在上一期《时区信息记录表|全方位认识 mysql 系统库》中,我们详细介绍了mysql系统库中的时区信息记录表,本期我们将为大家带来系列第七篇《复制信息记录表|全方位认识 mysql 系统库》,下面请跟随我们一起开始 mysql 系统库的系统学习之旅吧!
1、复制信息表概述
复制信息表用于在从库在复制主库的数据期间,用于保存从主库转发到从库的二进制日志事件、记录有关中继日志当前状态和位置的信息。 一共有三种类型的日志,如下:
master.info文件或者mysql.slave_master_info表:用于保存从库的IO线程连接主库的连接状态、帐号、IP、端口、密码以及IO线程当前读取主库binlog的file和position等信息(被称为IO线程信息日志。默认情况下,IO线程的连接信息和状态保存在master.info文件中(默认位置在datadir下,可以使用master_info_file选项执行master.info文件路径),如果需要保存在mysql.slave_master_info表中,需要在server启动之前设置master-info-repository = TABLE)。
relay-log.info文件或者mysql.slave_relay_log_info表: 从库的IO线程从主库获取到最新的binlog事件信息会先写入到从库本地的relay log中,SQL线程再去读取relay log解析并重放,而relay_log.info文件或者mysql.slave_relay_log_info表就是用于记录最新的relay log的file和position以及SQL线程当前重放的事件对应主库binlog的file和position(relay log即被称为中继日志,SQL线程位置被称为SQL线程信息日志。默认情况下,relay log的位置信息和SQL线程的位置信息保存在relay-log.info文件中(默认位置在datadir下,可以使用relay_log_info_file选项执行relay-log.info文件路径),如果需要保存在mysql.slave_relay_log_info表中,需要在server启动之前设置relay-log-info-repository = TABLE)。
设置relay_log_info_repository和master_info_repository设置为TABLE可以提高数据库本身或者所在主机意外终止之后crash recovery的能力(这两张表是innodb表,可以保证crash之后表中的位置信息不丢失),且可以保证数据一致性。
从库crash时,SQL线程可能还有一部分relay log重放延迟,另外,IO线程的位置也可能正处于一个事务的中间,并不完整,所以必须在从库上启用参数relay-log-recovery=ON,启用该参数之后,从库crash recovery时会清理掉SQL线程未重放完成的relay log,并以SQL线程的位置为准重置掉IO线程的位置重新从主库请求。
这两张表在数据库实例启动时如果无法被mysqld初始化,则mysqld允许继续启动,但会在错误日志中写入警告信息,这种情况在MySQL从不支持该表的版本升级到支持该表的版本时常常遇见。
PS:
不要尝试手动更新slave_master_info或slave_relay_log_info表,否则后果自负。
从库中复制线程在持续工作时,不允许任何可能对这两张表加写锁的语句执行,但允许对这两张表做只读的语句执行。
2、复制信息表详解
由于本期所介绍的表中存放的复制信息,在我们日常的数据库维护过程当中尤其重要,所以,下文中会在每张表的介绍过程中适度进行一些扩展。
root@localhost : mysql 01:08:29> select * from slave_master_info\G;
*************************** 1. row ***************************
Number_of_lines: 25
Master_log_name: mysql-bin.000292
Master_log_pos: 194
Host: 192.168.2.148
User_name: qfsys
User_password: letsg0
Port: 3306
Connect_retry: 60
Enabled_ssl: 0
Ssl_ca:
Ssl_capath:
Ssl_cert:
Ssl_cipher:
Ssl_key:
Ssl_verify_server_cert: 0
Heartbeat: 5
Bind:
Ignored_server_ids: 0
Uuid: ec123678-5e26-11e7-9d38-000c295e08a0
Retry_count: 86400
Ssl_crl:
Ssl_crlpath:
Enabled_auto_position: 0
Channel_name:
Tls_version:
1 row in set (0.00 sec)| master.info文件中的行数 | mysql.slave_master_info表字段 | show slave status命令输出字段 | 字段含义描述 |
|---|---|---|---|
| 1 | Number_of_lines | [None] | 表示master.info中的信息行数或者slave_master_info表中的信息字段数 |
| 2 | Master_log_name | Master_Log_File | 表示从库IO线程当前读取主库最新的binlog file名称 |
| 3 | Master_log_pos | Read_Master_Log_Pos | 表示从库IO线程当前读取主库最新的binlog position |
| 4 | Host | Master_Host | 表示从库IO线程当前正连接的主库IO或者主机名 |
| 5 | User_name | Master_User | 表示从库IO线程用于连接主库用户名 |
| 6 | User_password | [None] | 表示从库IO线程用于连接主库的用户密码 |
| 7 | Port | Master_Port | 表示从库IO线程所连接主库的网络端口 |
| 8 | Connect_retry | Connect_Retry | 表示从库IO线程断线重连主库的间隔时间,单位为秒,默认值为60 |
| 9 | Enabled_ssl | Master_SSL_Allowed | 表示主从之间的连接是否支持SSL |
| 10 | Ssl_ca | Master_SSL_CA_File | 表示CA(Certificate Authority )认证文件名 |
| 11 | Ssl_capath | Master_SSL_CA_Path | 表示CA(Certificate Authority )认证文件路径 |
| 12 | Ssl_cert | Master_SSL_Cert | 表示SSL认证证书文件名 |
| 13 | Ssl_cipher | Master_SSL_Cipher | 表示用于SSL连接握手中可能使用到的密码列表 |
| 14 | Ssl_key | Master_SSL_Key | 表示SSL认证的密钥文件名 |
| 15 | Ssl_verify_server_cert | Master_SSL_Verify_Server_Cert | 表示是否需要校验server的证书 |
| 16 | Heartbeat | [None] | 表示主从之间的复制心跳包的间隔时间,单位为秒 |
| 17 | Bind | Master_Bind | 表示从库可用于连接主库的网络接口,默认为空 |
| 18 | Ignored_server_ids | Replicate_Ignore_Server_Ids | 表示从库复制需要忽略哪些server-id,注意:这是一个列表,第一个数字表示需要忽略的实例server-id总数 |
| 19 | Uuid | Master_UUID | 表示主库的UUID |
| 20 | Retry_count | Master_Retry_Count | 表示从库最大允许重连主库的次数 |
| 21 | Ssl_crl | [None] | SSL证书撤销列表文件的路径 |
| 22 | Ssl_crl_path | [None] | 包含ssl证书吊销列表文件的目录路径 |
| 23 | Enabled_auto_position | Auto_position | 表示从库是否启用在主库中自动寻找位置的功能(使用1时启动自动寻找位置,如果使用auto_position=0,则不会自耦东找位置) |
| 24 | Channel_name | Channel_name | 表示从库复制通道名称,一个通道代表一个复制源 |
| 25 | Tls_Version | Master_TLS_Version | 表示在Master上的TLS版本号 |
root@localhost : mysql 10:39:31> select * from slave_relay_log_info\G
*************************** 1. row ***************************
Number_of_lines: 7
Relay_log_name: /home/mysql/data/mysqldata1/relaylog/mysql-relay-bin.000205
Relay_log_pos: 14097976
Master_log_name: mysql-bin.000060
Master_log_pos: 21996812
Sql_delay: 0
Number_of_workers: 16
Id: 1
Channel_name:
1 row in set (0.00 sec)| relay-log.info文件中的行数 | mysql.slave_relay_log_info表字段 | show slave status命令输出字段 | 字段含义描述 |
|---|---|---|---|
| 1 | Number_of_lines | [None] | 表示relay-log.info中的信息行数或者slave_relay_log_info表中的信息字段数,用于版本化表定义 |
| 2 | Relay_log_name | Relay_Log_File | 表示当前最新的relay log文件名称 |
| 3 | Relay_log_pos | Relay_Log_Pos | 表示当前最新的relay log文件对应的最近一次完整接收的event的位置 |
| 4 | Master_log_name | Relay_Master_Log_File | 表示SQL线程当前正在重放的中继日志对应的主库binlog 文件名 |
| 5 | Master_log_pos | Exec_Master_Log_Pos | 表示SQL线程当前正在重放的中继日志对应主库binlog 文件中的位置 |
| 6 | Sql_delay | SQL_Delay | 表示延迟复制指定的从库必须延迟主库多少秒 |
| 7 | Number_of_workers | [None] | 表示从库当前并行复制有多少个worker线程 |
| 8 | Id | [None] | 用于内部唯一标记表中的每一行记录,目前总是1 |
| 9 | Channel_name | Channel_name | 表示从库复制通道名称,用于多源复制,一个通道对应一个主库源 |
什么是中继日志:
中继日志(relay log)与二进制日志(binlog,即,binary log)中,保存的event数据是一样的(但中继日志中还保存了更多的信息),也是由一组包含描述数据库变更的事件数据的文件组成,这些文件名后缀带连续编号,此外,还有一个包含所有正在使用的中继日志文件名称的索引文件。
中继日志中的数据存放格式与二进制日志相同,都可以使用mysqlbinlog命令来提取数据,默认情况下,中继日志保存在datadir下,文件名格式为: host_name-relay-bin.nnnnnn,其中host_name是从库服务器主机名,nnnnnn是文件后缀序列号。连续的中继日志文件从000001开始的连续序列号创建。使用索引文件来跟踪当前正在使用的中继日志文件。默认的中继日志索引文件名保存在datadir下,文件名格式为:host_name-relay-bin.index。
* 中继日志文件和中继日志索引文件名称可分别使用--relay-log和--relay-log-index参数选项指定值覆盖默认值,如果文件名使用默认值,则要注意主机名称不能修改,否则会报无法打开中继日志的错误,建议使用参数选项指定固定的文件名称前缀。如果已经出现了这种情况发生报错了,那么需要修改index文件中的中继日志文件名和datadir下的中继日志文件名前缀为新的主机名,然后重启从库。
在什么情况下会产生新的中继日志文件。
I/O线程启动时。
使用语句: FLUSH LOGS或mysqladmin flush-logs命令时。
当前中继日志文件的大小变得“太大”时,日志滚动规则如下:
* 如果max_relay_log_size系统变量的值大于0,那么中继日志按照此参数指定的大小进行滚动。
* 如果max_relay_log_size系统变量的值为0,则中继日志按照max_binlog_size系统变量指定的大小进行滚动。
SQL线程在执行完relay log之后,会自行决定何时清理掉这些已经执行完成的relay log文件,但如果使用FLUSH LOGS语句或mysqladmin flush-logs命令强制滚动中继日志时,SQL线程可能会同时清理掉已经执行完成的relay log文件。
root@localhost : mysql 01:09:39> select * from slave_worker_info limit 1\G;
*************************** 1. row ***************************
Id: 1
Relay_log_name:
Relay_log_pos: 0
Master_log_name:
Master_log_pos: 0
Checkpoint_relay_log_name:
Checkpoint_relay_log_pos: 0
Checkpoint_master_log_name:
Checkpoint_master_log_pos: 0
Checkpoint_seqno: 0
Checkpoint_group_size: 64
Checkpoint_group_bitmap:
Channel_name:
1 row in set (0.00 sec)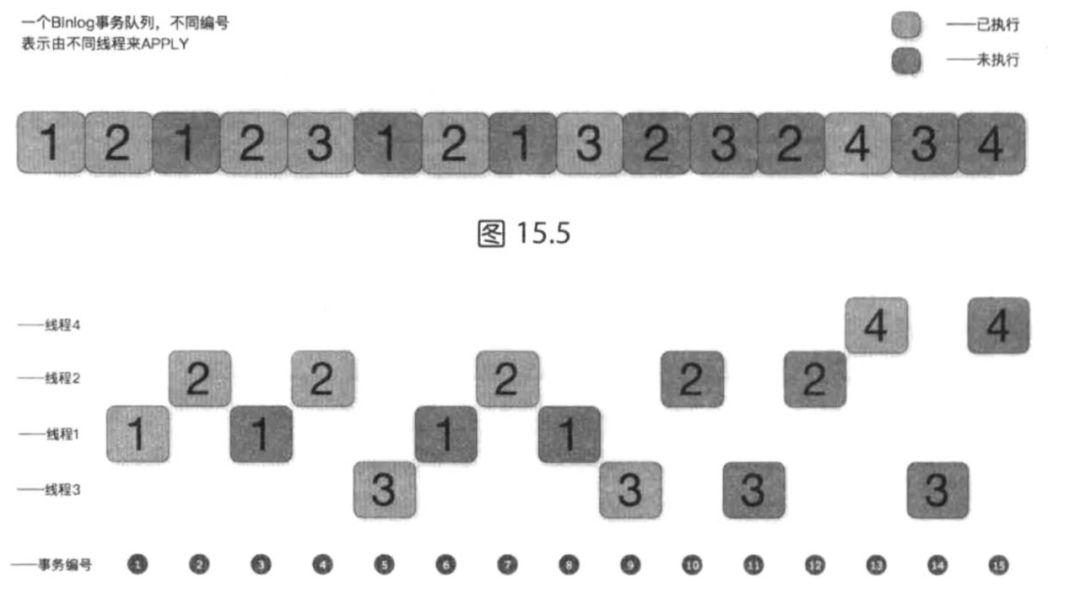
# 假设表中有如下实时记录的GTID记录
mysql> SELECT * FROM mysql.gtid_executed;
+ -------------------------------------- + ---------- ------ + -------------- +
| source_uuid | interval_start | interval_end |
| -------------------------------------- + ---------- ------ + -------------- |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 |
...
# 那么,每达到gtid_executed_compression_period变量定义的事务个数时,激活压缩功能,GTID被压缩为一行记录,如下
+ -------------------------------------- + ---------- ------ + -------------- +
| source_uuid | interval_start | interval_end |
| -------------------------------------- + ---------- ------ + -------------- |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 43 |
...
# 注意:当gtid_executed_compression_period系统变量设置为0时,周期性自动压缩功能失效,你需要预防该表被撑爆的风险mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
*************************** 1. row ***************************
THREAD_ID: 26
NAME: thread/sql/compress_gtid_table
TYPE: FOREGROUND
PROCESSLIST_ID: 1
PROCESSLIST_USER: NULL
PROCESSLIST_HOST: NULL
PROCESSLIST_DB: NULL
PROCESSLIST_COMMAND: Daemon
PROCESSLIST_TIME: 1509
PROCESSLIST_STATE: Suspending
PROCESSLIST_INFO: NULL
PARENT_THREAD_ID: 1
ROLE: NULL
INSTRUMENTED: YES
HISTORY: YES
CONNECTION_TYPE: NULL
THREAD_OS_ID: 18677"翻过这座山,你就可以看到一片海! "。 坚持阅读我们的"全方位认识 mysql 系统库"系列文章分享,你就可以系统地学完它。 谢谢你的阅读,我们下期不见不散!
| 作者简介
罗小波·沃趣科技高级数据库技术专家
IT从业多年,主要负责MySQL 产品的数据库支撑与售后二线支撑。曾参与版本发布系统、轻量级监控系统、运维管理平台、数据库管理平台的设计与编写,熟悉MySQL体系结构,Innodb存储引擎,喜好专研开源技术,多次在公开场合做过线下线上数据库专题分享,发表过多篇数据库相关的研究文章。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/28218939/viewspace-2661510/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



