这篇文章将为大家详细讲解有关Python3如何实现图片文字识别,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定
from PIL import Image
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim')
print(text)我们以识别诗词为例
下面是我们要识别的图片

先看下效果图
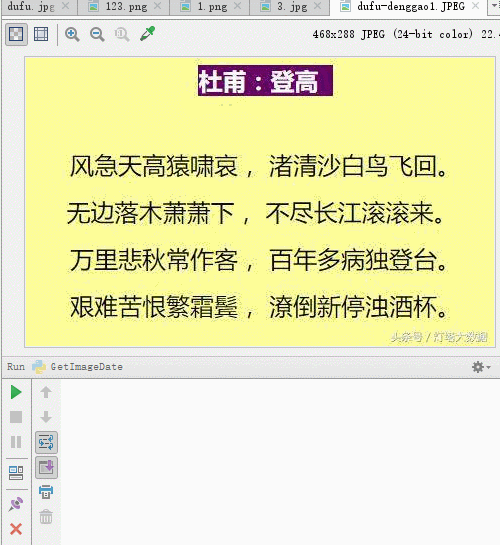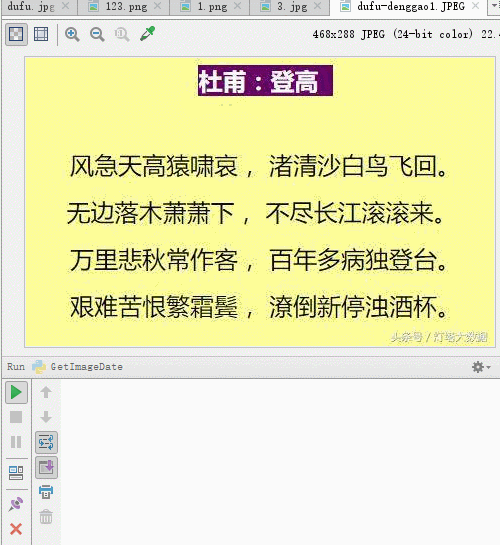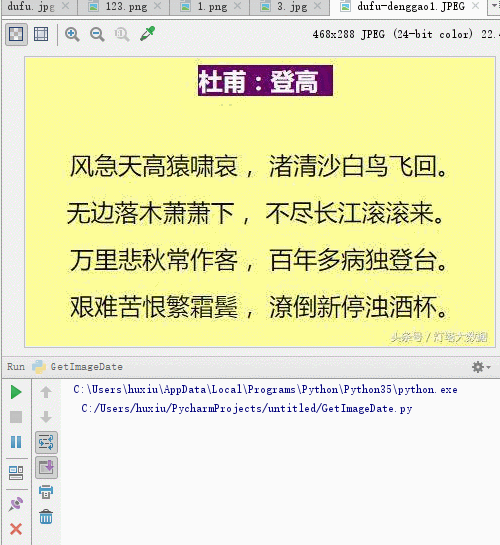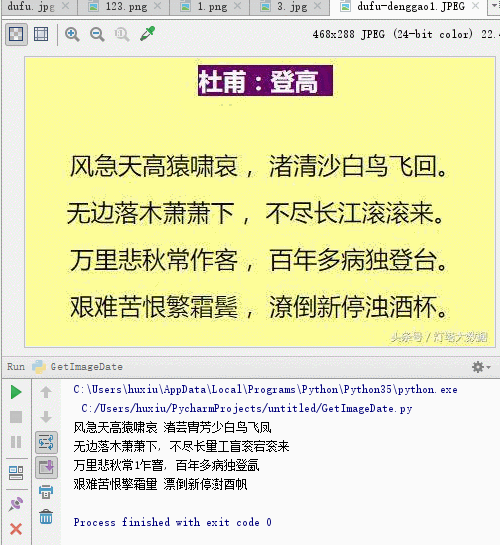
我们运行代码后识别的结果,有几个字没有正确识别,但是大多数字都能识别出来。
风急天高猿啸哀 渚芸胄芳少白鸟飞凤 无边落木萧萧下, 不尽长量工盲衮宕衮来 万里悲秋常1乍窨, 百年多病独登氤 艰难苦恨擎霜量 漂倒新停澍酉帆
一行代码就能识别图片,我们背后要做些准备工作的
这里我们需要用到两个库:pytesseract和PIL
同时我们还需要安装识别引擎tesseract-ocr
下面就来讲讲这几个库的安装,因为只有这几个库安装好以后Python才能实现一行代码实现图片文字识别
一,pytesseract和PIL的安装
安装这两个包可以借助pip
- 1,命令行安装
pip install PIL pip install pytesseract
- 2,如果你用的pycharm编辑器,就可以直接借助pycharm实现快速安装。
在pycharm的Settings设置页按照下面步骤操作
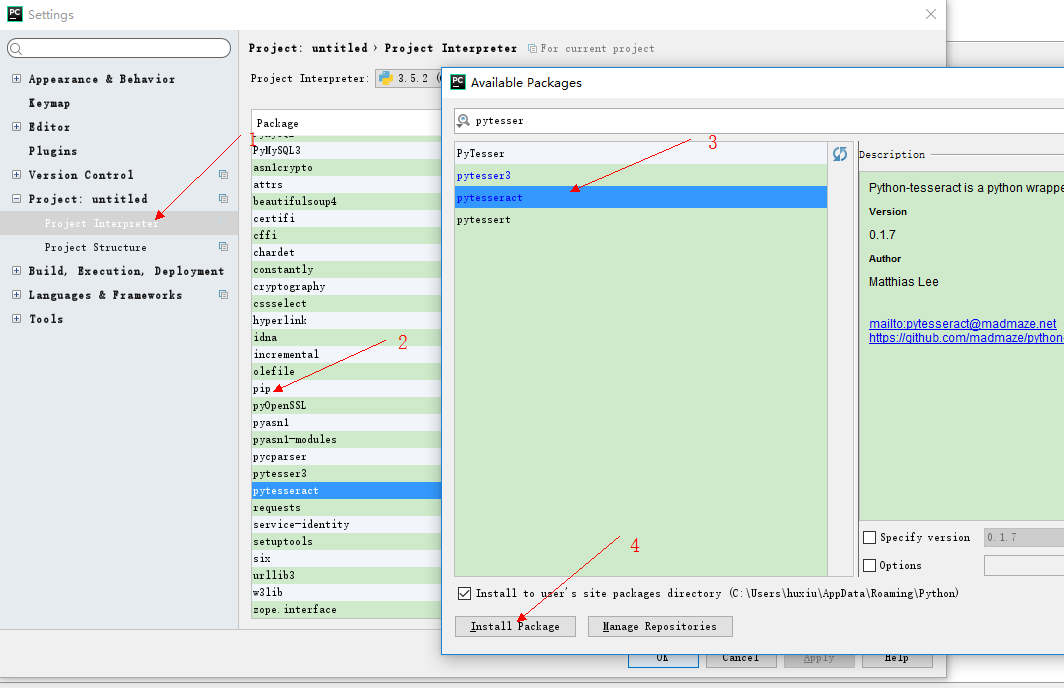
这样就能成功安装pytesseract,安装PIL只需要在上面第三步里搜索PIL并点击安装即可
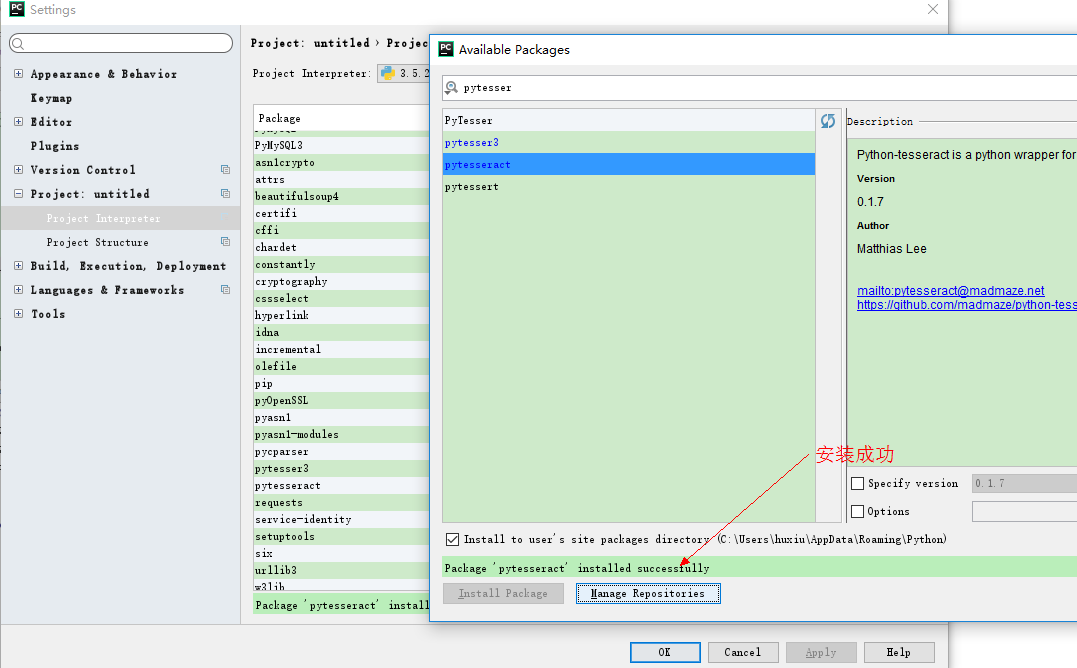
这时我们安转好了库,运行下面代码
from PIL import Image
import pytesseract
text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim')
print(text)会报下面错误,错误原因是:没有安装识别引擎tesseract-ocr
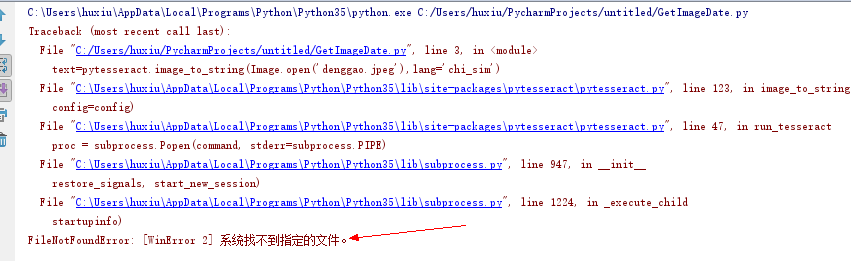
二,安装识别引擎tesseract-ocr
1.下载下面的安装包,然后直接点击安装即可
tesseract-ocr安装包和中文语言包
解压安装tesseract-ocr后做如下操作,就可以支持中文识别了。因为tesseract-ocr默认不支持中文识别。
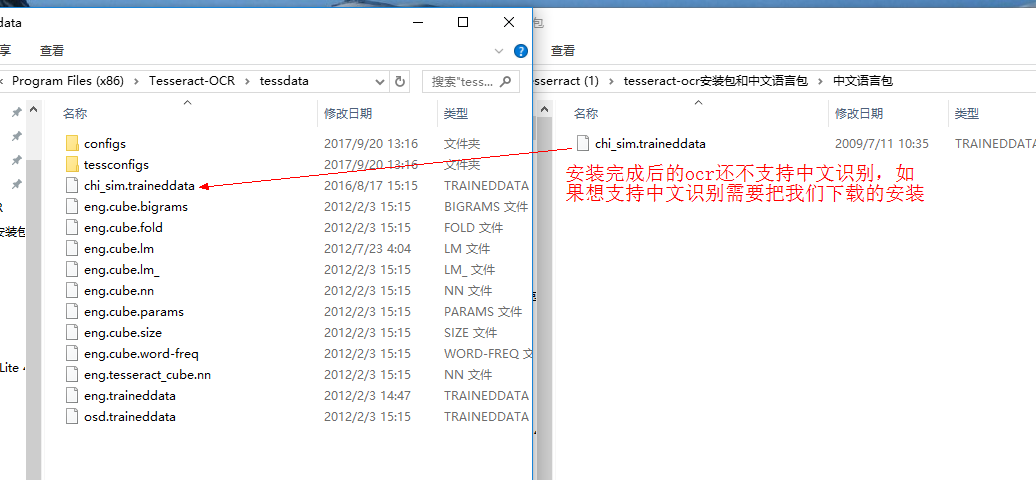
2,安装完成tesseract-ocr后,我们还需要做一下配置
在C:\Users\huxiu\AppData\Local\Programs\Python\Python35\Lib\site-packages\pytesseract找到pytesseract.py打开后做如下操作
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'也可以通过pycharm快速打开pytesseract.py


至此我们所有的配置就完成了,运行下面代码就可以把杜甫的登高这首图片诗解析成文字了
关于“Python3如何实现图片文字识别”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



