本文介绍了非易失性内存在阿里巴巴集团生产环境的首次应用:线上运行的情况;使用NVM遇到的问题和优化的过程;最后,总结性地给出了基于NVM构建缓存服务的设计要点,希望这些实践总结能对大家的工作有所启发。

简介
Tair MDB是阿里巴巴生态系统内广泛使用的缓存服务,它采用非易失性内存 Non-volatile memory (NVM)作为DRAM的补充,辅助DRAM作为后端存储介质,从天猫618购物节开始在生产环境上线灰度,经历了2次全链路压测,至今运行稳定。在使用NVM的过程中,Tair MDB遇到了写不均衡、锁开销等问题,经过优化之后取得了非常显著的效果。
通过这一系列优化工作和生产环境的实践,Tair工程团队总结出了一些在Non-volatile memory (NVM) / Persistent memory (PMEM)上实现缓存服务的设计准则,相信这些准则对其它有意愿使用Non-volatile memory来进行优化的产品会非常有指导意义。
背景
Tair Mdb主要服务于缓存场景,在阿里巴巴集团内部有着大量的部署和使用。随着用户态网络协议栈、无锁数据结构等特性的引入,单机QPS极限能力已经达到了1000w+的级别。Tair Mdb所有的数据都是存储在内存中,随着单机QPS极限能力的上升,内存容量逐渐成为限制集群规模的主要因素。
NVM产品单根DIMM的容量相对于DRAM DIMM要大很多,价格相对于DRAM更有优势,将Tair Mdb的数据存放在NVM上,是突破单机内存容量的限制的一个方向。
生产环境
效果
端到端,读写平均延时和相同软件版本下使用DRAM的节点数据持平;服务行为表现正常。生产环境的压力并没有达到Tair MDB节点的极限,后面的章节会介绍压测时我们遇到的问题和解决方案。
成本
前面提到了单根NVM DIMM最大容量比DRAM DIMM要高,相同容量的价格会比DRAM便宜。Tair MDB容量型的集群,如果采用NVM来补充内存容量的不足,规模可以大幅减少。算上机器价格、电费、机架等因素,成本大约可以降低30% ~ 50%左右 。
原理
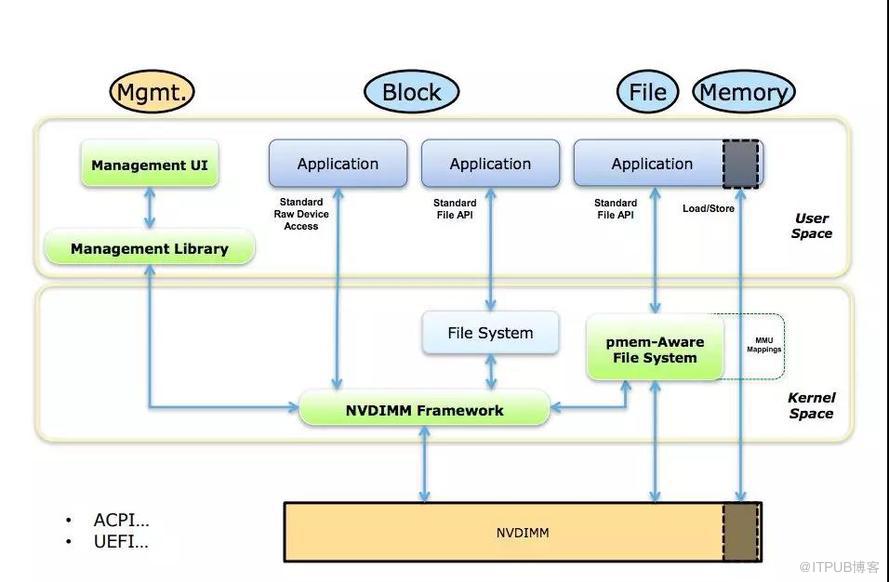
使用方式
Tair MDB使用NVM设备的方式,是把NVM以块设备的形式使用Pmem-Aware File System挂载(DAX挂载模式)。分配NVM空间对应的操作是在对应的文件系统路径上创建并打开文件,使用posix_fallocate分配空间。
内存分配器
NVM本身具备非易失的特性,对于缓存服务Tair MDB,是把NVM当作易失性设备,不需要去考虑操作的原子性和crash之后的recovery操作,也不需要显式地调用clflush/clwb等命令将CPU Cache中的内容强制刷回介质。
使用DRAM空间时,有tcmalloc/jemalloc等内存分配器可供选择,现在NVM的空间暴露给上层的是一个文件(或者是一个字符设备),所以如何使用内存分配器是首先需要考虑的事情。开源项目pmem[1]中维护了易失性的内存管理库libmemkind,有易用的类malloc/free的API,大部分应用接入时可以考虑这种方式。
Tair MDB在实现时并没有使用libmemkind[2]。下面介绍Tair MDB的内存布局,说明做出这种选择的原因。
内存布局
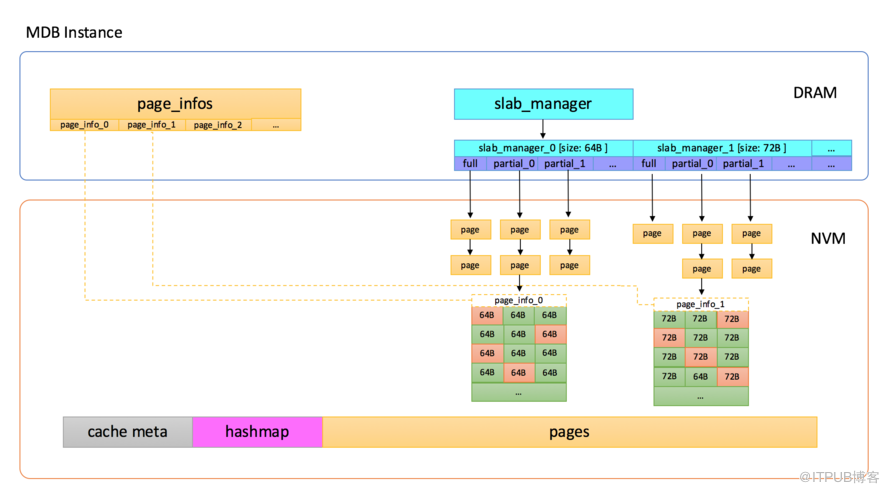
Tair MDB在内存管理上使用了slab机制,不是在使用时动态地分配匿名内存,而是在系统启动时先分配一大块内存,内置的内存管理模块会把元数据、数据页等在这一大块内存上连续分布,如下图所示:
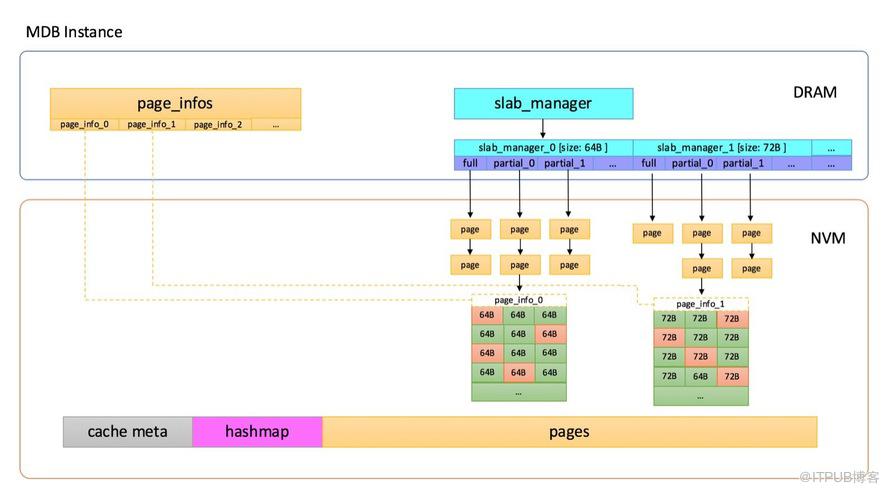 Tair MDB使用的内存主要分为以下几部分:
Tair MDB使用的内存主要分为以下几部分:
Cache Meta,存放了一些最大分片数之类的元数据信息,还有Slab Manager的索引信息。
Slab Manager,每个Slab Manager中管理固定大小的Slab。
Hashmap,全局哈希表索引,使用线性冲突链的方式处理哈希冲突,所有key的访问都需要经过Hashmap。
Page pool,内存池,启动之后会将内存划分成以1M为单位的页,Slab Manager会从Page pool中申请页,并格式化成指定的slab大小。
Tair Mdb会在启动时对所有可用的内存进行初始化,后续数据存储部分不需要动态地从操作系统分配内存了。
在使用NVM时,把对应的文件mmap到内存,获取虚拟地址空间,内置的内存管理模块就可以透明地利用这块空间了。所以在这个过程中,并不需要再调用malloc/free来管理NVM设备上的空间。
压测
Tair MDB在使用NVM作为DRAM的补充,辅助DRAM作为后端存储之后,在压测过程中遇到了一些问题,在这一章节会介绍这些问题的具体表现和优化的方法。
问题
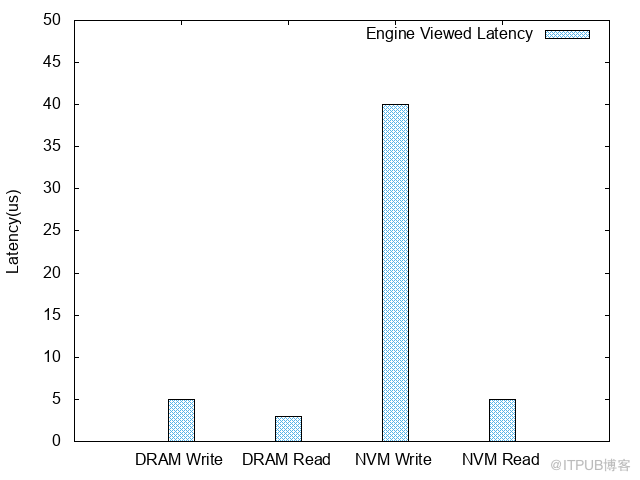
使用了NVM之后,使用100 bytes的条目对Tair MDB进行了压测,得到如下的数据:
引擎内延迟
客户端观测QPS
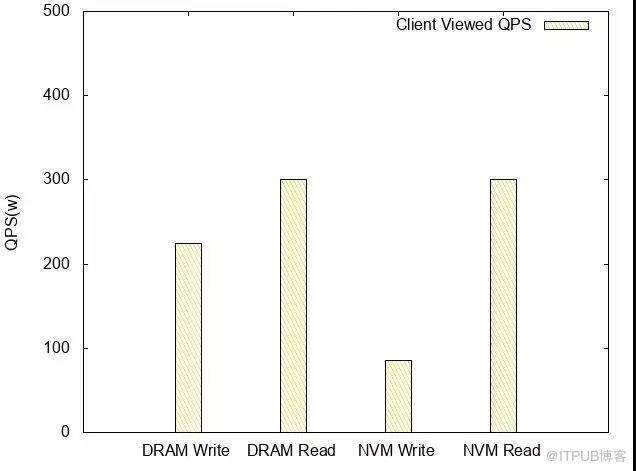
基于NVM的Read QPS /latency和DRAM相当,Write TPS大概是DRAM的1/3。
分析
写性能的损耗从perf的结果上看都在锁上,这个锁管理的临界区包含的是对上文内存布局中提到的Page的写操作。怀疑这种情况是NVM上的写延迟比DRAM上高导致的。
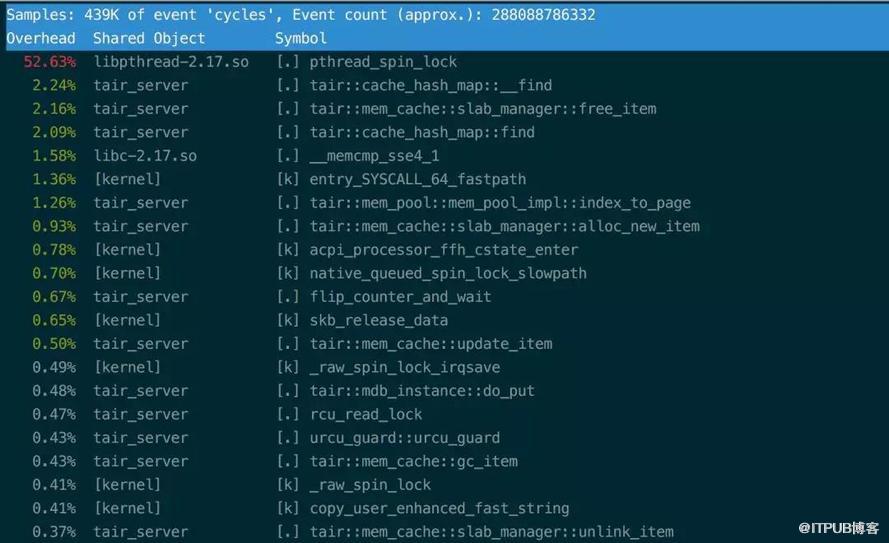 在压测的过程中,使用pcm[3]查看NVM DIMMS的带宽统计,观察到在某一根DIMM上的写非常不均衡,稳定情况下大约是其它DIMM的两倍。
在压测的过程中,使用pcm[3]查看NVM DIMMS的带宽统计,观察到在某一根DIMM上的写非常不均衡,稳定情况下大约是其它DIMM的两倍。
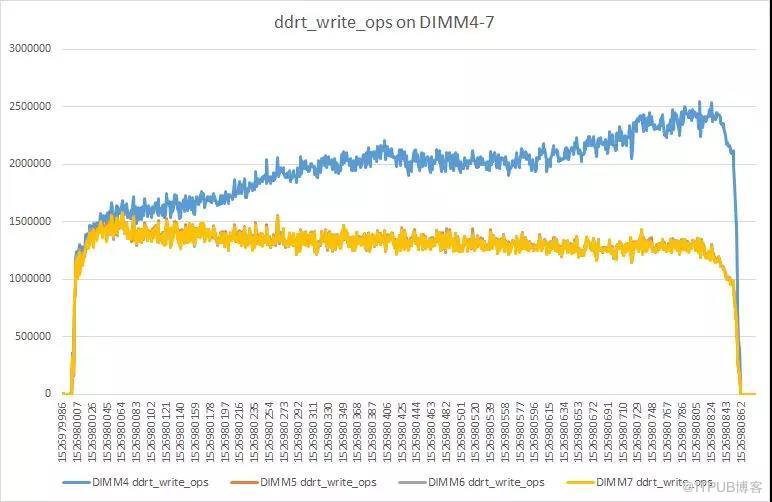
具体情况如下图所示:
这里先大概介绍下NVM DIMM的放置策略。
放置策略
现在使用单socket放置了4根 NVM DIMM,具体分布类似下图:
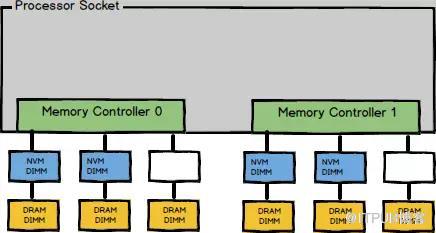
这种放置策略被称为2-2-1。每一个socket有4根 DIMM,分别属于四个不同的通道。在使用多个通道时,为了有效利用内存带宽CPU会进行interleave。当前放置策略和配置下,CPU以4K为单位,按照DIMM顺序进行interleave。

不均衡原因
从memory interleaving的策略,可以推断每次都会写同一个区域,而这片区域位于那根不均衡的DIMM上,导致这根DIMM的写入量会明显高于其它的DIMM。
那么接下来需要解决的问题就是找到导致写热点的处理逻辑。trivial的方法就是找些可疑的点,然后一个个排除下去,下面介绍下Tair工程团队使用的方法。
优化
上面提到了,写热点导致NVM DIMM访问不均衡,所以优化的第一步是先把写热点找出来,进行一些处理,比如说打散热点访问,或者把热点访问的区域放到DRAM中。
查找写热点
对于写热点的查找,Tair工程团队使用了Pin[4]。上面提到Tair MDB是对文件进行mmap获取逻辑地址来操作内存。于是我们可以使用Pin抓取mmap的返回值,进而得到NVM在程序内存空间中的逻辑地址。之后我们继续使用Pin对所有操作内存的程序指令进行插桩,统计对NVM映射到的地址空间中的每个字节的写入次数。
最终,发现写热点的确存在,相应的区域是Page的元数据。解决写热点的方案考虑过:加padding把热点交错到各个DIMM上、基本一样热的数据分DIMM存放、将热点移回DRAM等,最终选择将slab_manager和page_info移回DRAM。修改后结构如下:
至此,不均衡问题解决,TPS从85w提升至140w,此时引擎内写延迟从40us降低到12us。
锁开销过大
当TPS在140w时,注意到上面提到过的pthread_spin_lock的开销依然非常大。通过perf record的结果可以看到,pthread_spin_lock消耗的调用栈是:
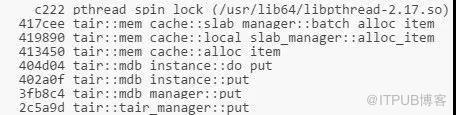
通过分析batch_alloc_item发现临界区内对page中item的初始化操作会对NVM产生大量写入。由于NVM的写入速度比DRAM慢,所以这里成为一个很耗时的地方。
其实按照Tair MDB的逻辑,只有将page link进slab_manager的时候才需要加锁。因此这里将对item的初始化操作移出临界区。之后又对Tair MDB代码中临界区内所有对NVM的写入操作进行了排查,并进行了相应的优化。
优化之后pthread_spin_lock开销降低到正常范围内,TPS提升至170w,此时引擎内写延迟为9us。
优化结果
均衡写负载、锁粒度细化等优化有效地降低了Latency,TPS上升到了170w,相较之前的数据,TPS提高了100%。由于介质的差异,和DRAM的写性能相比依然有30%左右的差距,但是对于缓存服务读多写少的场景,这个差距对整体的性能并不会有太大的影响。
设计指引
基于上述的优化工作和生产环境的实践,Tair工程团队总结了基于NVM实现缓存服务的设计准则,这些准则是和使用的硬件特性有紧密联系的。
硬件特性
对缓存服务设计有影响的特有的NVM硬件特性:
相对于DRAM密度更高,更便宜
延迟相较DRAM高,带宽比DRAM低
读写不均衡,写延迟相较读高
硬件有磨损,频繁写单一位置会加大磨损
设计准则
准则A:避免写热点
Tair MDB在使用NVM的过程中遇到过写热点的问题,写热点会加大介质的磨损,而且会导致负载不均衡(写压力在某一根DIMM上,不能充分利用所有DIMM的带宽)。除了内存布局(元数据和数据混合存放)会导致写热点外,业务的访问行为也会导致写热点。
这里,Tair工程团队总结了几种避免写热点的方法:
分离元数据和数据,将元数据移到DRAM中。元数据访问频率会相对于数据更高,前面提到的Tair MDB 中page_info属于元数据。这样可以从上层缓解NVM写延迟相较DRAM高的劣势。
上层实现Copy-On-Write的逻辑。这样在一些场景下会减少对特定区域硬件的磨损,Tair MDB中更新一条数据时,并不会in-place update之前的条目,而是会新增条目添加到hashmap冲突链的头部,异步删除之前的条目。
常态检测热点写,动态迁移到DRAM,执行写合并。对于上面提到的业务访问行为导致的热点写,Tair MDB会常态化检测热点写,并把热点写进行合并,减少对下层介质的访问。
准则B:减少临界区访问
由于NVM的写延迟相较DRAM高,所以当临界区中包含了对NVM的操作时,临界区的影响会放大,导致上层的并发度降低。
前面提到的锁开销,Tair MDB运行在DRAM上时并没有观测到,原因是运行在DRAM上,假设了这个临界区的开销比较小,但是使用NVM时,这个假设不成立了。这也是在使用新介质时经常会遇到的问题,以往软件流程中可能没有意识到的一些假设,在新介质上不成立了,这时候就需要对原有的流程进行一些调整。
鉴于上面的原因,Tair工程团队建议缓存服务使用NVM时,应该尽量地结合数据存储做无锁化的设计,减少临界区的访问,规避延迟升高带来的级联影响。
Tair MDB引入了用户态RCU,对大部分访问路径上的操作进行了无锁化改造,极大地降低了NVM延迟对上层带来的影响。准则C:实现合适的分配器
分配器是业务使用NVM设备的基础组件,分配器的并发度会直接影响软件的效率,分配器的空间管理会决定空间利用率。设计实现或者选择适合于软件特性的分配器,是缓存服务使用NVM的关键。
从Tair MDB的实践上来看,适用于NVM的分配器应该具备以下功能和特性:
碎片整理:由于NVM有密度更高、容量更大,所以在相同碎片率下,相较于DRAM会浪费更多的空间。由于碎片整理机制的存在,所以需要上层应用避免in-place update,而且尽量保证分配器分配的空间是fixed size。
需要有Threadlocal的quota:和上面说的减小临界区访问类似,如果没有Threadlocal的quota,从全局的资源池中分配资源的延时会降低分配操作的并发度。
Capacity-aware,分配器需要感知所能管理的空间: 缓存服务需要对管理的空间进行扩容或者缩容,分配器需要提供相应的功能以适配这个需求。
以上这些设计准则都是在实践中检验过,切实可行,而且会对应用带来有利的影响,相信对其它希望使用NVM的产品也会有非常大的帮助。
未来的工作
上面提到了Tair MDB使用NVM时还是当作易失性的设备,利用了密度大价格低的优势来降低整体服务的成本。未来Tair工程团队会致力于更好地利用NVM的非易失特性,挖掘新硬件的红利,赋能于业务和其它上层的服务。
本文是阿里巴巴集团存储技术事业部Tair团队关于NVM的系列分享的开篇,接下来会陆续推出我们在NVM领域的思考和成果。
分布式在线存储系统Tair 专注于承担超大流量下的在线访问加速,阿里巴巴集团大规模使用,在每秒数亿次访问请求的背后,提供着超低延时的响应。场景包括各类在线缓存,内存数据库,高性能持久化NoSQL数据库等,在高并发,快速响应和高可用上追求极致。在这里,你会遇到亿级别访问的尖峰时刻,不同类型业务错综复杂的场景需求,万台规模服务器集群的运营支撑,业务全球化等各类技术挑战。
本文作者
漠冰(付秋雷),阿里巴巴集团存储技术事业部技术专家,主要关注于分布式缓存、NoSQL数据库。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31077337/viewspace-2200254/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



