小编给大家分享一下如何对pandas的行列名进行更改与数据选择,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一、pandas的行列名获取和更改
1. 获取: df.index() df.columns()
首先,举个例子,做一个DataFrame如下:
>>>import pandas as pd
>>>import numpy as np
>>>data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
>>>data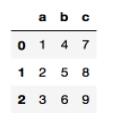
设置了列索引为 abc,行索引是自动生成的,也可以设置
>>>data.index = ['A','B','C']
>>>data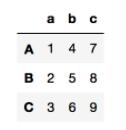
以下的做法都以这个 data 作为数据举例
接下来就可以获取索引了,index-行索引,columns-列索引
>>>data.index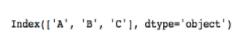
>>>data.columns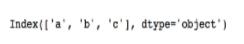
2. 修改,看到有很多方法,这里推荐一种比较灵活好用的方法
df.rename(index={ }, columns={ }, inplace=True)
>>>data.rename(index={'A':'D', 'B':'E', 'C':'F'}, columns={'a':'d', 'b':'e', 'c':'f'}, inplace = True)
>>>data
说明3点:
1. index和columns无关,可以分别指定,也就是说,可以只修改行索引,那么rename()中只写index
2. 索引可以任意挑选,如此处,index={'A':'D', 'C':'F'} 则只改A和C,columns同样
3. inplace=True, 在原dataframe上改动
二、pandas的数据选择
1. 直接用索引选(不灵活、不推荐) df[ ]
1) 选择‘a'列
>>>data['a']
注意:
1. 这样取出的数据类型为 Series
2. 这种方法只能取出一列,不能用数字下标,不能多选或片选, data['a','b'] , data['a':'c'] , data[0]
2)选择'A','B'行
>>>data['A':'B']
>>>data[0:2] # 两种方法同一结果
注意:
1. 这样取出的数据类型为 DateFrame
2. 这种方法只能用于片选行,可以用数字下标,不能单独取,即 data['A'] , data['A','B'] , data[1]
2.使用 .loc(推荐) df.loc(),()内参数先行后列,区别行列的取法
1) 取列:
>>>data.loc[:,['a','c']] #图1 需要行全取,再对应指定列2)取行:
>>>data.loc[['A','B']] #图2 直接指定行3)取行列交叉值:
>>>data.loc[['A'],['b','c']] #图3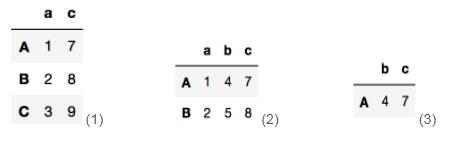
注意:
1. 区别 df.iloc()
.loc() —— 使用标签 label 作为索引取值
.iloc() —— 使用整数下标 index 作为索引取值,如上面三句可以换成以下三句,输出数据类型有不同
>>>data.iloc[:,[0,2]] # DataFrame
>>>data.iloc[[0,1]] # DataFrame
>>>data.iloc[0,[1,2]] # Series2. 对于 数字类型的变量,可以使用bool 选取行,列不能用bool,如
>>>data.loc[data.b>5] # DataFrame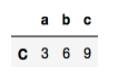
>>>data.loc[data.b>5,['c']] #DataFrame 输出为9位置的frame
>>>data.iloc[data.b.values>5,[2]] #DataFrame 输出同上,需要有 .values取值3. .ix[ ] 可以混用label和index,位置使用同 .loc[ ] .iloc[ ]
以上是“如何对pandas的行列名进行更改与数据选择”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



