这篇文章主要介绍了Pytorch如何实现自定义数据集,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
第一步、导入需要的包
import os
import scipy.io as sio
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from torch.autograd import VariablebatchSize = 128 # batchsize的大小
niter = 10 # epoch的最大值第二步、构建神经网络
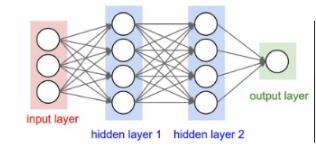
设神经网络为如上图所示,输入层4个神经元,两层隐含层各4个神经元,输出层一个神经。每一层网络所做的都是线性变换,即y=W×X+b;代码实现如下:
class Neuralnetwork(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Neuralnetwork, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
model = Neuralnetwork(1*3, 4, 4, 1)
print(model) # net architectureNeuralnetwork(
(layer1): Linear(in_features=3, out_features=4, bias=True)
(layer2): Linear(in_features=4, out_features=4, bias=True)
(layer3): Linear(in_features=4, out_features=1, bias=True)
) 第三步、读取数据
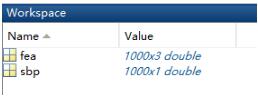
自定义的数据为demo_SBPFea.mat,是MATLAB保存的数据格式,其存储的内容如下:包括fea(1000*3)和sbp(1000*1)两个数组;fea为特征向量,行为样本数,列为特征宽度;sbp为标签
class SBPEstimateDataset(Dataset):
def __init__(self, ext='demo'):
data = sio.loadmat(ext+'_SBPFea.mat')
self.fea = data['fea']
self.sbp = data['sbp']
def __len__(self):
return len(self.sbp)
def __getitem__(self, idx):
fea = self.fea[idx]
sbp = self.sbp[idx]
"""Convert ndarrays to Tensors."""
return {'fea': torch.from_numpy(fea).float(),
'sbp': torch.from_numpy(sbp).float()
}
train_dataset = SBPEstimateDataset(ext='demo')
train_loader = DataLoader(train_dataset, batch_size=batchSize, # 分批次训练
shuffle=True, num_workers=int(8))整个数据样本为1000,以batchSize = 128划分,分为8份,前7份为104个样本,第8份则为104个样本。在网络训练过程中,是一份数据一份数据进行训练的
第四步、模型训练
# 优化器,Adam
optimizer = optim.Adam(list(model.parameters()), lr=0.0001, betas=(0.9, 0.999),weight_decay=0.004)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.997)
criterion = nn.MSELoss() # loss function
if torch.cuda.is_available(): # 有GPU,则用GPU计算
model.cuda()
criterion.cuda()
for epoch in range(niter):
losses = []
ERROR_Train = []
model.train()
for i, data in enumerate(train_loader, 0):
model.zero_grad()# 首先提取清零
real_cpu, label_cpu = data['fea'], data['sbp']
if torch.cuda.is_available():# CUDA可用情况下,将Tensor 在GPU上运行
real_cpu = real_cpu.cuda()
label_cpu = label_cpu.cuda()
input=real_cpu
label=label_cpu
inputv = Variable(input)
labelv = Variable(label)
output = model(inputv)
err = criterion(output, labelv)
err.backward()
optimizer.step()
losses.append(err.data[0])
error = output.data-label+ 1e-12
ERROR_Train.extend(error)
MAE = np.average(np.abs(np.array(ERROR_Train)))
ME = np.average(np.array(ERROR_Train))
STD = np.std(np.array(ERROR_Train))
print('[%d/%d] Loss: %.4f MAE: %.4f Mean Error: %.4f STD: %.4f' % (
epoch, niter, np.average(losses), MAE, ME, STD))
[0/10] Loss: 18384.6699 MAE: 135.3871 Mean Error: -135.3871 STD: 7.5580
[1/10] Loss: 17063.0215 MAE: 130.4145 Mean Error: -130.4145 STD: 7.8918
[2/10] Loss: 13689.1934 MAE: 116.6625 Mean Error: -116.6625 STD: 9.7946
[3/10] Loss: 8192.9053 MAE: 89.6611 Mean Error: -89.6611 STD: 12.9911
[4/10] Loss: 2979.1340 MAE: 52.5410 Mean Error: -52.5279 STD: 15.0930
[5/10] Loss: 599.7094 MAE: 22.2735 Mean Error: -19.9979 STD: 14.2069
[6/10] Loss: 207.2831 MAE: 11.2394 Mean Error: -4.8821 STD: 13.5528
[7/10] Loss: 189.8173 MAE: 9.8020 Mean Error: -1.2357 STD: 13.7095
[8/10] Loss: 188.3376 MAE: 9.6512 Mean Error: -0.6498 STD: 13.7075
[9/10] Loss: 186.8393 MAE: 9.6946 Mean Error: -1.0850 STD: 13.6332感谢你能够认真阅读完这篇文章,希望小编分享的“Pytorch如何实现自定义数据集”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



