代码如下
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, datetime import base64, json, pymysql from fontTools.ttLib import TTFont ua = UserAgent() class CustomException(Exception): def __init__(self, status, msg): self.status = status self.msg = msg class City_58: ''' 58同城的爬虫类,目前就写这两个 出租房url: https://cd.58.com/chuzu/ cd代表成都缩写 二手房url: https://cd.58.com/ershoufang/ ''' font_dict = { "glyph00001": "0", "glyph00002": "1", "glyph00003": "2", "glyph00004": "3", "glyph00005": "4", "glyph00006": "5", "glyph00007": "6", "glyph00008": "7", "glyph00009": "8", "glyph00010": "9", } conn = None def __init__(self): self.session = requests.Session() self.session.headers = { "user-agent": ua.random } self.__init__all_city() def __init__all_city(self): '''获取所有城市的名字及缩写的对应关系''' api = "https://www.58.com/changecity.html" headers = self.session.headers.copy() response = self.session.get(api, headers=headers) html = response.text res = re.findall("cityList = (.*?)</script>", html, re.S)[0] res = re.sub("\s", "", res) dic = json.loads(res) for k, v in dic.items(): for k1, v1 in v.items(): dic[k][k1] = v1.split("|")[0] city_dict = {} def traverse_dict(dic: dict): for k, v in dic.items(): if k == "海外" or k == "其他": continue if isinstance(v, dict): traverse_dict(v) city_dict[k] = v traverse_dict(dic) other_city = re.findall("independentCityList = (.*?)var", html, re.S)[0] res = re.sub("\s", "", other_city) other_city_dic = json.loads(res) for k, v in other_city_dic.items(): other_city_dic[k] = v.split("|")[0] city_dict.update(other_city_dic) self.all_city_dict = city_dict def spider_zufang(self, city: str = "成都", is_get_all: bool = True): '''爬取租房信息的爬虫方法''' assert self.all_city_dict is not None, "获取所有城市信息失败 !" format_city = self.all_city_dict.pop(city, None) assert format_city is not None, "{}该城市不在爬取城市之内".format(city) while True: self.city = city # self.file = open("./house_info.json", "a", encoding="utf-8") start_url = self.__init_zufang(format_city) # 思路是什么,首先进入区域的租房页面,在该页面中先提取出相应的title,比如经纪人,个人房源等等... # 我们需要构建出相应的url就可以了 # start_url的格式为 https://cd.58.com/chuzu/ 我们需要转为这样的格式 https://cd.58.com/jintang/hezu/ # 我们访问转化后的地址,再拿去到相应的链接,比如经纪人,个人房源等链接 # 拿到该链接以后,这就是这个分类里的第一页url,我们再对这个链接发生请求, # 拿到响应体,这里可以写一个while循环,因为我们不知道有多少页,其实也可以知道有多少页,就是在这个响应体中可拿到 # 我的思路就是写一个while循环,判断是否有下一页,有的继续,没有的话直接break for url_info_list in self.__get_url(start_url): # 这里的话,最好进行判断一下,因为每个title(值个人房源,品牌公寓等..)不一样的话,可能爬取的策略也不太一样 title = url_info_list[1] if title in ["个人房源", "安选房源", "经纪人", "热租房源"] or "出租" in title: self.__spiders_v1(url_info_list) # pass elif title == "品牌公寓": self.__spiders_v2(url_info_list) pass elif title == "房屋求租": # 房屋求租不太想写,数据也不是很多 pass else: # 这种情况不在范围内,直接pass掉 continue if not is_get_all: return try: city = list(self.all_city_dict.keys()).pop() format_city = self.all_city_dict.pop(city) except IndexError: print('全国出租房信息,爬取完毕') return def spider_ershoufang(self, city: str = "cd"): '''爬取二手房信息的爬虫方法''' pass def __spiders_v1(self, url_info_list): "负责处理个人房源,安选房源等等页面的方法" url = url_info_list[2] page_num = 1 while True: time.sleep(2) print("正在爬取{}-{}--第{}页数据".format(url_info_list[0], url_info_list[1], page_num)) response = self.__get_html_source(url) # 从html源码中获取到想要的数据 for house_info_list in self.__deal_with_html_source_v1(response): self.__save_to_mysql(house_info_list, url_info_list) # 判断是否还有下一页 next_page_url = self.__is_exist_next_page(response) if not next_page_url: print("{}-{}爬取完毕".format(url_info_list[0], url_info_list[1])) return url = next_page_url page_num += 1 def __spiders_v2(self, url_info_list): '''处理品牌公寓的爬虫信息''' base_url = url_info_list[2] format_url = self.__format_url_v2(base_url) page_num = 1 params = None while True: print("正在爬取{}--第{}页数据...".format(url_info_list[1], page_num)) time.sleep(2) url = format_url.format(page_num) response = self.__get_html_source(url, params) # 获取到有用的数据 deal_with_html_source_v2 for house_info_list in self.__deal_with_html_source_v2(response): # self.__save_to_file_v2(house_info_list) self.__save_to_mysql(house_info_list) # 获取到下一页的encryptData encryptData = self.__get_html_encryptData(response) # 判断是否还有下一页,通过<div class="tip">信息不足,为您推荐附近房源</div> if not self.__is_exist_next_page_v2(response): print("{}爬取完毕".format(url_info_list[1])) return page_num += 1 params = { "encryptData": encryptData or "", "segment": "true" } def __save_to_file_v2(self, house_info_list): ''' :param house_info_list: 关于房子的信息的列表 :param url_info_list: [区域,类型(个人房源,经纪人等等...),url] :return: ''' print("房间图片地址>>:", file=self.file) print(json.dumps(house_info_list[0], ensure_ascii=False), file=self.file) print("房间描述>>:", file=self.file) print(json.dumps(house_info_list[1], ensure_ascii=False), file=self.file) print("房间详情>>:", file=self.file) print(json.dumps(house_info_list[2], ensure_ascii=False), file=self.file) print("房间地理位置>>:", file=self.file) print(json.dumps(house_info_list[3], ensure_ascii=False), file=self.file) print("获取房间的标签>>:", file=self.file) print(json.dumps(house_info_list[4], ensure_ascii=False), file=self.file) print("获取房间的价格>>:", file=self.file) print(json.dumps(house_info_list[5], ensure_ascii=False), file=self.file) print(file=self.file) def __save_to_mysql(self, house_info_list, url_info_list=None): '''保存到数据库''' if not self.conn: self.conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="root", db="city_58") self.conn.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor) if not url_info_list: sql = "insert into zu_house_copy (house_img_url,house_title,house_details,house_address,house_tags,hoouse_price,house_type,city) values (%s,%s,%s,%s,%s,%s,%s,%s)" house_info_list.append("品牌公寓") else: sql = "insert into zu_house_copy (house_img_url,house_title,house_details,house_address,house_tags,hoouse_price,area,house_type,city) values (%s,%s,%s,%s,%s,%s,%s,%s,%s)" house_info_list.append(url_info_list[0]) house_info_list.append(url_info_list[1]) house_info_list.append(self.city) row = self.conn.cursor.execute(sql, house_info_list) if not row: print("插入失败") else: self.conn.commit() def __deal_with_html_source_v1(self, response): html = response.text self.__get_font_file(html) html = self.__format_html_source(html) for house_info_list in self.__parse_html_v1(html): yield house_info_list def __deal_with_html_source_v2(self, response): html = response.text # 源码里的关于数字0123456789都是进行处理过的,我们需要先获取到字体文件 # 我们先获取到字体文件并且保存 self.__get_font_file(html) # 对源码中的字体进行处理,得到浏览器显示的数据 html = self.__format_html_source(html) # 开始从页面中提取出想要的数据 for house_info_list in self.__parse_html_v2(html): yield house_info_list def __parse_html_v1(self, html): xml = etree.HTML(html) li_xpath_list = xml.xpath("//ul[@class='listUl']/li[@logr]") for li_xpath in li_xpath_list: house_info_list = [] try: house_img_url = li_xpath.xpath("div[@class='img_list']/a/img/@lazy_src")[0] except IndexError: house_img_url = li_xpath.xpath("div[@class='img_list']/a/img/@src")[0] house_info_list.append(house_img_url) # 房间描述 house_title = re.sub("\s", "", li_xpath.xpath("div[@class='des']/h3/a/text()")[0]) house_info_list.append(house_title) # 房间详情 house_details = re.sub("\s", "", li_xpath.xpath("div[@class='des']/p[@class='room strongbox']/text()")[0].strip()) house_info_list.append(house_details) # 房间地理位置 house_address = re.sub("\s", "", li_xpath.xpath("div[@class='des']/p[@class='add']")[0].xpath("string(.)")) house_info_list.append(house_address) # 获取房间的标签 house_tags = "暂无标签" house_info_list.append(house_tags) # 获取房间的价格 hoouse_price = re.sub("\s", "", li_xpath.xpath("div[@class='listliright']/div[@class='money']")[0].xpath("string(.)")) house_info_list.append(hoouse_price) yield house_info_list def __parse_html_v2(self, html): '''解析页面,拿到数据''' xml = etree.HTML(html) li_xpath_list = xml.xpath("//ul[@class='list']/li") for li_xpath in li_xpath_list: house_info_list = [] # 房间图片地址,这里只获取了一张,我在想要不要获取多张 # 先空着。。。。。。。。。。。。。 house_img_url = li_xpath.xpath("a/div[@class='img']/img/@lazy_src")[0] house_info_list.append(house_img_url) # 房间描述 house_title = li_xpath.xpath("a/div[@class='des strongbox']/h3/text()")[0].strip() house_info_list.append(house_title) # 房间详情 house_details = re.sub("\s", "", li_xpath.xpath("a/div[@class='des strongbox']/p[@class='room']/text()")[0]) # house_details = li_xpath.xpath("a/div[@class='des strongbox']/p[@class='room']/text()")[0] house_info_list.append(house_details) # 房间地理位置 house_address = re.sub("\s", "", li_xpath.xpath( "a/div[@class='des strongbox']/p[@class='dist']")[0].xpath("string(.)")) or "暂无地址" # house_address = li_xpath.xpath( "a/div[@class='des strongbox']/p[@class='dist']/text()")[0] house_info_list.append(house_address) # 获取房间的标签 house_tags = ",".join(li_xpath.xpath("a/div[@class='des strongbox']/p[@class='spec']/span/text()")) house_info_list.append(house_tags) # 获取房间的价格 hoouse_price = re.sub("\s", "", li_xpath.xpath("a/div[@class='money']/span[@class='strongbox']")[0].xpath( "string(.)")) or "暂无价格" house_info_list.append(hoouse_price) yield house_info_list def __get_font_file(self, html): '''从源码中获取到字体文件,并且转为保存,转为TTFont对象''' try: b64 = re.findall(r"base64,(.*?)\'", html, re.S)[0] res = base64.b64decode(b64) with open("./online_font.ttf", "wb") as f: f.write(res) self.online_font = TTFont("./online_font.ttf") self.online_font.saveXML("./online.xml") except IndexError: return def __format_html_source(self, html): assert self.online_font, "必须创建字体对象" assert os.path.exists("./online.xml"), "请先获取到字体文件。" with open("./online.xml", "rb") as f: file_data = f.read() online_uni_list = self.online_font.getGlyphOrder()[1:] file_selector = etree.HTML(file_data) for uni2 in online_uni_list: code = file_selector.xpath("//cmap//map[@name='{}']/@code".format(uni2))[0] dd = "&#x" + code[2:].lower() + ";" if dd in html: html = html.replace(dd, self.font_dict[uni2]) return html def __format_url_v2(self, url): ''' :param url: https://cd.58.com/pinpaigongyu/?from=58_pc_zf_list_ppgy_tab_ppgy :return: https://cd.58.com/pinpaigongyu/pn/{}/?from=58_pc_zf_list_ppgy_tab_ppgy ''' a = url.split("?") a[0] = a[0] + "pn/{}" format_url = "?".join(a) return format_url def __is_exist_next_page_v2(self, response): xml = self.__response_to_xml(response) try: _ = xml.xpath("//div[@class='tip']")[0] return False except IndexError: return True def __get_html_encryptData(self, response): html = response.text encryptData = re.findall(r"encryptData\":\"(.*?)\"", html, re.S)[0] return encryptData def __get_url(self, start_url: str): url_set = set() for area, v in self.area_dict.items(): url = self.__conversion_url(start_url, v) response = self.__get_html_source(url) title_dict = self.__get_title_info(response) for title_name, v in title_dict.items(): # 对于求租、品牌公寓这个url,它是重复的,在这里进行判断判断就好了 if v in url_set: continue else: url_set.add(v) yield [area, title_name, v] def __conversion_url(self, url: str, area: str): ''' :param url: https://cd.58.com/chuzu/ :param area: :return: https://cd.58.com/区域缩写/chuzu/ ''' lis = url.split("/") lis.insert(3, area) return "/".join(lis) def __init_zufang(self, format_city): '''首先将所需要的数据的获取到''' start_url = "https://{}.58.com/chuzu/".format(format_city) headers = self.session.headers.copy() response = self.session.get(url=start_url, headers=headers) self.__get_area_info(response) return start_url def __get_html_source(self, url, params=None): '''通过get方式获取到网页的源码''' time.sleep(1) headers = self.session.headers.copy() try: if not params: params = {} response = self.session.get(url=url, headers=headers, params=params) return response except Exception as e: with open("./url_log_error.txt", "a", encoding="utf-8") as f: f.write(str(datetime.datetime.now()) + "\n") f.write(str(e) + "\n") f.write("error_url>>:{}".format(url) + "\n") def __response_to_xml(self, response): try: xml = etree.HTML(response.text) return xml except AttributeError: raise CustomException(10000, "response对象转换为xml失败,错误的链接地址为>>:{}".format(response)) def __is_exist_next_page(self, response): '''判断是否存在下一页,存在拿到下一页的链接,不存在返回False''' xml = self.__response_to_xml(response) try: next_page_url = xml.xpath("//a[@class='next']/@href")[0] return next_page_url except IndexError: return False def __get_area_info(self, response): '''获取到当前城市的区域''' xml = self.__response_to_xml(response) a_xpath_list = xml.xpath("//dl[@class='secitem secitem_fist']//a[not(@class)]") area_key_list = [] area_value_list = [] for a_xpath in a_xpath_list: area_key_list.append(a_xpath.xpath("text()")[0]) area_value_list.append(re.findall("com/(.*?)/", a_xpath.xpath("@href")[0])[0]) assert len(area_key_list) == len(area_value_list), "数据不完整" self.area_dict = {k: v for k, v in zip(area_key_list, area_value_list)} def __get_title_info(self, response): '''获取房屋的分类,比如个人房源,合租房,经纪人,热选房源...''' "listTitle" xml = self.__response_to_xml(response) a_xpath_list = xml.xpath("//div[@class='listTitle']//a[not(@class)]") title_key_list = [] title_value_list = [] for a_xpath in a_xpath_list: title_key_list.append(a_xpath.xpath("span/text()")[0]) title_value_list.append(a_xpath.xpath("@href")[0]) assert len(title_key_list) == len(title_value_list), "数据不完整" return {k: v for k, v in zip(title_key_list, title_value_list)} if __name__ == '__main__': city_58 = City_58() city_58.spider_zufang("重庆")
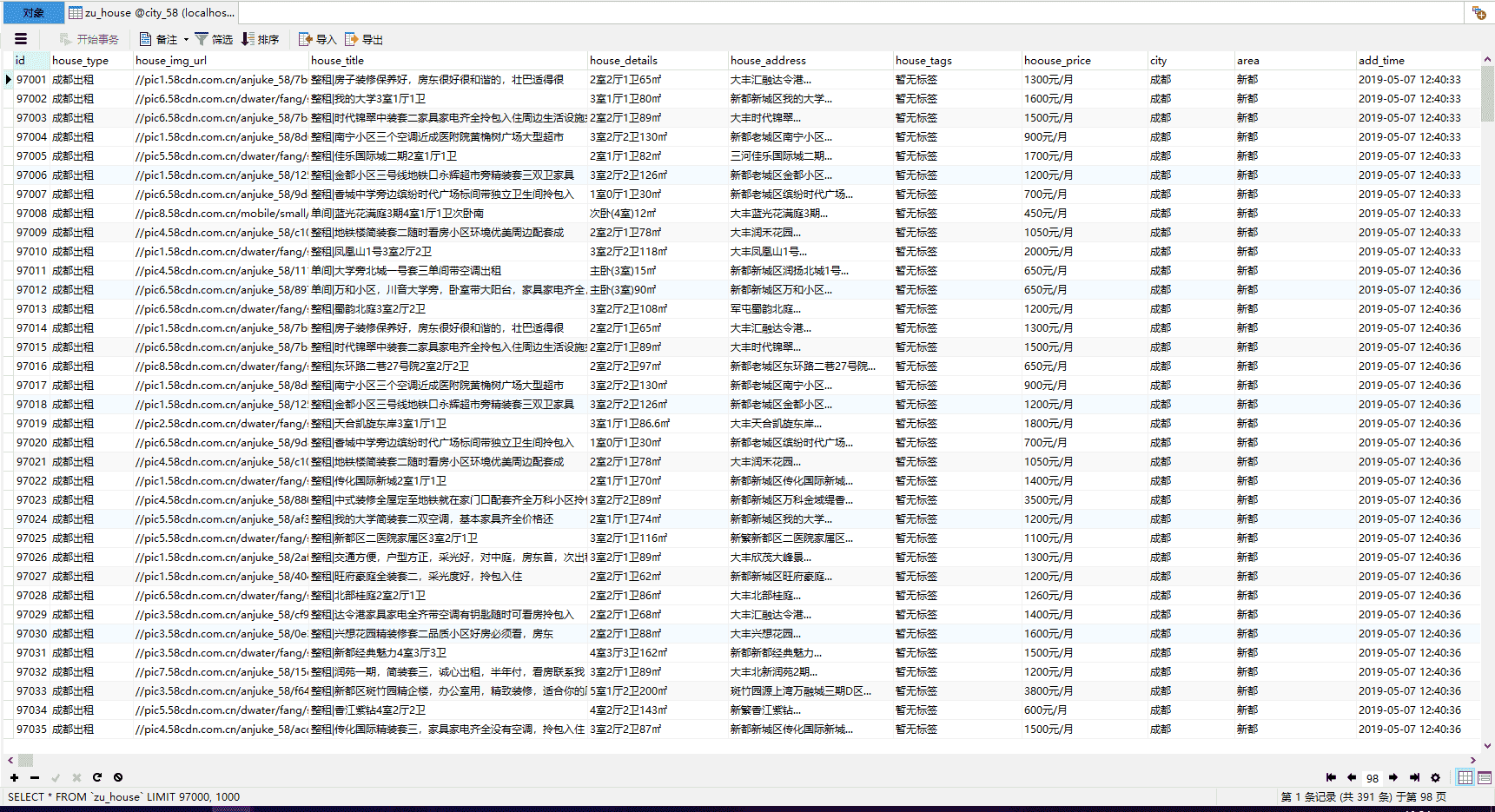
附上数据库爬取的结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





