Python Numpyдёӯж•°з»„arrayе’Ңзҹ©йҳөmatrixзҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPython Numpyдёӯж•°з»„arrayе’Ңзҹ©йҳөmatrixзҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
NumPyзҡ„дё»иҰҒеҜ№иұЎжҳҜеҗҢз§Қе…ғзҙ зҡ„еӨҡз»ҙж•°з»„гҖӮиҝҷжҳҜдёҖдёӘжүҖжңүзҡ„е…ғзҙ йғҪжҳҜдёҖз§Қзұ»еһӢгҖҒйҖҡиҝҮдёҖдёӘжӯЈж•ҙж•°е…ғз»„зҙўеј•зҡ„е…ғзҙ иЎЁж ј(йҖҡеёёжҳҜе…ғзҙ жҳҜж•°еӯ—)гҖӮ
еңЁNumPyдёӯз»ҙеәҰ(dimensions)еҸ«еҒҡиҪҙ(axes)пјҢиҪҙзҡ„дёӘж•°еҸ«еҒҡ秩(rankпјҢдҪҶжҳҜе’ҢзәҝжҖ§д»Јж•°дёӯзҡ„秩дёҚжҳҜдёҖж ·зҡ„пјҢеңЁз”ЁpythonжұӮзәҝд»Јдёӯзҡ„秩дёӯпјҢжҲ‘们用numpyеҢ…дёӯзҡ„linalg.matrix_rankж–№жі•и®Ўз®—зҹ©йҳөзҡ„秩пјҢдҫӢеӯҗеҰӮдёӢ)гҖӮ
з»“жһңжҳҜпјҡ
зәҝжҖ§д»Јж•°дёӯ秩зҡ„е®ҡд№үпјҡи®ҫеңЁзҹ©йҳөAдёӯжңүдёҖдёӘдёҚзӯүдәҺ0зҡ„rйҳ¶еӯҗејҸDпјҢдё”жүҖжңүr+1йҳ¶еӯҗејҸ(еҰӮжһңеӯҳеңЁзҡ„иҜқ)е…ЁзӯүдәҺ0пјҢйӮЈжң«Dз§°дёәзҹ©йҳөAзҡ„жңҖй«ҳйҳ¶йқһйӣ¶еӯҗејҸпјҢж•°rз§°дёәзҹ©йҳөAзҡ„秩пјҢи®°дҪңR(A)гҖӮ
numpyдёӯж•°з»„е’Ңзҹ©йҳөзҡ„еҢәеҲ«пјҡ
matrixжҳҜarrayзҡ„еҲҶж”ҜпјҢmatrixе’ҢarrayеңЁеҫҲеӨҡж—¶еҖҷйғҪжҳҜйҖҡз”Ёзҡ„пјҢдҪ з”Ёе“ӘдёҖдёӘйғҪдёҖж ·гҖӮдҪҶиҝҷж—¶еҖҷпјҢе®ҳж–№е»әи®®еӨ§е®¶еҰӮжһңдёӨдёӘеҸҜд»ҘйҖҡз”ЁпјҢйӮЈе°ұйҖүжӢ©arrayпјҢеӣ дёәarrayжӣҙзҒөжҙ»пјҢйҖҹеәҰжӣҙеҝ«пјҢеҫҲеӨҡдәәжҠҠдәҢз»ҙзҡ„arrayд№ҹзҝ»иҜ‘жҲҗзҹ©йҳөгҖӮ
дҪҶжҳҜmatrixзҡ„дјҳеҠҝе°ұжҳҜзӣёеҜ№з®ҖеҚ•зҡ„иҝҗз®—з¬ҰеҸ·пјҢжҜ”еҰӮдёӨдёӘзҹ©йҳөзӣёд№ҳпјҢе°ұжҳҜз”Ёз¬ҰеҸ·*пјҢдҪҶжҳҜarrayзӣёд№ҳдёҚиғҪиҝҷд№Ҳз”ЁпјҢеҫ—з”Ёж–№жі•.dot()
arrayзҡ„дјҳеҠҝе°ұжҳҜдёҚд»…д»…иЎЁзӨәдәҢз»ҙпјҢиҝҳиғҪиЎЁзӨә3гҖҒ4гҖҒ5...з»ҙпјҢиҖҢдё”еңЁеӨ§йғЁеҲҶPythonзЁӢеәҸйҮҢпјҢarrayд№ҹжҳҜжӣҙеёёз”Ёзҡ„гҖӮ
зҺ°еңЁжҲ‘们讨и®әnumpyзҡ„еӨҡз»ҙж•°з»„
дҫӢеҰӮпјҢеңЁ3Dз©әй—ҙдёҖдёӘзӮ№зҡ„еқҗж Ү[1, 2, 3]жҳҜдёҖдёӘ秩дёә1зҡ„ж•°з»„пјҢеӣ дёәе®ғеҸӘжңүдёҖдёӘиҪҙгҖӮйӮЈдёӘиҪҙй•ҝеәҰдёә3.еҸҲдҫӢеҰӮпјҢеңЁд»ҘдёӢдҫӢеӯҗдёӯпјҢж•°з»„зҡ„秩дёә2(е®ғжңүдёӨдёӘз»ҙеәҰ).第дёҖдёӘз»ҙеәҰй•ҝеәҰдёә2,第дәҢдёӘз»ҙеәҰй•ҝеәҰдёә3.
[[ 1., 0., 0.],
[ 0., 1., 2.]]
NumPyзҡ„ж•°з»„зұ»иў«з§°дҪңndarrayгҖӮйҖҡеёёиў«з§°дҪңж•°з»„гҖӮжіЁж„Ҹnumpy.arrayе’Ңж ҮеҮҶPythonеә“зұ»array.array并дёҚзӣёеҗҢпјҢеҗҺиҖ…еҸӘеӨ„зҗҶдёҖз»ҙж•°з»„е’ҢжҸҗдҫӣе°‘йҮҸеҠҹиғҪгҖӮжӣҙеӨҡйҮҚиҰҒndarrayеҜ№иұЎеұһжҖ§жңүпјҡ
ndarray.ndim
ж•°з»„иҪҙзҡ„дёӘж•°пјҢеңЁpythonзҡ„дё–з•ҢдёӯпјҢиҪҙзҡ„дёӘж•°иў«з§°дҪң秩
ndarray.shape
ж•°з»„зҡ„з»ҙеәҰгҖӮиҝҷжҳҜдёҖдёӘжҢҮзӨәж•°з»„еңЁжҜҸдёӘз»ҙеәҰдёҠеӨ§е°Ҹзҡ„ж•ҙж•°е…ғз»„гҖӮдҫӢеҰӮдёҖдёӘnжҺ’mеҲ—зҡ„зҹ©йҳөпјҢе®ғзҡ„shapeеұһжҖ§е°ҶжҳҜ(2,3),иҝҷдёӘе…ғз»„зҡ„й•ҝеәҰжҳҫ然жҳҜ秩пјҢеҚіз»ҙеәҰжҲ–иҖ…ndimеұһжҖ§
ndarray.size
ж•°з»„е…ғзҙ зҡ„жҖ»дёӘж•°пјҢзӯүдәҺshapeеұһжҖ§дёӯе…ғз»„е…ғзҙ зҡ„д№ҳз§ҜгҖӮ
ndarray.dtype
дёҖдёӘз”ЁжқҘжҸҸиҝ°ж•°з»„дёӯе…ғзҙ зұ»еһӢзҡ„еҜ№иұЎпјҢеҸҜд»ҘйҖҡиҝҮеҲӣйҖ жҲ–жҢҮе®ҡdtypeдҪҝз”Ёж ҮеҮҶPythonзұ»еһӢгҖӮеҸҰеӨ–NumPyжҸҗдҫӣе®ғиҮӘе·ұзҡ„ж•°жҚ®зұ»еһӢгҖӮ
ndarray.itemsize
ж•°з»„дёӯжҜҸдёӘе…ғзҙ зҡ„еӯ—иҠӮеӨ§е°ҸгҖӮдҫӢеҰӮпјҢдёҖдёӘе…ғзҙ зұ»еһӢдёәfloat64зҡ„ж•°з»„itemsizеұһжҖ§еҖјдёә8(=64/8),еҸҲеҰӮпјҢдёҖдёӘе…ғзҙ зұ»еһӢдёәcomplex32зҡ„ж•°з»„itemеұһжҖ§дёә4(=32/8).
ndarray.data
еҢ…еҗ«е®һйҷ…ж•°з»„е…ғзҙ зҡ„зј“еҶІеҢәпјҢйҖҡеёёжҲ‘们дёҚйңҖиҰҒдҪҝз”ЁиҝҷдёӘеұһжҖ§пјҢеӣ дёәжҲ‘们жҖ»жҳҜйҖҡиҝҮзҙўеј•жқҘдҪҝз”Ёж•°з»„дёӯзҡ„е…ғзҙ гҖӮ
дёҖдёӘдҫӢеӯҗ1
>>> from numpy import *
>>> a = arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int32'
>>> a.itemsize
4
>>> a.size
15
>>> type(a)
numpy.ndarray
>>> b = array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
numpy.ndarray
еҲӣе»әж•°з»„
жңүеҘҪеҮ з§ҚеҲӣе»әж•°з»„зҡ„ж–№жі•гҖӮ
дҫӢеҰӮпјҢдҪ еҸҜд»ҘдҪҝз”ЁarrayеҮҪж•°д»Һ常规зҡ„PythonеҲ—иЎЁе’Ңе…ғз»„еҲӣйҖ ж•°з»„гҖӮжүҖеҲӣе»әзҡ„ж•°з»„зұ»еһӢз”ұеҺҹеәҸеҲ—дёӯзҡ„е…ғзҙ зұ»еһӢжҺЁеҜјиҖҢжқҘгҖӮ
>>> from numpy import *
>>> a = array( [2,3,4] )
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int32')
>>> b = array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')дёҖдёӘеёёи§Ғзҡ„й”ҷиҜҜеҢ…жӢ¬з”ЁеӨҡдёӘж•°еҖјеҸӮж•°и°ғз”ЁarrayиҖҢдёҚжҳҜжҸҗдҫӣдёҖдёӘз”ұж•°еҖјз»„жҲҗзҡ„еҲ—иЎЁдҪңдёәдёҖдёӘеҸӮж•°гҖӮ
>>> a = array(1,2,3,4) # WRONG
>>> a = array([1,2,3,4]) # RIGHT
ж•°з»„е°ҶеәҸеҲ—еҢ…еҗ«еәҸеҲ—иҪ¬еҢ–жҲҗдәҢз»ҙзҡ„ж•°з»„пјҢеәҸеҲ—еҢ…еҗ«еәҸеҲ—еҢ…еҗ«еәҸеҲ—иҪ¬еҢ–жҲҗдёүз»ҙж•°з»„зӯүзӯүгҖӮ
>>> b = array( [ (1.5,2,3), (4,5,6) ] )
>>> b
array([[ 1.5, 2. , 3. ],
[ 4. , 5. , 6. ]])
ж•°з»„зұ»еһӢеҸҜд»ҘеңЁеҲӣе»әж—¶жҳҫзӨәжҢҮе®ҡ
>>> c = array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])
йҖҡеёёпјҢж•°з»„зҡ„е…ғзҙ ејҖе§ӢйғҪжҳҜжңӘзҹҘзҡ„пјҢдҪҶжҳҜе®ғзҡ„еӨ§е°Ҹе·ІзҹҘгҖӮеӣ жӯӨпјҢNumPyжҸҗдҫӣдәҶдёҖдәӣдҪҝз”ЁеҚ дҪҚз¬ҰеҲӣе»әж•°з»„зҡ„еҮҪж•°гҖӮиҝҷжңҖе°ҸеҢ–дәҶжү©еұ•ж•°з»„зҡ„йңҖиҰҒе’Ңй«ҳжҳӮзҡ„иҝҗз®—д»Јд»·гҖӮ
еҮҪж•°functionеҲӣе»әдёҖдёӘе…ЁжҳҜ0зҡ„ж•°з»„пјҢеҮҪж•°onesеҲӣе»әдёҖдёӘе…Ё1зҡ„ж•°з»„пјҢеҮҪж•°emptyеҲӣе»әдёҖдёӘеҶ…е®№йҡҸжңә并且дҫқиө–дёҺеҶ…еӯҳзҠ¶жҖҒзҡ„ж•°з»„гҖӮй»ҳи®ӨеҲӣе»әзҡ„ж•°з»„зұ»еһӢ(dtype)йғҪжҳҜfloat64гҖӮ
>>> zeros( (3,4) )
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
>>> ones( (2,3,4), dtype=int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> empty( (2,3) )
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])
дёәдәҶеҲӣе»әдёҖдёӘж•°еҲ—пјҢNumPyжҸҗдҫӣдёҖдёӘзұ»дјјarangeзҡ„еҮҪж•°иҝ”еӣһж•°з»„иҖҢдёҚжҳҜеҲ—иЎЁ:
>>> arange( 10, 30, 5 )
array([10, 15, 20, 25])
>>> arange( 0, 2, 0.3 ) # it accepts float arguments
array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
еҪ“arangeдҪҝз”Ёжө®зӮ№ж•°еҸӮж•°ж—¶пјҢз”ұдәҺжңүйҷҗзҡ„жө®зӮ№ж•°зІҫеәҰпјҢйҖҡеёёж— жі•йў„жөӢиҺ·еҫ—зҡ„е…ғзҙ дёӘж•°гҖӮеӣ жӯӨпјҢжңҖеҘҪдҪҝз”ЁеҮҪж•°linspaceеҺ»жҺҘ收жҲ‘们жғіиҰҒзҡ„е…ғзҙ дёӘж•°жқҘд»Јжӣҝз”ЁrangeжқҘжҢҮе®ҡжӯҘй•ҝгҖӮ
е…¶е®ғеҮҪж•°array, zeros, zeros_like, ones, ones_like, empty, empty_like, arange, linspace, rand, randn, fromfunction, fromfileеҸӮиҖғпјҡNumPyзӨәдҫӢ
жү“еҚ°ж•°з»„
еҪ“дҪ жү“еҚ°дёҖдёӘж•°з»„пјҢNumPyд»Ҙзұ»дјјеөҢеҘ—еҲ—иЎЁзҡ„еҪўејҸжҳҫзӨәе®ғпјҢдҪҶжҳҜе‘Ҳд»ҘдёӢеёғеұҖпјҡ
жңҖеҗҺзҡ„иҪҙд»Һе·ҰеҲ°еҸіжү“еҚ°
ж¬ЎеҗҺзҡ„иҪҙд»ҺйЎ¶еҗ‘дёӢжү“еҚ°
еү©дёӢзҡ„иҪҙд»ҺйЎ¶еҗ‘дёӢжү“еҚ°пјҢжҜҸдёӘеҲҮзүҮйҖҡиҝҮдёҖдёӘз©әиЎҢдёҺдёӢдёҖдёӘйҡ”ејҖ
дёҖз»ҙж•°з»„иў«жү“еҚ°жҲҗиЎҢпјҢдәҢз»ҙж•°з»„жҲҗзҹ©йҳөпјҢдёүз»ҙж•°з»„жҲҗзҹ©йҳөеҲ—иЎЁгҖӮ
>>> a = arange(6) # 1d array
>>> print a
[0 1 2 3 4 5]
>>>
>>> b = arange(12).reshape(4,3) # 2d array
>>> print b
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
>>>
>>> c = arange(24).reshape(2,3,4) # 3d array
>>> print c
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
жҹҘзңӢеҪўзҠ¶ж“ҚдҪңдёҖиҠӮиҺ·еҫ—жңүе…іreshapeзҡ„жӣҙеӨҡз»ҶиҠӮ
еҰӮжһңдёҖдёӘж•°з»„з”ЁжқҘжү“еҚ°еӨӘеӨ§дәҶпјҢNumPyиҮӘеҠЁзңҒз•Ҙдёӯй—ҙйғЁеҲҶиҖҢеҸӘжү“еҚ°и§’иҗҪ
>>> print arange(10000)
[ 0 1 2 ..., 9997 9998 9999]
>>>
>>> print arange(10000).reshape(100,100)
[[ 0 1 2 ..., 97 98 99]
[ 100 101 102 ..., 197 198 199]
[ 200 201 202 ..., 297 298 299]
...,
[9700 9701 9702 ..., 9797 9798 9799]
[9800 9801 9802 ..., 9897 9898 9899]
[9900 9901 9902 ..., 9997 9998 9999]]
зҰҒз”ЁNumPyзҡ„иҝҷз§ҚиЎҢдёә并ејәеҲ¶жү“еҚ°ж•ҙдёӘж•°з»„пјҢдҪ еҸҜд»Ҙи®ҫзҪ®printoptionsеҸӮж•°жқҘжӣҙж”№жү“еҚ°йҖүйЎ№гҖӮ
>>> set_printoptions(threshold='nan')
еҹәжң¬иҝҗз®—
ж•°з»„зҡ„з®—жңҜиҝҗз®—жҳҜжҢүе…ғзҙ зҡ„гҖӮж–°зҡ„ж•°з»„иў«еҲӣе»ә并且被结жһңеЎ«е……гҖӮ
>>> a = array( [20,30,40,50] )
>>> b = arange( 4 )
>>> b
array([0, 1, 2, 3])
>>> c = a-b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10*sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a<35
array([True, True, False, False], dtype=bool)
дёҚеғҸи®ёеӨҡзҹ©йҳөиҜӯиЁҖпјҢNumPyдёӯзҡ„д№ҳжі•иҝҗз®—з¬Ұ*жҢҮзӨәжҢүе…ғзҙ и®Ўз®—пјҢзҹ©йҳөд№ҳжі•еҸҜд»ҘдҪҝз”ЁdotеҮҪж•°жҲ–еҲӣе»әзҹ©йҳөеҜ№иұЎе®һзҺ°(еҸӮи§Ғж•ҷзЁӢдёӯзҡ„зҹ©йҳөз« иҠӮ)
>>> A = array( [[1,1],
... [0,1]] )
>>> B = array( [[2,0],
... [3,4]] )
>>> A*B # elementwise product
array([[2, 0],
[0, 4]])
>>> dot(A,B) # matrix product
array([[5, 4],
[3, 4]])
жңүдәӣж“ҚдҪңз¬ҰеғҸ+=е’Ң*=иў«з”ЁжқҘжӣҙж”№е·ІеӯҳеңЁж•°з»„иҖҢдёҚеҲӣе»әдёҖдёӘж–°зҡ„ж•°з»„гҖӮ
>>> a = ones((2,3), dtype=int)
>>> b = random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.69092703, 3.8324276 , 3.0114541 ],
[ 3.18679111, 3.3039349 , 3.37600289]])
>>> a += b # b is converted to integer type
>>> a
array([[6, 6, 6],
[6, 6, 6]])
еҪ“иҝҗз®—зҡ„жҳҜдёҚеҗҢзұ»еһӢзҡ„ж•°з»„ж—¶пјҢз»“жһңж•°з»„е’Ңжӣҙжҷ®йҒҚе’ҢзІҫзЎ®зҡ„е·ІзҹҘ(иҝҷз§ҚиЎҢдёәеҸ«еҒҡupcast)гҖӮ
>>> a = ones(3, dtype=int32)
>>> b = linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'
и®ёеӨҡйқһж•°з»„иҝҗз®—пјҢеҰӮи®Ўз®—ж•°з»„жүҖжңүе…ғзҙ д№Ӣе’ҢпјҢиў«дҪңдёәndarrayзұ»зҡ„ж–№жі•е®һзҺ°
>>> a = random.random((2,3))
>>> a
array([[ 0.6903007 , 0.39168346, 0.16524769],
[ 0.48819875, 0.77188505, 0.94792155]])
>>> a.sum()
3.4552372100521485
>>> a.min()
0.16524768654743593
>>> a.max()
0.9479215542670073
иҝҷдәӣиҝҗз®—й»ҳи®Өеә”з”ЁеҲ°ж•°з»„еҘҪеғҸе®ғе°ұжҳҜдёҖдёӘж•°еӯ—з»„жҲҗзҡ„еҲ—иЎЁпјҢж— е…іж•°з»„зҡ„еҪўзҠ¶гҖӮ然иҖҢпјҢжҢҮе®ҡaxisеҸӮж•°дҪ еҸҜд»Ҙеҗ§иҝҗз®—еә”з”ЁеҲ°ж•°з»„жҢҮе®ҡзҡ„иҪҙдёҠпјҡ
>>> b = arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # sum of each column
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # min of each row
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
йҖҡз”ЁеҮҪж•°(ufunc)
NumPyжҸҗдҫӣеёёи§Ғзҡ„ж•°еӯҰеҮҪж•°еҰӮsin,cosе’ҢexpгҖӮеңЁNumPyдёӯпјҢиҝҷдәӣеҸ«дҪңвҖңйҖҡз”ЁеҮҪж•°вҖқ(ufunc)гҖӮеңЁNumPyйҮҢиҝҷдәӣеҮҪж•°дҪңз”ЁжҢүж•°з»„зҡ„е…ғзҙ иҝҗз®—пјҢдә§з”ҹдёҖдёӘж•°з»„дҪңдёәиҫ“еҮәгҖӮ
>>> B = arange(3)
>>> B
array([0, 1, 2])
>>> exp(B)
array([ 1. , 2.71828183, 7.3890561 ])
>>> sqrt(B)
array([ 0. , 1. , 1.41421356])
>>> C = array([2., -1., 4.])
>>> add(B, C)
array([ 2., 0., 6.])
жӣҙеӨҡеҮҪж•° all, alltrue, any, apply along axis, argmax, argmin, argsort, average, bincount, ceil, clip, conj, conjugate, corrcoef, cov, cross, cumprod, cumsum, diff, dot, floor, inner, inv, lexsort, max, maximum, mean, median, min, minimum, nonzero, outer, prod, re, round, sometrue, sort, std, sum, trace, transpose, var, vdot, vectorize, where еҸӮи§Ғ:NumPyзӨәдҫӢ
зҙўеј•пјҢеҲҮзүҮе’Ңиҝӯд»Ј
дёҖз»ҙж•°з»„еҸҜд»Ҙиў«зҙўеј•гҖҒеҲҮзүҮе’Ңиҝӯд»ЈпјҢе°ұеғҸеҲ—иЎЁе’Ңе…¶е®ғPythonеәҸеҲ—гҖӮ
>>> a = arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # equivalent to a[0:6:2] = -1000; from start to position 6, exclusive, set every 2nd element to -1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, 216, 343, 512, 729])
>>> a[ : :-1] # reversed a
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
>>> for i in a:
... print i**(1/3.),
...
nan 1.0 nan 3.0 nan 5.0 6.0 7.0 8.0 9.0
еӨҡз»ҙж•°з»„еҸҜд»ҘжҜҸдёӘиҪҙжңүдёҖдёӘзҙўеј•гҖӮиҝҷдәӣзҙўеј•з”ұдёҖдёӘйҖ—еҸ·еҲҶеүІзҡ„е…ғз»„з»ҷеҮәгҖӮ
>>> def f(x,y):
... return 10*x+y
...
>>> b = fromfunction(f,(5,4),dtype=int)
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
еҪ“е°‘дәҺиҪҙж•°зҡ„зҙўеј•иў«жҸҗдҫӣж—¶пјҢзЎ®еӨұзҡ„зҙўеј•иў«и®ӨдёәжҳҜж•ҙдёӘеҲҮзүҮпјҡ
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])
b[i]дёӯжӢ¬еҸ·дёӯзҡ„иЎЁиҫҫејҸиў«еҪ“дҪңiе’ҢдёҖзі»еҲ—:пјҢжқҘд»ЈиЎЁеү©дёӢзҡ„иҪҙгҖӮNumPyд№ҹе…Ғи®ёдҪ дҪҝз”ЁвҖңзӮ№вҖқеғҸb[i,...]гҖӮ
зӮ№(вҖҰ)д»ЈиЎЁи®ёеӨҡдә§з”ҹдёҖдёӘе®Ңж•ҙзҡ„зҙўеј•е…ғз»„еҝ…иҰҒзҡ„еҲҶеҸ·гҖӮеҰӮжһңxжҳҜ秩дёә5зҡ„ж•°з»„(еҚіе®ғжңү5дёӘиҪҙ)пјҢйӮЈд№Ҳ:
x[1,2,вҖҰ] зӯүеҗҢдәҺ x[1,2,:,:,:],
x[вҖҰ,3] зӯүеҗҢдәҺ x[:,:,:,:,3]
x[4,вҖҰ,5,:] зӯүеҗҢ x[4,:,:,5,:].
>>> c = array( [ [[ 0, 1, 2], # a 3D array (two stacked 2D arrays) ... [ 10, 12, 13]], ... ... [[100,101,102], ... [110,112,113]] ] ) >>> c.shape (2, 2, 3) >>> c[1,...] # same as c[1,:,:] or c[1] array([[100, 101, 102], [110, 112, 113]]) >>> c[...,2] # same as c[:,:,2] array([[ 2, 13], [102, 113]])
иҝӯд»ЈеӨҡз»ҙж•°з»„жҳҜе°ұ第дёҖдёӘиҪҙиҖҢиЁҖзҡ„:2
>>> for row in b:
... print row
...
[0 1 2 3]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]
[40 41 42 43]
然иҖҢпјҢеҰӮжһңдёҖдёӘдәәжғіеҜ№жҜҸдёӘж•°з»„дёӯе…ғзҙ иҝӣиЎҢиҝҗз®—пјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁflatеұһжҖ§пјҢиҜҘеұһжҖ§жҳҜж•°з»„е…ғзҙ зҡ„дёҖдёӘиҝӯд»ЈеҷЁ:
>>> for element in b.flat:
... print element,
...
0 1 2 3 10 11 12 13 20 21 22 23 30 31 32 33 40 41 42 43
жӣҙеӨҡ[], вҖҰ, newaxis, ndenumerate, indices, index exp еҸӮиҖғNumPyзӨәдҫӢ
еҪўзҠ¶ж“ҚдҪң
жӣҙж”№ж•°з»„зҡ„еҪўзҠ¶
дёҖдёӘж•°з»„зҡ„еҪўзҠ¶з”ұе®ғжҜҸдёӘиҪҙдёҠзҡ„е…ғзҙ дёӘж•°з»ҷеҮәпјҡ
>>> a = floor(10*random.random((3,4)))
>>> a
array([[ 7., 5., 9., 3.],
[ 7., 2., 7., 8.],
[ 6., 8., 3., 2.]])
>>> a.shape
(3, 4)
дёҖдёӘж•°з»„зҡ„еҪўзҠ¶еҸҜд»Ҙиў«еӨҡз§Қе‘Ҫд»Өдҝ®ж”№пјҡ
>>> a.ravel() # flatten the array
array([ 7., 5., 9., 3., 7., 2., 7., 8., 6., 8., 3., 2.])
>>> a.shape = (6, 2)
>>> a.transpose()
array([[ 7., 9., 7., 7., 6., 3.],
[ 5., 3., 2., 8., 8., 2.]])
з”ұravel()еұ•е№ізҡ„ж•°з»„е…ғзҙ зҡ„йЎәеәҸйҖҡеёёжҳҜвҖңCйЈҺж јвҖқзҡ„пјҢе°ұжҳҜиҜҙпјҢжңҖеҸіиҫ№зҡ„зҙўеј•еҸҳеҢ–еҫ—жңҖеҝ«пјҢжүҖд»Ҙе…ғзҙ a[0,0]д№ӢеҗҺжҳҜa[0,1]гҖӮеҰӮжһңж•°з»„иў«ж”№еҸҳеҪўзҠ¶(reshape)жҲҗе…¶е®ғеҪўзҠ¶пјҢж•°з»„д»Қ然жҳҜвҖңCйЈҺж јвҖқзҡ„гҖӮNumPyйҖҡеёёеҲӣе»әдёҖдёӘд»ҘиҝҷдёӘйЎәеәҸдҝқеӯҳж•°жҚ®зҡ„ж•°з»„пјҢжүҖд»Ҙravel()е°ҶжҖ»жҳҜдёҚйңҖиҰҒеӨҚеҲ¶е®ғзҡ„еҸӮж•°3гҖӮдҪҶжҳҜеҰӮжһңж•°з»„жҳҜйҖҡиҝҮеҲҮзүҮе…¶е®ғж•°з»„жҲ–жңүдёҚеҗҢеҜ»еёёзҡ„йҖүйЎ№ж—¶пјҢе®ғеҸҜиғҪйңҖиҰҒиў«еӨҚеҲ¶гҖӮеҮҪж•°reshape()е’Ңravel()иҝҳеҸҜд»Ҙиў«еҗҢиҝҮдёҖдәӣеҸҜйҖүеҸӮж•°жһ„е»әжҲҗFORTRANйЈҺж јзҡ„ж•°з»„пјҢеҚіжңҖе·Ұиҫ№зҡ„зҙўеј•еҸҳеҢ–жңҖеҝ«гҖӮ
reshapeеҮҪж•°ж”№еҸҳеҸӮж•°еҪўзҠ¶е№¶иҝ”еӣһе®ғпјҢиҖҢresizeеҮҪж•°ж”№еҸҳж•°з»„иҮӘиә«гҖӮ
>>> a
array([[ 7., 5.],
[ 9., 3.],
[ 7., 2.],
[ 7., 8.],
[ 6., 8.],
[ 3., 2.]])
>>> a.resize((2,6))
>>> a
array([[ 7., 5., 9., 3., 7., 2.],
[ 7., 8., 6., 8., 3., 2.]])
еҰӮжһңеңЁж”№еҸҳеҪўзҠ¶ж“ҚдҪңдёӯдёҖдёӘз»ҙеәҰиў«з»ҷеҒҡ-1пјҢе…¶з»ҙеәҰе°ҶиҮӘеҠЁиў«и®Ўз®—
жӣҙеӨҡ shape, reshape, resize, ravel еҸӮиҖғNumPyзӨәдҫӢ
з»„еҗҲ(stack)дёҚеҗҢзҡ„ж•°з»„
еҮ з§Қж–№жі•еҸҜд»ҘжІҝдёҚеҗҢиҪҙе°Ҷж•°з»„е ҶеҸ еңЁдёҖиө·пјҡ
>>> a = floor(10*random.random((2,2)))
>>> a
array([[ 1., 1.],
[ 5., 8.]])
>>> b = floor(10*random.random((2,2)))
>>> b
array([[ 3., 3.],
[ 6., 0.]])
>>> vstack((a,b))
array([[ 1., 1.],
[ 5., 8.],
[ 3., 3.],
[ 6., 0.]])
>>> hstack((a,b))
array([[ 1., 1., 3., 3.],
[ 5., 8., 6., 0.]])
еҮҪж•°column_stackд»ҘеҲ—е°ҶдёҖз»ҙж•°з»„еҗҲжҲҗдәҢз»ҙж•°з»„пјҢе®ғзӯүеҗҢдёҺvstackеҜ№дёҖз»ҙж•°з»„гҖӮ
>>> column_stack((a,b)) # With 2D arrays
array([[ 1., 1., 3., 3.],
[ 5., 8., 6., 0.]])
>>> a=array([4.,2.])
>>> b=array([2.,8.])
>>> a[:,newaxis] # This allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 2.],
[ 2., 8.]])
>>> vstack((a[:,newaxis],b[:,newaxis])) # The behavior of vstack is different
array([[ 4.],
[ 2.],
[ 2.],
[ 8.]])
row_stackеҮҪж•°пјҢеҸҰдёҖж–№йқўпјҢе°ҶдёҖз»ҙж•°з»„д»ҘиЎҢз»„еҗҲжҲҗдәҢз»ҙж•°з»„гҖӮ
еҜ№йӮЈдәӣз»ҙеәҰжҜ”дәҢз»ҙжӣҙй«ҳзҡ„ж•°з»„пјҢhstackжІҝзқҖ第дәҢдёӘиҪҙз»„еҗҲпјҢvstackжІҝзқҖ第дёҖдёӘиҪҙз»„еҗҲ,concatenateе…Ғи®ёеҸҜйҖүеҸӮж•°з»ҷеҮәз»„еҗҲж—¶жІҝзқҖзҡ„иҪҙгҖӮ
Note
еңЁеӨҚжқӮжғ…еҶөдёӢпјҢr_[]е’Ңc_[]еҜ№еҲӣе»әжІҝзқҖдёҖдёӘж–№еҗ‘з»„еҗҲзҡ„ж•°еҫҲжңүз”ЁпјҢе®ғ们е…Ғи®ёиҢғеӣҙз¬ҰеҸ·(вҖң:вҖқ):
>>> r_[1:4,0,4]
array([1, 2, 3, 0, 4])
еҪ“дҪҝз”Ёж•°з»„дҪңдёәеҸӮж•°ж—¶пјҢr_е’Ңc_зҡ„й»ҳи®ӨиЎҢдёәе’Ңvstackе’ҢhstackеҫҲеғҸпјҢдҪҶжҳҜе…Ғи®ёеҸҜйҖүзҡ„еҸӮж•°з»ҷеҮәз»„еҗҲжүҖжІҝзқҖзҡ„иҪҙзҡ„д»ЈеҸ·гҖӮ
жӣҙеӨҡеҮҪж•°hstack , vstack, column_stack , row_stack , concatenate , c_ , r_ еҸӮи§ҒNumPyзӨәдҫӢ.
е°ҶдёҖдёӘж•°з»„еҲҶеүІ(split)жҲҗеҮ дёӘе°Ҹж•°з»„
дҪҝз”ЁhsplitдҪ иғҪе°Ҷж•°з»„жІҝзқҖе®ғзҡ„ж°ҙе№іиҪҙеҲҶеүІпјҢжҲ–иҖ…жҢҮе®ҡиҝ”еӣһзӣёеҗҢеҪўзҠ¶ж•°з»„зҡ„дёӘж•°пјҢжҲ–иҖ…жҢҮе®ҡеңЁе“ӘдәӣеҲ—еҗҺеҸ‘з”ҹеҲҶеүІ:
>>> a = floor(10*random.random((2,12)))
>>> a
array([[ 8., 8., 3., 9., 0., 4., 3., 0., 0., 6., 4., 4.],
[ 0., 3., 2., 9., 6., 0., 4., 5., 7., 5., 1., 4.]])
>>> hsplit(a,3) # Split a into 3
[array([[ 8., 8., 3., 9.],
[ 0., 3., 2., 9.]]), array([[ 0., 4., 3., 0.],
[ 6., 0., 4., 5.]]), array([[ 0., 6., 4., 4.],
[ 7., 5., 1., 4.]])]
>>> hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 8., 8., 3.],
[ 0., 3., 2.]]), array([[ 9.],
[ 9.]]), array([[ 0., 4., 3., 0., 0., 6., 4., 4.],
[ 6., 0., 4., 5., 7., 5., 1., 4.]])]
vsplitжІҝзқҖзәөеҗ‘зҡ„иҪҙеҲҶеүІпјҢarray splitе…Ғи®ёжҢҮе®ҡжІҝе“ӘдёӘиҪҙеҲҶеүІгҖӮ
еӨҚеҲ¶е’Ңи§Ҷеӣҫ
еҪ“иҝҗз®—е’ҢеӨ„зҗҶж•°з»„ж—¶пјҢе®ғ们зҡ„ж•°жҚ®жңүж—¶иў«жӢ·иҙқеҲ°ж–°зҡ„ж•°з»„жңүж—¶дёҚжҳҜгҖӮиҝҷйҖҡеёёжҳҜж–°жүӢзҡ„еӣ°жғ‘д№ӢжәҗгҖӮиҝҷжңүдёүз§Қжғ…еҶө:
е®Ңе…ЁдёҚжӢ·иҙқ
з®ҖеҚ•зҡ„иөӢеҖјдёҚжӢ·иҙқж•°з»„еҜ№иұЎжҲ–е®ғ们зҡ„ж•°жҚ®гҖӮ
>>> a = arange(12)
>>> b = a # no new object is created
>>> b is a # a and b are two names for the same ndarray object
True
>>> b.shape = 3,4 # changes the shape of a
>>> a.shape
(3, 4)
Python дј йҖ’дёҚе®ҡеҜ№иұЎдҪңдёәеҸӮиҖғ4пјҢжүҖд»ҘеҮҪж•°и°ғз”ЁдёҚжӢ·иҙқж•°з»„гҖӮ
>>> def f(x):
... print id(x)
...
>>> id(a) # id is a unique identifier of an object
148293216
>>> f(a)
148293216
и§Ҷеӣҫ(view)е’Ңжө…еӨҚеҲ¶
дёҚеҗҢзҡ„ж•°з»„еҜ№иұЎеҲҶдә«еҗҢдёҖдёӘж•°жҚ®гҖӮи§Ҷеӣҫж–№жі•еҲӣйҖ дёҖдёӘж–°зҡ„ж•°з»„еҜ№иұЎжҢҮеҗ‘еҗҢдёҖж•°жҚ®гҖӮ
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c is a view of the data owned by a
True
>>> c.flags.owndata
False
>>>
>>> c.shape = 2,6 # a's shape doesn't change
>>> a.shape
(3, 4)
>>> c[0,4] = 1234 # a's data changes
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])
еҲҮзүҮж•°з»„иҝ”еӣһе®ғзҡ„дёҖдёӘи§Ҷеӣҫпјҡ
>>> s = a[ : , 1:3] # spaces added for clarity; could also be written "s = a[:,1:3]"
>>> s[:] = 10 # s[:] is a view of s. Note the difference between s=10 and s[:]=10
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
ж·ұеӨҚеҲ¶
иҝҷдёӘеӨҚеҲ¶ж–№жі•е®Ңе…ЁеӨҚеҲ¶ж•°з»„е’Ңе®ғзҡ„ж•°жҚ®гҖӮ
>>> d = a.copy() # a new array object with new data is created
>>> d is a
False
>>> d.base is a # d doesn't share anything with a
False
>>> d[0,0] = 9999
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
еҮҪж•°е’Ңж–№жі•(method)жҖ»и§Ҳ
иҝҷжҳҜдёӘNumPyеҮҪж•°е’Ңж–№жі•еҲҶзұ»жҺ’еҲ—зӣ®еҪ•гҖӮиҝҷдәӣеҗҚеӯ—й“ҫжҺҘеҲ°NumPyзӨәдҫӢ,дҪ еҸҜд»ҘзңӢеҲ°иҝҷдәӣеҮҪж•°иө·дҪңз”ЁгҖӮ5
еҲӣе»әж•°з»„
arange, array, copy, empty, empty_like, eye, fromfile, fromfunction, identity, linspace, logspace, mgrid, ogrid, ones, ones_like, r , zeros, zeros_like
иҪ¬еҢ–
astype, atleast 1d, atleast 2d, atleast 3d, mat
ж“ҚдҪң
array split, column stack, concatenate, diagonal, dsplit, dstack, hsplit, hstack, item, newaxis, ravel, repeat, reshape, resize, squeeze, swapaxes, take, transpose, vsplit, vstack
иҜўй—®
all, any, nonzero, where
жҺ’еәҸ
argmax, argmin, argsort, max, min, ptp, searchsorted, sort
иҝҗз®—
choose, compress, cumprod, cumsum, inner, fill, imag, prod, put, putmask, real, sum
еҹәжң¬з»ҹи®Ў
cov, mean, std, var
еҹәжң¬зәҝжҖ§д»Јж•°
cross, dot, outer, svd, vdot
иҝӣйҳ¶
е№ҝж’ӯжі•еҲҷ(rule)
е№ҝж’ӯжі•еҲҷиғҪдҪҝйҖҡз”ЁеҮҪж•°жңүж„Ҹд№үең°еӨ„зҗҶдёҚе…·жңүзӣёеҗҢеҪўзҠ¶зҡ„иҫ“е…ҘгҖӮ
е№ҝж’ӯ第дёҖжі•еҲҷжҳҜпјҢеҰӮжһңжүҖжңүзҡ„иҫ“е…Ҙж•°з»„з»ҙеәҰдёҚйғҪзӣёеҗҢпјҢдёҖдёӘвҖң1вҖқе°Ҷиў«йҮҚеӨҚең°ж·»еҠ еңЁз»ҙеәҰиҫғе°Ҹзҡ„ж•°з»„дёҠзӣҙиҮіжүҖжңүзҡ„ж•°з»„жӢҘжңүдёҖж ·зҡ„з»ҙеәҰгҖӮ
е№ҝж’ӯ第дәҢжі•еҲҷзЎ®е®ҡй•ҝеәҰдёә1зҡ„ж•°з»„жІҝзқҖзү№ж®Ҡзҡ„ж–№еҗ‘иЎЁзҺ°ең°еҘҪеғҸе®ғжңүжІҝзқҖйӮЈдёӘж–№еҗ‘жңҖеӨ§еҪўзҠ¶зҡ„еӨ§е°ҸгҖӮеҜ№ж•°з»„жқҘиҜҙпјҢжІҝзқҖйӮЈдёӘз»ҙеәҰзҡ„ж•°з»„е…ғзҙ зҡ„еҖјзҗҶеә”зӣёеҗҢгҖӮ
еә”з”Ёе№ҝж’ӯжі•еҲҷд№ӢеҗҺпјҢжүҖжңүж•°з»„зҡ„еӨ§е°Ҹеҝ…йЎ»еҢ№й…ҚгҖӮжӣҙеӨҡз»ҶиҠӮеҸҜд»Ҙд»ҺиҝҷдёӘж–ҮжЎЈжүҫеҲ°гҖӮ
иҠұе“Ёзҡ„зҙўеј•е’Ңзҙўеј•жҠҖе·§
NumPyжҜ”жҷ®йҖҡPythonеәҸеҲ—жҸҗдҫӣжӣҙеӨҡзҡ„зҙўеј•еҠҹиғҪгҖӮйҷӨдәҶзҙўеј•ж•ҙж•°е’ҢеҲҮзүҮпјҢжӯЈеҰӮжҲ‘们д№ӢеүҚзңӢеҲ°зҡ„пјҢж•°з»„еҸҜд»Ҙиў«ж•ҙж•°ж•°з»„е’Ңеёғе°”ж•°з»„зҙўеј•гҖӮ
йҖҡиҝҮж•°з»„зҙўеј•
>>> a = arange(12)**2 # the first 12 square numbers
>>> i = array( [ 1,1,3,8,5 ] ) # an array of indices
>>> a[i] # the elements of a at the positions i
array([ 1, 1, 9, 64, 25])
>>>
>>> j = array( [ [ 3, 4], [ 9, 7 ] ] ) # a bidimensional array of indices
>>> a[j] # the same shape as j
array([[ 9, 16],
[81, 49]])
еҪ“иў«зҙўеј•ж•°з»„aжҳҜеӨҡз»ҙзҡ„ж—¶пјҢжҜҸдёҖдёӘе”ҜдёҖзҡ„зҙўеј•ж•°еҲ—жҢҮеҗ‘aзҡ„第дёҖз»ҙ[^5]гҖӮд»ҘдёӢзӨәдҫӢйҖҡиҝҮе°ҶеӣҫзүҮж Үзӯҫз”Ёи°ғиүІзүҲиҪ¬жҚўжҲҗиүІеҪ©еӣҫеғҸеұ•зӨәдәҶиҝҷз§ҚиЎҢдёәгҖӮ
>>> palette = array( [ [0,0,0], # black
... [255,0,0], # red
... [0,255,0], # green
... [0,0,255], # blue
... [255,255,255] ] ) # white
>>> image = array( [ [ 0, 1, 2, 0 ], # each value corresponds to a color in the palette
... [ 0, 3, 4, 0 ] ] )
>>> palette[image] # the (2,4,3) color image
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])
жҲ‘们д№ҹеҸҜд»Ҙз»ҷеҮәдёҚдёҚжӯўдёҖз»ҙзҡ„зҙўеј•пјҢжҜҸдёҖз»ҙзҡ„зҙўеј•ж•°з»„еҝ…йЎ»жңүзӣёеҗҢзҡ„еҪўзҠ¶гҖӮ
>>> a = arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> i = array( [ [0,1], # indices for the first dim of a
... [1,2] ] )
>>> j = array( [ [2,1], # indices for the second dim
... [3,3] ] )
>>>
>>> a[i,j] # i and j must have equal shape
array([[ 2, 5],
[ 7, 11]])
>>>
>>> a[i,2]
array([[ 2, 6],
[ 6, 10]])
>>>
>>> a[:,j] # i.e., a[ : , j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])
иҮӘ然пјҢжҲ‘们еҸҜд»ҘжҠҠiе’Ңjж”ҫеҲ°еәҸеҲ—дёӯ(жҜ”еҰӮиҜҙеҲ—иЎЁ)然еҗҺйҖҡиҝҮlistзҙўеј•гҖӮ
>>> l = [i,j]
>>> a[l] # equivalent to a[i,j]
array([[ 2, 5],
[ 7, 11]])
然иҖҢпјҢжҲ‘们дёҚиғҪжҠҠiе’Ңjж”ҫеңЁдёҖдёӘж•°з»„дёӯпјҢеӣ дёәиҝҷдёӘж•°з»„е°Ҷиў«и§ЈйҮҠжҲҗзҙўеј•aзҡ„第дёҖз»ҙгҖӮ
>>> s = array( [i,j] )
>>> a[s] # not what we want
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
----> 1 a[s]
IndexError: index (3) out of range (0<=index<2) in dimension 0
>>>
>>> a[tuple(s)] # same as a[i,j]
array([[ 2, 5],
[ 7, 11]])
еҸҰдёҖдёӘеёёз”Ёзҡ„ж•°з»„зҙўеј•з”Ёжі•жҳҜжҗңзҙўж—¶й—ҙеәҸеҲ—жңҖеӨ§еҖј6гҖӮ
>>> time = linspace(20, 145, 5) # time scale
>>> data = sin(arange(20)).reshape(5,4) # 4 time-dependent series
>>> time
array([ 20. , 51.25, 82.5 , 113.75, 145. ])
>>> data
array([[ 0. , 0.84147098, 0.90929743, 0.14112001],
[-0.7568025 , -0.95892427, -0.2794155 , 0.6569866 ],
[ 0.98935825, 0.41211849, -0.54402111, -0.99999021],
[-0.53657292, 0.42016704, 0.99060736, 0.65028784],
[-0.28790332, -0.96139749, -0.75098725, 0.14987721]])
>>>
>>> ind = data.argmax(axis=0) # index of the maxima for each series
>>> ind
array([2, 0, 3, 1])
>>>
>>> time_max = time[ ind] # times corresponding to the maxima
>>>
>>> data_max = data[ind, xrange(data.shape[1])] # => data[ind[0],0], data[ind[1],1]...
>>>
>>> time_max
array([ 82.5 , 20. , 113.75, 51.25])
>>> data_max
array([ 0.98935825, 0.84147098, 0.99060736, 0.6569866 ])
>>>
>>> all(data_max == data.max(axis=0))
True
дҪ д№ҹеҸҜд»ҘдҪҝз”Ёж•°з»„зҙўеј•дҪңдёәзӣ®ж ҮжқҘиөӢеҖјпјҡ
>>> a = arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[[1,3,4]] = 0
>>> a
array([0, 0, 2, 0, 0])
然иҖҢпјҢеҪ“дёҖдёӘзҙўеј•еҲ—иЎЁеҢ…еҗ«йҮҚеӨҚж—¶пјҢиөӢеҖјиў«еӨҡж¬Ўе®ҢжҲҗпјҢдҝқз•ҷжңҖеҗҺзҡ„еҖјпјҡ
>>> a = arange(5)
>>> a[[0,0,2]]=[1,2,3]
>>> a
array([2, 1, 3, 3, 4])
иҝҷи¶іеӨҹеҗҲзҗҶпјҢдҪҶжҳҜе°ҸеҝғеҰӮжһңдҪ жғіз”ЁPythonзҡ„+=з»“жһ„пјҢеҸҜиғҪз»“жһң并йқһдҪ жүҖжңҹжңӣпјҡ
>>> a = arange(5)
>>> a[[0,0,2]]+=1
>>> a
array([1, 1, 3, 3, 4])
еҚідҪҝ0еңЁзҙўеј•еҲ—иЎЁдёӯеҮәзҺ°дёӨж¬ЎпјҢзҙўеј•дёә0зҡ„е…ғзҙ д»…д»…еўһеҠ дёҖж¬ЎгҖӮиҝҷжҳҜеӣ дёәPythonиҰҒжұӮa+=1е’Ңa=a+1зӯүеҗҢгҖӮ
йҖҡиҝҮеёғе°”ж•°з»„зҙўеј•
еҪ“жҲ‘们дҪҝз”Ёж•ҙж•°ж•°з»„зҙўеј•ж•°з»„ж—¶пјҢжҲ‘们жҸҗдҫӣдёҖдёӘзҙўеј•еҲ—иЎЁеҺ»йҖүжӢ©гҖӮйҖҡиҝҮеёғе°”ж•°з»„зҙўеј•зҡ„ж–№жі•жҳҜдёҚеҗҢзҡ„жҲ‘们жҳҫејҸең°йҖүжӢ©ж•°з»„дёӯжҲ‘们жғіиҰҒе’ҢдёҚжғіиҰҒзҡ„е…ғзҙ гҖӮ
жҲ‘们иғҪжғіеҲ°зҡ„дҪҝз”Ёеёғе°”ж•°з»„зҡ„зҙўеј•жңҖиҮӘ然方ејҸе°ұжҳҜдҪҝз”Ёе’ҢеҺҹж•°з»„дёҖж ·еҪўзҠ¶зҡ„еёғе°”ж•°з»„гҖӮ
>>> a = arange(12).reshape(3,4)
>>> b = a > 4
>>> b # b is a boolean with a's shape
array([[False, False, False, False],
[False, True, True, True],
[True, True, True, True]], dtype=bool)
>>> a[b] # 1d array with the selected elements
array([ 5, 6, 7, 8, 9, 10, 11])
иҝҷдёӘеұһжҖ§еңЁиөӢеҖјж—¶йқһеёёжңүз”Ёпјҡ
>>> a[b] = 0 # All elements of 'a' higher than 4 become 0
>>> a
array([[0, 1, 2, 3],
[4, 0, 0, 0],
[0, 0, 0, 0]])
дҪ еҸҜд»ҘеҸӮиҖғжӣјеҫ·еҚҡйӣҶеҗҲзӨәдҫӢзңӢзңӢеҰӮдҪ•дҪҝз”Ёеёғе°”зҙўеј•жқҘз”ҹжҲҗжӣјеҫ·еҚҡйӣҶеҗҲзҡ„еӣҫеғҸгҖӮ
第дәҢз§ҚйҖҡиҝҮеёғе°”жқҘзҙўеј•зҡ„ж–№жі•жӣҙиҝ‘дјјдәҺж•ҙж•°зҙўеј•пјӣеҜ№ж•°з»„зҡ„жҜҸдёӘз»ҙеәҰжҲ‘们з»ҷдёҖдёӘдёҖз»ҙеёғе°”ж•°з»„жқҘйҖүжӢ©жҲ‘们жғіиҰҒзҡ„еҲҮзүҮгҖӮ
>>> a = arange(12).reshape(3,4)
>>> b1 = array([False,True,True]) # first dim selection
>>> b2 = array([True,False,True,False]) # second dim selection
>>>
>>> a[b1,:] # selecting rows
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[b1] # same thing
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[:,b2] # selecting columns
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
>>>
>>> a[b1,b2] # a weird thing to do
array([ 4, 10])
жіЁж„ҸдёҖз»ҙж•°з»„зҡ„й•ҝеәҰеҝ…йЎ»е’ҢдҪ жғіиҰҒеҲҮзүҮзҡ„з»ҙеәҰжҲ–иҪҙзҡ„й•ҝеәҰдёҖиҮҙпјҢеңЁд№ӢеүҚзҡ„дҫӢеӯҗдёӯпјҢb1жҳҜдёҖдёӘ秩дёә1й•ҝеәҰдёәдёүзҡ„ж•°з»„(aзҡ„иЎҢж•°)пјҢb2(й•ҝеәҰдёә4)дёҺaзҡ„第дәҢ秩(еҲ—)зӣёдёҖиҮҙгҖӮ7
ix_()еҮҪж•°
ix_еҮҪж•°еҸҜд»ҘдёәдәҶиҺ·еҫ—еӨҡе…ғз»„зҡ„з»“жһңиҖҢз”ЁжқҘз»“еҗҲдёҚеҗҢеҗ‘йҮҸгҖӮдҫӢеҰӮпјҢеҰӮжһңдҪ жғіиҰҒз”ЁжүҖжңүеҗ‘йҮҸaгҖҒbе’Ңcе…ғзҙ з»„жҲҗзҡ„дёүе…ғз»„жқҘи®Ўз®—a+b*cпјҡ
>>> a = array([2,3,4,5])
>>> b = array([8,5,4])
>>> c = array([5,4,6,8,3])
>>> ax,bx,cx = ix_(a,b,c)
>>> ax
array([[[2]],
[[3]],
[[4]],
[[5]]])
>>> bx
array([[[8],
[5],
[4]]])
>>> cx
array([[[5, 4, 6, 8, 3]]])
>>> ax.shape, bx.shape, cx.shape
((4, 1, 1), (1, 3, 1), (1, 1, 5))
>>> result = ax+bx*cx
>>> result
array([[[42, 34, 50, 66, 26],
[27, 22, 32, 42, 17],
[22, 18, 26, 34, 14]],
[[43, 35, 51, 67, 27],
[28, 23, 33, 43, 18],
[23, 19, 27, 35, 15]],
[[44, 36, 52, 68, 28],
[29, 24, 34, 44, 19],
[24, 20, 28, 36, 16]],
[[45, 37, 53, 69, 29],
[30, 25, 35, 45, 20],
[25, 21, 29, 37, 17]]])
>>> result[3,2,4]
17
>>> a[3]+b[2]*c[4]
17
дҪ д№ҹеҸҜд»Ҙе®һиЎҢеҰӮдёӢз®ҖеҢ–пјҡ
def ufunc_reduce(ufct, *vectors):
vs = ix_(*vectors)
r = ufct.identity
for v in vs:
r = ufct(r,v)
return r
然еҗҺиҝҷж ·дҪҝз”Ёе®ғпјҡ
>>> ufunc_reduce(add,a,b,c)
array([[[15, 14, 16, 18, 13],
[12, 11, 13, 15, 10],
[11, 10, 12, 14, 9]],
[[16, 15, 17, 19, 14],
[13, 12, 14, 16, 11],
[12, 11, 13, 15, 10]],
[[17, 16, 18, 20, 15],
[14, 13, 15, 17, 12],
[13, 12, 14, 16, 11]],
[[18, 17, 19, 21, 16],
[15, 14, 16, 18, 13],
[14, 13, 15, 17, 12]]])
иҝҷдёӘreduceдёҺufunc.reduce(жҜ”еҰӮиҜҙadd.reduce)зӣёжҜ”зҡ„дјҳеҠҝеңЁдәҺе®ғеҲ©з”ЁдәҶе№ҝж’ӯжі•еҲҷпјҢйҒҝе…ҚдәҶеҲӣе»әдёҖдёӘиҫ“еҮәеӨ§е°Ҹд№ҳд»Ҙеҗ‘йҮҸдёӘж•°зҡ„еҸӮж•°ж•°з»„гҖӮ8
з”Ёеӯ—з¬ҰдёІзҙўеј•
еҸӮи§ҒRecordArrayгҖӮ
зәҝжҖ§д»Јж•°
继з»ӯеүҚиҝӣпјҢеҹәжң¬зәҝжҖ§д»Јж•°еҢ…еҗ«еңЁиҝҷйҮҢгҖӮ
з®ҖеҚ•ж•°з»„иҝҗз®—
еҸӮиҖғnumpyж–Ү件еӨ№дёӯзҡ„linalg.pyиҺ·еҫ—жӣҙеӨҡдҝЎжҒҜ
>>> from numpy import *
>>> from numpy.linalg import *
>>> a = array([[1.0, 2.0], [3.0, 4.0]])
>>> print a
[[ 1. 2.]
[ 3. 4.]]
>>> a.transpose()
array([[ 1., 3.],
[ 2., 4.]])
>>> inv(a)
array([[-2. , 1. ],
[ 1.5, -0.5]])
>>> u = eye(2) # unit 2x2 matrix; "eye" represents "I"
>>> u
array([[ 1., 0.],
[ 0., 1.]])
>>> j = array([[0.0, -1.0], [1.0, 0.0]])
>>> dot (j, j) # matrix product
array([[-1., 0.],
[ 0., -1.]])
>>> trace(u) # trace
2.0
>>> y = array([[5.], [7.]])
>>> solve(a, y)
array([[-3.],
[ 4.]])
>>> eig(j)
(array([ 0.+1.j, 0.-1.j]),
array([[ 0.70710678+0.j, 0.70710678+0.j],
[ 0.00000000-0.70710678j, 0.00000000+0.70710678j]]))
Parameters:
square matrix
Returns
The eigenvalues, each repeated according to its multiplicity.
The normalized (unit "length") eigenvectors, such that the
column ``v[:,i]`` is the eigenvector corresponding to the
eigenvalue ``w[i]`` .
зҹ©йҳөзұ»
иҝҷжҳҜдёҖдёӘе…ідәҺзҹ©йҳөзұ»зҡ„з®Җзҹӯд»Ӣз»ҚгҖӮ
>>> A = matrix('1.0 2.0; 3.0 4.0')
>>> A
[[ 1. 2.]
[ 3. 4.]]
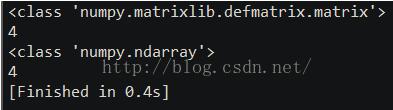
>>> type(A) # file where class is defined
>>> A.T # transpose
[[ 1. 3.]
[ 2. 4.]]
>>> X = matrix('5.0 7.0')
>>> Y = X.T
>>> Y
[[5.]
[7.]]
>>> print A*Y # matrix multiplication
[[19.]
[43.]]
>>> print A.I # inverse
[[-2. 1. ]
[ 1.5 -0.5]]
>>> solve(A, Y) # solving linear equation
matrix([[-3.],
[ 4.]])зҙўеј•пјҡжҜ”иҫғзҹ©йҳөе’ҢдәҢз»ҙж•°з»„
жіЁж„ҸNumPyдёӯж•°з»„е’Ңзҹ©йҳөжңүдәӣйҮҚиҰҒзҡ„еҢәеҲ«гҖӮNumPyжҸҗдҫӣдәҶдёӨдёӘеҹәжң¬зҡ„еҜ№иұЎпјҡдёҖдёӘNз»ҙж•°з»„еҜ№иұЎе’ҢдёҖдёӘйҖҡз”ЁеҮҪж•°еҜ№иұЎгҖӮе…¶е®ғеҜ№иұЎйғҪжҳҜе»әжһ„еңЁе®ғ们д№ӢдёҠзҡ„гҖӮзү№еҲ«зҡ„пјҢзҹ©йҳөжҳҜ继жүҝиҮӘNumPyж•°з»„еҜ№иұЎзҡ„дәҢз»ҙж•°з»„еҜ№иұЎгҖӮеҜ№ж•°з»„е’Ңзҹ©йҳөпјҢзҙўеј•йғҪеҝ…йЎ»еҢ…еҗ«еҗҲйҖӮзҡ„дёҖдёӘжҲ–еӨҡдёӘиҝҷдәӣз»„еҗҲпјҡж•ҙж•°ж ҮйҮҸгҖҒзңҒз•ҘеҸ·(ellipses)гҖҒж•ҙж•°еҲ—иЎЁ;еёғе°”еҖјпјҢж•ҙж•°жҲ–еёғе°”еҖјжһ„жҲҗзҡ„е…ғз»„пјҢе’ҢдёҖдёӘдёҖз»ҙж•ҙж•°жҲ–еёғе°”еҖјж•°з»„гҖӮзҹ©йҳөеҸҜд»Ҙиў«з”ЁдҪңзҹ©йҳөзҡ„зҙўеј•пјҢдҪҶжҳҜйҖҡеёёйңҖиҰҒж•°з»„гҖҒеҲ—иЎЁжҲ–иҖ…е…¶е®ғеҪўејҸжқҘе®ҢжҲҗиҝҷдёӘд»»еҠЎгҖӮ
еғҸе№іеёёеңЁPythonдёӯдёҖж ·пјҢзҙўеј•жҳҜд»Һ0ејҖе§Ӣзҡ„гҖӮдј з»ҹдёҠжҲ‘们用зҹ©еҪўзҡ„иЎҢе’ҢеҲ—иЎЁзӨәдёҖдёӘдәҢз»ҙж•°з»„жҲ–зҹ©йҳөпјҢе…¶дёӯжІҝзқҖ0иҪҙзҡ„ж–№еҗ‘иў«з©ҝиҝҮзҡ„з§°дҪңиЎҢпјҢжІҝзқҖ1иҪҙзҡ„ж–№еҗ‘иў«з©ҝиҝҮзҡ„жҳҜеҲ—гҖӮ9
и®©жҲ‘们еҲӣе»әж•°з»„е’Ңзҹ©йҳөз”ЁжқҘеҲҮзүҮпјҡ
>>> A = arange(12)
>>> A
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> A.shape = (3,4)
>>> M = mat(A.copy())
>>> print type(A)," ",type(M)
>>> print A
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
>>> print M
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
зҺ°еңЁпјҢи®©жҲ‘们з®ҖеҚ•зҡ„еҲҮеҮ зүҮгҖӮеҹәжң¬зҡ„еҲҮзүҮдҪҝз”ЁеҲҮзүҮеҜ№иұЎжҲ–ж•ҙж•°гҖӮдҫӢеҰӮпјҢA[:]е’ҢM[:]зҡ„жұӮеҖје°ҶиЎЁзҺ°еҫ—е’ҢPythonзҙўеј•еҫҲзӣёдјјгҖӮ然иҖҢиҰҒжіЁж„ҸеҫҲйҮҚиҰҒзҡ„дёҖзӮ№е°ұжҳҜNumPyеҲҮзүҮж•°з»„дёҚеҲӣе»әж•°жҚ®зҡ„еүҜжң¬;еҲҮзүҮжҸҗдҫӣз»ҹдёҖж•°жҚ®зҡ„и§ҶеӣҫгҖӮ
>>> print A[:]; print A[:].shape
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
(3, 4)
>>> print M[:]; print M[:].shape
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
(3, 4)
зҺ°еңЁжңүдәӣе’ҢPythonзҙўеј•дёҚеҗҢзҡ„дәҶпјҡдҪ еҸҜд»ҘеҗҢж—¶дҪҝз”ЁйҖ—еҸ·еҲҶеүІзҙўеј•жқҘжІҝзқҖеӨҡдёӘиҪҙзҙўеј•гҖӮ
>>> print A[:,1]; print A[:,1].shape
[1 5 9]
(3,)
>>> print M[:,1]; print M[:,1].shape
[[1]
[5]
[9]]
(3, 1)
жіЁж„ҸжңҖеҗҺдёӨдёӘз»“жһңзҡ„дёҚеҗҢгҖӮеҜ№дәҢз»ҙж•°з»„дҪҝз”ЁдёҖдёӘеҶ’еҸ·дә§з”ҹдёҖдёӘдёҖз»ҙж•°з»„пјҢ然иҖҢзҹ©йҳөдә§з”ҹдәҶдёҖдёӘдәҢз»ҙзҹ©йҳөгҖӮ10дҫӢеҰӮпјҢдёҖдёӘM[2,:]еҲҮзүҮдә§з”ҹдәҶдёҖдёӘеҪўзҠ¶дёә(1,4)зҡ„зҹ©йҳөпјҢзӣёжҜ”д№ӢдёӢпјҢдёҖдёӘж•°з»„зҡ„еҲҮзүҮжҖ»жҳҜдә§з”ҹдёҖдёӘжңҖдҪҺеҸҜиғҪз»ҙеәҰ11зҡ„ж•°з»„гҖӮдҫӢеҰӮпјҢеҰӮжһңCжҳҜдёҖдёӘдёүз»ҙж•°з»„пјҢC[...,1]дә§з”ҹдёҖдёӘдәҢз»ҙзҡ„ж•°з»„иҖҢC[1,:,1]дә§з”ҹдёҖдёӘдёҖз»ҙж•°з»„гҖӮд»Һиҝҷж—¶ејҖе§ӢпјҢеҰӮжһңзӣёеә”зҡ„зҹ©йҳөеҲҮзүҮз»“жһңжҳҜзӣёеҗҢзҡ„иҜқпјҢжҲ‘们е°ҶеҸӘеұ•зӨәж•°з»„еҲҮзүҮзҡ„з»“жһңгҖӮ
еҒҮеҰӮжҲ‘们жғіиҰҒдёҖдёӘж•°з»„зҡ„第дёҖеҲ—е’Ң第дёүеҲ—пјҢдёҖз§Қж–№жі•жҳҜдҪҝз”ЁеҲ—иЎЁеҲҮзүҮпјҡ
>>> A[:,[1,3]]
array([[ 1, 3],
[ 5, 7],
[ 9, 11]])
зЁҚеҫ®еӨҚжқӮзӮ№зҡ„ж–№жі•жҳҜдҪҝз”Ёtake()ж–№жі•(method):
>>> A[:,].take([1,3],axis=1)
array([[ 1, 3],
[ 5, 7],
[ 9, 11]])
еҰӮжһңжҲ‘们жғіи·іиҝҮ第дёҖиЎҢпјҢжҲ‘们еҸҜд»Ҙиҝҷж ·пјҡ
>>> A[1:,].take([1,3],axis=1)
array([[ 5, 7],
[ 9, 11]])
жҲ–иҖ…жҲ‘们仅仅дҪҝз”ЁA[1:,[1,3]]гҖӮиҝҳжңүдёҖз§Қж–№жі•жҳҜйҖҡиҝҮзҹ©йҳөеҗ‘йҮҸз§Ҝ(еҸүз§Ҝ)гҖӮ
>>> A[ix_((1,2),(1,3))]
array([[ 5, 7],
[ 9, 11]])
дёәдәҶиҜ»иҖ…зҡ„ж–№дҫҝпјҢеңЁж¬ЎеҶҷдёӢд№ӢеүҚзҡ„зҹ©йҳөпјҡ
>>> A[ix_((1,2),(1,3))]
array([[ 5, 7],
[ 9, 11]])
зҺ°еңЁи®©жҲ‘们еҒҡдәӣжӣҙеӨҚжқӮзҡ„гҖӮжҜ”еҰӮиҜҙжҲ‘们жғіиҰҒдҝқз•ҷ第дёҖиЎҢеӨ§дәҺ1зҡ„еҲ—гҖӮдёҖз§Қж–№жі•жҳҜеҲӣе»әеёғе°”зҙўеј•пјҡ
>>> A[0,:]>1
array([False, False, True, True], dtype=bool)
>>> A[:,A[0,:]>1]
array([[ 2, 3],
[ 6, 7],
[10, 11]])
е°ұжҳҜжҲ‘们жғіиҰҒзҡ„пјҒдҪҶжҳҜзҙўеј•зҹ©йҳөжІЎиҝҷд№Ҳж–№дҫҝгҖӮ
>>> M[0,:]>1
matrix([[False, False, True, True]], dtype=bool)
>>> M[:,M[0,:]>1]
matrix([[2, 3]])
иҝҷдёӘиҝҮзЁӢзҡ„й—®йўҳжҳҜз”ЁвҖңзҹ©йҳөеҲҮзүҮвҖқжқҘеҲҮзүҮдә§з”ҹдёҖдёӘзҹ©йҳө12пјҢдҪҶжҳҜзҹ©йҳөжңүдёӘж–№дҫҝзҡ„AеұһжҖ§пјҢе®ғзҡ„еҖјжҳҜж•°з»„е‘ҲзҺ°зҡ„гҖӮжүҖд»ҘжҲ‘们仅仅еҒҡд»ҘдёӢжӣҝд»Јпјҡ
>>> M[:,M.A[0,:]>1]
matrix([[ 2, 3],
[ 6, 7],
[10, 11]])
еҰӮжһңжҲ‘们жғіиҰҒеңЁзҹ©йҳөдёӨдёӘж–№еҗ‘жңүжқЎд»¶ең°еҲҮзүҮпјҢжҲ‘们еҝ…йЎ»зЁҚеҫ®и°ғж•ҙзӯ–з•ҘпјҢд»Јд№Ӣд»Ҙпјҡ
>>> A[A[:,0]>2,A[0,:]>1]
array([ 6, 11])
>>> M[M.A[:,0]>2,M.A[0,:]>1]
matrix([[ 6, 11]])
жҲ‘们йңҖиҰҒдҪҝз”Ёеҗ‘йҮҸз§Ҝix_:
>>> A[ix_(A[:,0]>2,A[0,:]>1)]
array([[ 6, 7],
[10, 11]])
>>> M[ix_(M.A[:,0]>2,M.A[0,:]>1)]
matrix([[ 6, 7],
[10, 11]])
жҠҖе·§е’ҢжҸҗзӨә
дёӢйқўжҲ‘们з»ҷеҮәз®Җзҹӯе’Ңжңүз”Ёзҡ„жҸҗзӨәгҖӮ
вҖңиҮӘеҠЁвҖқж”№еҸҳеҪўзҠ¶
жӣҙж”№ж•°з»„зҡ„з»ҙеәҰпјҢдҪ еҸҜд»ҘзңҒз•ҘдёҖдёӘе°әеҜёпјҢе®ғе°Ҷиў«иҮӘеҠЁжҺЁеҜјеҮәжқҘгҖӮ
>>> a = arange(30)
>>> a.shape = 2,-1,3 # -1 means "whatever is needed"
>>> a.shape
(2, 5, 3)
>>> a
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]],
[[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]]])
еҗ‘йҮҸз»„еҗҲ(stacking)
жҲ‘们еҰӮдҪ•з”ЁдёӨдёӘзӣёеҗҢе°әеҜёзҡ„иЎҢеҗ‘йҮҸеҲ—иЎЁжһ„е»әдёҖдёӘдәҢз»ҙж•°з»„пјҹеңЁMATLABдёӯиҝҷйқһеёёз®ҖеҚ•пјҡеҰӮжһңxе’ҢyжҳҜдёӨдёӘзӣёеҗҢй•ҝеәҰзҡ„еҗ‘йҮҸпјҢдҪ д»…д»…йңҖиҰҒеҒҡm=[x;y]гҖӮеңЁNumPyдёӯиҝҷдёӘиҝҮзЁӢйҖҡиҝҮеҮҪж•°column_stackгҖҒdstackгҖҒhstackе’ҢvstackжқҘе®ҢжҲҗпјҢеҸ–еҶідәҺдҪ жғіиҰҒеңЁйӮЈдёӘз»ҙеәҰдёҠз»„еҗҲгҖӮдҫӢеҰӮпјҡ
x = arange(0,10,2) # x=([0,2,4,6,8])
y = arange(5) # y=([0,1,2,3,4])
m = vstack([x,y]) # m=([[0,2,4,6,8],
# [0,1,2,3,4]])
xy = hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])
дәҢз»ҙд»ҘдёҠиҝҷдәӣеҮҪж•°иғҢеҗҺзҡ„йҖ»иҫ‘дјҡеҫҲеҘҮжҖӘгҖӮ
еҸӮиҖғеҶҷдёӘMatlabз”ЁжҲ·зҡ„NumPyжҢҮеҚ—并且еңЁиҝҷйҮҢж·»еҠ дҪ зҡ„ж–°еҸ‘зҺ°: )
зӣҙж–№еӣҫ(histogram)
NumPyдёӯhistogramеҮҪж•°еә”з”ЁеҲ°дёҖдёӘж•°з»„иҝ”еӣһдёҖеҜ№еҸҳйҮҸпјҡзӣҙж–№еӣҫж•°з»„е’Ңз®ұејҸеҗ‘йҮҸгҖӮжіЁж„Ҹпјҡmatplotlibд№ҹжңүдёҖдёӘз”ЁжқҘе»әз«Ӣзӣҙж–№еӣҫзҡ„еҮҪж•°(еҸ«дҪңhist,жӯЈеҰӮmatlabдёӯдёҖж ·)дёҺNumPyдёӯзҡ„дёҚеҗҢгҖӮдё»иҰҒзҡ„е·®еҲ«жҳҜpylab.histиҮӘеҠЁз»ҳеҲ¶зӣҙж–№еӣҫпјҢиҖҢnumpy.histogramд»…д»…дә§з”ҹж•°жҚ®гҖӮ
import numpy
import pylab
# Build a vector of 10000 normal deviates with variance 0.5^2 and mean 2
mu, sigma = 2, 0.5
v = numpy.random.normal(mu,sigma,10000)
# Plot a normalized histogram with 50 bins
pylab.hist(v, bins=50, normed=1) # matplotlib version (plot)
pylab.show()
# Compute the histogram with numpy and then plot it
(n, bins) = numpy.histogram(v, bins=50, normed=True) # NumPy version (no plot)
pylab.plot(.5*(bins[1:]+bins[:-1]), n)
pylab.show()
е…ідәҺвҖңPython Numpyдёӯж•°з»„arrayе’Ңзҹ©йҳөmatrixзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





