写在前面
拉勾网于 2019 年 3 月份开始尝试将生产环境的业务从 UHost 迁移到 UK8S,截至 2019 年 9 月份,QA 环境的大部分业务模块已经完成容器化改造,生产环境中,后台管理服务已全部迁移到 UK8S,部分业务模块也已完成容器化。迁移过程遇到很多问题,也积累了一些实践经验,同时深刻体会到 K8S 给企业带来的好处,像资源使用率的提升,运维效率的提升,以及由于环境一致性带来的业务迭代的加速。
本文从拉勾网的业务架构、日志采集、监控、服务暴露 / 调用等方面介绍了其基于 UK8S 的容器化改造实践。
业务架构
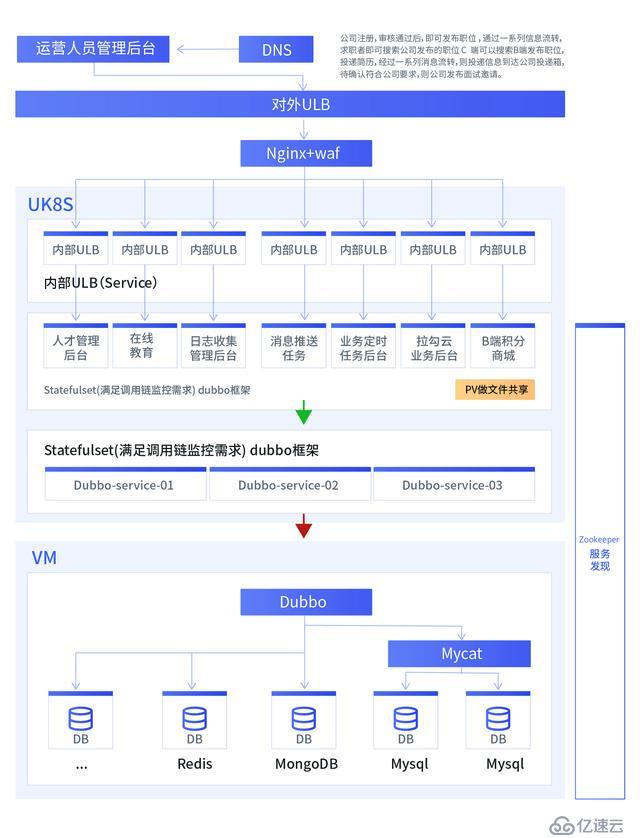
如上图所示,拉勾网目前迁移到 UK8S 中的业务以后台管理服务为主,不过其依赖的基础组件部分依然部署在 UHost,得益于 UK8S 扁平化的网络架构,Pod 与 VM 可互联互通,因此在将业务迁移到 UK8S 的过程中并不需要对业务架构做改动。
所有容器化的业务,均采用 StatefulSet 的方式来管理,而没有使用 Deployment,一是因为 StatefulSet 的 Pod 名称固定,通过配置中心做配置文件的下发容易处理,而基于 Deployment 做配置下发的话,不好做有状态发布。二是 StatefulSet 调用链条非常固定,通过调用链监控可以快速排查出是哪个 Pod 出现问题,清晰明了。
日志采集
在容器化之前,拉勾网的业务日志都是分别写入到 VM 本地的日志文件。但随着业务迁移至 UK8S,由于 Pod(应用)与 VM 的关系并非固定,一旦 Pod 被调度到其他 VM,则会导致应用日志也随之散落在不同的 VM,不便于统一采集,因此容器化部分的应用日志选择输出到统一的日志平台系统,不保留在 VM 本地。
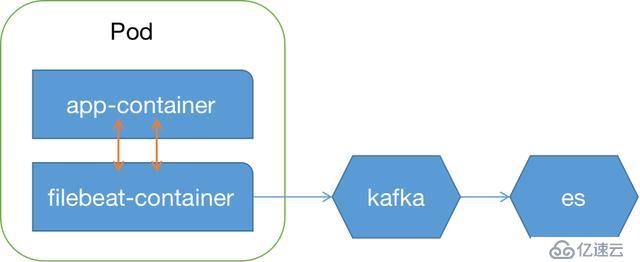
日志的收集方案,拉勾网选择的是 Sidecar 模式,每个业务 pod 中建一个 filebeat 容器,应用容器与 filebeat 容器共享 emptyDir 日志目录,filebeat 容器负责收集主容器日志并传输到 Kafka。
选择这个方案的原因是应用程序的日志依然可以输出到文件,不需要改造成 stdout 和 stderr,减小业务迁移到 UK8S 的负担,而 filebeat 作为一个轻量级的采集工具,也不会消耗太多的资源。另外 SideCar 方式相对于 DaemonSet 方式灵活性也更高,适合于大型、混合集群,且可以做到租户隔离,不同应用程序的日志可以输出到不同日志系统。
监控方案
在监控方案的选择上,拉勾网根据自身的情况,针对集群和业务使用了两套不同的方案,分别是由 UCloud 搭建的 Prometheus 监控系统和用户自研的监控系统。
K8S 集群层面选择使用了 Prometheus。集群层面的监控又分为 Node、K8S 基础组件、K8S 资源对象三大类。
对于 Node 的监控,Prometheus 提供了 node-exporter,可采集到 CPU、内存、磁盘 IO、磁盘使用率、网络包量、带宽等数据;
K8S 基础组件类的 kubelet、kube-apiserver、kube-controller-manager 和 kube-scheduler 等,都提供了 metrics 接口曝光(暴露) 自身的运行时的监控数据,这些数据都可被部署在 K8S 集群中的 Prometheus 直接拉取到;
另外结合 cadvisor 和 kube-state-metrics ,可直接采集到 K8S 中 Pod 的 CPU、内存、磁盘 IO、网络 IO 等数据。这里值得提一下由 CoreOS 开源的 Kube-Prometheus 项目,极大简化了 Prometheus 的安装部署运维工作,UCloud 也提供了适配 UK8S 的分支版本。
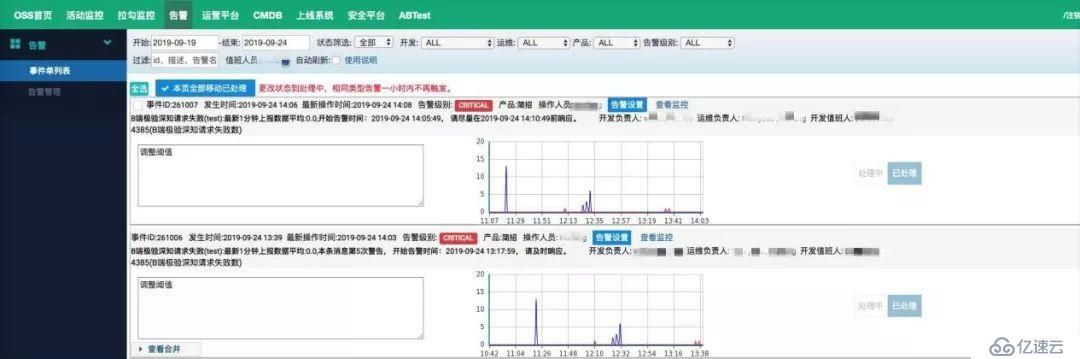
而业务监控层面,拉勾网沿用了一套之前自研的监控系统,除了负责采集自定义的监控数据外,还负责监控整体调用链的健康情况。其原理跟 Prometheus 类似,应用程序需嵌入 SDK,通过 UDP 协议上报给收集端,收集端将数据直接存入 OpenTSDB,然后有一个展示模块(类似 Grafana)来展现 OpenTSDB 数据。另外告警模块,如果发现监控项高于阈值,展示模块就给告警模块发送告警,并生成事件单 push 给对应的负责人。
服务暴露 / 调用
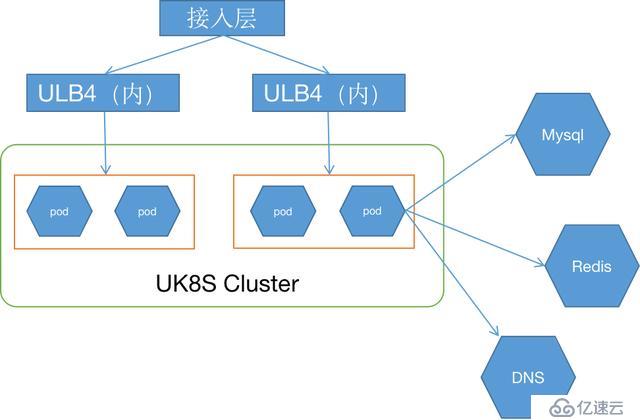
K8S 的服务暴露以及服务间的调用是一个很重要的问题,特别是拉勾网这种 VM 和 K8S 混合部署的架构,针对此问题,社区也有很多方案,类似 LoadBalancer、Ingress 等,这里拉勾网直接使用了 UK8S 的自带 LoadBalancer 方案,通过 UCloud 的内网 ULB4 对内暴露服务,操作简单,稳定性也较高。
而集群内部的服务间调用则是基于 ZK/Eureka 的服务注册与发现,与之前在 VM 环境一致,未做改造。
另外拉勾网还有大量的基础服务像 zk、Kafka、Redis、MySQL,为了提升服务间调用的可靠性,由于应用程序都是通过域名来连接这些服务的,因此拉勾网在 UHost 环境下基于 CoreDNS 部署了一套 DNS 服务。容器化的服务以及 VM 内的服务,都通过这套 DNS 服务实现域名统一解析,从而解决了服务间调用的可靠性问题。
配置中心
配置文件的管理和下发,拉勾网采用的统一配置中心,基于百度 Disconf 做了二次开发,这样就可以将 db 等连接信息等做一次隔离,根据不同的主机名及 namespace 做下发,这也就是 K8S 资源类型使用 StatefulSet 的原因了。
版本发布的配置文件通过 Git 来统一管理,并没有使用 ConfigMap,这个一方面是考虑到 ConfigMap 过大对集群的性能造成影响,另一方面也是与 VM 环境保持一致。
持续交付
拉勾网的 CI/CD 运转在 4 套不同的环境下,分别是研发环境、测试环境、 预发布环境(线上验证环境) 、正式环境。预发布和正式环境都运行在 UCloud 的 UK8S 中,通过 Namespace 隔离,确保了环境的一致性。
此外,拉勾网还有一套自研的 VM 环境的业务发布系统,不过这套发布系统未适配容器环境。而在 K8S 环境下,采用 Jenkins 做过渡,统一使用 pipeline 做发布流水线。目前正在改造老的业务发布系统,兼容 K8S 环境,统一全公司的业务发布流程。
下一步计划
目前拉勾网正在测试 HPA(Horizontal Pod Autoscaler)和 CA(Cluster Autoscaler),计划在生产环境逐步引入自动伸缩,减少人工的伸缩容行为,希望借此能降低 IT 成本,并减少重复性的工作。另外除了基础组件类的服务,像 MySQL、Kafka、大数据集群等会继续使用 UHost 外,其他服务拉勾网计划都将逐步迁移到 UK8S 中。
关于 UK8S
UK8S 是一项基于 Kubernetes 的容器管理服务,用户可以在 UK8S 上部署、管理、扩展容器化应用,而无需关心 Kubernetes 集群自身的搭建及维护等运维类工作。UK8S 完全兼容原生的 Kubernetes API,以 UCloud 私有网络为基础,并整合了 ULB、UDisk、EIP、VPC 等云产品。欢迎点击 “https://www.ucloud.cn/site/product/uk8s.html” 了解 UK8S 产品详情。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





