本文实例讲述了Python爬虫爬取新浪微博内容。分享给大家供大家参考,具体如下:
用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474)
一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站。当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选。一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn。
前期准备
1.代理IP
网上有很多免费代理ip,如西刺免费代理IPhttp://www.xicidaili.com/,自己可找一个可以使用的进行测试;
2.抓包分析
通过抓包获取微博内容地址,这里不再细说,不明白的小伙伴可以自行百度查找相关资料,下面直接上完整的代码
完整代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
#定义要爬取的微博大V的微博ID
id='1259110474'
#设置代理IP
proxy_addr="122.241.72.191:808"
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)
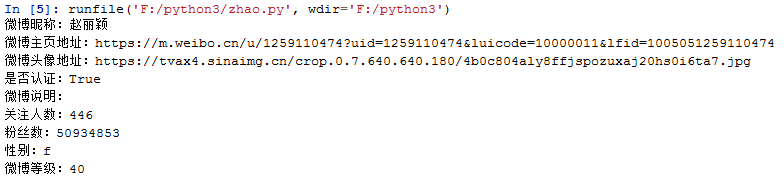
爬取结果

更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





