这篇文章将为大家详细讲解有关SpringBoot整合Redis实现分布式锁的方法,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
前言
最近在做分块上传的业务,使用到了Redis来维护上传过程中的分块编号。
每上传完成一个分块就获取一下文件的分块集合,加入新上传的编号,手动接口测试下是没有问题的,前端通过并发上传调用就出现问题了,并发的get再set,就会存在覆盖写现象,导致最后的分块数据不对,不能触发分块合并请求。
遇到并发二话不说先上锁,针对执行代码块加了一个JVM锁之后问题就解决了。
仔细一想还是不太对,项目是分布式部署的,做了负载均衡,一个节点的代码被锁住了,请求轮询到其他节点还是可以进行覆盖写,并没有解决到问题啊
没办法,只有用上分布式锁了。之前对于分布式锁的理论还是很熟悉的,没有比较好的应用场景就没写过具体代码,趁这个机会就学习使用一下分布式锁。
理论
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。是为了解决分布式系统中,不同的系统或是同一个系统的不同主机共享同一个资源的问题,它通常会采用互斥来保证程序的一致性
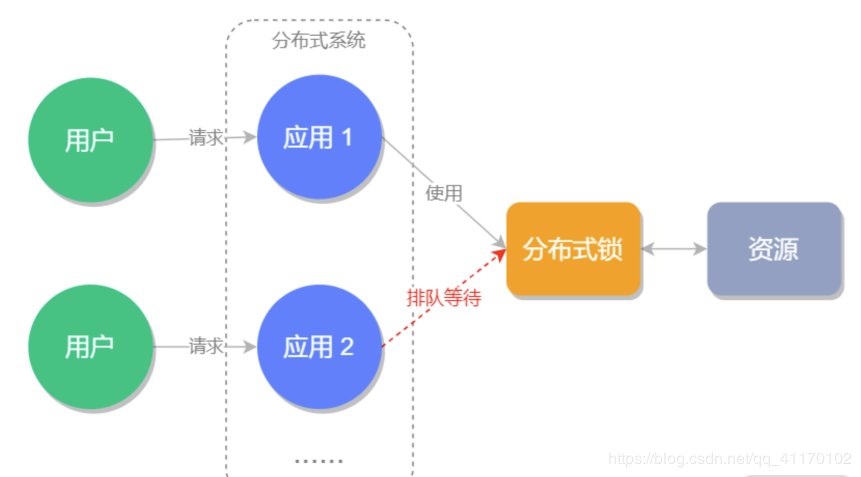
通常的实现方式有三种:
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
本文就使用的是Redis的setnx实现,如果Redis是多机版的可以去了解下Radssion,封装的就特别的好,也是官方推荐的
代码
1. 加依赖
引入Spring Boot和Redis整合的快速使用依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2. 加配置
application.properties中加入Redis连接相关配置
spring.redis.host=xxx
spring.redis.port=6379
spring.redis.database=0
spring.redis.password=xxx
spring.redis.timeout=10000
# 设置jedis连接池
spring.redis.jedis.pool.max-active=50
spring.redis.jedis.pool.min-idle=203. 重写Redis的序列化规则
默认使用的JDK的序列化,不自己设置一下Redis中的数据是看不懂的
/**
* @author Chkl
* @create 2020/6/7
* @since 1.0.0
*/
@Component
public class RedisConfig {
/**
* 改造RedisTemplate,重写序列化规则,避免存入序列化内容看不懂
* @param connectionFactory
* @return
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(connectionFactory);
// 设置key和value的序列化规则
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer(Object.class));
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}4. 如何正确的上锁
直接上代码
@Component
public class RedisLock {
@Autowired
private StringRedisTemplate redisTemplate;
private long timeout = 3000;
/**
* 上锁
* @param key 锁标识
* @param value 线程标识
* @return 上锁状态
*/
public boolean lock(String key, String value) {
long start = System.currentTimeMillis();
while (true) {
//检测是否超时
if (System.currentTimeMillis() - start > timeout) {
return false;
}
//执行set命令
Boolean absent = redisTemplate.opsForValue().setIfAbsent(key, value, timeout, TimeUnit.MILLISECONDS);//1
//是否成功获取锁
if (absent) {
return true;
}
return false;
}
}
}核心代码就是
Boolean absent = redisTemplate.opsForValue().setIfAbsent(key, value, timeout, TimeUnit.MILLISECONDS);setIfAbsent方法就相当于命令行下的Setnx方法,指定的 key 不存在时,为 key 设置指定的值
参数分别是key、value、超时时间和时间单位
5. 如何正确解锁
@Component
public class RedisLock {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private DefaultRedisScript<Long> redisScript;
private static final Long RELEASE_SUCCESS = 1L;
/**
* 解锁
* @param key 锁标识
* @param value 线程标识
* @return 解锁状态
*/
public boolean unlock(String key, String value) {
//使用Lua脚本:先判断是否是自己设置的锁,再执行删除
Long result = redisTemplate.execute(redisScript, Arrays.asList(key,value));
//返回最终结果
return RELEASE_SUCCESS.equals(result);
}
/**
* @return lua脚本
*/
@Bean
public DefaultRedisScript<Long> defaultRedisScript() {
DefaultRedisScript<Long> defaultRedisScript = new DefaultRedisScript<>();
defaultRedisScript.setResultType(Long.class);
defaultRedisScript.setScriptText("if redis.call('get', KEYS[1]) == KEYS[2] then return redis.call('del', KEYS[1]) else return 0 end");
return defaultRedisScript;
}
}解锁过程需要两步操作
1.判断操作线程是否是加锁的线程
2.如果是加锁线程,执行解锁操作
这两步操作也需要原子的进行操作,但是Redis不支持这两步的合并的操作,所以,就只有使用lua脚本实现来保证原子性咯
如果在判断是加锁的线程之后,并且执行解锁之前,锁到期了,被其他线程获得锁了,这时候再进行解锁就会解掉其他线程的锁,使得不满足解铃还须系铃人
6. 实际应用
没有使用分布式锁时的保存文件分块的代码
/**
* 保存文件分块编号到redis
* @param chunkNumber 分块号
* @param identifier 文件唯一编号
* @return 文件分块的大小
*/
@Override
public Integer saveChunk(Integer chunkNumber, String identifier) {
//从Redis获取已经存在的分块编号集合
Set<Integer> oldChunkNumber = (Set<Integer>) JSON.parseObject(redisOperator.get("chunkNumberList_"+identifier),Set.class);
//如果不存在分块集合,创建一个集合
if (Objects.isNull(oldChunkNumber)) {
Set<Integer> newChunkNumber = new HashSet<>();
newChunkNumber.add(chunkNumber);
redisOperator.set("chunkNumberList_"+identifier, JSON.toJSONString(newChunkNumber),36000);
return newChunkNumber.size();
//如果分块集合已经存在了,就添加一个编号
} else {
oldChunkNumber.add(chunkNumber);
redisOperator.set("chunkNumberList_"+identifier, JSON.toJSONString(oldChunkNumber),36000);
return oldChunkNumber.size();
}
}存在的问题是:当并发的请求进来之后,可能获取同一个状态的集合进行修改,修改后直接写入,造成同一个状态获得的集合操作线程覆盖写的现象
使用分布式锁保证同时只能有一个线程能获取到集合并进行修改,避免了覆盖写现象
使用分布式锁代码
/**
* 保存文件分块编号到redis
* @param chunkNumber 分块号
* @param identifier 文件唯一编号
* @return 文件分块的大小
*/
@Override
public Integer saveChunk(Integer chunkNumber, String identifier) {
//通过UUID生成一个请求线程识别标志作为锁的value
String threadUUID = CoreUtil.getUUID();
//上锁,以共享资源标识:文件唯一编号,作为key,以线程标识UUID作为value
redisLock.lock(identifier,threadUUID);
//从Redis获取已经存在的分块编号集合
Set<Integer> oldChunkNumber = (Set<Integer>) JSON.parseObject(redisOperator.get("chunkNumberList_"+identifier),Set.class);
//如果不存在分块集合,创建一个集合
if (Objects.isNull(oldChunkNumber)) {
Set<Integer> newChunkNumber = new HashSet<>();
newChunkNumber.add(chunkNumber);
redisOperator.set("chunkNumberList_"+identifier, JSON.toJSONString(newChunkNumber),36000);
//解锁
redisLock.unlock(identifier,threadUUID);
return newChunkNumber.size();
//如果分块集合已经存在了,就添加一个编号
} else {
oldChunkNumber.add(chunkNumber);
redisOperator.set("chunkNumberList_"+identifier, JSON.toJSONString(oldChunkNumber),36000);
//解锁
redisLock.unlock(identifier,threadUUID);
return oldChunkNumber.size();
}
}代码中使用的共享资源标识是文件唯一编号identifier,它能标识加锁代码段中的唯一资源,即key为"chunkNumberList_"+identifier的集合
代码中使用的线程唯一标识是UUID,能保证加锁和解锁时获取的标识不会重复
关于SpringBoot整合Redis实现分布式锁的方法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



