli),
'p1': (_198:Person {name: 'xiaozhao'}),
'p2': (_199:Person {name: 'xiaoli'})}
]
'''通过graph.run().to_subgraph()方法将返回的结果转化为SubGraph对象,接着按之前操作SubGraph对象的方法取得节点对象,这里的节点对象Node可以直接按照之前的Node操作
# 查询(p1)-[k]->(p2),并返回所有节点和关系
gql = "MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *"
sub_graph = graph.run(gql).to_subgraph()
# 获取子图中所有节点对象并打印
nodes=sub_graph.nodes
for node in nodes:
print(node)
# 输出的节点对象如下:
'''
(_101:Person {name: 'xiaozhang'})
(_100:Person {name: 'xiaowang'})
(_103:Person {name: 'xiaoli'})
(_102:Person {name: 'xiaozhao'})
'''Object-Graph Mapping将图数据库中的节点映射为python对象,通过对象的方式对节点进行访问和操作。
将图中的每种标签定义为一个python类,其继承自GraphObject,注意使用前先import。在定义时可以指定数据类的主键,并定义类的属性Property()、标签Label()、关系RelatedTo()/RelatedFrom。
from py2neo.ogm import GraphObject, Property, RelatedTo, RelatedFrom, Label
class Person(GraphObject):
# 定义主键
__primarykey__ = 'name'
# 定义类的属性
name=Property()
age=Property()
# 定义类的标签
student=Label()
# 定义Person指向的关系
knows=RelatedTo('Person','KNOWS')
# 定义指向Person的关系
known=RelatedFrom('Person','KNOWN')通过类方法wrap()可以将一个普通节点转化为类的对象。
类方法match(graph,primary_key)可以在graph中查找主键值为primary_key的节点
可以直接通过类构造方法创建一个对象,并直接访问对象的属性及方法,并通过关系方法add()添加关系
类的标签是一个bool值,默认为False,将其修改为True,即可为对象添加标签
# 将节点c转化为OGM类型 c=Person.wrap(c) print(c.name) # 查找Person类中主键(name)为Alice的节点 ali=Person.match(graph,'Alice').first() # 创建一个新的Person对象并对其属性赋值 new_person = Person() new_person.name = 'Durant' new_person.age = 28 # 标签值默认为False print(new_person.student) # 修改bool值为True,为对象添加student标签 new_person.student=True # 将修改后的图写入数据库 graph.push(ali)
在定义节点类时还可以定义其相关的关系,例如通过RelatedTo()定义从该节点指出的关系,RelatedFrom()定义指向该节点的关系。通过对象调用关系的对应的方法完成节点周围的关系操作,例如add()添加关系,clear()清除节点所有的关系,get()获取关系属性,remove()清楚指定的关系,update()更新关系
class Person(GraphObject):
# 定义Person指向的关系
knows=RelatedTo('Person','KNOWS')
# 定义指向Person的关系
known=RelatedFrom('Person','KNOWN')
# 新建一个从ali指向new_person的关系
ali.knows.add(new_person)
# 清除ali节点所有的know关系
ali.knows.clear()
# 清除ali节点指向new_person的那个know关系
ali.knows.remove(new_person)
# 更新ali指向new_person关系的属性值
ali.knows.update(new_person,year=5)
# 获取ali指向new_person关系的属性year的值
ali.knows.get(new_person,'year')通过图对象也可以调用match方法对节点、关系进行匹配
# 获取第一个主键name名为Alice的Person对象
ali = Person.match(graph, 'Alice').first()
# 获取所有name以B开头的Person对象
Person.match(graph).where("_.name =~ 'B.*'")也可以通过图graph对节点对象进行操作:
# 更新图中ali节点的相关数据 graph.push(ali) # 用图中的信息来更新ali节点 graph.pull(ali) # 删除图中的ali对象节点 graph.delete(ali)
关于怎么在Python中使用py2neo操作neo4j数据库就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





