前言
这几天caffe2发布了,支持移动端,我理解是类似单片机的物联网吧应该不是手机之类的,试想iphone7跑CNN,画面太美~
作为一个刚入坑的,甚至还没入坑的人,咱们还是老实研究下tensorflow吧,虽然它没有caffe好上手。tensorflow的特点我就不介绍了:
tensorflow(tf)运算流程:
tensorflow的运行流程主要有2步,分别是构造模型和训练。
在构造模型阶段,我们需要构建一个图(Graph)来描述我们的模型,tensoflow的强大之处也在这了,支持tensorboard:
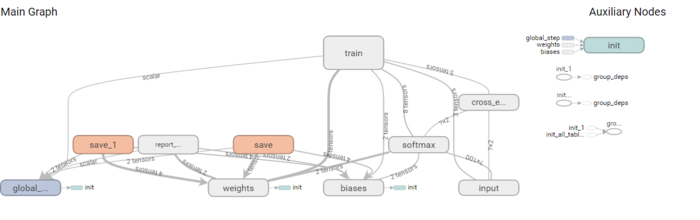
就类似这样的图,有点像流程图,这里还推荐一个google的tensoflow游乐场,很有意思。
然后到了训练阶段,在构造模型阶段是不进行计算的,只有在tensoflow.Session.run()时会开始计算。
文本分类
先给出代码,然后我们在一一做解释
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import tensorflow as tf
from collections import Counter
from sklearn.datasets import fetch_20newsgroups
def get_word_2_index(vocab):
word2index = {}
for i,word in enumerate(vocab):
word2index[word] = i
return word2index
def get_batch(df,i,batch_size):
batches = []
results = []
texts = df.data[i*batch_size : i*batch_size+batch_size]
categories = df.target[i*batch_size : i*batch_size+batch_size]
for text in texts:
layer = np.zeros(total_words,dtype=float)
for word in text.split(' '):
layer[word2index[word.lower()]] += 1
batches.append(layer)
for category in categories:
y = np.zeros((3),dtype=float)
if category == 0:
y[0] = 1.
elif category == 1:
y[1] = 1.
else:
y[2] = 1.
results.append(y)
return np.array(batches),np.array(results)
def multilayer_perceptron(input_tensor, weights, biases):
#hidden层RELU函数激励
layer_1_multiplication = tf.matmul(input_tensor, weights['h2'])
layer_1_addition = tf.add(layer_1_multiplication, biases['b1'])
layer_1 = tf.nn.relu(layer_1_addition)
layer_2_multiplication = tf.matmul(layer_1, weights['h3'])
layer_2_addition = tf.add(layer_2_multiplication, biases['b2'])
layer_2 = tf.nn.relu(layer_2_addition)
# Output layer
out_layer_multiplication = tf.matmul(layer_2, weights['out'])
out_layer_addition = out_layer_multiplication + biases['out']
return out_layer_addition
#main
#从sklearn.datas获取数据
cate = ["comp.graphics","sci.space","rec.sport.baseball"]
newsgroups_train = fetch_20newsgroups(subset='train', categories=cate)
newsgroups_test = fetch_20newsgroups(subset='test', categories=cate)
# 计算训练和测试数据总数
vocab = Counter()
for text in newsgroups_train.data:
for word in text.split(' '):
vocab[word.lower()]+=1
for text in newsgroups_test.data:
for word in text.split(' '):
vocab[word.lower()]+=1
total_words = len(vocab)
word2index = get_word_2_index(vocab)
n_hidden_1 = 100 # 一层hidden层神经元个数
n_hidden_2 = 100 # 二层hidden层神经元个数
n_input = total_words
n_classes = 3 # graphics, sci.space and baseball 3层输出层即将文本分为三类
#占位
input_tensor = tf.placeholder(tf.float32,[None, n_input],name="input")
output_tensor = tf.placeholder(tf.float32,[None, n_classes],name="output")
#正态分布存储权值和偏差值
weights = {
'h2': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h3': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
#初始化
prediction = multilayer_perceptron(input_tensor, weights, biases)
# 定义 loss and optimizer 采用softmax函数
# reduce_mean计算平均误差
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=output_tensor))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
#初始化所有变量
init = tf.global_variables_initializer()
#部署 graph
with tf.Session() as sess:
sess.run(init)
training_epochs = 100
display_step = 5
batch_size = 1000
# Training
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(len(newsgroups_train.data) / batch_size)
for i in range(total_batch):
batch_x,batch_y = get_batch(newsgroups_train,i,batch_size)
c,_ = sess.run([loss,optimizer], feed_dict={input_tensor: batch_x,output_tensor:batch_y})
# 计算平均损失
avg_cost += c / total_batch
# 每5次epoch展示一次loss
if epoch % display_step == 0:
print("Epoch:", '%d' % (epoch+1), "loss=", "{:.6f}".format(avg_cost))
print("Finished!")
# Test model
correct_prediction = tf.equal(tf.argmax(prediction, 1), tf.argmax(output_tensor, 1))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
total_test_data = len(newsgroups_test.target)
batch_x_test,batch_y_test = get_batch(newsgroups_test,0,total_test_data)
print("Accuracy:", accuracy.eval({input_tensor: batch_x_test, output_tensor: batch_y_test}))代码解释
这里我们没有进行保存模型的操作。按代码流程,我解释下各种函数和选型,其实整个代码是github的已有的,我也是学习学习~
数据获取,我们从sklearn.datas获取数据,这里有个20种类的新闻文本,我们根据每个单词来做分类:
# 计算训练和测试数据总数
vocab = Counter()
for text in newsgroups_train.data:
for word in text.split(' '):
vocab[word.lower()]+=1
for text in newsgroups_test.data:
for word in text.split(' '):
vocab[word.lower()]+=1
total_words = len(vocab)
word2index = get_word_2_index(vocab)根据每个index转为one_hot型编码,One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
def get_batch(df,i,batch_size):
batches = []
results = []
texts = df.data[i*batch_size : i*batch_size+batch_size]
categories = df.target[i*batch_size : i*batch_size+batch_size]
for text in texts:
layer = np.zeros(total_words,dtype=float)
for word in text.split(' '):
layer[word2index[word.lower()]] += 1
batches.append(layer)
for category in categories:
y = np.zeros((3),dtype=float)
if category == 0:
y[0] = 1.
elif category == 1:
y[1] = 1.
else:
y[2] = 1.
results.append(y)
return np.array(batches),np.array(results)在这段代码中根据自定义的data的数据范围,即多少个数据进行一次训练,批处理。在测试模型时,我们将用更大的批处理来提供字典,这就是为什么需要定义一个可变的批处理维度。
构造神经网络
神经网络是一个计算模型(一种描述使用机器语言和数学概念的系统的方式)。这些系统是自主学习和被训练的,而不是明确编程的。下图是传统的三层神经网络:
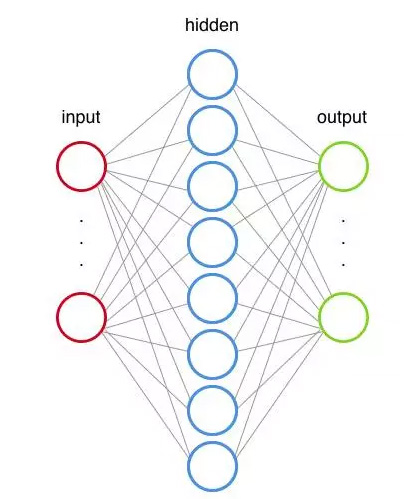
而在这个神经网络中我们的hidden层拓展到两层,这两层是做的完全相同的事,只是hidden1层的输出是hidden2的输入。
weights = {
'h2': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h3': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}在输入层需要定义第一个隐藏层会有多少节点。这些节点也被称为特征或神经元,在上面的例子中我们用每一个圆圈表示一个节点。
输入层的每个节点都对应着数据集中的一个词(之后我们会看到这是怎么运行的)
每个节点(神经元)乘以一个权重。每个节点都有一个权重值,在训练阶段,神经网络会调整这些值以产生正确的输出。
将输入乘以权重并将值与偏差相加,有点像y = Wx + b 这种linear regression。这些数据也要通过激活函数传递。这个激活函数定义了每个节点的最终输出。有很多激活函数。
这里我们的hidden层里面使用RELU,之前大多数是传统的sigmoid系来激活。
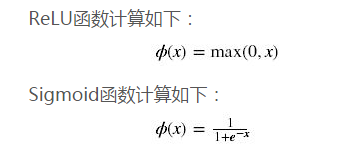
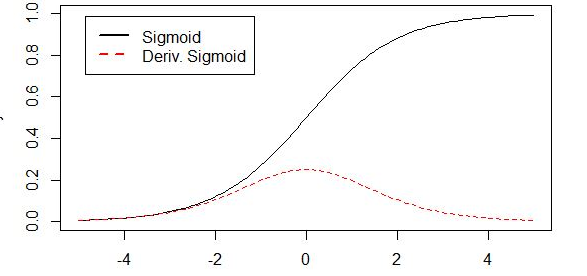
由图可知,导数从0开始很快就又趋近于0了,易造成“梯度消失”现象,而ReLU的导数就不存在这样的问题。 对比sigmoid类函数主要变化是:1)单侧抑制 2)相对宽阔的兴奋边界 3)稀疏激活性。这与人的神经皮层的工作原理接近。
为什么要加入偏移常量?
以sigmoid为例
权重w使得sigmoid函数可以调整其倾斜程度,下面这幅图是当权重变化时,sigmoid函数图形的变化情况:
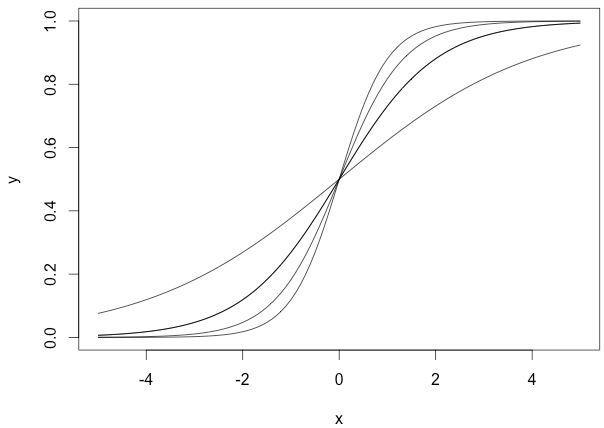
可以看到无论W怎么变化,函数都要经过(0,0.5),但实际情况下,我们可能需要在x接近0时,函数结果为其他值。
当我们改变权重w和偏移量b时,可以为神经元构造多种输出可能性,这还仅仅是一个神经元,在神经网络中,千千万万个神经元结合就能产生复杂的输出模式。
输出层的值也要乘以权重,并我们也要加上误差,但是现在激活函数不一样。
你想用分类对每一个文本进行标记,并且这些分类相互独立(一个文本不能同时属于两个分类)。
考虑到这点,你将使用 Softmax 函数而不是 ReLu 激活函数。这个函数把每一个完整的输出转换成 0 和 1 之间的值,并且确保所有单元的和等于一。
在这个神经网络中,output层中明显是3个神经元,对应着三种分本分类。
#初始化所有变量
init = tf.global_variables_initializer()
#部署 graph
with tf.Session() as sess:
sess.run(init)
training_epochs = 100
display_step = 5
batch_size = 1000
# Training
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(len(newsgroups_train.data) / batch_size)
for i in range(total_batch):
batch_x,batch_y = get_batch(newsgroups_train,i,batch_size)
c,_ = sess.run([loss,optimizer], feed_dict={input_tensor: batch_x,output_tensor:batch_y})
# 计算平均损失
avg_cost += c / total_batch
# 每5次epoch展示一次loss
if epoch % display_step == 0:
print("Epoch:", '%d' % (epoch+1), "loss=", "{:.6f}".format(avg_cost))
print("Finished!")这里的 参数设置:
为了知道网络是否正在学习,需要比较一下输出值(Z)和期望值(expected)。我们要怎么计算这个的不同(损耗)呢?有很多方法去解决这个问题。
因为我们正在进行分类任务,测量损耗的最好的方式是 交叉熵误差。
通过 TensorFlow 你将使用 tf.nn.softmax_cross_entropy_with_logits() 方法计算交叉熵误差(这个是 softmax 激活函数)并计算平均误差 (tf.reduced_mean() ) 。
通过权重和误差的最佳值,以便最小化输出误差(实际得到的值和正确的值之间的区别)。要做到这一点,将需使用 梯度下降法。更具体些是,需要使用 随机梯度下降。
对应代码:
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=output_tensor))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)tensoflow已经将这些发杂的算法封装为函数,我们只需要选取特定的函数即可。
tf.train.AdamOptimizer(learning_rate).minimize(loss) 方法是一个 语法糖,它做了两件事情:
compute_gradients(loss, <list of variables>) 计算
apply_gradients(<list of variables>) 展示
这个方法用新的值更新了所有的 tf.Variables ,因此我们不需要传递变量列表。
运行计算
Epoch: 0001 loss= 1133.908114347
Epoch: 0006 loss= 329.093700409
Epoch: 00011 loss= 111.876660109
Epoch: 00016 loss= 72.552971845
Epoch: 00021 loss= 16.673050320
........
Finished!
Accuracy: 0.81
Accuracy: 0.81 表示置信度在81%,我们通过调整参数和增加数据量(本文没做),置信度会产生变化。
结束
就是这样!使用神经网络创建了一个模型来将文本分类到不同的类别中。采用GPU或者采取分布式的TF可以提升训练速度和效率~
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



