PythonдҪҝз”ЁеҲҶеёғејҸй”Ғзҡ„д»Јз Ғжј”зӨәзӨәдҫӢ
еңЁи®Ўз®—жңә并еҸ‘йўҶеҹҹзј–зЁӢдёӯжҖ»жҳҜдјҡдёҺй”Ғжү“дәӨйҒ“пјҢй”ҒеҸҲжңүеҫҲеӨҡз§ҚпјҢдә’ж–Ҙй”ҒгҖҒиҮӘж—Ӣй”ҒзӯүзӯүгҖӮ
й”ҒжҖ»жҳҜдјҙйҡҸзқҖзәҝзЁӢгҖҒиҝӣзЁӢиҝҷж ·зҡ„иҜҚжұҮеҮәзҺ°пјҢйҳ®дёҖеі°жңү дёҖзҜҮж–Үз« еҜ№иҝҷдәӣеҗҚиҜҚиҝӣиЎҢдәҶз®ҖеҚ•жҳ“жҮӮзҡ„и§ЈйҮҠгҖӮ
жҲ‘зҡ„зҗҶи§ЈжҳҜпјҢдҪҝз”ЁзәҝзЁӢгҖҒиҝӣзЁӢжҳҜдёәдәҶе®һзҺ°е№¶еҸ‘д»ҺиҖҢиҺ·еҫ—жҖ§иғҪзҡ„жҸҗеҚҮ(еҲ©з”ЁеӨҡж ёCPUпјҢеӨҡеҸ°жңҚеҠЎеҷЁ)пјҢдҪҶиҝҷз§Қ并еҸ‘з”ұдәҺи°ғеәҰзҡ„дёҚзЎ®е®ҡжҖ§пјҢеҫҲе®№жҳ“еҮәд№ұеӯҗпјҢдёәдәҶ(еңЁдёҖдәӣе…ұдә«иө„жәҗгҖҒе…ій”®иҠӮзӮ№дёҠ)дёҚеҮәд№ұеӯҗпјҢеҸҲйңҖиҰҒеҜ№иө„жәҗеҠ й”ҒпјҢеңЁж“ҚдҪңиҝҷдёӘиө„жәҗж—¶жҺ§еҲ¶иҝҷз§Қ并еҸ‘пјҢе°Ҷд№ұеӯҗж¶ҲзҒӯгҖӮ
еҫҲеӨҡиҜӯиЁҖйғҪжҸҗдҫӣдәҶдёҖдәӣзәҝзЁӢзә§еҲ«зҡ„й”Ғе®һзҺ°д»ҘеҸҠдёҖдәӣзӣёеә”зҡ„е·Ҙе…·пјҢдҪҶеңЁиҝӣзЁӢж–№йқўе°ұж— иғҪдёәеҠӣдәҶгҖӮиҖҢдёҖдёӘжңҚеҠЎйғЁзҪІеҲ°з”ҹдә§зҺҜеўғпјҢеҫҖеҫҖдјҡйғЁзҪІеӨҡдёӘе®һдҫӢпјҢиҝҷз§Қжғ…еҶөдёӢпјҢе°ұз»Ҹеёёдјҡз”ЁеҲ°з»ҷдёҚеҗҢиҝӣзЁӢз”Ёзҡ„й”ҒпјҢеҲҶеёғејҸй”ҒдҫҝжҳҜеңЁеҲҶеёғејҸзі»з»ҹдёӯеҜ№жҹҗе…ұдә«иө„жәҗиҝӣиЎҢеҠ й”Ғзҡ„жһ„件гҖӮ
зҺ°еңЁжқҘиҜ•зқҖеұ•зӨәдёҖдёӢеңЁPythonйЎ№зӣ®дёӯеҰӮдҪ•дҪҝз”Ёз®ҖеҚ•зҡ„еҲҶеёғејҸдә’ж–Ҙй”ҒгҖӮ
дёҚдҪҝз”ЁеҲҶеёғејҸй”ҒдјҡжҖҺж ·
е…Ҳз”ЁдёҖдёӘз®ҖеҚ•зҡ„е®һдҫӢжқҘжј”зӨәдёҖдёӢпјҢдёҚдҪҝз”ЁеҲҶеёғејҸй”ҒдјҡеҮәжҖҺж ·зҡ„д№ұеӯҗгҖӮ
еҒҮи®ҫе•ҶеҹҺзі»з»ҹиҰҒеҒҡз§’жқҖжҙ»еҠЁпјҢеңЁredisдёӯи®°еҪ•зқҖ count:1 зҡ„дҝЎжҒҜпјҢеҲ°з§’жқҖж—¶й—ҙзӮ№зҡ„ж—¶еҖҷпјҢдјҡ收еҲ°и®ёеӨҡзҡ„иҜ·жұӮпјҢиҝҷж—¶еҗ„еә”з”ЁзЁӢеәҸеҺ»жҹҘredisдёӯcountзҡ„еҖјпјҢиӢҘcountиҝҳеӨ§дәҺ0пјҢеҲҷе°Ҷcount-1пјҢиҝҷж ·е…¶д»–иҜ·жұӮе°ұдёҚеҶҚиғҪз§’жқҖеҲ°дәҶгҖӮ
# -*- coding: utf-8 -*-
import os
import arrow
import redis
from multiprocessing import Pool
HOT_KEY = 'count'
r = redis.Redis(host='localhost', port=6379)
def seckilling():
name = os.getpid()
v = r.get(HOT_KEY)
if int(v) > 0:
print name, ' decr redis.'
r.decr(HOT_KEY)
else:
print name, ' can not set redis.', v
def run_without_lock(name):
while True:
if arrow.now().second % 5 == 0:
seckilling()
return
if __name__ == '__main__':
p = Pool(16)
r.set(HOT_KEY, 1)
for i in range(16):
p.apply_async(run_without_lock, args=(i, ))
print 'now 16 processes are going to get lock!'
p.close()
p.join()
print('All subprocesses done.')
д»ҘдёҠд»Јз ҒдҪҝз”ЁеӨҡиҝӣзЁӢжқҘжЁЎд»ҝиҝҷз§Қ并еҸ‘иҜ·жұӮеңәжҷҜпјҢзЁӢеәҸејҖе§Ӣзҡ„ж—¶еҖҷе°Ҷcountи®ҫдёә1пјҢд№ӢеҗҺеҗ„иҝӣзЁӢејҖе§Ӣиҝӣе…Ҙзӯүеҫ…пјҢеҪ“з§’ж•°дёә5зҡ„ж—¶еҖҷпјҢжүҖжңүиҝӣзЁӢеҗҢж—¶еҺ»и®ҝй—®з§’жқҖеҮҪж•°пјҢжқҘзңӢдёҖдёӢж•Ҳжһңпјҡ
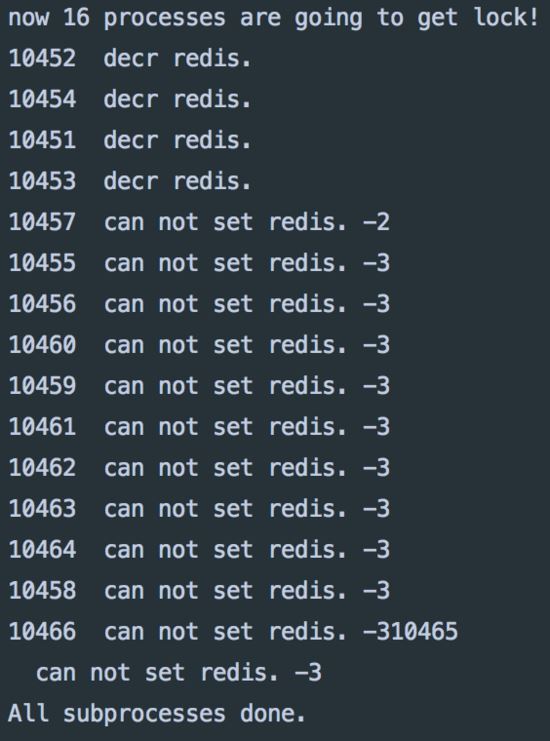
иҝҗиЎҢз»“жһң

redisжҹҘиҜўеұ•зӨә
д»ҺзЁӢеәҸжү“еҚ°дёҺжҹҘredisзҡ„з»“жһңжқҘиҜҙ并жңӘеҰӮж„ҝпјҢжң¬жқҘз§’жқҖе•Ҷе“ҒеҸӘжңүдёҖ件пјҢдҪҶеҚҙиў«жҲҗеҠҹжҠўиҙӯеҲ°дәҶ4ж¬ЎгҖӮиҝҷжҳҜз”ұдәҺеҗ„иҝӣзЁӢеңЁget countзҡ„еҖјж—¶пјҢеҜ№redisеҖјжӣҙж–°зҡ„жҢҮд»Өе·Із»ҸеҸ‘еҮәиҖҢиҝҳжңӘиҝӣиЎҢе®ҢжҜ•пјҢдјҡи®©е…¶д»–иҝӣзЁӢи®ӨдёәиҮӘе·ұеҸҜд»Ҙиҙӯеҫ—гҖӮ
иҝҷз§Қй—®йўҳеҸҜеҪ’дёә дёҚеҸҜйҮҚеӨҚиҜ» з§Қзұ»зҡ„ж•°жҚ®е№¶еҸ‘й—®йўҳгҖӮ
еңЁиҝҷз§ҚжҜ«ж— дҝқжҠӨзҡ„жғ…еҶөдёӢпјҢе…¶д»–еёёи§Ғ并еҸ‘й—®йўҳе№»иҜ»гҖҒи„ҸиҜ»гҖҒ第дёҖ第дәҢзұ»дёўеӨұжӣҙж–°зӯүйғҪжңүеҸҜиғҪеҸ‘з”ҹпјҢиҝҷйҮҢдёҚеҶҚдёҖдёҖдёҫдҫӢгҖӮ
дҪҝз”ЁZooKeeperдҪңеҲҶеёғејҸй”Ғ
дҪңдёәиҮҙеҠӣдәҺи§ЈеҶіеҲҶеёғејҸеҚҸеҗҢй—®йўҳзҡ„зҹҘеҗҚе·Ҙе…·пјҢеҲ©з”ЁzookeeperжҸҗдҫӣзҡ„APIе’Ңе®ғеҜ№дәҺиҠӮзӮ№е”ҜдёҖжҖ§дёҺйЎәеәҸдёҖиҮҙжҖ§зҡ„дҝқиҜҒеҸҜд»Ҙе®һзҺ°еҲҶејҸејҸй”ҒгҖӮ
е®һзҺ°жҖқи·ҜдёәпјҢеҗ„иҝӣзЁӢеҺ»еҲӣе»ә /exclusive_lock/lock зҡ„з»“зӮ№пјҢzookeeperдҝқиҜҒеҸӘжңүдёҖдёӘclientеҸҜд»ҘеҲӣе»әжҲҗеҠҹпјҢйӮЈд№Ҳдҫҝи®ӨдёәеҲӣе»әжҲҗеҠҹзҡ„йӮЈдёӘclientиҺ·еҫ—дәҶй”ҒпјҢеҪ“е®ғеӨ„зҗҶе®ҢдёҡеҠЎеҗҺпјҢе°ҶиҜҘnodeеҲ йҷӨпјҢе…¶д»–clientдјҡзӣ‘еҗ¬еҲ°иҝҷдёӘдәӢ件пјҢ并еҶҚж¬Ўе°қиҜ•еҲӣе»әиҜҘиҠӮзӮ№пјҢеҰӮжӯӨиҝӣиЎҢдёӢеҺ»гҖӮ
Kazoo еә“е®һзҺ°дәҶиҝҷз§ҚLockпјҢдҪҝз”Ёиө·жқҘйқһеёёз®ҖеҚ•пјҢзј–зЁӢдәәе‘ҳеҸҜд»ҘдёҚз”ЁеҶҚеҺ»иҮӘе·ұе®һзҺ°acquireпјҢreleaseзӯүй”Ғзҡ„йҖҡз”ЁжҺҘеҸЈгҖӮ
еҗҢж—¶еңЁPythonдёӯпјҢеҜ№й”Ғзҡ„дҪҝз”ЁеҫҖеҫҖеҸҜд»ҘйҖҡиҝҮдјҳйӣ…зҡ„дёҠдёӢж–Үз®ЎзҗҶеҷЁwithгҖӮ
def run_with_zk_lock(name):
zk = KazooClient()
zk.start()
lock = zk.Lock("/lockpath", "my-identifier")
while True:
if arrow.now().second % 5 == 0:
with lock:
seckilling()
return
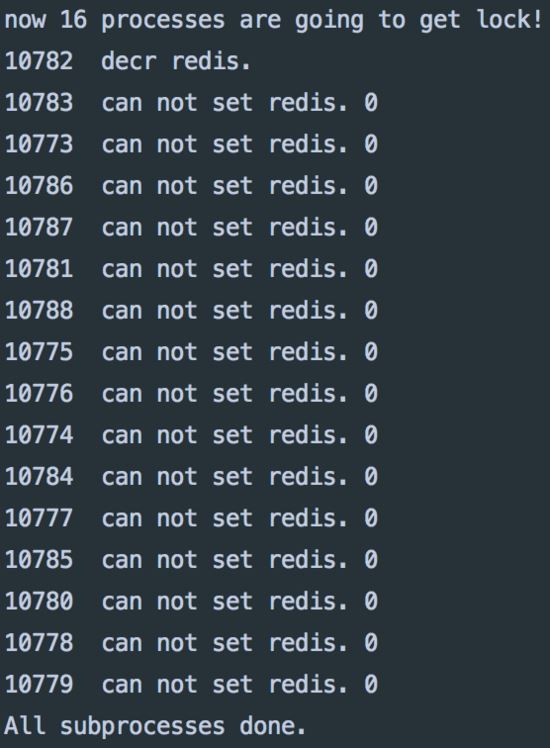
дҪҝз”Ёzkз»“жһң

redisжҹҘиҜўеұ•зӨә
еҪ“з§’жқҖеҸ‘з”ҹж—¶пјҢеҸӘжңүиҺ·еҫ—й”Ғзҡ„иҝӣзЁӢеҸҜд»ҘеҺ»иҝӣиЎҢз§’жқҖж“ҚдҪңгҖӮ
еңЁй”Ғзҡ„её®еҠ©дёӢпјҢзЁӢеәҸжҢүз…§йў„жғізҡ„ж–№ејҸиҝҗиЎҢдәҶгҖӮ
дҪҝз”ЁredisдҪңеҲҶеёғејҸй”Ғ
еңЁredisзҡ„зҪ‘з«ҷжңүдёҖзҜҮж–Үз« дё“й—Ёд»Ӣз»ҚеҰӮдҪ•дҪҝз”ЁredisдҪңдёәеҲҶеёғејҸй”ҒпјҢж–Үе°ҫиҝҳйҷ„еёҰдәҶеҜ№жӯӨж–Үз« зҡ„еҸҚеҜ№ж–Үз« д»ҘеҸҠеҶҚж¬ЎеӣһеҮ»зҡ„ж–Үз« пјҢжңүзӮ№зІҫеҪ©гҖӮ
ж–Үз« жҸҗеҲ°дәҶдёҖдёӘredlockзҡ„еҲҶеёғејҸй”Ғи®ҫи®ЎгҖӮ
и®ҫзҪ®й”Ғзҡ„redisе‘Ҫд»Өдёә SET resource_name my_random_value NX PX 30000 пјҢеҪ“еҠ NXеҸӮж•°ж—¶пјҢиӢҘresouce_nameдёҚеӯҳеңЁжүҚдјҡеҲӣе»әпјҢиӢҘдёҚеӯҳеңЁеҲҷдјҡеҗ‘clientиҝ”еӣһдёҚеҗҢзҡ„з»“жһңпјҢеҲ©з”ЁиҝҷдёӘжңәеҲ¶пјҢдҫҝеҸӘжңүдёҖдёӘclientеҸҜд»ҘsetжҲҗеҠҹпјҢе°ұеғҸдёҠйқўзҡ„zkдёҖж ·дәҶгҖӮ
дҪҶжҳҜпјҢе®һзҺ°иҝҷж ·дёҖдёӘеҲҶеёғејҸй”ҒиҝңдёҚжӯўиҝҷд№Ҳз®ҖеҚ•пјҢredis并дёҚеғҸzkдёҖж ·жҳҜдёҖдёӘеҲҶеёғејҸеҚҸеҗҢе·Ҙе…·пјҢдјҡеҗ‘clientеҒҡеҮәеҲҶеёғејҸдёӯеҗ„з§ҚдёҖиҮҙжҖ§еҸҠе®№й”ҷгҖҒеҸҜз”ЁжҖ§зҡ„дҝқиҜҒгҖӮ
redisжң¬иә«д№ҹжҳҜйӣҶзҫӨйғЁзҪІзҡ„пјҢе®ғ们д№Ӣй—ҙжңүзқҖејӮжӯҘеӨҚеҲ¶ж—¶й—ҙе·®гҖҒе®№й”ҷзӯүй—®йўҳеҸҜиғҪдјҡеҮәзҺ°пјҢиҰҒзңҹжӯЈеҒҡеҲ°иҝҷдёӘй”Ғзҡ„е®һзҺ°еңЁзәҝдёҠеӨ§и§„жЁЎеҲҶеёғејҸзі»з»ҹдёӯеҸҜз”ЁпјҢзңҹзҡ„жҳҜиҰҒиҖғиҷ‘еҗ„з§Қжғ…еҶөпјҢеҫҲдёҚе®№жҳ“гҖӮ
е…ідәҺеҰӮдҪ•еңЁиҜӯиЁҖдёҠе®һзҺ°дёҖдёӘй”Ғзҡ„жҺҘеҸЈпјҢredlockзҡ„еҺҹзҗҶдёҺд»Јз Ғе®һзҺ°пјҢд»ҘеҸҠдёҠиҝ°kazooеҢ…йҮҢе®һзҺ°lockзҡ„жәҗз ҒпјҢжҲ‘дјҡеңЁеҸҰдёҖзҜҮдё“й—Ёзҡ„ж–Үз« дёӯиҜҙдёҖдёӢгҖӮ
redlock-py еҢ…жҳҜpythonиҜӯиЁҖдёӯеҜ№дёҠиҝ°ж–Үз« зҡ„е®һзҺ°пјҢжҲ‘们зҺ°еңЁдҪҝз”Ёе®ғжқҘиҝӣиЎҢе°қиҜ•гҖӮ
rlock = RedLock([{"host": "localhost", "port": 6379, "db": 0}, ])
def run_with_redis_lock(name):
while True:
if arrow.now().second % 5 == 0:
with rlock:
seckilling()
return
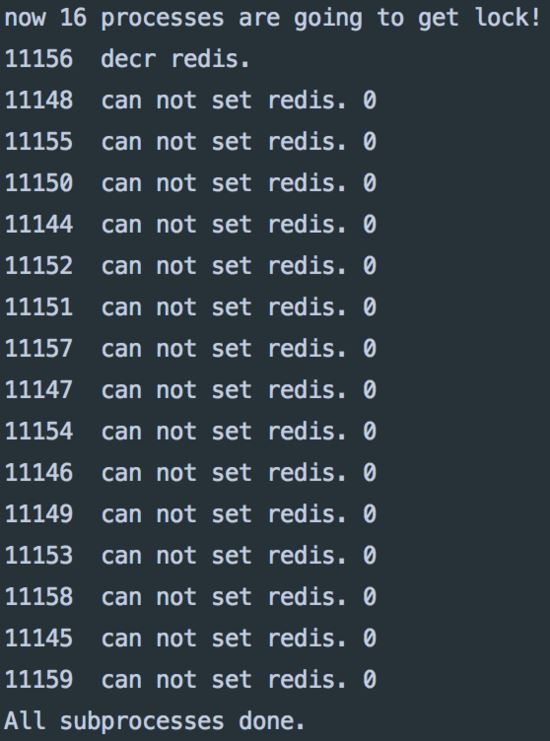
redisй”ҒиҝҗиЎҢз»“жһң
иҝҗиЎҢз»“жһңе’ҢдёҠйқўдҪҝз”ЁzkдёҖж ·пјҢз¬ҰеҗҲзЁӢеәҸи®ҫи®Ўйў„жңҹгҖӮ
д»ҘдёҠеҸӘжҳҜеҹәдәҺpythonиҜӯиЁҖзҡ„дёҖдәӣд»Јз Ғеұ•зӨәпјҢйҖҡиҝҮдҪҝз”ЁдёӨдёӘ第дёүж–№еҢ…пјҢжқҘдҪҝз”ЁеҲҶеёғејҸй”ҒжқҘйҒҝе…Қ并еҸ‘зЁӢеәҸдёӯж··д№ұзҡ„дә§з”ҹгҖӮ
дҪҶе…¶е®һиҝҷдёӯй—ҙжҳҜжңүдёҖдёӘж–ӯеұӮзҡ„пјҢеҚіпјҢиҝҷдёӨдёӘе·Ҙе…·йғҪжҳҜжҸҗдҫӣдәҶдёҖдёӘжңәеҲ¶пјҢиҖҢ并дёҚжҳҜзӣҙжҺҘеҜ№еӨ–жҸҗдҫӣдәҶж“ҚдҪңй”Ғзҡ„APIпјҢйӮЈд№ҲеҰӮдҪ•еҲ©з”ЁиҝҷдёӘжңәеҲ¶жқҘе®һзҺ°иҝҷж ·зҡ„й”ҒжӯЈжҳҜиҝҷдёӨдёӘ第дёүж–№еҒҡзҡ„дәӢжғ…гҖӮ
з®ҖеҚ•зңӢиҝҮе®ғ们е®һзҺ°зҡ„жәҗз ҒпјҢд»ҘеҸҠthreadingдёӯдёҖдәӣlockзҡ„д»Јз ҒпјҢеҸ‘зҺ°еңЁй”Ғзҡ„е®һзҺ°дёҠжҳҜжңүзқҖе…ұйҖҡд№ӢеӨ„зҡ„пјҢйғҪжңүйҖҡз”Ёзҡ„acquireдёҺreleaseж–№жі•пјҢ然еҗҺе°Ҷ enter дёҺ exit жҢҮеҗ‘еүҚйқўдёӨдёӘж–№жі•жқҘе®һзҺ°дёҠдёӢж–Үз®ЎзҗҶеҷЁwithзҡ„з”Ёжі•гҖӮ
жӯӨеӨ–пјҢиҝҳеҸҜд»ҘеҲ©з”Ёе…ізі»еһӢж•°жҚ®еә“еҰӮMySQLеӣәжңүзҡ„й”ҒжңәеҲ¶жқҘдҪңдёәеҲҶеёғејҸй”ҒпјҢдҪҶз”ұдәҺж•°жҚ®еә“еҫҖеҫҖжҳҜзі»з»ҹзҡ„瓶йўҲжүҖеңЁпјҢжІЎжңүеҝ…иҰҒдёәе®ғеј•е…ҘдёҚеҝ…иҰҒзҡ„еҺӢеҠӣгҖӮеҗҢж—¶пјҢMySQLдёӯзҡ„й”ҒгҖҒйҡ”зҰ»зә§еҲ«д№ҹжңүдёҖеӨ§е ҶеҸҜиҜҙзҡ„пјҢеңЁgithubдёҠжүҫдәҶдёҖдёӢд№ҹ并жңӘжүҫеҲ°дёҖдёӘжҲҗзҶҹзҡ„еғҸдёҠйқўзҡ„еҹәдәҺMySQLе®һзҺ°зҡ„еҜ№еӨ–жҡҙйңІй”ҒйҖҡз”ЁAPIзҡ„第дёүж–№еҢ…пјҢж•…жңӘиғҪеңЁдёҠйқўеҠ д»Ҙеұ•зӨәгҖӮ
жғіиҰҒиҜҙжё…жҘҡиҝҷдёӘдәӢжғ…并没жңүйӮЈд№Ҳе®№жҳ“пјҢд№ӢеҗҺжҲ‘дјҡе°қиҜ•жҗһжё…жҘҡеҰӮдҪ•еҶҷдёҖдёӘжҜ”иҫғең°йҒ“зҡ„й”ҒпјҢ并еҜ№дёҠйқўдёӨдёӘ第дёүж–№еҢ…зҡ„е…·дҪ“е®һзҺ°еҠ д»Ҙз ”з©¶пјҢдәүеҸ–жҠҠиҝҷдёӘж–ӯеұӮиЎҘдёҠгҖӮд№ӢеҗҺпјҢжҲ–и®ёеҸҜд»Ҙе°қиҜ•е®һзҺ°дёҖдёӢеҹәдәҺMySQLзҡ„зұ»дјјз¬¬дёүж–№еҢ…пјҢиҝҷйңҖиҰҒеҜ№MySQLзҡ„дёҖдәӣжңәеҲ¶жҗһеҫ—жӣҙеҠ жё…жҘҡжүҚиЎҢгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ





